高性能计算HPC笔记(一):概论
学习自:
B站北京大学Linux俱乐部:https://space.bilibili.com/3461562830424779
学习视频:北大未名超算队 高性能计算入门讲座(一):概论
概论
基本工具
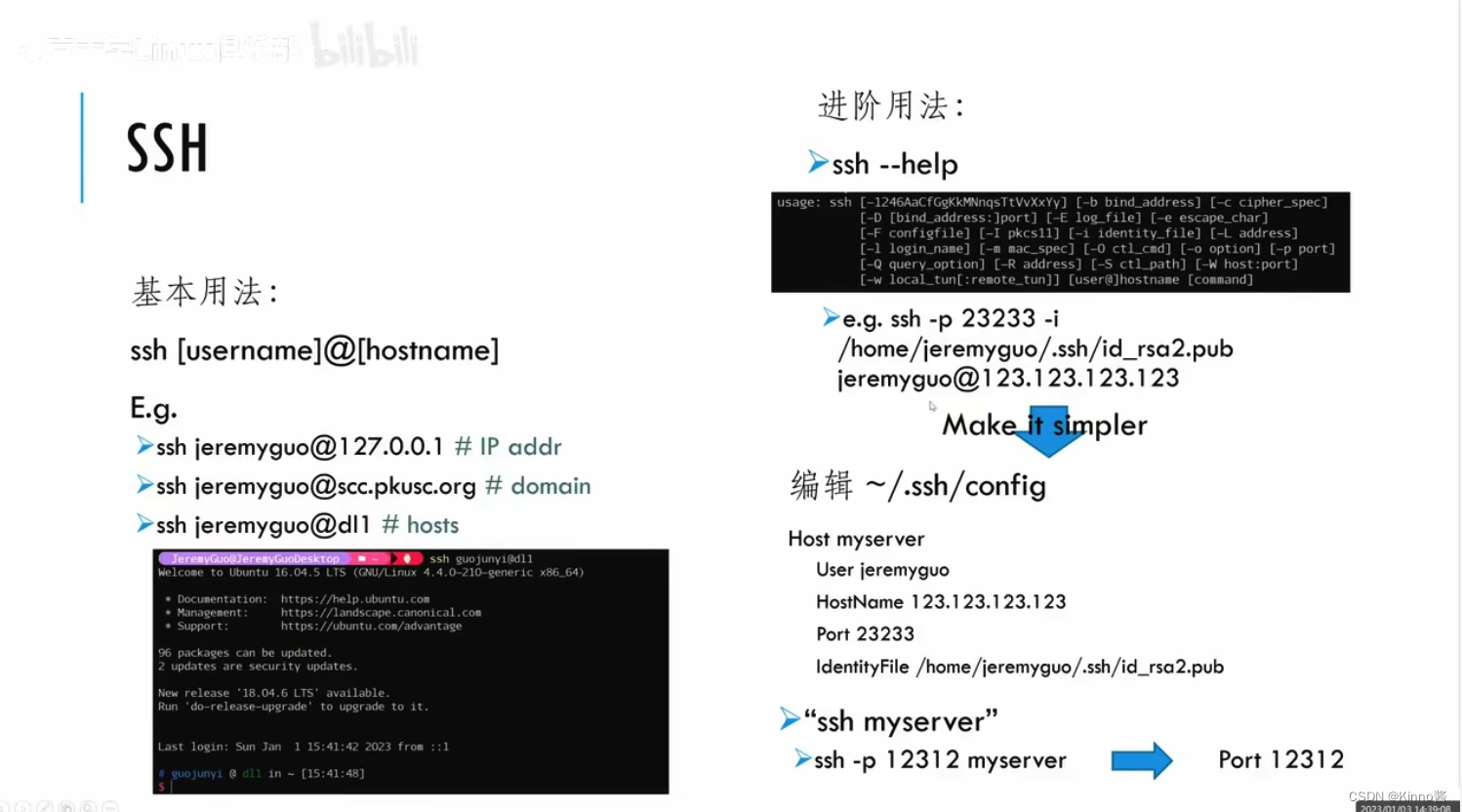
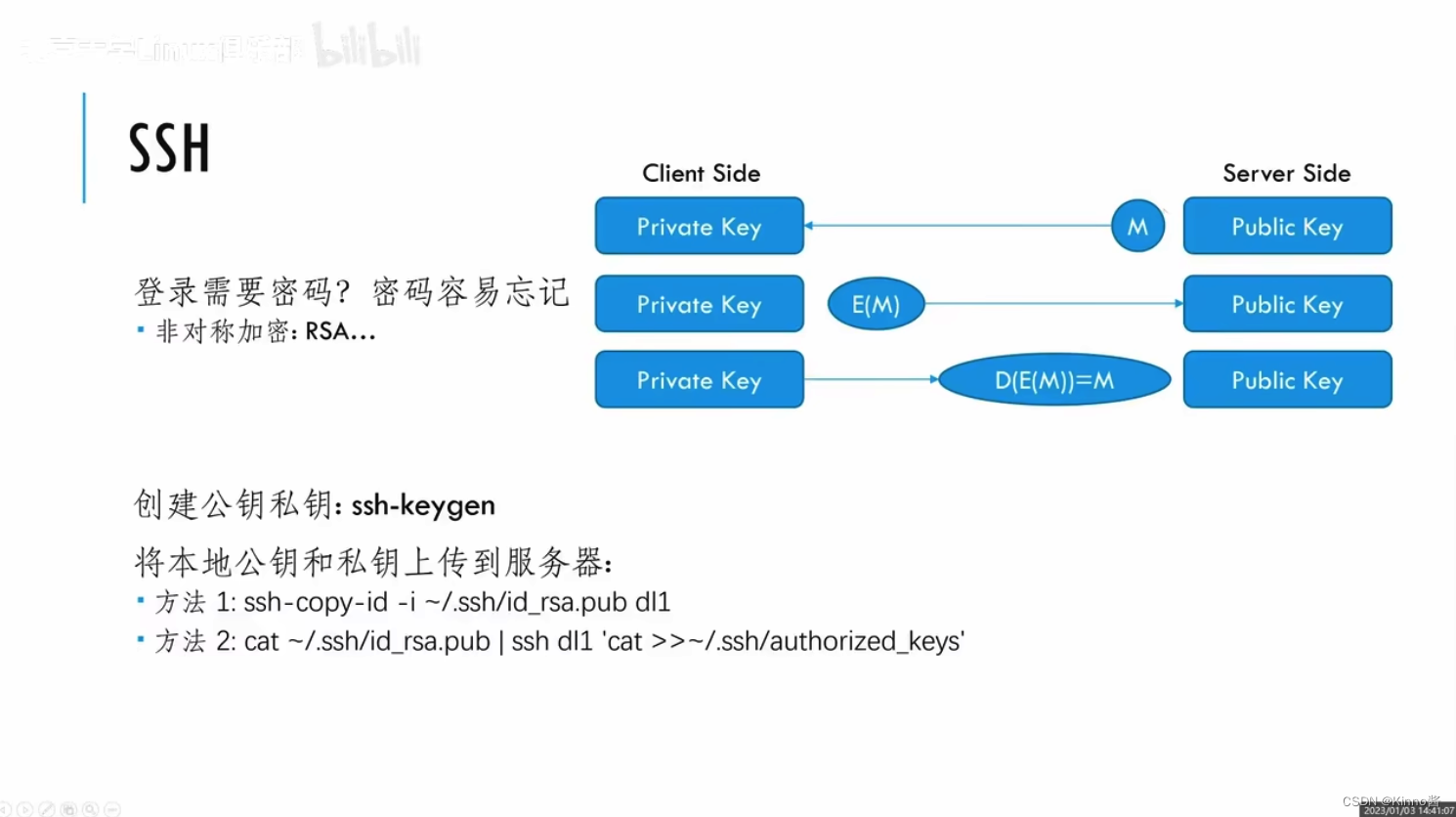
