Python中线程、进程与异步的介绍和实现(非常详细,例子多多、注解多多,值得大家参考借鉴)
一、线程与进程关系
(1)线程:线程是进程中的一个执行流,是进程中的实际工作单位,一个进程可以包含多个线程。
(2)进程:进程是操作系统中的一个执行单位,是程序的一次执行过程。它拥有独立的内存空间、执行环境和资源。
(3)关系:一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间、文件描述符等。线程是在进程内部创建和销毁的,它们共享进程的上下文,可以访问进程的全局变量和堆内存。不同线程之间可以通过共享内存进行通信。
(4)执行方式:进程和线程的执行方式不同。进程是独立执行的,每个进程有自己的执行顺序和状态。而线程是在进程内部并发执行的,多个线程可以同时执行不同的任务,从而提高程序的并发性和响应能力。
(5)调度和切换:进程和线程的调度和切换方式也不同。进程的调度和切换需要操作系统的支持,涉及到上下文的切换和内核态与用户态之间的转换。线程的调度和切换相对较为轻量,由线程库或运行时环境负责管理。
总结来说,进程是操作系统中的一个执行单位,拥有独立的资源和执行环境;而线程是进程中的一个执行流,共享进程的资源,可以并发执行。线程是进程的一部分,是实现并发和并行执行的基本单位。线程的使用可以提高程序的性能和响应能力,但也需要注意线程间的同步和资源竞争问题。(操作系统在运行程序时会开辟一块内存,这个区域可以称为“xxx进程”,进程里面则有一个个线程)
二、异步的介绍
(1)简介:异步是一种编程模型或方式,用于处理可能耗时的操作,以提高程序的性能和响应能力。在传统的同步编程中,程序会按照顺序执行,当遇到一个耗时的操作时,程序会阻塞等待操作完成,然后才能继续执行后续的操作。而异步编程则不会阻塞程序的执行,它允许程序在执行耗时操作的同时,继续执行其他操作。异步操作通常会在后台或其他线程中执行,当操作完成后,会通知程序进行后续的处理。
(2)优点:异步编程的优点在于可以提高程序的并发性和响应能力,特别适用于处理网络请求、文件读写、数据库访问等耗时操作。通过异步操作,程序可以在等待操作完成的同时,继续执行其他任务,从而充分利用系统资源,提高程序的效率。
(3)实现方式:包括回调函数、Promise、协程和异步/await等。这些机制可以帮助程序在执行异步操作时,定义回调函数或处理异步结果的方式,使得代码更加简洁和易于理解。
实现异步编程的方法有多种,具体选择哪种方法取决于编程语言、开发框架和应用程序的需求。以下是一些常见的实现异步的方法:
1、回调函数(Callback):在异步操作完成后,通过回调函数来处理操作的结果。这是一种传统的实现异步的方式,但容易导致回调地狱(callback hell)的问题,代码可读性差。
