走出大模型部署新手村!小明这样用魔搭+函数计算
作者:拓山
前文介绍了魔搭 ModelScope 社区模型服务 SwingDeploy** 服务**。开发者可以将模型从魔搭社区的模型库一键部署至阿里云函数计算,当选择模型并部署时,系统会选择对应的机器配置。按需使用可以在根据工作负载动态的减少资源,节约机器使用成本。5分钟完成从开源模型至模型推理 API 服务的生产转换……好,优势前文已经介绍过了。
那么,到底怎么应该怎么开始使用,本文将带小明(纯纯的小白)走出新手村,体验魔搭社区的一键部署服务(SwingDeploy),对小明的种种疑惑进行解答。开始!
0.小明如何在魔搭社区一键部署开源模型?
魔搭开源社区当前只有热门开源模型支持一键部署(可支持部署的模型列表紧密扩充中),小明可以在模型库列表页面,过滤支持快速部署的SwingDeploy的模型列表,然后点击进模型详情页,其中模型详情页的右上角包含有部署按钮,可以进行快速部署(SwingDeploy)。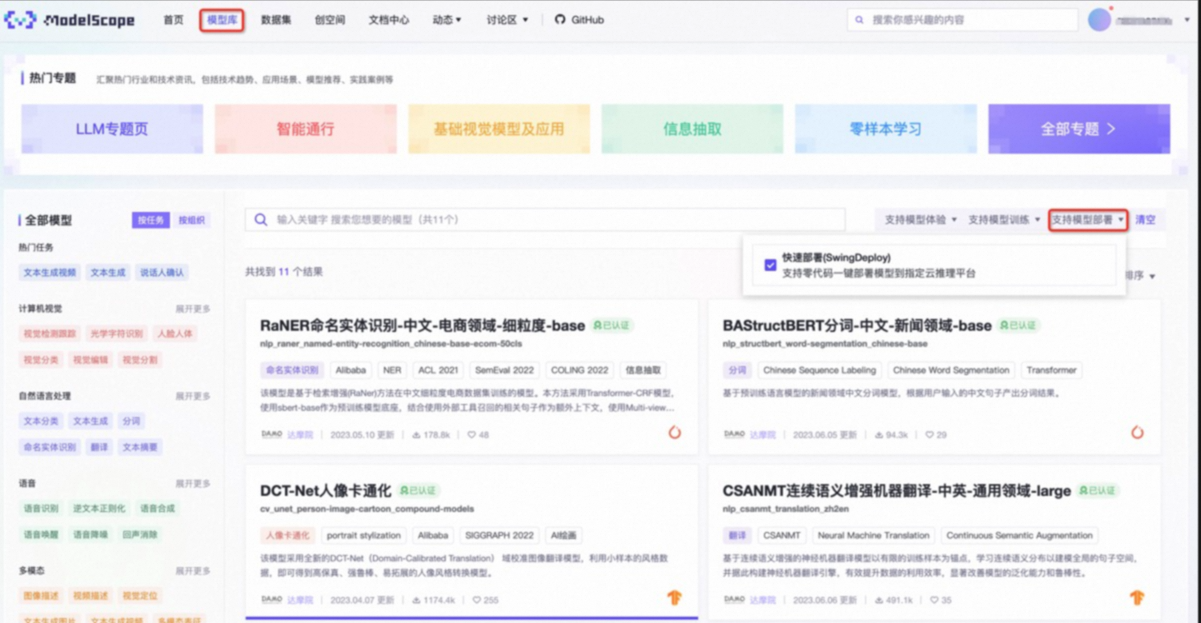
模型列表页:过滤支持模型部署的模型列表
- 模型详情页:右上快速部署
另外,小明可以切换至首页,通过左侧【模型服务】进入模型部署服务(SwingDeploy)页面。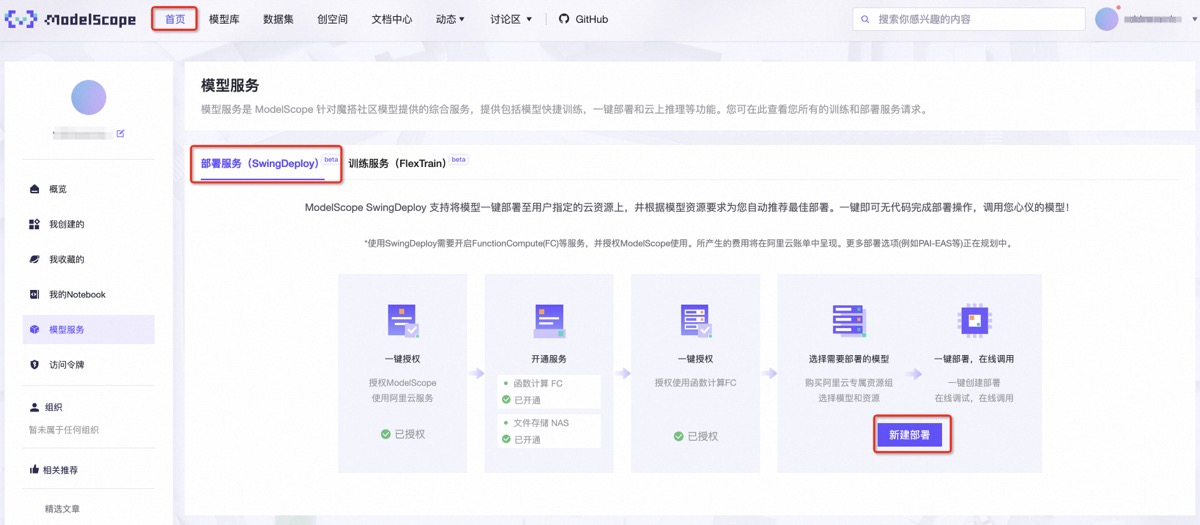
在新建快速部署(SwingDeploy)后,小明可以针对模型部署信息进行配置,包括必要的部署模型版本、部署地域、部署卡型、部署显存等。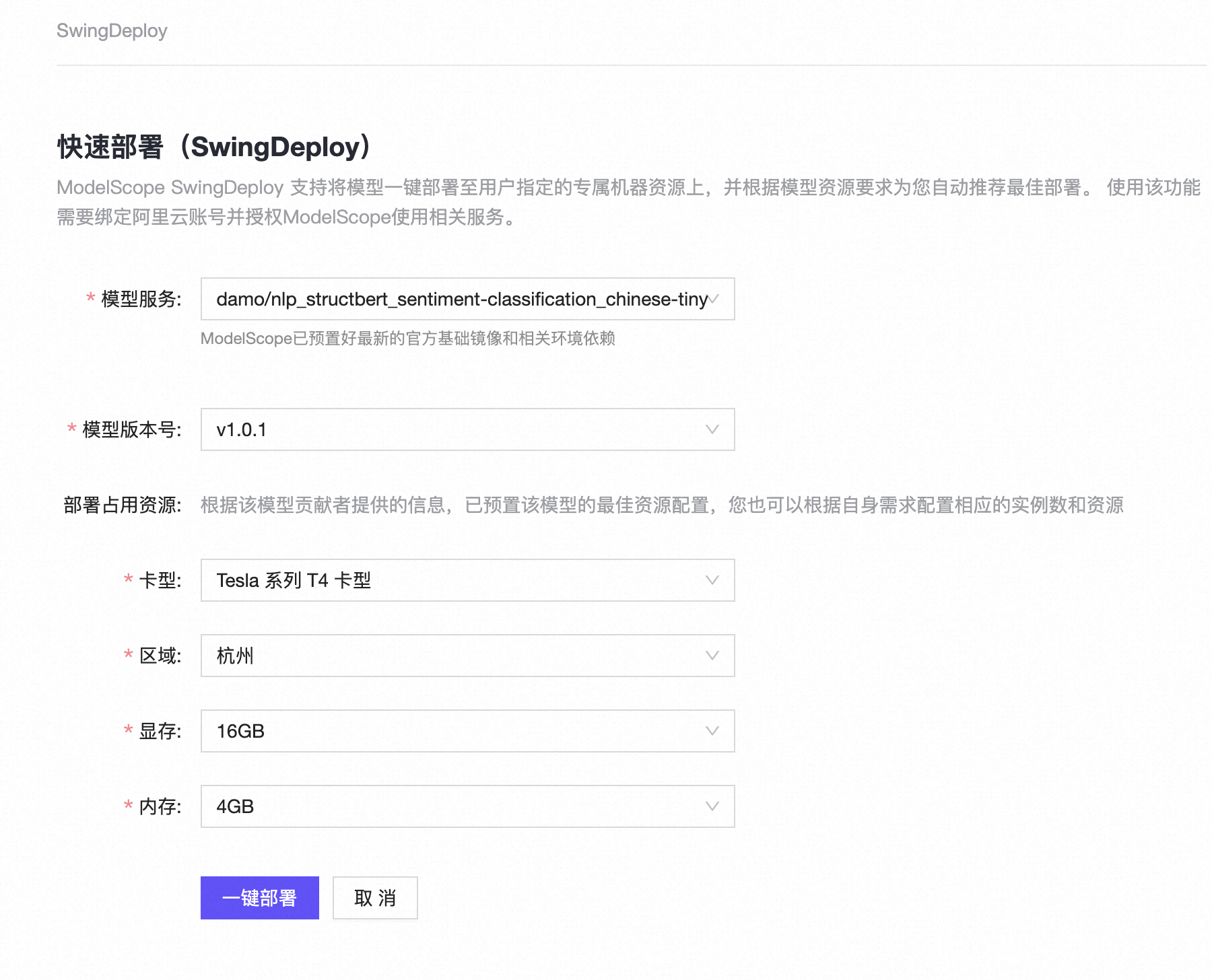
当小明点击确认快速配置无误后,通过点击【一键部署】按钮,从而进入部署过程;整个过程一般持续1-5分钟,当部署完成后,可以看到服务状态切换为【部署成功】。
小明在魔搭一键部署模型到FC后,实际在FC部署了什么?