这里PPT中有个问题:客户端只上传公钥给服务器,私钥是自己保留的。

开发工具
概念
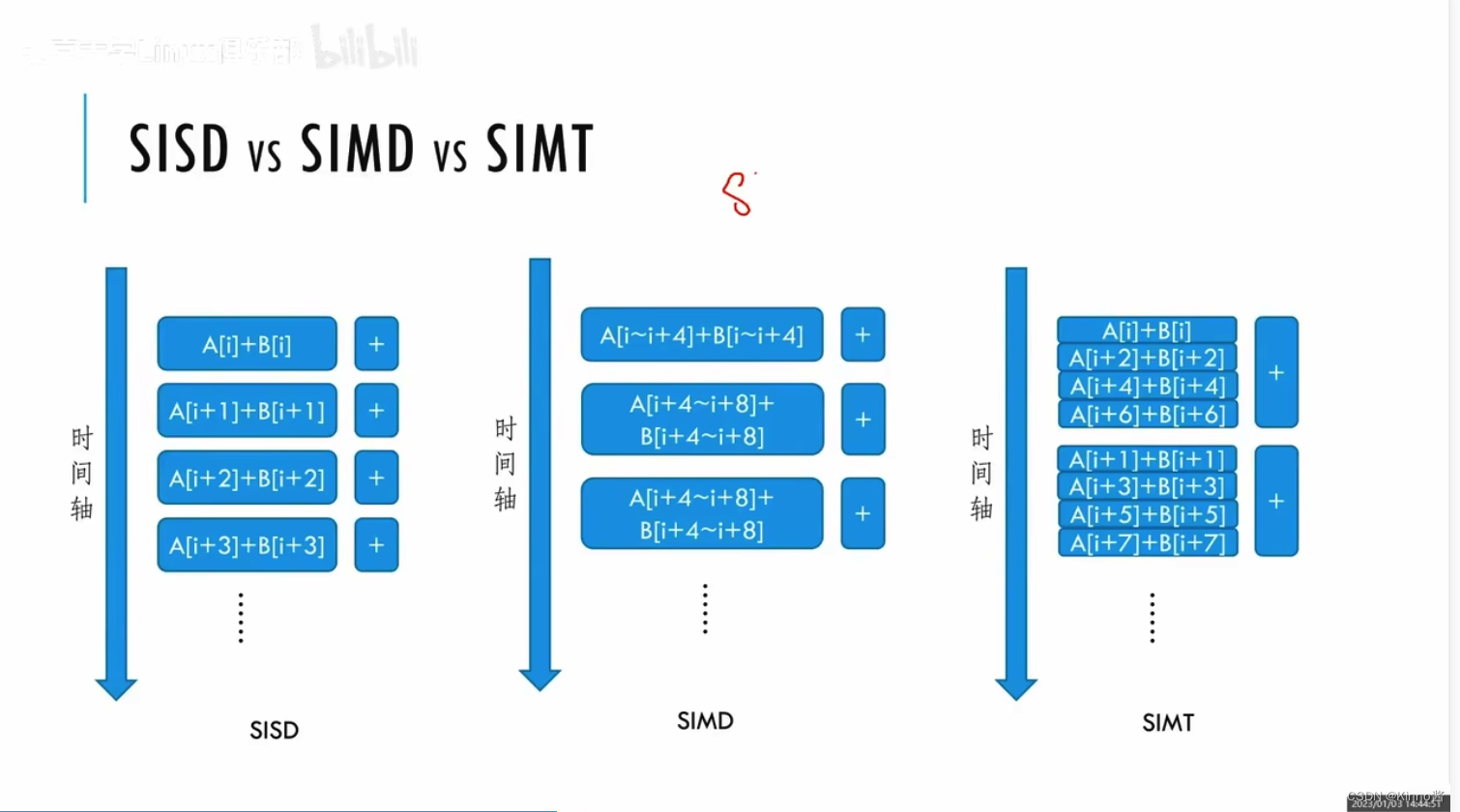
SISD:用一个线程去执行一条指令。
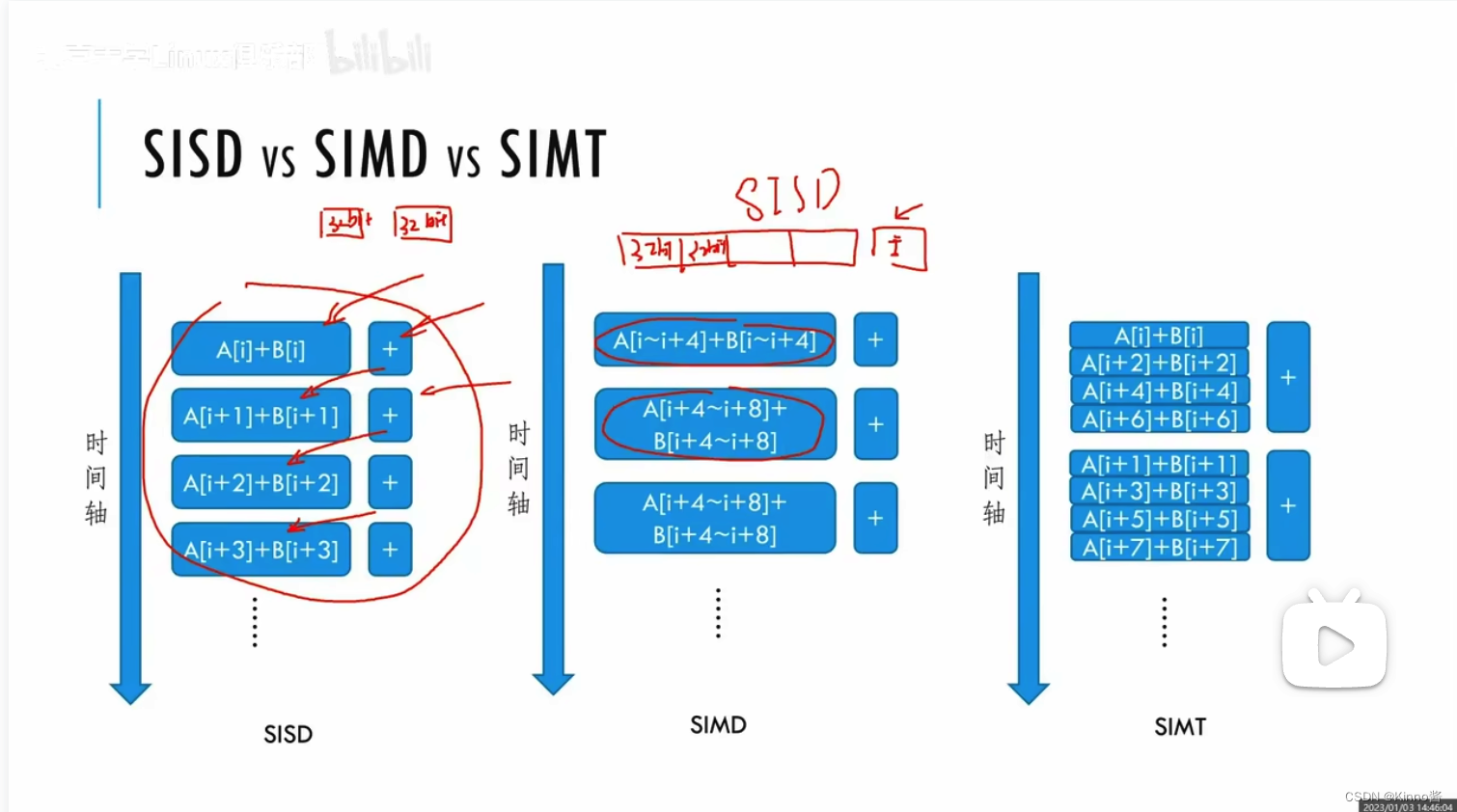
SIMD:使用单个instruction来操作多条数据(vector化),会共用一个很长的唯一运算器。

