mysql中的事务和索引
1. 索引
????????索引:index(下标)->目录
????????索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引, 并指定索引的类型,各类索引有各自的数据结构实现。
1.1?索引的作用
????????MySQL 索引是一种数据结构,用于加快数据库查询的速度和性能,数据库是把数据存储在硬盘上的;
????????MySQL 索引的建立对于 MySQL 的高效运行是很重要的,索引可以大大提高MySQL 的检索速度。
? ? ? ? 举例说明:
- MySQL 索引类似于书籍的索引,通过存储指向数据行的指针,可以快速定位和访问表中的特定数据。
1.2 索引的使用场景?
????????创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为WHERE 子句的条件)。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。索引虽然能够提高查询性能,但也需要注意以下几点:
????????1、索引需要占用额外的存储空间。
????????2、对表进行插入、更新和删除操作时,索引需要维护,可能会影响性能。
????????3、过多或不合理的索引可能会导致性能下降,因此需要谨慎选择和规划索引。
????????满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
1.3 索引的使用
????????创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约(FOREIGN KEY)时,会自动创建对应列的索引,接下里我们来学习一些索引的基本操作和使用
1.3.1?查看索引
????????Show index from?
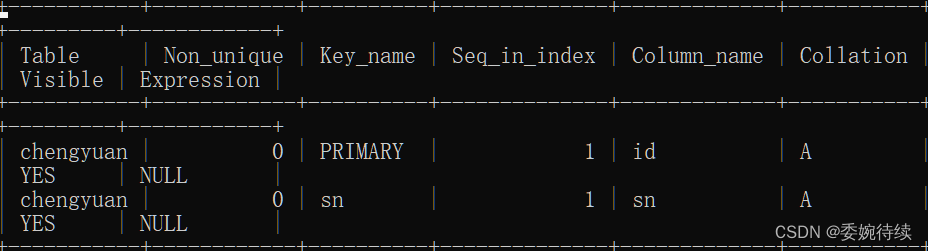
show index from chengyuan;? ? ? ? 结果如下:我们将显示之前创建的成员表的所有索引(其中下图表一和表二是一个图);
表一:
表二:
? ? ? ? 由此可以看到,执行上述显示表的所有索引命令后,将会显示指定表中所有索引的详细信息,如:索引名称(Key_name)、索引列(Column_name)、是否是唯一索引(Non_unique)、排序方式(Collation)、索引的基数(Cardinality)等

? ? ? ? ?注意:
????????Mysql中的primary key和unique和foreign key都会生成自动索引。这几个操作都会频繁涉及到查询。
????????一个表的索引,可以有多个。每个索引,都是根据某个具体的列来展开的。后序按照这个列来查询,这个时候才能提高效率。(类似于同一个字典,有很多个目录,拼音,笔画,偏旁部首)
1.3.2 创建索引
????????Create index 索引名 on 表名(列名);//那个表的那个列
????????对于非主键、非唯一约束、非外键的字段,可以创建普通索引,使用 CREATE INDEX 语句可以创建普通索引。普通索引是最常见的索引类型,用于加速对表中数据的查询。
create index index_chengyuan_id on chengyuan(id);????????结果如下:
表一:
表二:

? ? ? ? 注意:
? ? ? ? 创建操作是一个比危险的操作。如果表数据时空着或者比较少,此时创建索引就没有关系。
如果表本身有很多数据,此时常见索引,就会出发大量的硬盘io;
1.3.3 删除索引
????????Drop index 索引名 on 表名;
drop index index_chengyuan_id on chengyuan;? ? ? ? 以上操作就是删除我们刚才创建的index,结果如下;
? ? ? ? 产看当前表的索引:
表一:
表二:


1.4 索引保存的数据结构?
????????Q:DICENG索引底层数据结构的实现?