当小明将魔搭开源模型一键部署(SwingDeploy)到阿里云函数计算FC后,实际上是在阿里云函数计算FC 平台创建了对应的服务与函数;服务和函数是阿里云函数计算资源模型中的一级概念:
- 服务:
- 一个服务中可以包含多个函数。
- 在服务级别上可以配置日志采集、网络通道、存储扩展等,服务中的所有函数继承服务中的这些配置。
- 函数:
- 函数是调度与运行的基本单位,是平台用户业务逻辑的所在,其中指明了代码/容器镜像,配置了CPU/内存/显存/GPU的运行规格等。
函数计算平台在收到该函数的推理请求调用后,会根据服务和函数的配置来创建对应的CPU/GPU容器实例。函数实例处理完请求后,再由平台将响应返回给用户。对应的CPU/GPU容器实例空闲一段时间没有处理调用请求后,函数计算平台会将其释放。所以**默认情况下,空闲未使用的服务/函数没有资源消耗,函数计算仅对请求处理部分计费。 **
使用魔搭的“模型服务”SwingDeploy一键部署模型到函数计算后,可以在部署列表中看到“服务名称”,使用服务名称可以到函数计算控制台相应地域的服务列表找到部署好的服务和函数
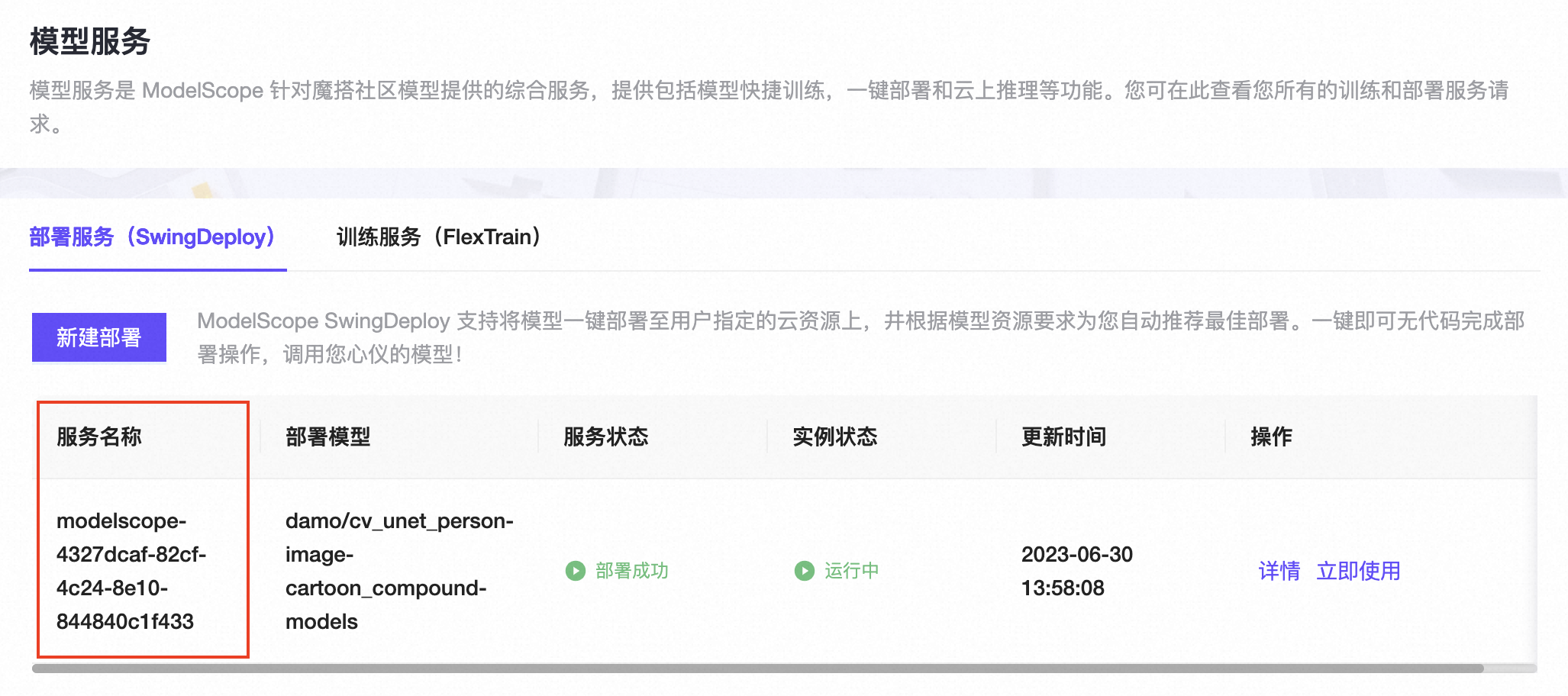
在函数计算控制台的服务与函数页面,搜索指定的服务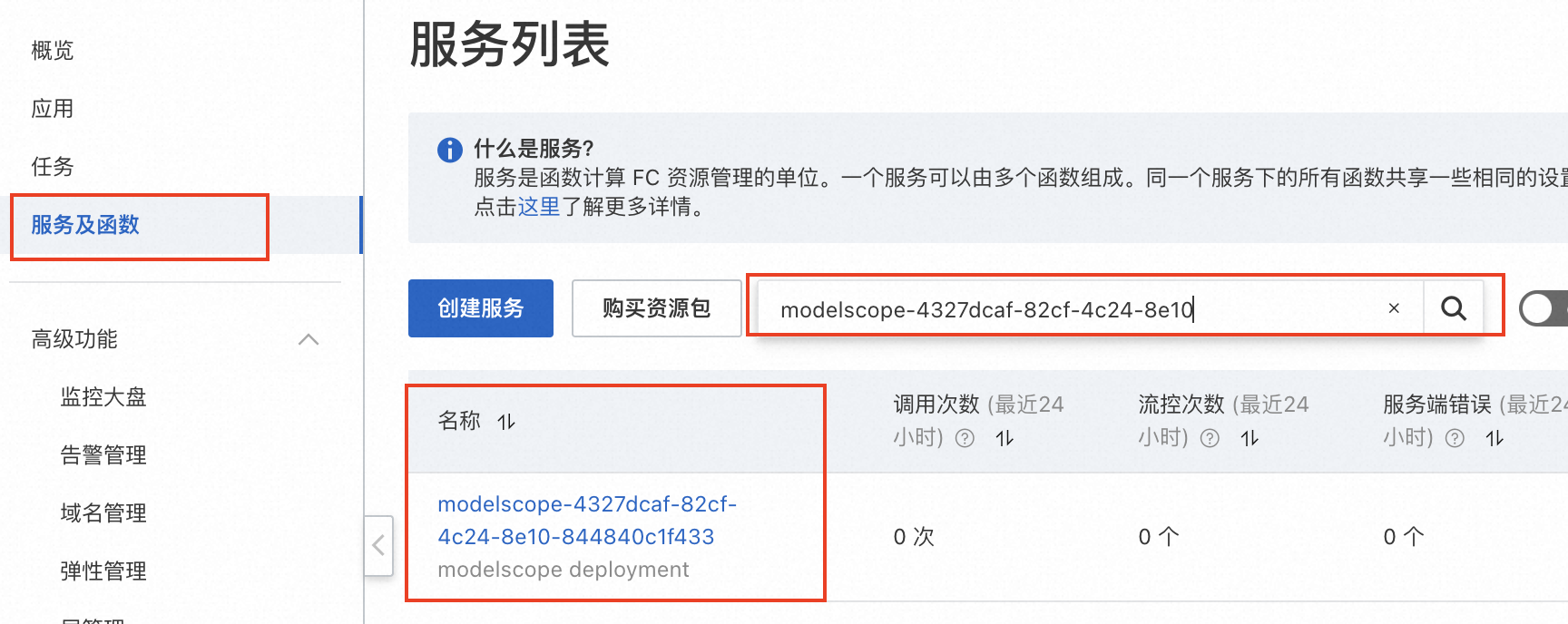
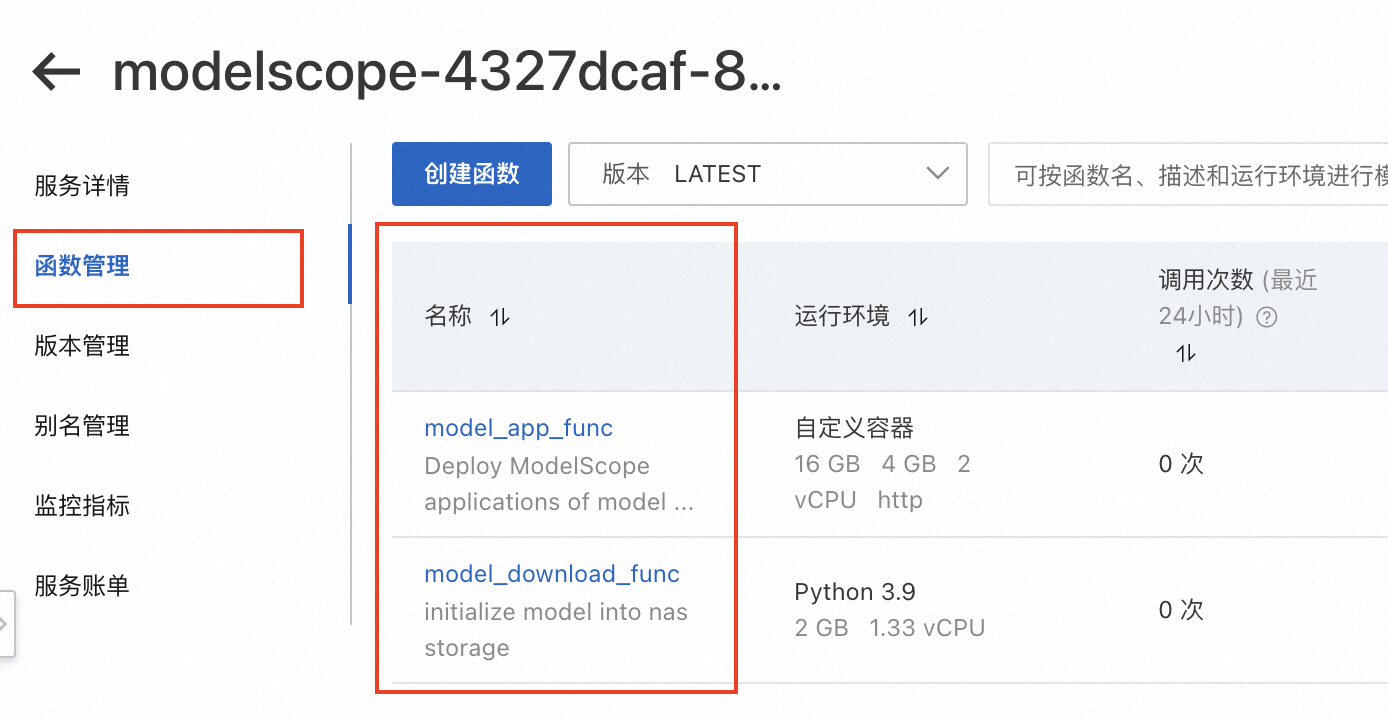
用户通过魔搭一键部署模型后,在函数计算会对应生成的一个服务与其下的两个函数:
- model_download_func作用:用于部署阶段将魔搭模型下载至用户NAS内。
- model_app_func作用:基于Flask + 魔搭模型的推理API,具体源码可见链接。
小明如何调用部署在 FC 的模型?