2、Promise/Deferred:在一些编程语言(如 JavaScript)中,可以使用 Promise 或 Deferred 对象来处理异步操作。Promise 提供了更优雅的处理异步操作和错误处理的方式,避免了回调地狱的问题。
3、协程(Coroutine):协程是一种特殊的函数,可以在函数执行过程中暂停和恢复执行。通过使用协程,可以实现更简洁和可读性更好的异步代码。例如,在 Python 中可以使用 async/await 关键字来定义和调用协程函数。
4、事件驱动(Event-driven):使用事件驱动的方式来处理异步操作。在事件驱动模型中,程序通过监听和触发事件来处理异步操作。一些编程语言和框架提供了对事件驱动的支持,例如 Node.js 中的事件循环机制。
5、异步库/框架:使用专门的异步库或框架来处理异步操作。这些库或框架提供了更高级的抽象和工具,简化了异步编程的过程。例如,在 Python 中可以使用 asyncio、Tornado、Twisted 等库来处理异步操作。
需要根据具体的语言和框架来选择适合的方法来实现异步。不同的方法有不同的优缺点,开发者需要根据应用程序的需求和自己的编程经验来选择合适的方法。
需要注意的是,异步编程也会带来一些挑战,如处理并发和竞态条件、错误处理、代码可读性等。因此,在进行异步编程时,需要仔细考虑并充分理解异步操作的特性和相关的编程模型,以确保代码的正确性和可维护性。
三、进程、线程和异步是操作系统和编程中的三个相关概念,它们之间有一定的关系
1、异步与线程:异步是一种编程模型,用于处理可能耗时的操作。在异步编程中,程序可以继续执行其他操作,而不需要等待耗时操作完成。异步操作通常会在后台或其他线程中执行,当操作完成后,会通知程序进行后续的处理。
2、异步与进程:异步操作可以在一个进程中进行,也可以在多个进程中进行。在单进程中,异步操作通常由多个线程或协程来执行。在多进程或分布式系统中,异步操作可以由不同的进程或节点来执行,通过消息传递或远程调用来实现异步通信和协作。
总结来说,进程和线程是操作系统中的执行单位,而异步是一种编程模型。线程可以用于实现异步操作的并发执行,而进程和多进程系统可以通过异步操作来实现分布式的异步通信和协作。异步编程可以提高程序的性能和响应能力,但也需要注意处理并发和竞态条件、错误处理等问题。
四、线程的实现
(1)根据一个程序或进程中所包含的线程数量来对线程进行分类:
1、单线程:单线程指的是一个程序或进程中只包含一个线程。在单线程模型中,所有的任务都是按照顺序依次执行的,每个任务需要等待前一个任务完成后才能开始执行。单线程的优点是简单易用,不会出现多线程并发带来的竞态条件和死锁等问题。但它的缺点是执行效率较低,无法充分利用多核处理器的并行能力。
