物理机本地和集群部署Spark
发布时间:2024年01月13日
一、单机本地部署
1)官网地址:http://spark.apache.org/
2)文档查看地址:https://spark.apache.org/docs/3.1.3/
3)下载地址:
https://spark.apache.org/downloads.html
https://archive.apache.org/dist/spark/
- 上传文件、解压缩、修改文件名
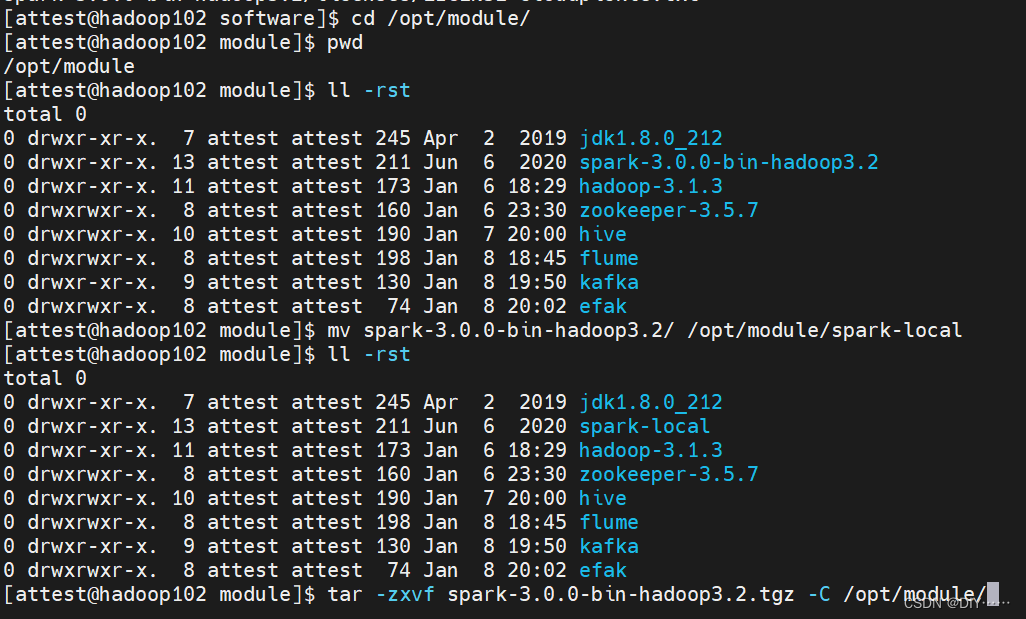
- 启动Spark

- spark-shell使用
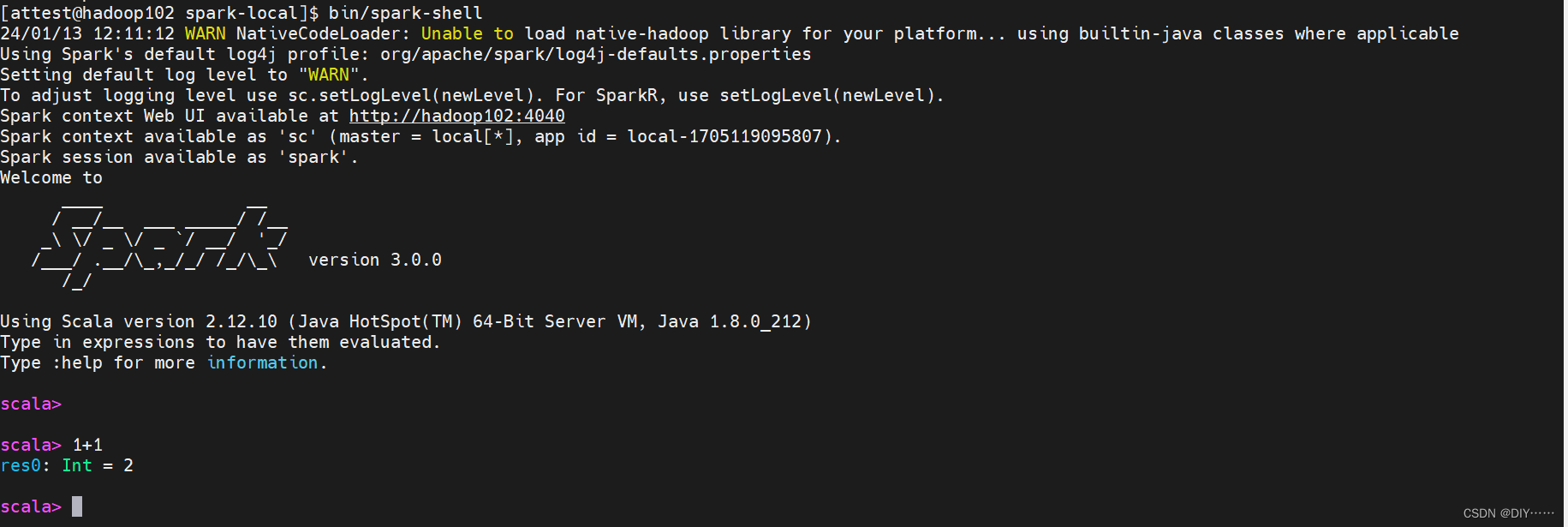
- 入门案例:

注意:sc是SparkCore程序的入口;spark是SparkSQL程序入口;master = local[*]表示本地模式运行。
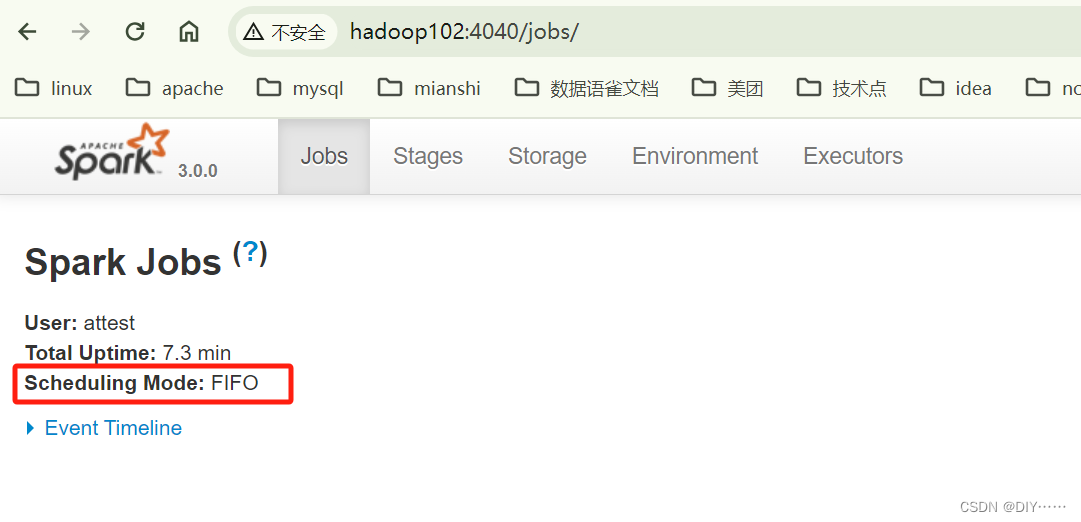
说明:本地模式下,默认的调度器为FIFO。



二、Standalone模式
Standalone模式是Spark自带的资源调度引擎,构建一个由Master + Worker构成的Spark集群,Spark运行在集群中。
这个要和Hadoop中的Standalone区别开来。这里的Standalone是指只用Spark来搭建一个集群,不需要借助Hadoop的Yarn和Mesos等其他框架。


- 集群规划

- 解压缩、修改文件名

- 进入Spark的配置目录/opt/module/spark-standalone/conf,修改slave文件,添加work节点,分发文件:


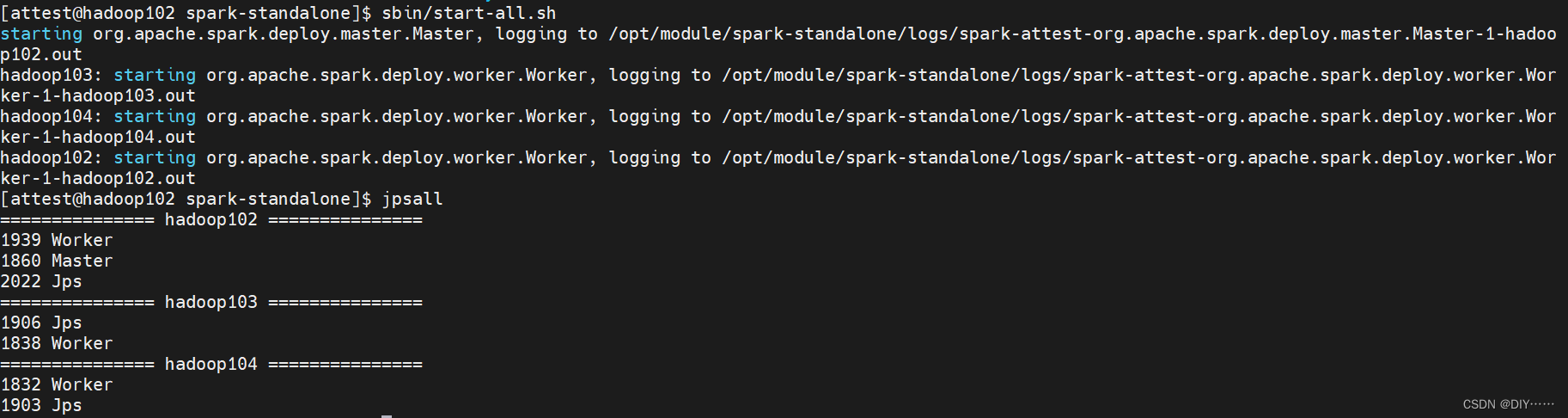
 4. 启动spark集群
4. 启动spark集群

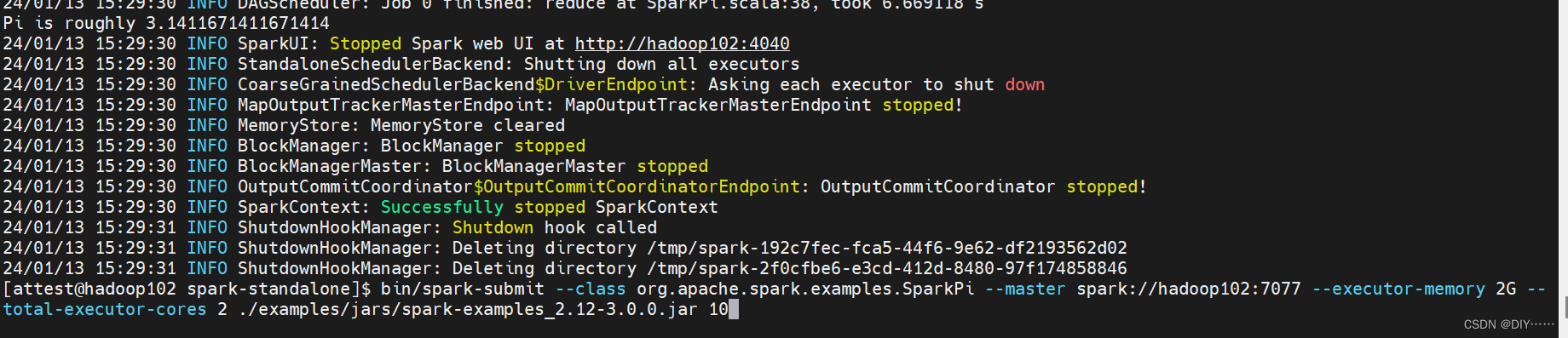
5. 测试

三、yarn模式
Spark客户端直接连接Yarn,不需要额外构建Spark集群。
- 上传文件、解压缩、修改文件名
- 修改hadoop配置文件/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml,添加下面内容,并分发文件

注意:生产环境视情况而定

3. 修改/opt/module/spark-yarn/conf/spark-env.sh,添加YARN_CONF_DIR配置,保证后续运行任务的路径都变成集群路径


4. 启动HDFS以及YARN集群
先启动zk,启动yarn,启动hdfs

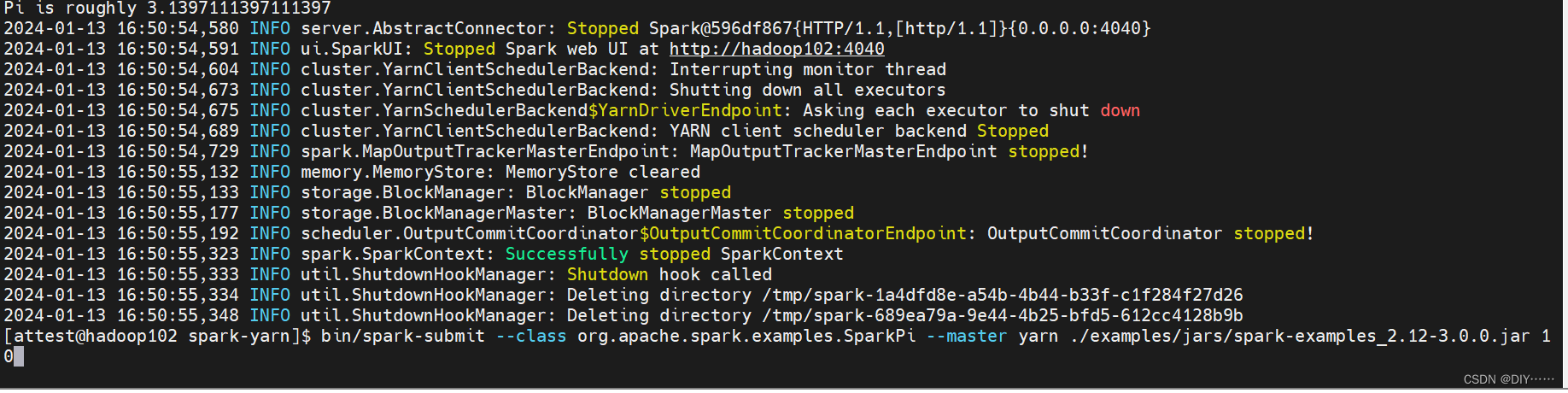
5. 测试
文章来源:https://blog.csdn.net/qq_37232843/article/details/135567188
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- All the stories begin at installation
- 【LMM 008】Instruction Tuning with GPT-4
- 戴西软件公司收购PRESYS全球知识产权:以通用有限元仿真软件撬动工业未来
- 化妆品销售团队:365元月月换新妆,半年狂销10亿!
- Redis实现延迟任务队列(一)
- 独立站如何借助内容营销实现品牌提升与用户增长?
- LoadRunner从零开始之走近LoadRunner
- starrocks权限管理-2.3.2版本
- Midjourney网页版
- 期末前端web大作业——我的家乡陕西介绍网页制作源码