函数的调用是事件驱动的,我们定义一组规则,事件源产生的事件若匹配这些规则,就会触发函数的调用执行。这些规则的定义在函数计算中由“触发器”承载。具体到魔搭一键部署的函数,我们默认为其配置了一个HTTP触发器,若有相应的HTTP请求发生,即会触发函数的调用,详见函数计算平台HTTP触发器的使用文档。
小明可以通过魔搭平台提供的示例代码调用已部署好的模型。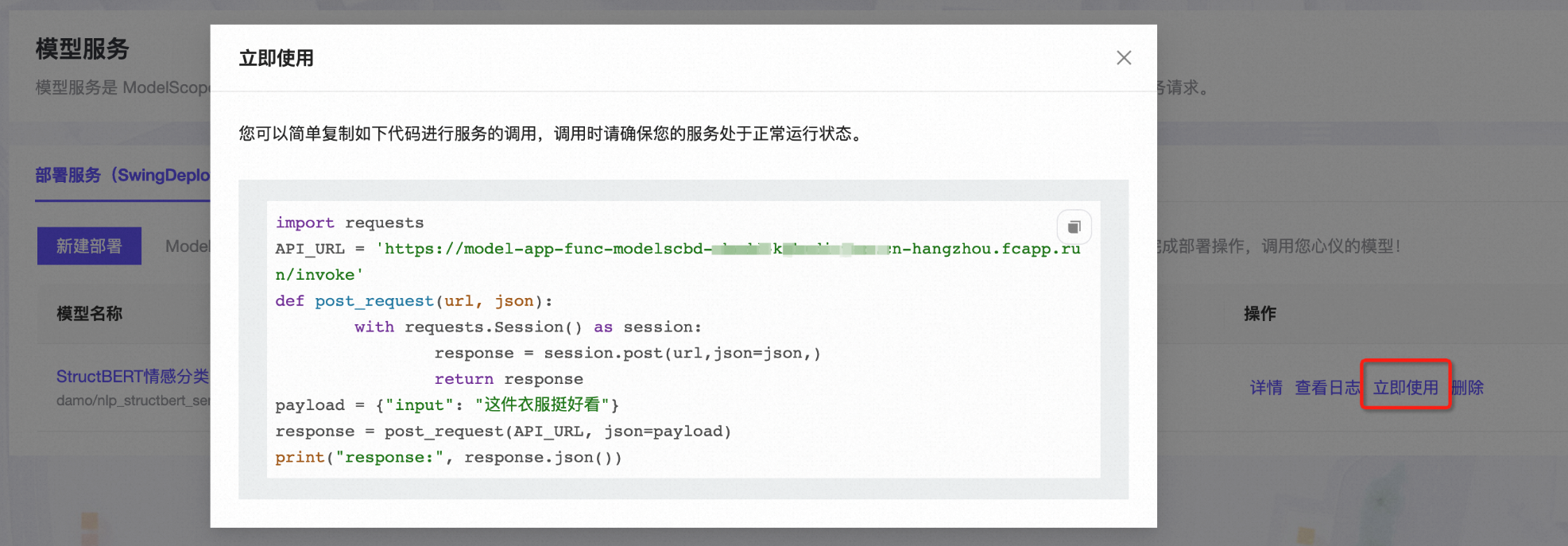
魔搭示例代码中API_URL中的HTTP URL,就是函数计算为每个魔搭模型函数配置的HTTP触发器。可以通过FC控制台,找到对应的魔搭服务下的model_app_func函数,通过查看函数详情页的“触发器管理”选项卡,查看更为详细的触发器信息。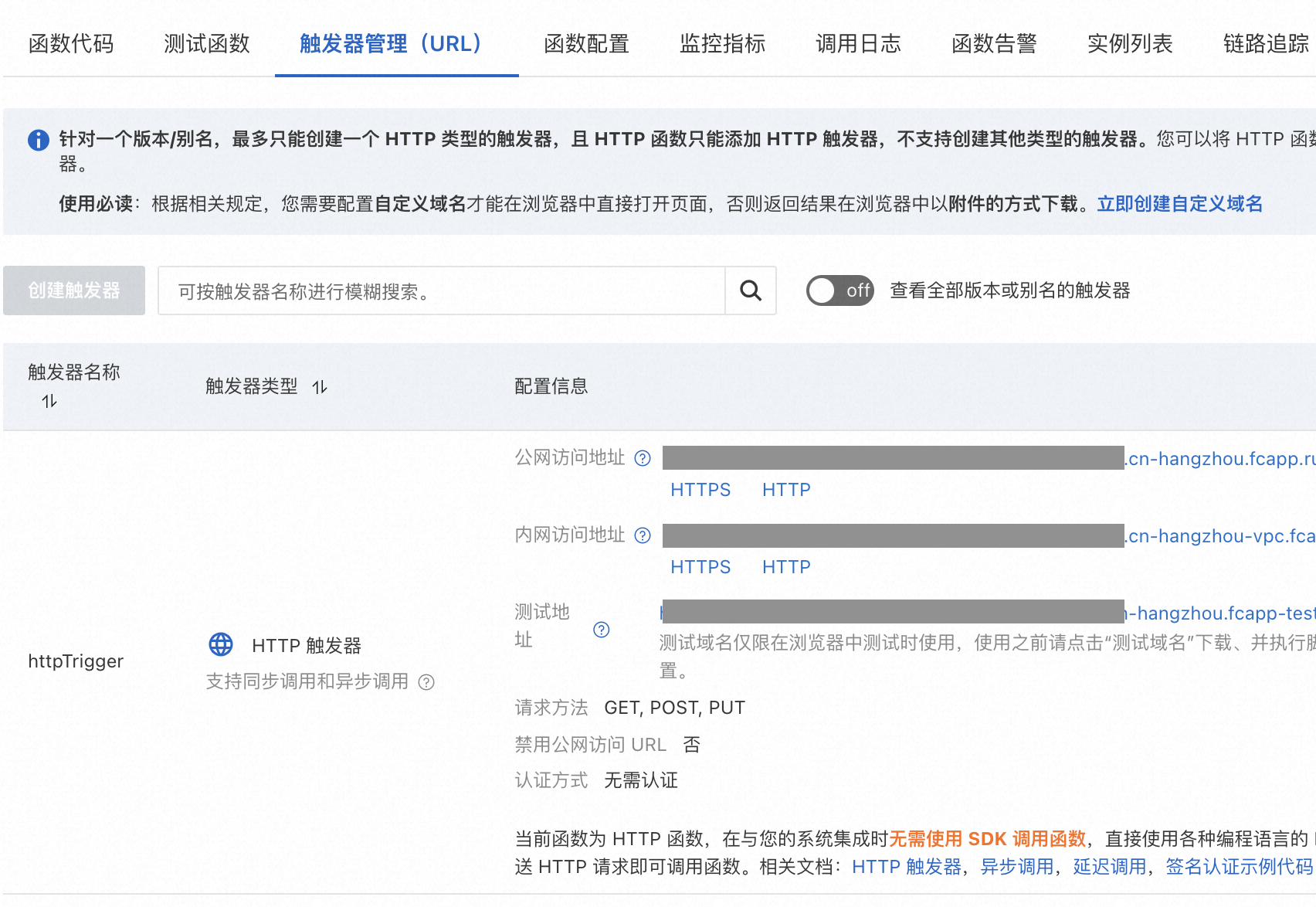
小明发现部署在FC的模型首次调用耗时长,后续调用耗时短,如何调优。
如上所说,函数如果长时间空闲(没有调用发生),平台会通过回收函数实例来释放资源。函数计算平台在收到一个调用请求后,会判断当前是否有空闲的函数实例可供使用,如果没有,则需要新创建一个函数实例来服务该请求,这个过程称之为冷启动。
如果函数实例初始化时间耗时较长,那么服务该实例上发生的初次调用的时延也会增加,例如,初始化较大的模型文件(ChatGLM-6B模型文件15GB)。
为了应对上述场景,函数实例按照弹性规则,可以分为按量和预留两种模式。上述根据请求量弹出的实例我们称为按量实例。与之对应的,可以为函数配置弹性规则,增加预留模式的实例。预留实例由函数计算平台预先创建,属于常驻资源,可用于平缓突发请求产生的时延毛刺。