????????A:1、索引其实就是通过额外的数据结构,来针对表里的数据进行重新组织,使用啥样的结构,对于查询的时间和表占用的空间都有很大的影响的。且顺序表,链表,栈,队列(不适合进行查找)
? ? ? ? 2、因此,数据库的索引使用了一个B+树作为数据结构---->B+树,相当于是针对数据库这个场景,量身定做的。学习B+树之前首先了解B树,即B-树(-是连字符,不是减号,因此不读B减树)
1.4.1?B树
????????B树是一个N叉搜索树(要求这里是有序的),就是在二叉搜索树里面进行了扩展(一个节点可能包含n个值,n个值划分出了n+1个区间。)下图是B树的数据结构;
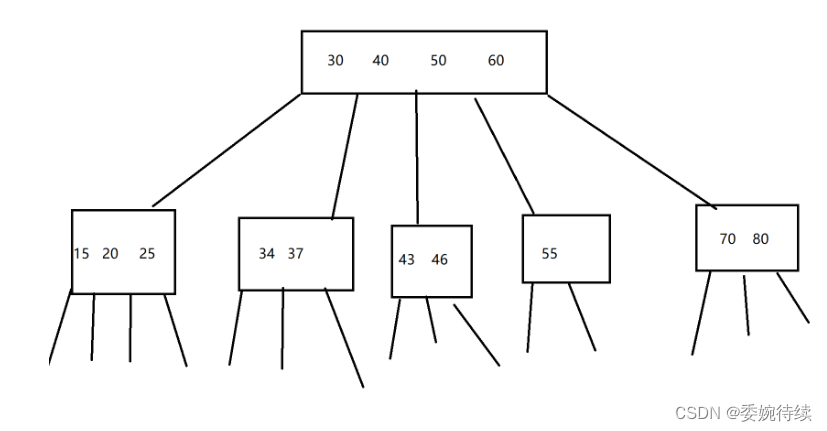
? ? ? ? 即同样高度的树,相比于二叉搜索树来说能表示的值会跟多。
? ? ? ? 我们在使用b树来查询的时候,虽然比较次数比二叉搜索树多。但是,这里的关键在于,同一个节点的这些key都是一次硬盘io就读出来的。所以即使总的比较次数增加了,但是硬盘io的次数就少了(一次硬盘io相当于内存中惊醒1w次比较)
1.4.2?B+树
????????在B树的基础上,我们引入了B+树同样是n叉搜索树,每个节点包含多个key,n个key划分出n个区间(每一个节点的key会在左下方的key的最右边显示出来),B+树的数据结构图如下所示:
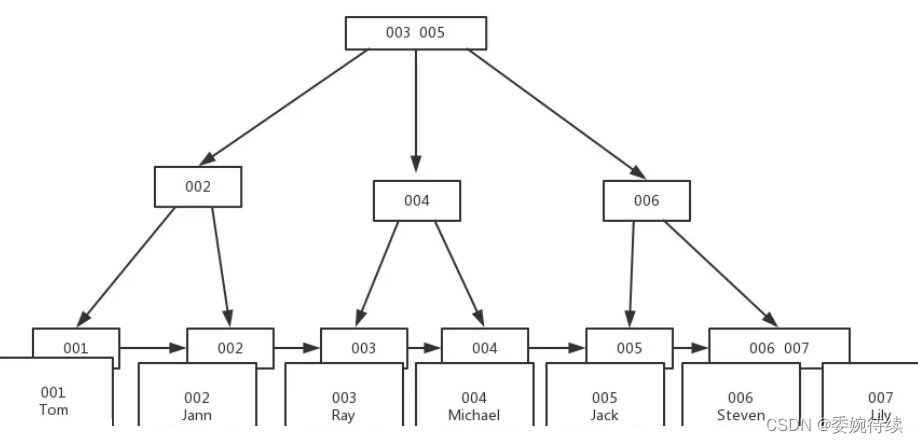
????????B+树的特点:
- n叉搜索树,每个节点上都包含n个key,n个key划分出n个区域
- 每个节点的n个key中,会存在一个“最大值”(设成最小值也一样)
- 每个节点的key都会在子树中重复出现。(好处:所有的数据都会包括在叶子结点的数据中)
? ? ? 4.把叶子节点使用链式结构相连。(此时我们进行范围查询就会十分方便)
????????优点:
- 如果没有这一个链式列表结构,就可能需要反复的对树进行回溯
- 针对B树查询,b+树的查询时间是比较稳定的。查询任何一个元素,都是需要从根节点查询到叶子结点的,过程中经过的硬盘io次数是一样的(b树,有时候的硬盘io多,有时候少,不稳定)
- 按照上述结构来存储的话,只需要在叶子结点来存储,其他的非叶子节点只存储key,这个key十个整数,占用空间是比较少的。一个key才4个字节,100w个key才是4mb,这些非叶子节点的数据,是可以缓存到内存中去的,这个时候我们在进行查询的时候,可以只进行内存的比较了,大幅度减少了硬盘的io次数.