2、多线程:多线程指的是一个程序或进程中包含多个线程。在多线程模型中,不同的任务可以并发执行,各个线程之间可以共享数据和资源,提高了程序的执行效率和响应能力。多线程的优点是能够充分利用多核处理器的并行能力,提高程序的执行效率。但它的缺点是线程之间的并发控制和数据共享需要额外的同步机制,可能会导致竞态条件、死锁等问题。
在实际应用中,可以根据任务的性质和需求来选择单线程或多线程模型。如果任务之间没有明显的并发关系,且执行效率要求不高,可以选择单线程模型。如果任务之间存在并发关系,且执行效率要求较高,可以选择多线程模型。同时,多线程模型也需要注意线程安全和同步机制的设计,以避免潜在的问题。
(2)实现单线程:
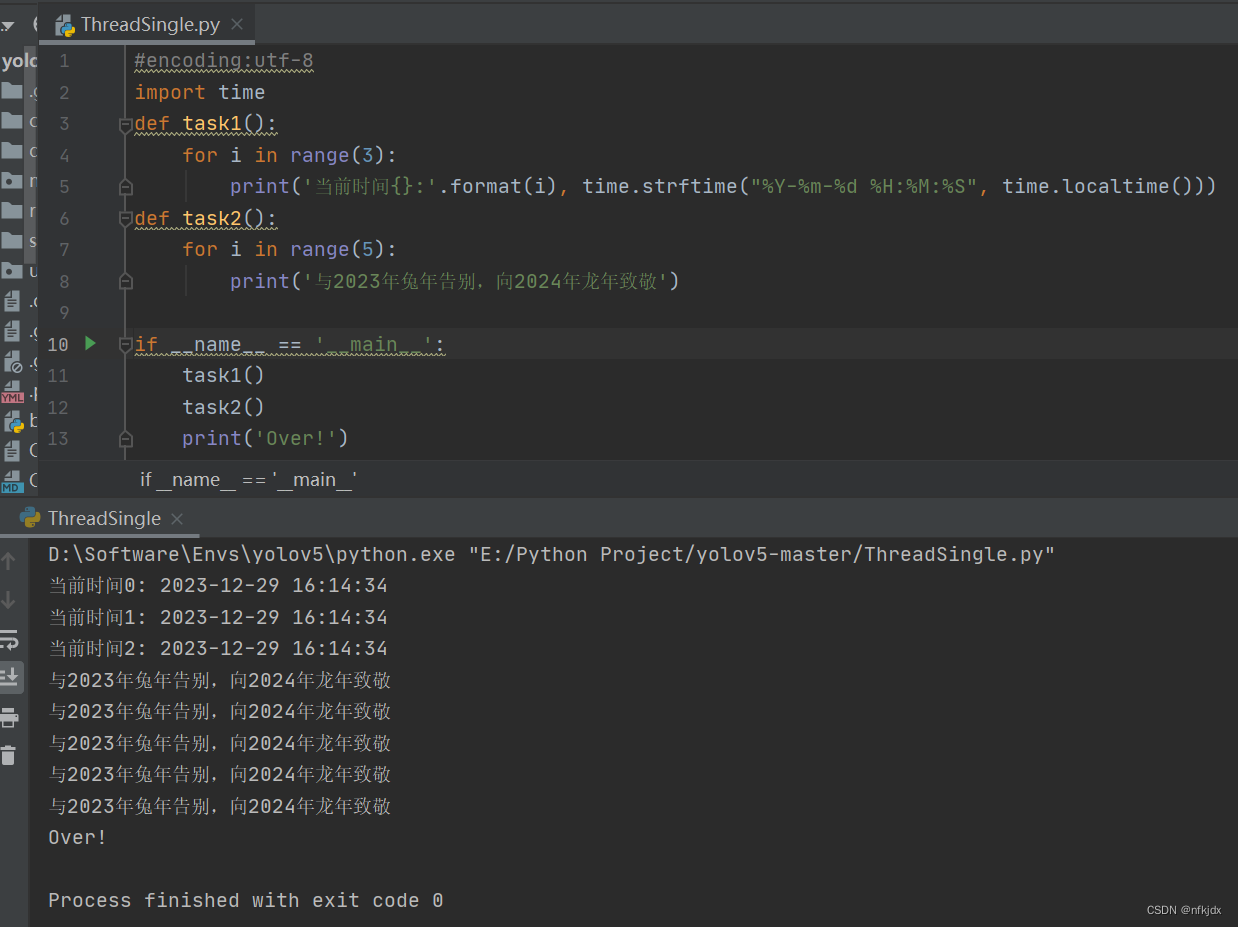
先执行完task1,再去执行task2,最后执行print输出,按照先后顺序执行!
#encoding:utf-8
import time
def task1():
for i in range(3):
print('当前时间{}:'.format(i), time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
def task2():
for i in range(5):
print('与2023年兔年告别,向2024年龙年致敬')
if __name__ == '__main__':
task1()
task2()
print('Over!')
结果如下图所示:
(3)实现多线程:多线程的优点是能够充分利用多核处理器的并行能力
导入threading 包的 Tread 模块,这是一个线程的类,通过将这个类实例化得到一个新的线程,如下:
1、实例1:
#encoding:utf-8
import time
from threading import Thread # 线程的类
def task1():
for i in range(3):
print('当前时间{}:'.format(i), time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
def task2():
for i in range(5):
print('与2023年兔年告别,向2024年龙年致敬')
if __name__ == '__main__':
# 创建一个线程类的对象,target告诉程序当前线程执行谁,安排好任务
t = Thread(target=task1)
# 多线程状态为可以开始执行了,具体执行时间由CPU决定
t.start()
task2()
print('Over!')