FC按量模式与预留模式的差异:
- FC按量模式为通过请求自动触发实例的创建,首次发起调用时,需要等待实例冷启动。如果您希望消除冷启动延时的影响,可以通过配置FC预留模式来解决。
- FC预留模式是将函数实例的分配和释放交由您管理,当配置预留函数实例后,预留的函数实例将会常驻,直到您主动将其释放。
在控制台中,可以在函数详情的“弹性管理”选项卡配置弹性规则。如下图示例,最小实例数即预留实例数,最大实例数与最小实例数之差即按量实例数的上限(避免弹出资源太多,控制成本上限)。弹性管理的配置方法详见文档
例如:可以通过如下操作指导,预留指定数量的GPU实例(测试目的:一般建议预留1个GPU实例)。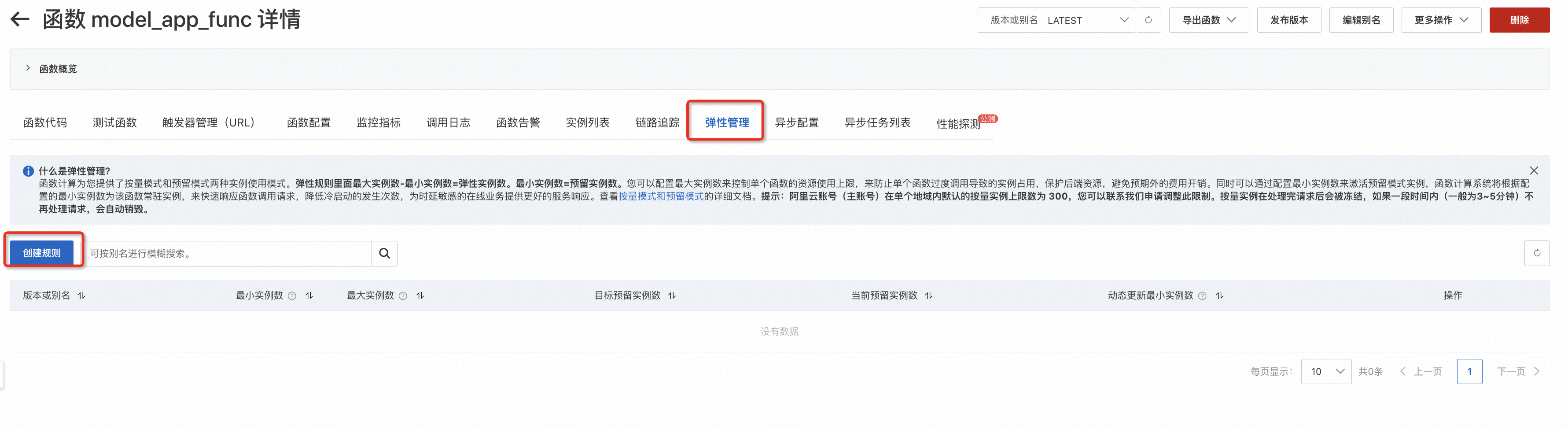
- 切换至函数的弹性管理Tab页
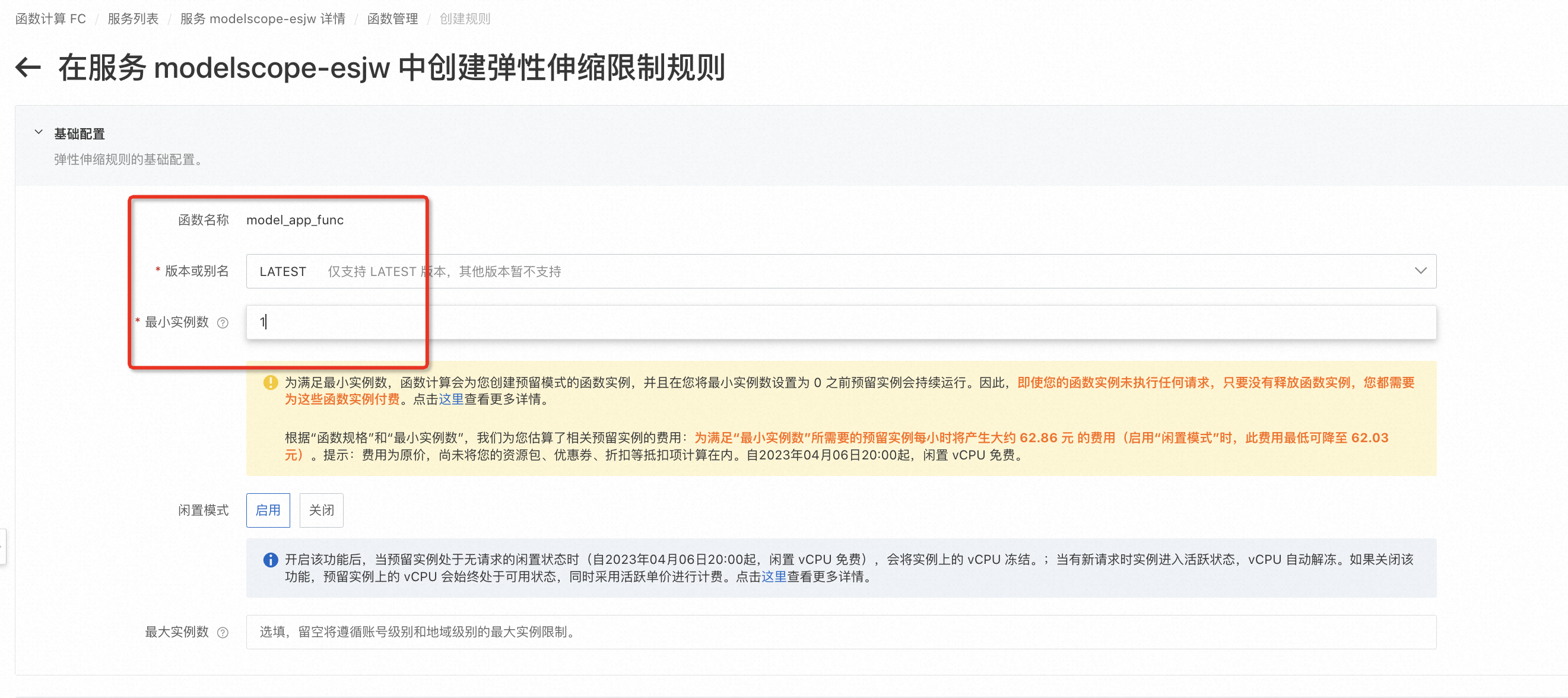
- 设置函数的LATEST版本,至少预留1个GPU实例
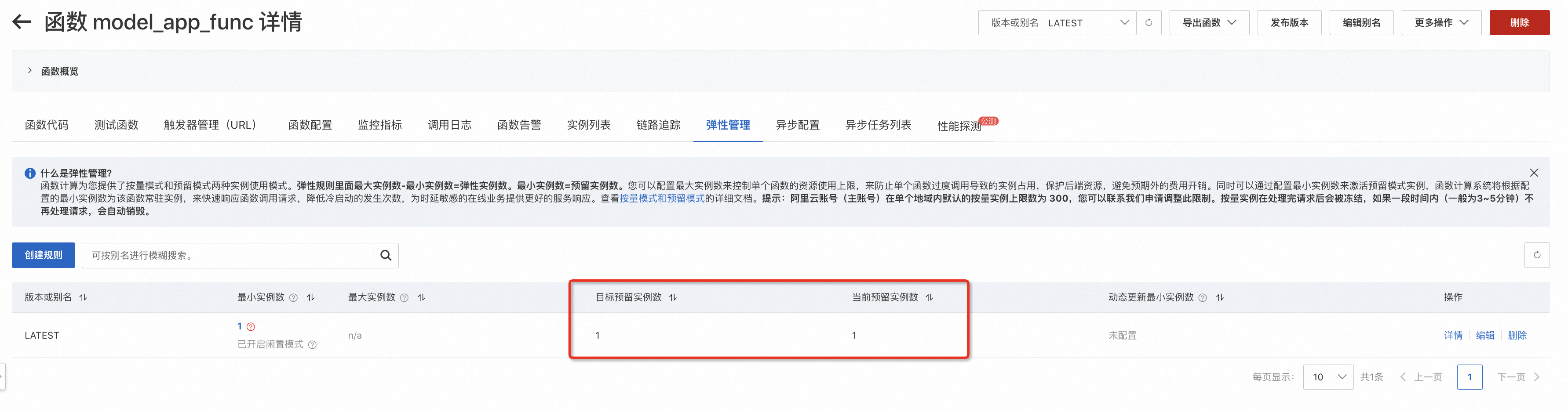
- 查看当前预留实例数量,是否满足目标预留实例数量。(上图表明完成指定数量的GPU实例预留)
- 当预留实例就绪后,推理请求调用会被优先分配至该预留实例上执行,从而规避按量场景下的冷启动。
- 小明可以通过请求级别的日志观测,来查看请求是由按量实例服务、还是预留实例服务。