SIMT:开发起来更自由,一条指令执行的运算器来自于不同的硬件,取的内容的地址位置可以在任何地方


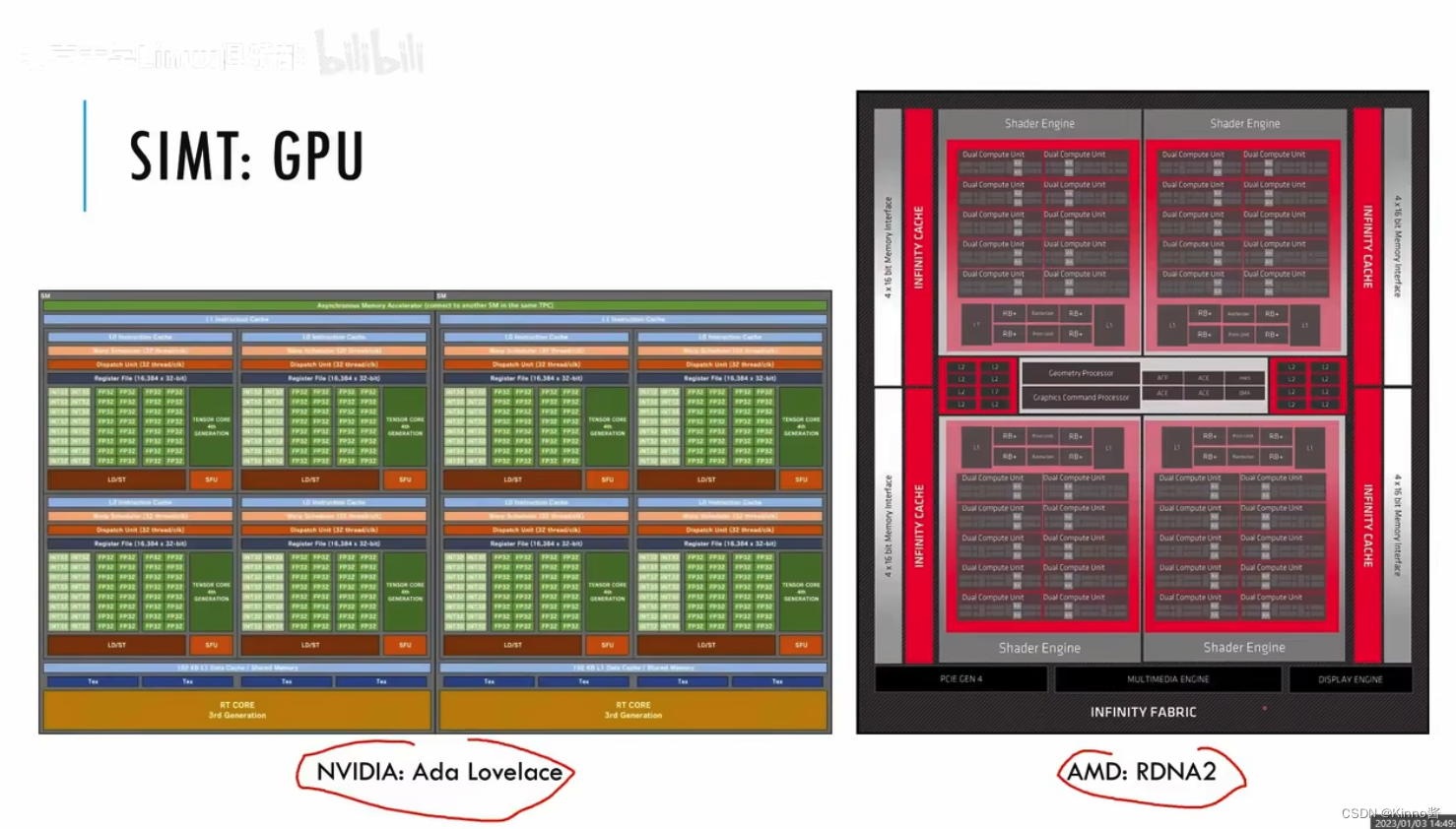
一个instrcution指令调用不同的运算器

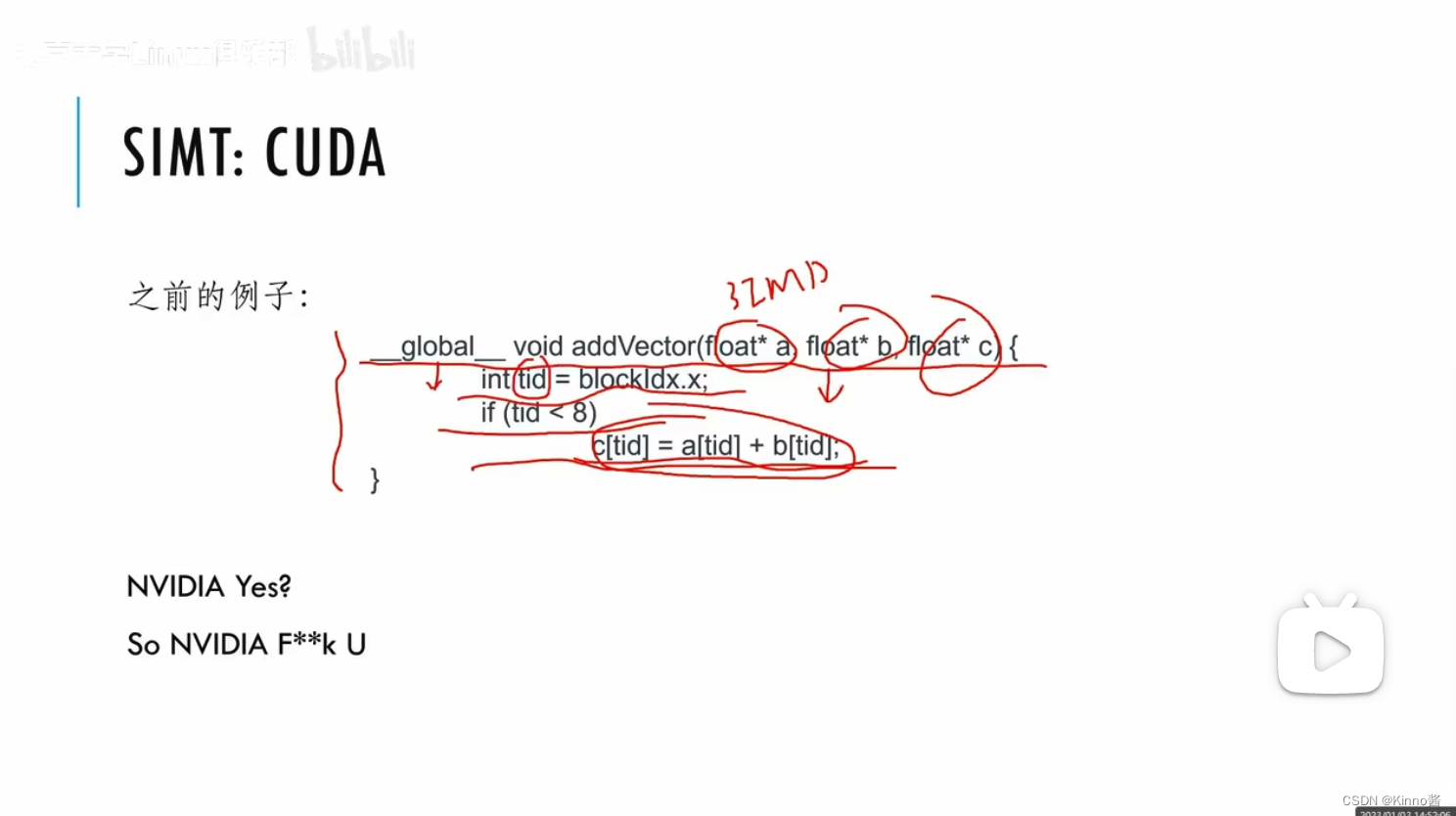
用GPU做运算,把这里看为8个并行在做的事情,每一个流拿的tid不一样