2. 事务
2.1 事务的概念
????????事务就能让多个执行语句要么都执行成功,要么语句都执行失败。(其实是执行了,但是数据恢复的时候,将之前执行的数据恢复了---此行为叫回滚rollback)
????????事务的原子性本质上是依托于回滚机制的。通过回滚到机制把数据恢复到之前的状态。
????????数据库对于事务治理有特殊的机制(undo + redo log)通过日志,printin,写到文件里记录之前的数据,进行的操作。
????????数据库中间挂了,但是日志保存下来了,等到数据库重启之后,读取之前的日志,看看是否有执行了一半的事务,如果有,将之前执行过的数据进行回滚。
????????虽然事务让数据变得更加靠谱,但是付出了巨大的执行效率代价。
2.2?事务需要满足的四大条件
- 原子性,通过事务,把多个操作打包到一起(事务最重要的特性)
- 一致性:相当于原子性的衍生,当数据库中出现问题了,不会产生向上述这种“钱凭空消失”这种不科学的现象,另一方面,还通过约束,来避免出现一些非法的情况。
- 持久性:事务人核对修改都是持久化存在的(写入硬盘的),无论是重启程序、还是重启主机、修改都不会丢失。(数据库本身就是为了持久存储)
- 隔离性:多个事务并发执行的时候,可能会带来一些问题,通过隔离特性来对这些问题进行权衡,看你是希望数据尽量准确,还是速度尽量快。
2.3 多线程与事务
????????多线程:属于是“并发编程”中的一种典型实现方式。
????????如果多个客户端,同时给服务器数据库发送事务请求,这个时候叫做“并发执行事务”
????????如果多个事务修改不同的表,问题不大;如果是修改相同的表,就可能产生一些bug。
详细bug如下图所示:
Bug1:脏读问题。
????????当前有两个事务1,2
事务1:修改了某个数据,但是事务本身还没有提交(提交->告诉数据库服务器,完毕)
事务2:读取了同一个数据,此时实务二读到的数据可能是脏的数据,因为事务1后序可能还要再次修改代码
????????解决脏读问题,核心思想降低事务的并发程度,给写操作进行加锁。(意味着释放之前,其他人是不能访问的)-->写的时候不能读,写完之后提交之后释放,才可以让别人读了
Bug2:不可重复读:
????????不可重复读,是在写“加锁”的前提下导致的,虽然写了加锁,但是可以分为多个事务,多次提交的方式来修改数据,虽然没有之前频繁,但是也是可能会出现的
?????? 有事务1,2,其中事务一,先修改数据(加锁),此时事务二读取数据,就需要事务一提交完。等到事务一提交了之后,事务二开始读数据(实务二可能会多次读取数据)
?????? 又来了一个事务3,这就导致事务二两次读取的数据是不一样的(刚刚的规则,写的时候不能读,但没有读的时候不能写),事务二要求两次读到的同一个数据是一样的。
?????? 解决这个问题,就是进行“读加锁”操作,在读的时候不能写,虽然该操作让并发程度降低了,但是准数据的确性就提高了。
Bug3、幻读:
?????? 事务一和二:事务一修改数据,提交,事务二开始读数据;
????????此时事务三,新增了一个其他的数据,所以事务二就可能出现两次读取的“结果集”不同。(查询的时候,有不同的行)
????????解决幻读问题,串行化,不在进行任何并发了,每个事务都是串行执行的(执行完第一个,在执行第二个,在执行第三个)
? ? ? ? 上面问题的解决措施:
Mysql在配置中,提供了“隔离级别”这样的选项,我们可以根据需要,调整隔离级别,适应不同的情况。
- read uncommitted;读未提交,并行程度是最高的,隔离程度是最低的,效率是最高的,数据是不靠谱的,此时不可能出现上述的三个大问题。
- read committed;读已提交,相当于给写加锁,并行程度降低了,隔离程度提高了,效率数据会靠谱一些,此时可能会出现不可重复读+幻读(事务之间,影响越小,就是隔离程度越高)
- repeatable read 可重复读,相当于给读操作和写操作都加了锁,并行程度降低了,隔离程度提高了,数据更靠谱了,效率降低了,此时可能出现幻读。(一般来说,是默认的隔离级别)
- serializable 串行化,让所有的事务都串行化执行,并行程度最低,隔离程度最高,效率最低,数据最靠谱。
ps:本次的内容就到这里了,如果大家感兴趣的话就请一键三连哦!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- js中强制类型转换有哪些,隐式类型转换有哪些
- Linux C获取终端尺寸
- 【DDD分布式系统学习笔记】RPC调用以及系统初步搭建
- 2024第二届中部(郑州) 化工新材料及精细化工展览会
- 酷开科技 | 酷开系统视频模式,高能视频刷不停!
- 【IoT网络层】STM32 + ESP8266 +MQTT + 阿里云物联网平台 |开源,附资料|
- VuePress-theme-hope 搭建个人博客 2【快速上手】 —— 安装、部署 防止踩坑篇
- 【趣味题-06】20240121 三色球
- 探索web技术与低代码开发的融合应用
- MATLAB聚类及给无标签数据加标签