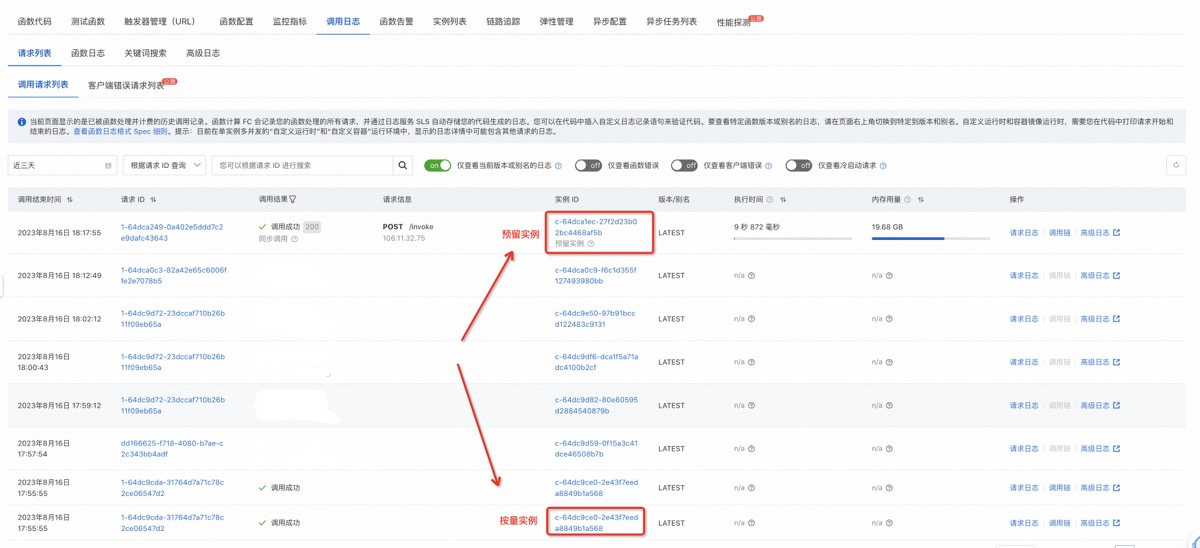
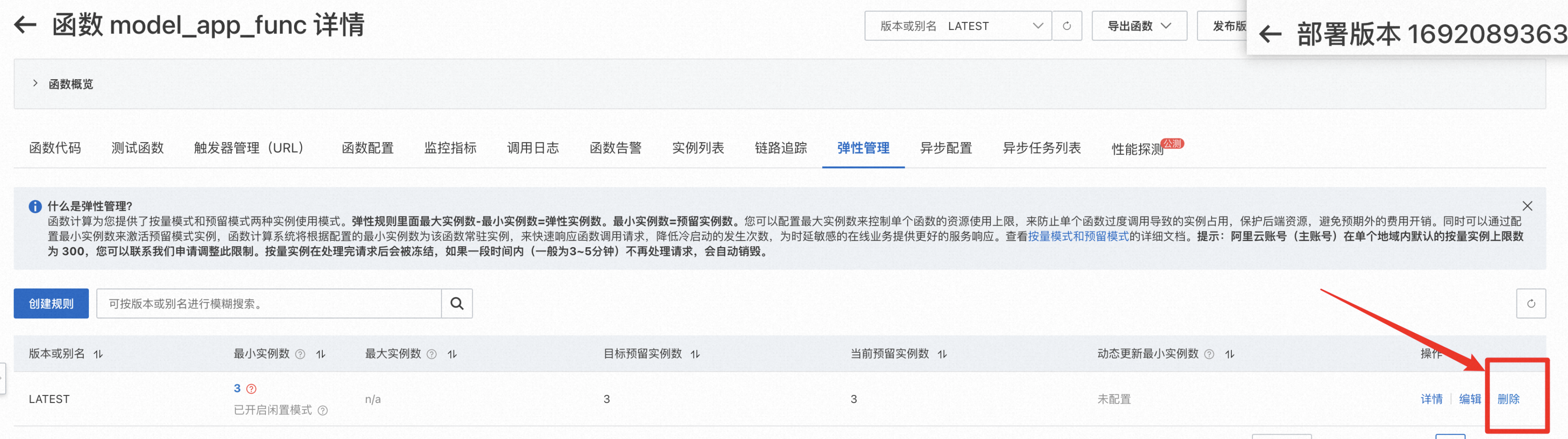
- 通过删除弹性规则,可以删除对应预留实例。
- 注意:预留实例的生命周期,完全由小明全权负责。
小明想实现类似MidJourney异步调用效果,应该如何做呢?
类似于 StableDiffusion 的 AIGC 生图场景,Midjourney 提供了非常好的异步队列效果,基于函数计算如何实现呢?
函数计算同时提供同步调用、异步调用、异步任务三种处理能力。
- 同步调用:
- 当您同步调用一个函数时,事件将直接触发函数,函数计算会运行该函数并等待响应。当函数调用完成后,函数计算会将执行结果直接返回给您,例如返回结果、执行摘要和日志输出。
- 详细文档:链接。
- 异步调用:
- 函数计算系统接收异步调用请求后,将请求持久化后会立即返回响应,而不是等待请求执行完成后再返回。函数计算保证请求至少执行一次。
- 详细文档:链接。
- 异步任务:
- 当您对函数发起异步调用时,相关请求会被持久化保存到函数计算内部队列中,然后被可靠地处理。如果您想追踪并保存异步调用各个阶段的状态,实现更丰富的任务控制和可观测能力,可以选择开启任务模式处理异步请求。
- 详细文档:链接。
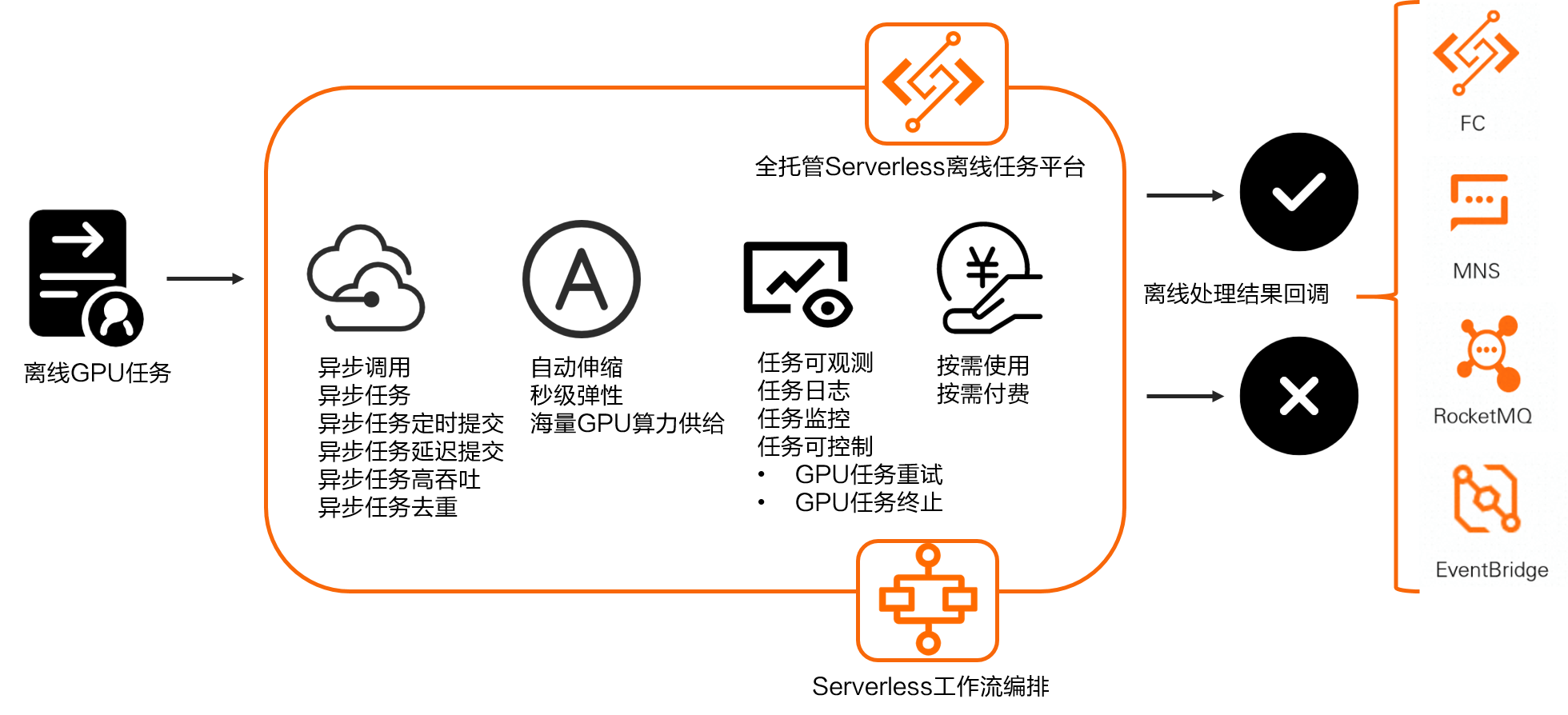
当函数计算的异步调用能力与GPU相较合时(详细文档:链接),小明可以很轻松的实现AIGC异步排队处理的良好用户体验。
小明发现模型/应用有问题,如何定位?