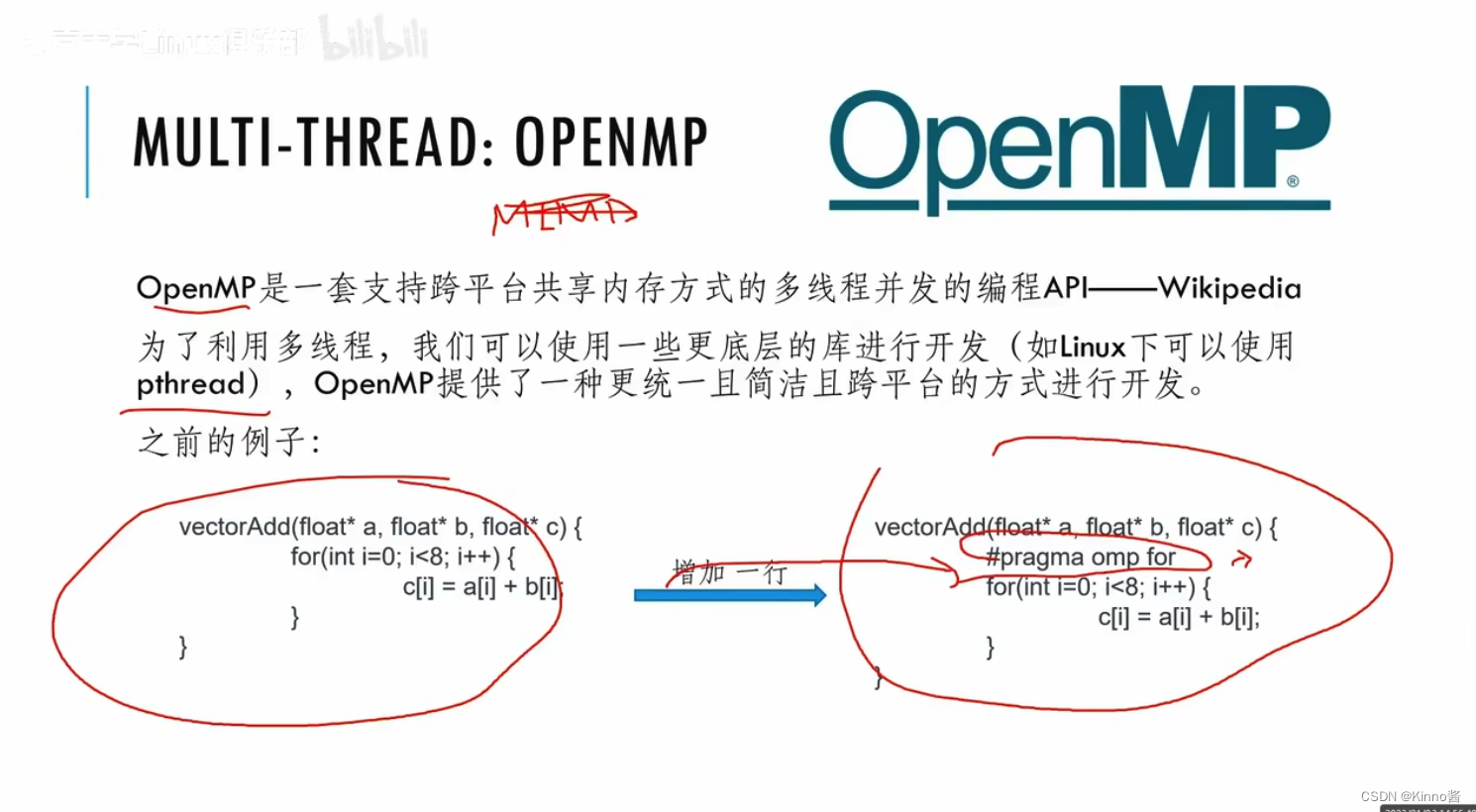
用CPU做MIMD开发,加一行与编译指令就可以实现并行。
性能调优
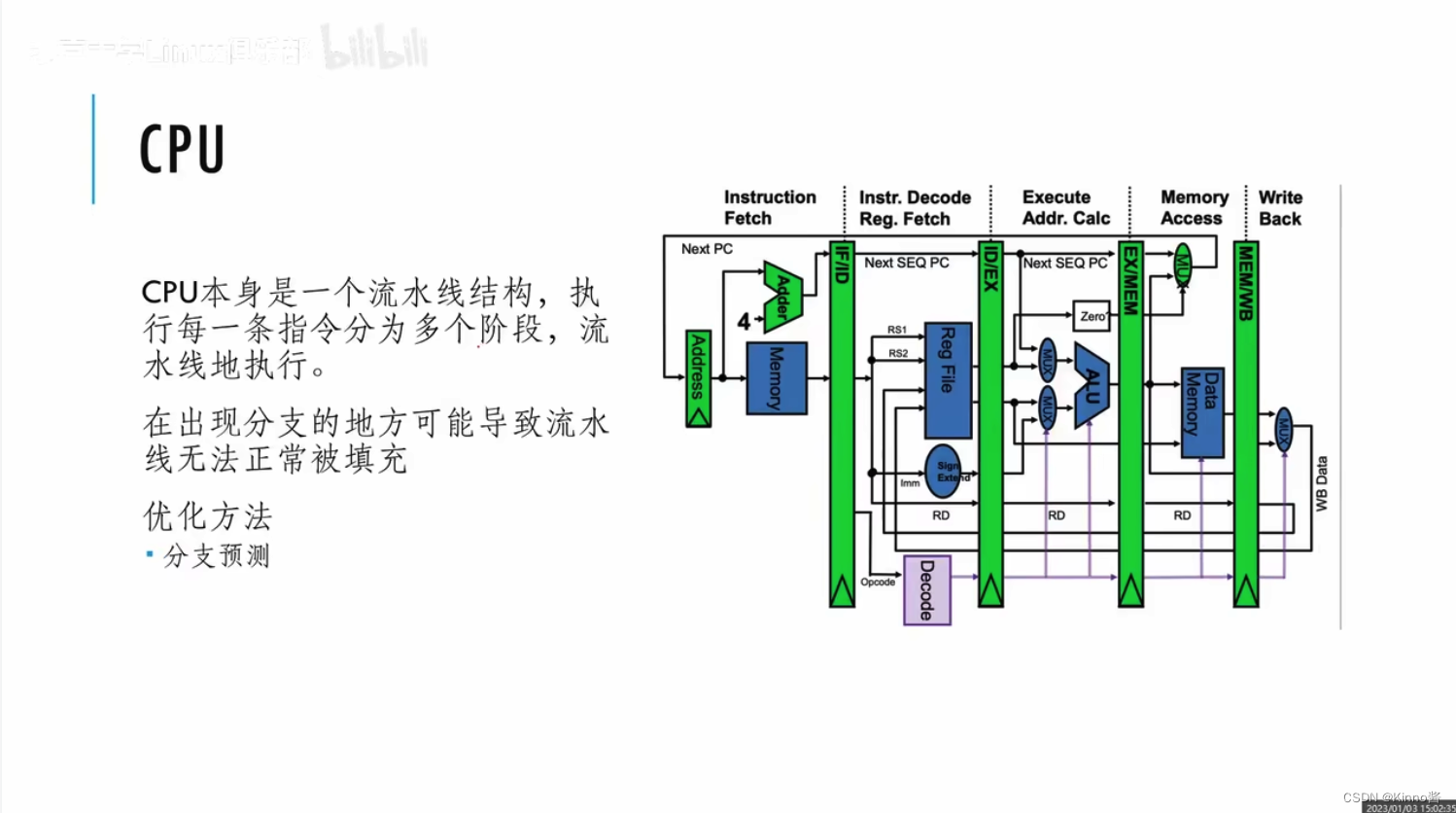
CPU执行前一个指令时,下一个指令可能已经开始预取了(准备工作),吞吐提高。(但是if-else分支走向会影响预读取数据),可以让CPU预测走哪个分支的概率大。
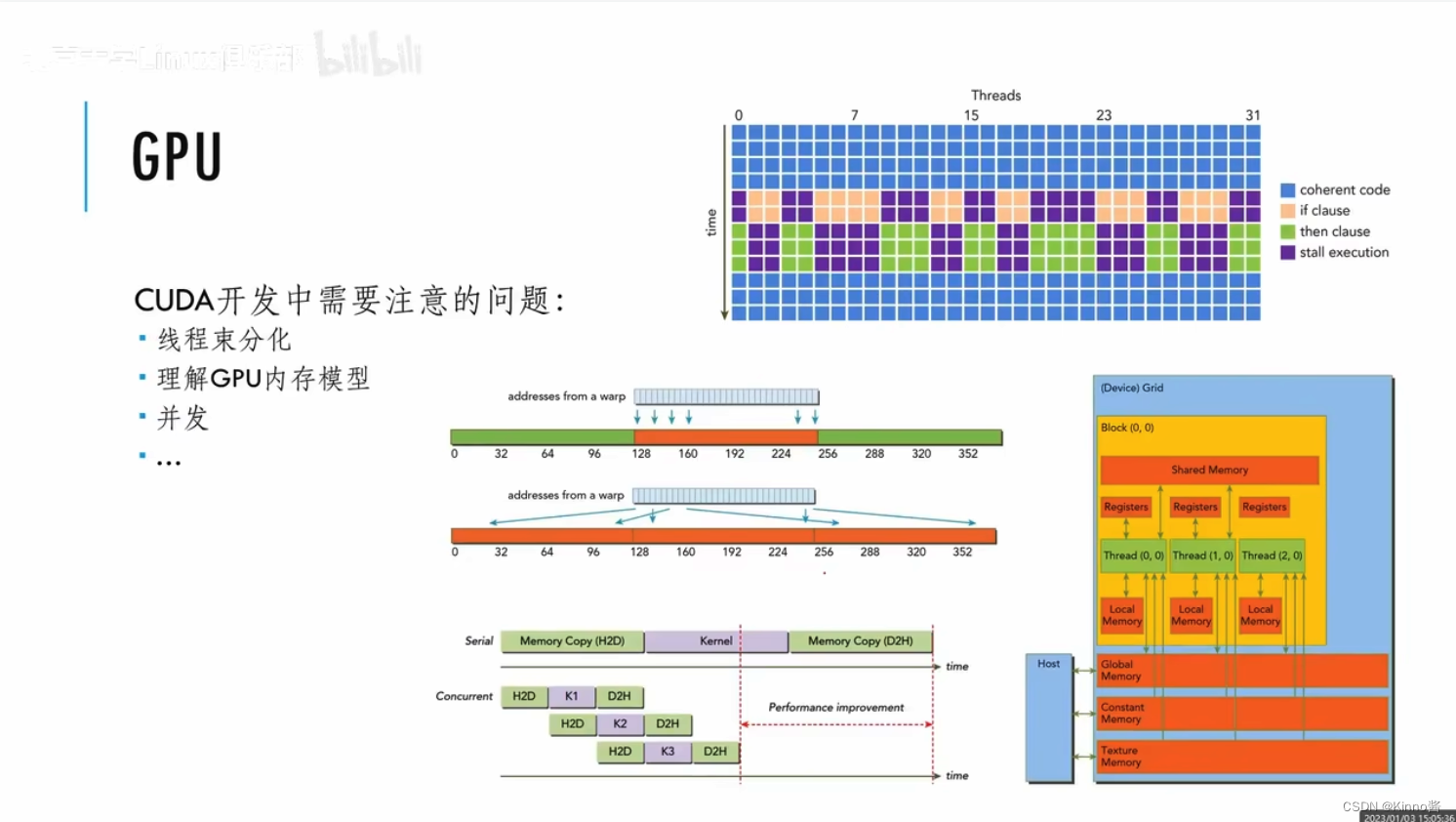