结果如下图所示:
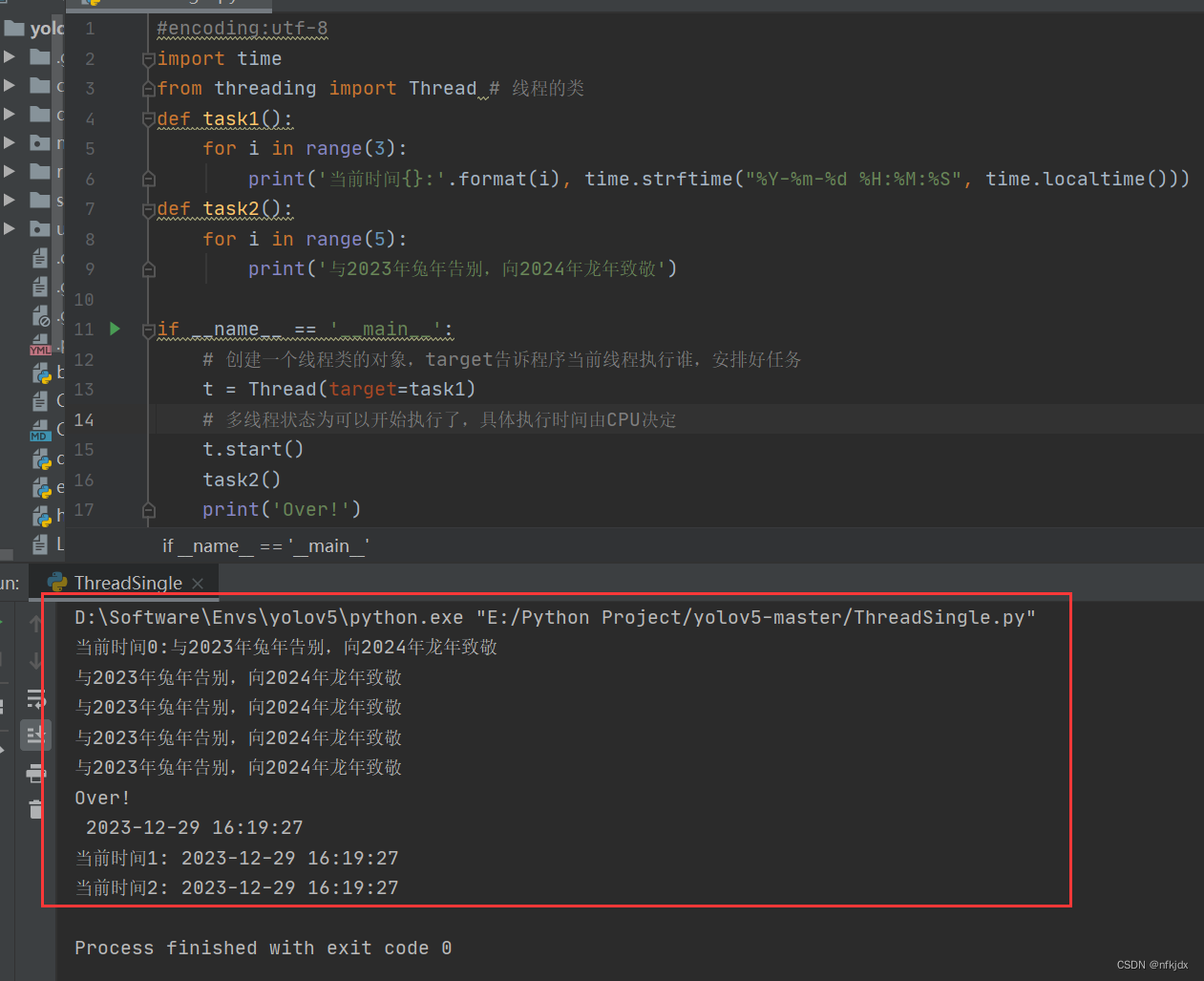
这是由于使用多线程,利用多核处理器的并行能力导致打印的结果顺序变得“混乱”。
2、实例2:先执行task2,在执行print与task1
#encoding:utf-8
import time
from threading import Thread # 线程的类
def task1():
time.sleep(1) # 使用time.sleep()函数来设置线程的睡眠时间
for i in range(3):
print('当前时间{}:'.format(i), time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
def task2():
for i in range(5):
print('与2023年兔年告别,向2024年龙年致敬')
if __name__ == '__main__':
# 创建一个线程类的对象,target告诉程序当前线程执行谁,安排好任务
t = Thread(target=task1)
# 多线程状态为可以开始执行了,具体执行时间由CPU决定
t.start()
task2()
print('Over!')