a.可观测:配置 SLS 日志
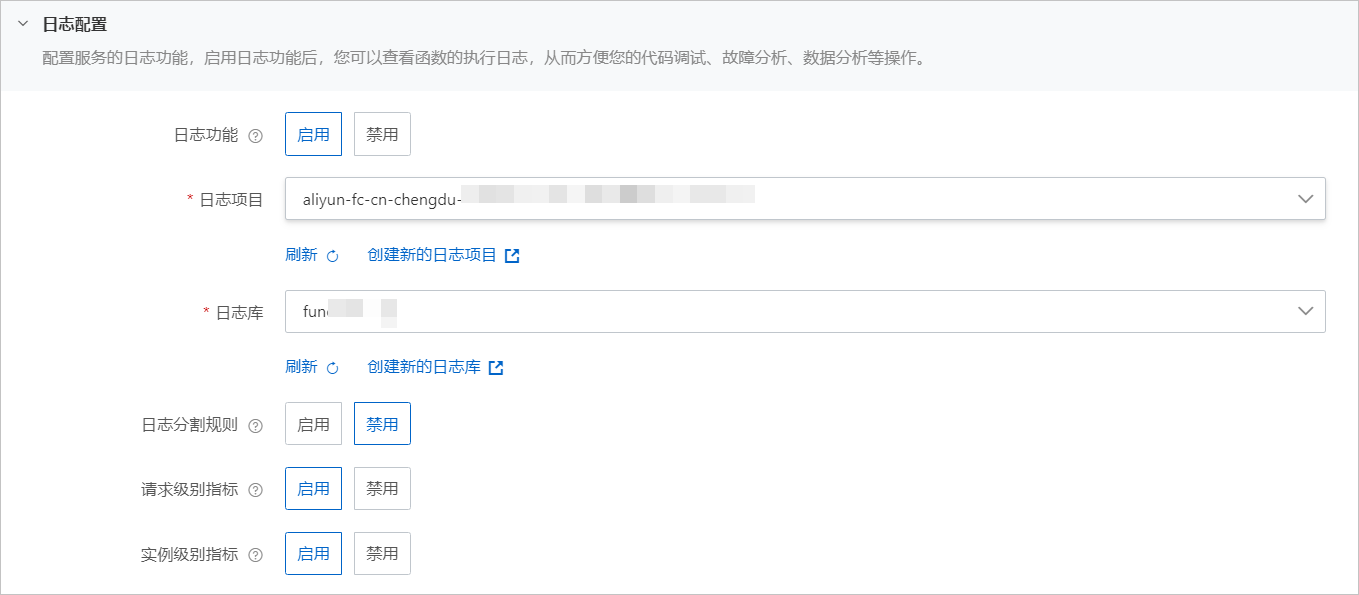
SLS 是阿里云提供的日志类数据一站式服务。我们可以通过在函数对应的服务中配置 SLS 日志项目和日志库,函数实例执行过程中的输出就可以记录到配置的日志库中。之后可以通过函数计算控制台、 SLS 的控制台都可以对这些内容进行查看。
函数计算服务配置日志的详细内容,请见文档。以下给出简要步骤。
- 在服务配置中确认日志功能已启用
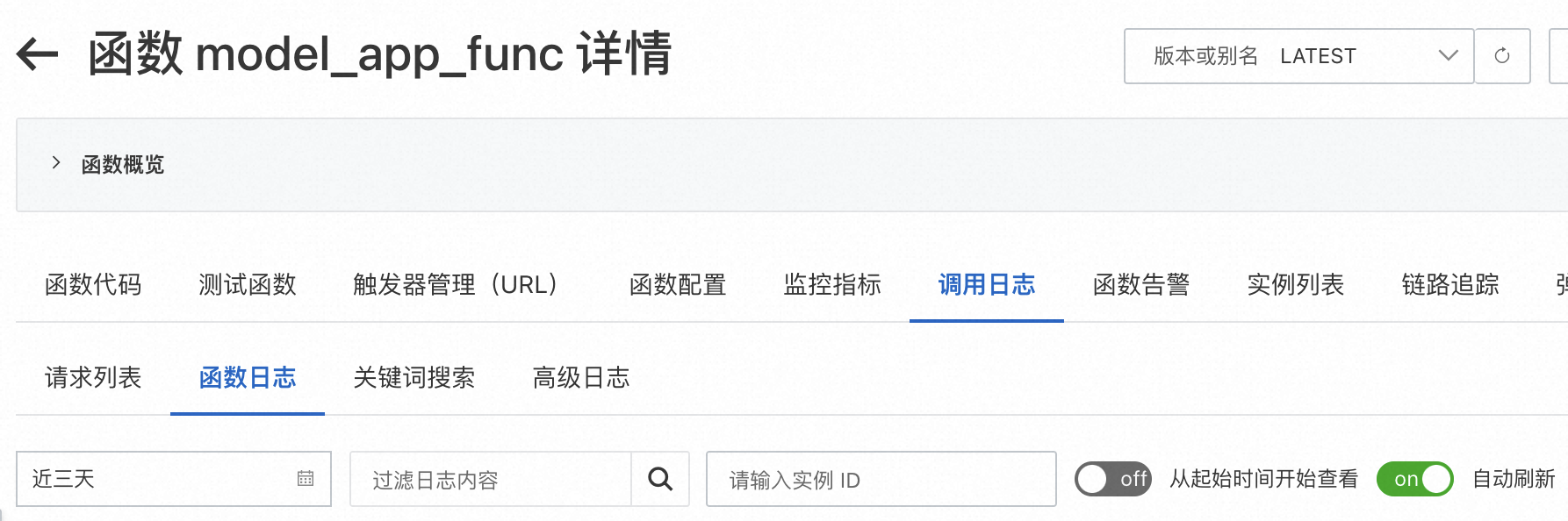
- 在函数详情中,“调用日志”选项卡查看函数维度的日志、请求维度的日志、容器实例维度的日志。

b. 可观测:如何查看监控
函数计算平台记录了多个层次的监控指标,我们可以通过控制台进行查询。
一方面,我们可以通过控制台左侧“高级功能”、“监控大盘”进入,在大盘页面下方依次选择服务名称、函数名称,查看不同层次的监控汇总信息。有关监控指标详细信息请见文档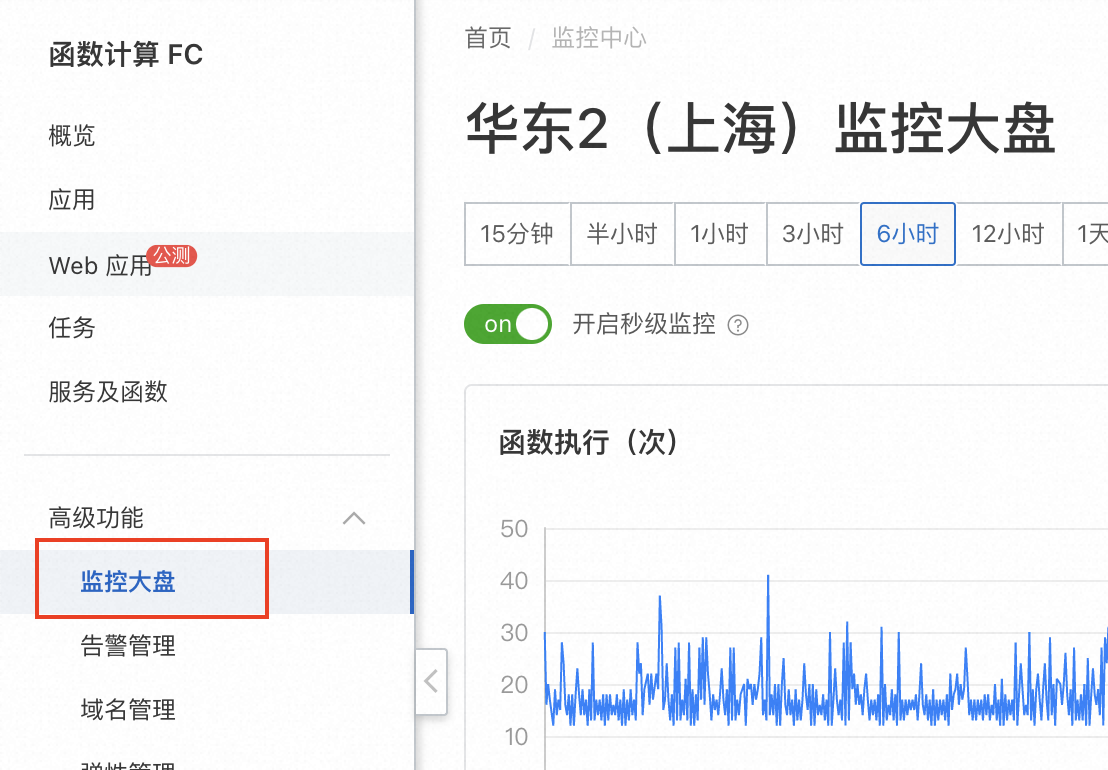