线程束分化:写两个线程,这两个线程执行一样的代码,但是数据不一样
GPU只有一个instruction器,遇到这种情况,GPU会比CPU更慢
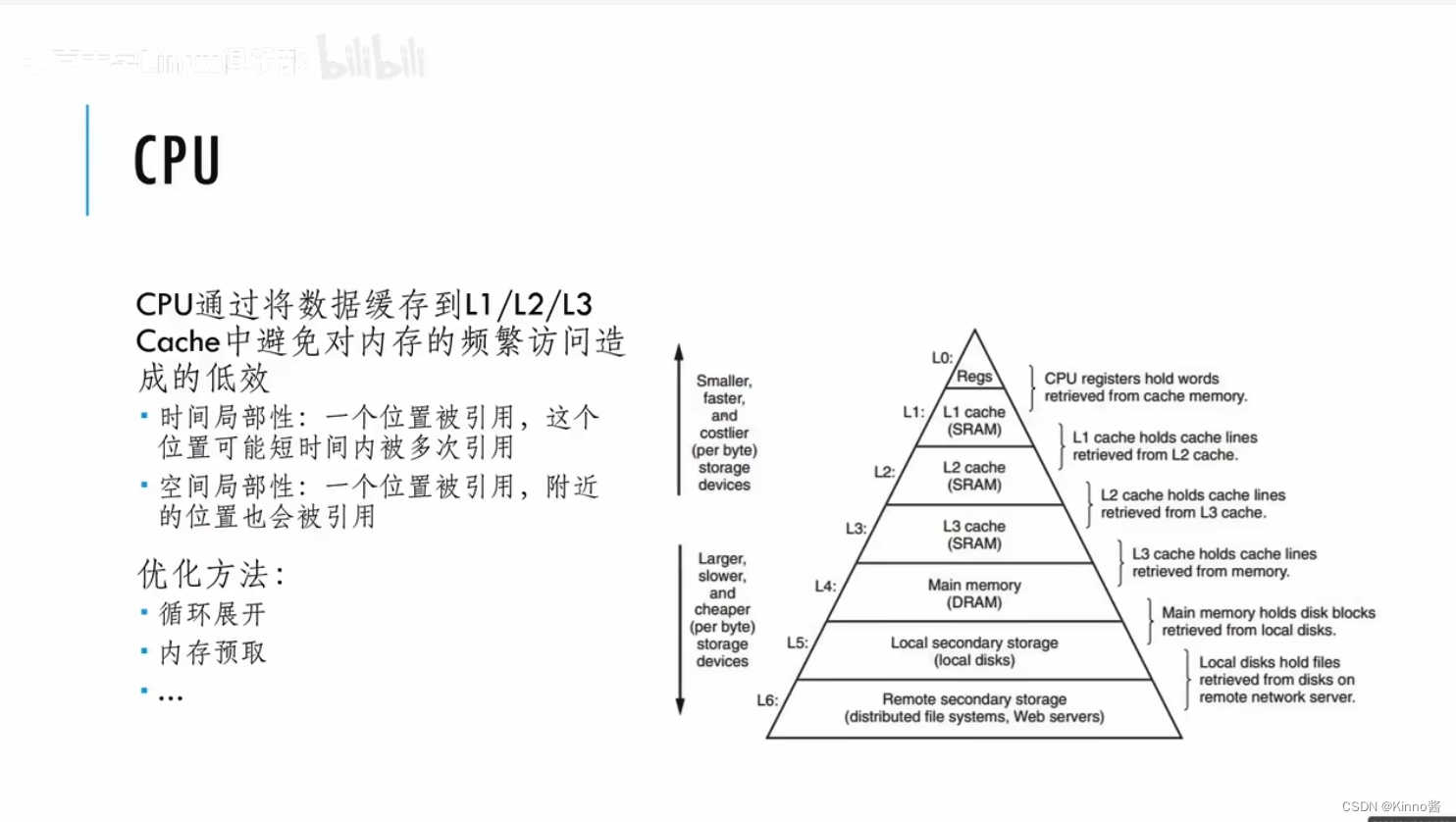
CPU里最快的是寄存器,CPU的程序具有局部性,在CPU上是线性排列的。
GPU里有很多作用不同的内容,速度也不同,SIMT可能会在执行一条指令时用