另一方面,我们可以在函数详情“监控指标”选项卡中,直接对函数自身相关的指标进行查看。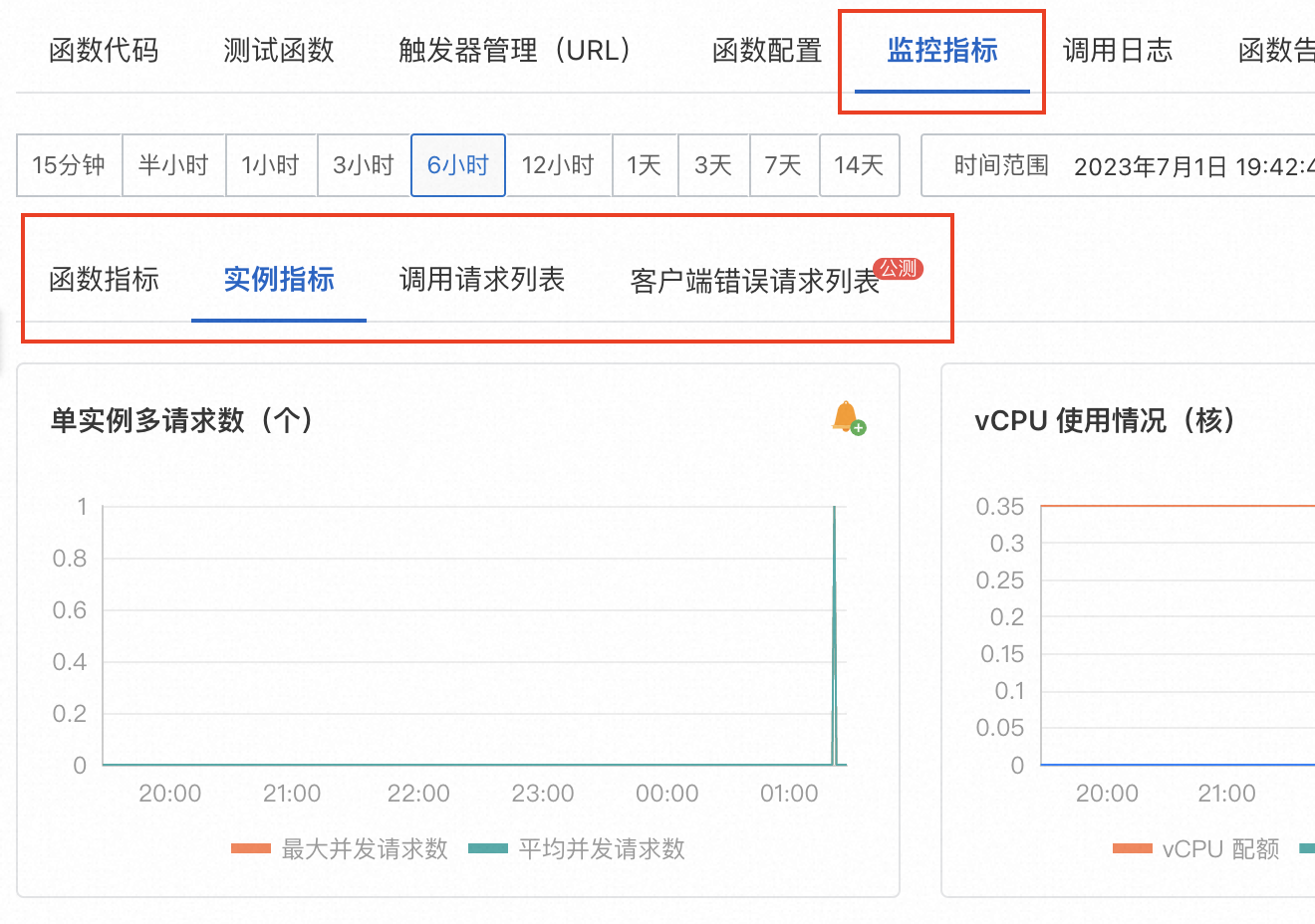
最后,我们可以在函数详情"调用日志"选项卡中,查看函数运行的相关日志。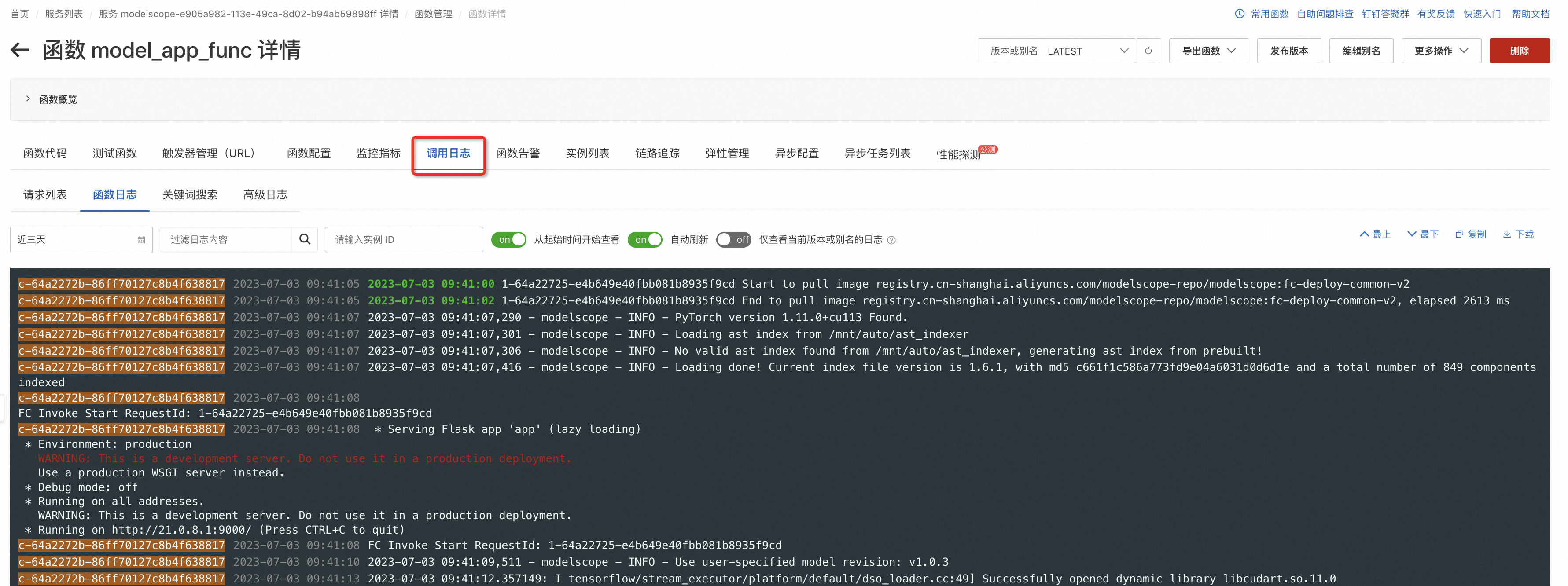
c. 可观测:如何命令行调试
我们也可以通过函数计算控制台函数详情的“实例列表”选项卡,使用“登录实例”功能进入到函数实例里面,通过直接的交互对执行环境、函数行为进行调试。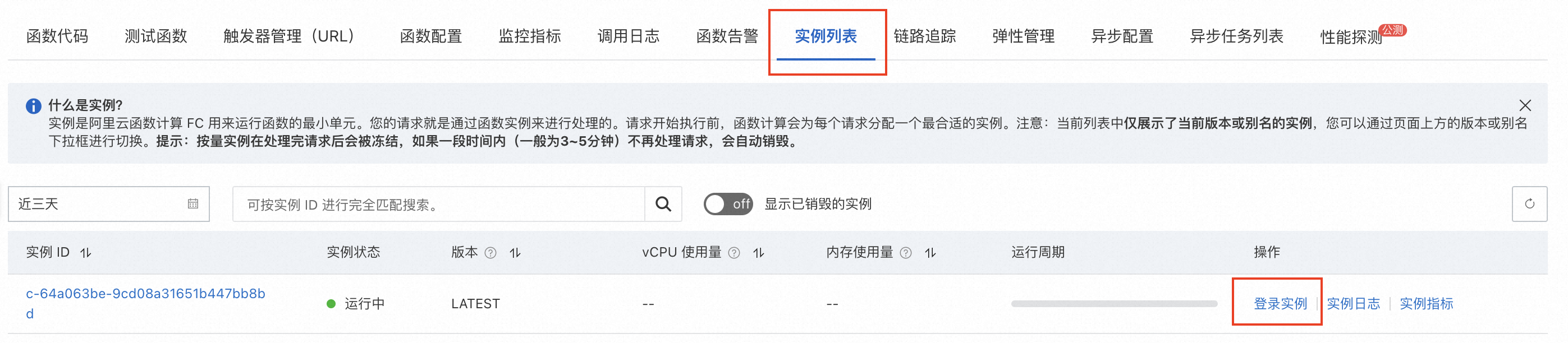
如果当前“实例列表”为空,可以通过测试调用触发函数计算平台新弹出一个实例。
登陆 GPU 实例后,小明就可以执行相关的 shell 命令了#
Tips:需要注意的是,登录实例的过程中,函数实例处于活跃状态,和调用函数采用相同的计量规则。为避免忘记关闭会话而意外产生费用,通过控制台进行命令行操作时,会话默认会在空闲10分钟之后断开连接。如有需要,可以通过执行例如top来进行保活。
小明想让模型跑在不同的 CPU/GPU 上,在 FC 上应如何设置呢?
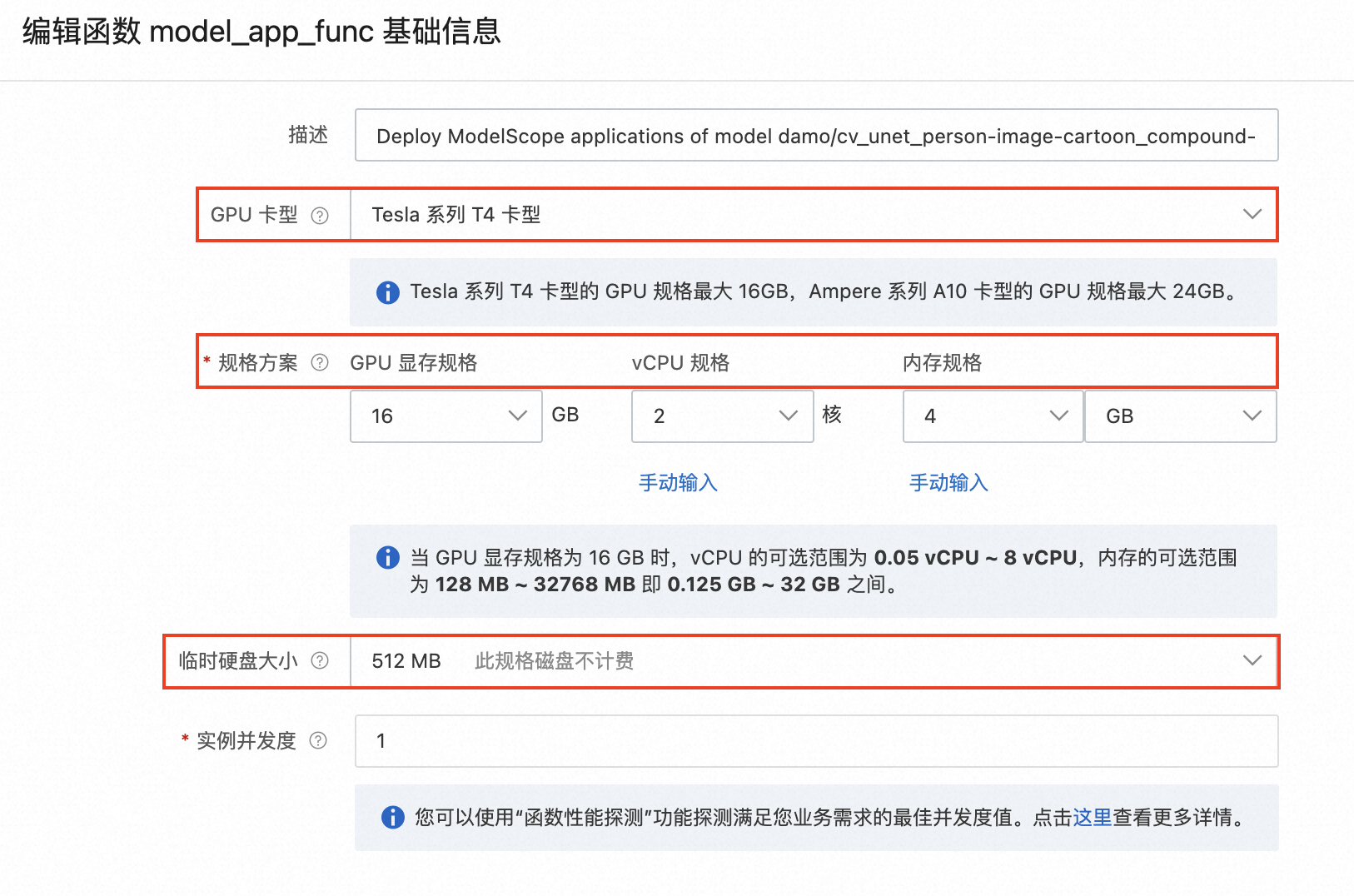
如果我们通过监控指标发现函数实例的资源使用较为饱和或者空闲,可以在“函数配置”选项卡上,对函数的资源规格进行配置,包括CPU/磁盘/内存/显存等。
特别地,对于GPU函数,我们可以通过切换GPU卡型,还提升单个函数实例最大可配置的显存大小(T4最大16GB,A10最大24GB)。关于GPU函数的更多信息,可见文档。
- 查看函数当前配置
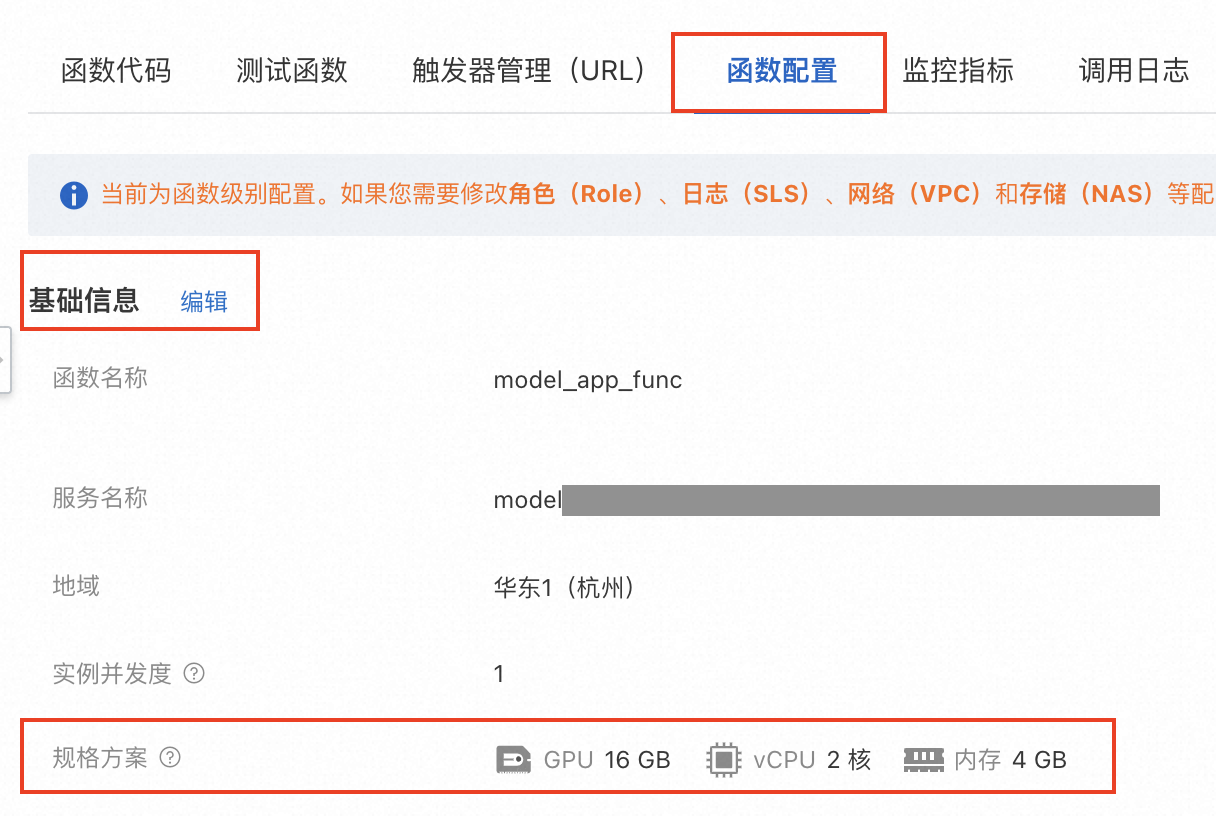
- 编辑函数基础信息
小明调优后的模型可以批量推理,在FC上应该如何设置呢?
函数计算平台在收到一个推理调用请求后,会判断现有函数容器实例的并发度是否够用,决定是否将该推理调用请求转发给现有函数容器实例来处理,还是新弹出一个函数容器实例处理该请求。
单个函数容器实例同时能处理的调用请求数为函数实例的并发度。如果应用本身能够同时处理多个请求,相比默认的1并发度,可以减少函数的冷启动次数。
建议根据不同应用场景的需要,选择不同的并发度配置。
- 计算密集型的推理应用:建议GPU函数实例的并发度保持默认值1。
- 支持请求批量聚合的推理应用:建议GPU函数实例的并发度根据能同时聚合的推理请求数量进行设置,以便批量推理。
我们可以在编辑函数的“基础信息”过程中,调整函数实例的并发度。
特别地,对于GPU函数,默认情况下,无论Tesla系列T4卡型、还是Ampere系列A10卡型的GPU实例,单个阿里云账号地域级别的GPU物理卡上限为10卡(示例请见文档)。在高并发场景下,如您有更高的物理卡需求,请加入钉钉用户群(钉钉群号:11721331)申请。
小明完成了函数计算新手村课程,对小明还要其它嘱咐嘛?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 每日一题----删除指定数字
- JavaScript之ES6新特性03
- STM32使用中断方式进行USART数据收发以及printf函数的重写
- Python连接打印机:实现自动化打印的利器
- 认识Linux指令之与时间相关的指令
- [DevOps-01] DevOps介绍
- Linux学习第一天(常见指令)
- 【Mybatis】深入学习MyBatis:CRUD操作与动态SQL实战指南
- KBU808-ASEMI适配高端电源KBU808
- 双括号初始化