到各种不同位置的内存,内存地址差异过大一次读不完的话,会极大的浪费内存的带宽。要考虑多个内存之间怎么去访问内存,怎么在GPU里把数据很好的布局。
并发:首先要把数据拷贝到GPU,然后启动GPU的kernel,最后把GPU的执行结果拷贝到主存上。改进:并发,把每个阶段分为3份,在拷贝完1/3的数据后,就对前1/3的数据进行处理。流水线化。
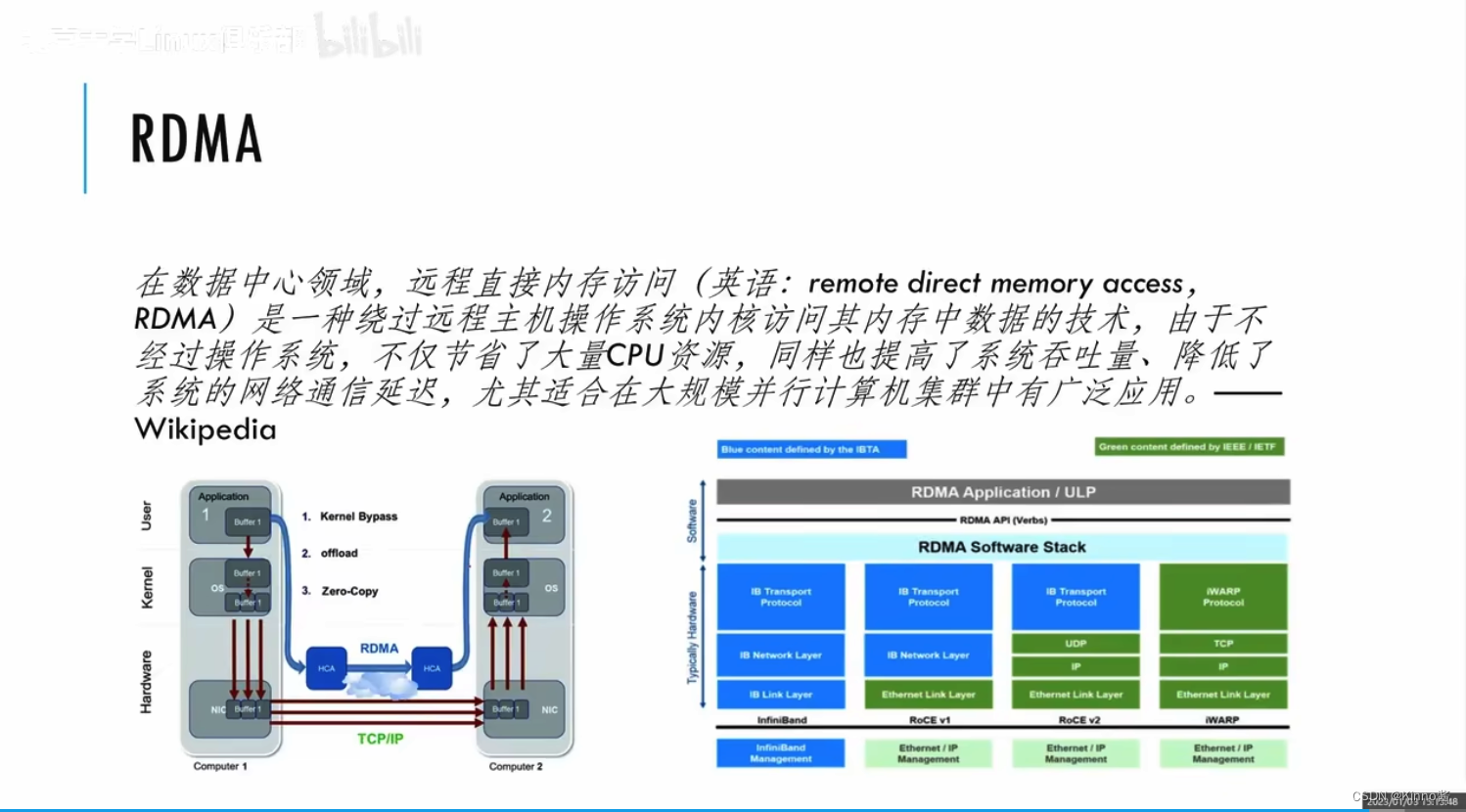
传统的数据中心网络是通过网卡连接,当有数据报到达后,网卡把数据DMA到主存中,发中断给CPU,让CPU对拷贝过来的数据报文通过协议去处理。这会把CPU浪费在不必要的报文处理(如:TCP/IP协议栈)。通过RDMA可以把CPU绕开
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Spring系列学习七、Spring的高级特性
- 记edusrc一处信息泄露登录统一平台
- 管理篇 - 19到23
- 【算法设计与分析】——动态规划算法
- 5.MapReduce之Combiner-预聚合
- 企业常用的几种实用的加速FTP传输方式
- 【我的2023】一个48岁码农的不堪回首一年。
- 爬虫入门与urllib&requests
- 网络通信实战小项目:linux系统下实现服务端与客户端的通信
- JVM性能调优辅助手册之JVM指令