结果如下图所示:
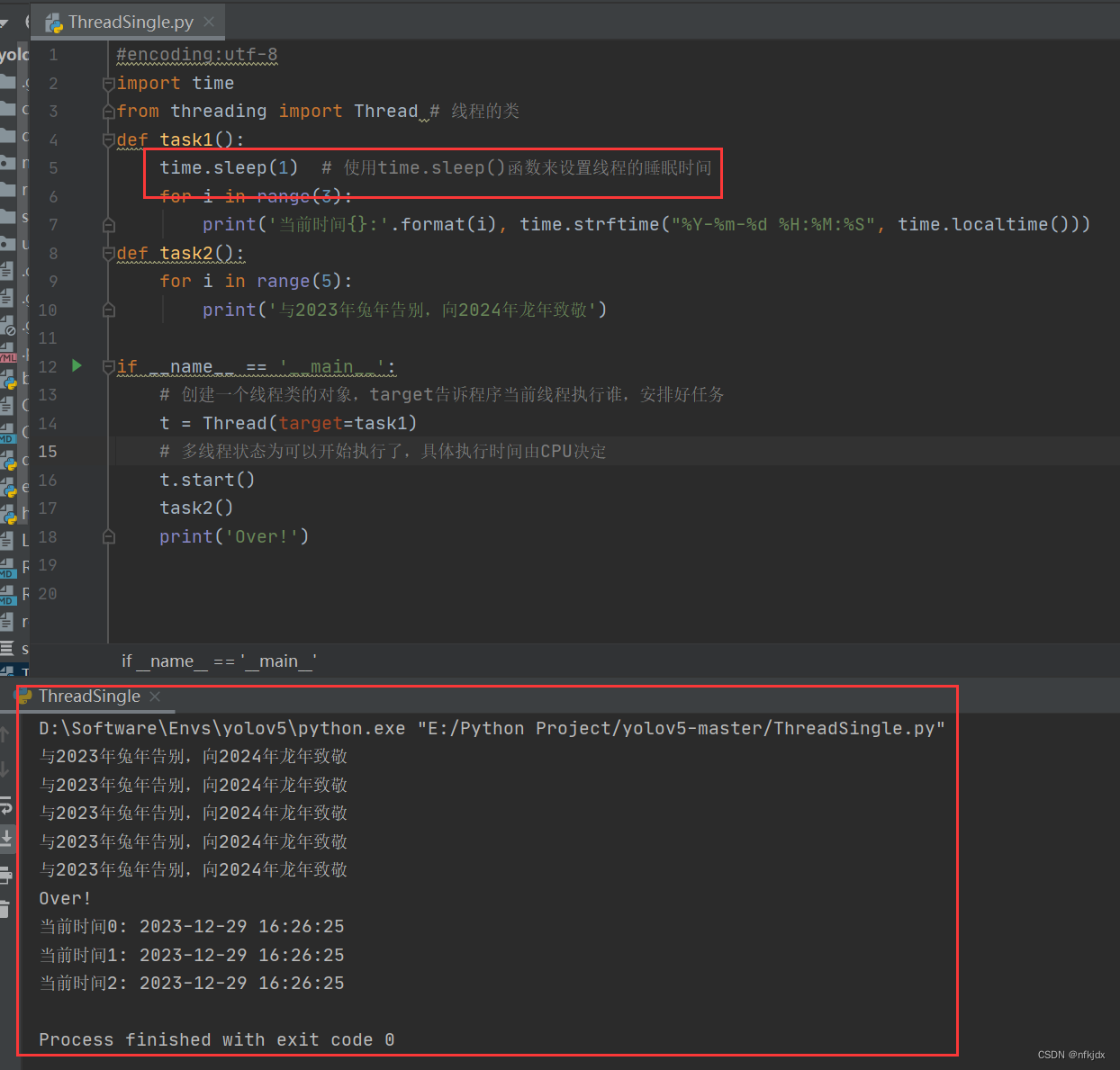
在Python中,可以使用time.sleep()函数来设置线程的睡眠时间。time.sleep()函数会暂停当前线程的执行,让其进入睡眠状态,并在指定的时间后恢复执行。
time.sleep()函数的参数是一个浮点数,表示睡眠的时间,单位是秒。可以传入整数或小数来指定具体的睡眠时间。例如,time.sleep(2)表示线程将会睡眠2秒。
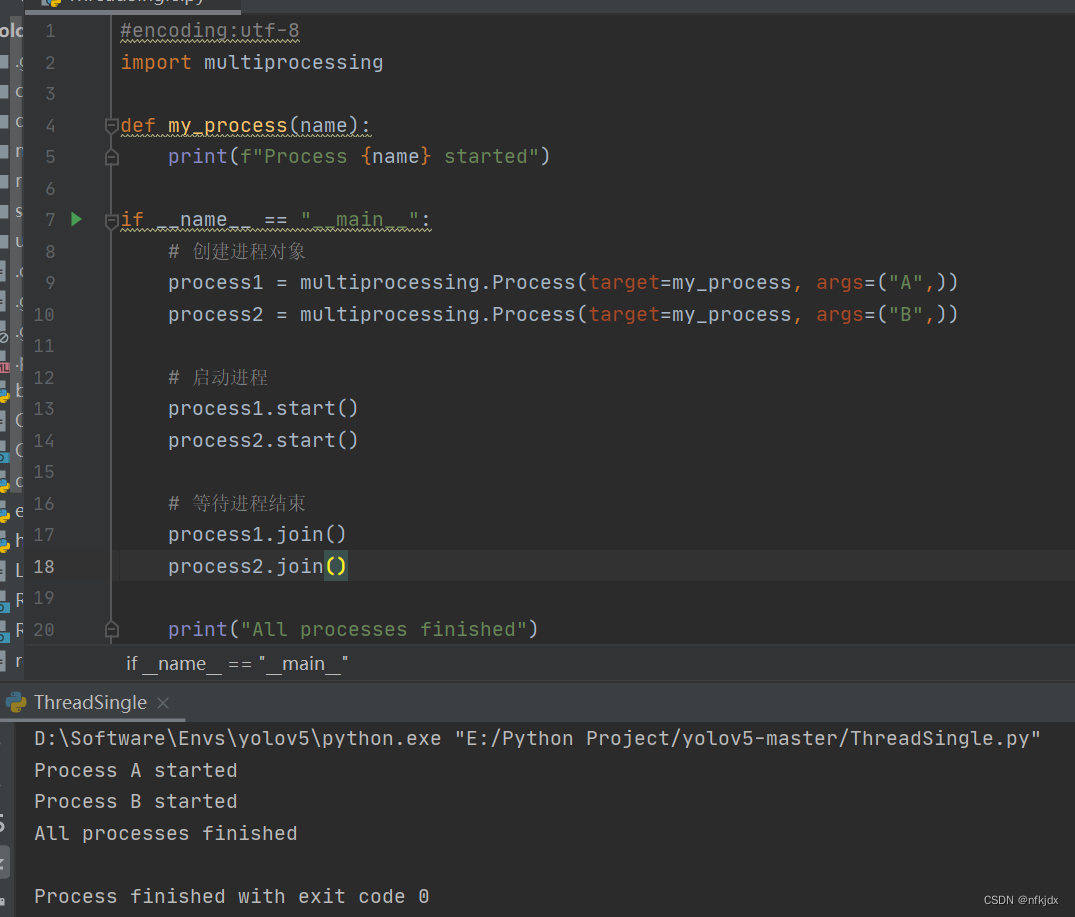
(4)实现多进程:多进程是指一个程序中同时运行多个进程的情况。每个进程都有自己独立的内存空间和执行环境,它们可以并行执行,相互之间不会干扰。
在Python中,可以使用multiprocessing模块来创建和管理多进程。multiprocessing模块提供了一些类和函数,用于创建进程、进程间通信、进程池等操作。
#encoding:utf-8
import multiprocessing
def my_process(name):
print(f"Process {name} started")
if __name__ == "__main__":
# 创建进程对象
process1 = multiprocessing.Process(target=my_process, args=("A",))
process2 = multiprocessing.Process(target=my_process, args=("B",))
# 启动进程
process1.start()
process2.start()
# 等待进程结束
process1.join()
process2.join()
print("All processes finished")
在上述示例中,我们首先定义了一个my_process()函数,它接受一个参数name,并在启动时打印一条消息。然后,我们使用multiprocessing.Process类创建了两个进程对象process1和process2,并分别传入不同的name参数。接着,我们使用start()方法启动进程,join()方法等待进程结束。最后,主进程打印一条消息表示所有进程都已经结束。
需要注意的是,每个进程都有自己独立的内存空间,因此进程之间的数据无法直接共享。如果需要进程间通信,可以使用multiprocessing模块提供的Queue、Pipe等机制来实现。另外,多进程的创建和启动会消耗一定的系统资源,因此在使用多进程时要注意控制进程的数量,避免过多的进程导致系统负载过高。
结果如下:
五、线程池与进程池
(1)简介:
线程池和进程池都是一种用于管理和复用线程或进程的机制,可以提高程序的性能和效率。
线程池是一组预先创建好的线程,这些线程可以被重复使用来执行多个任务。线程池中的线程会被放入一个任务队列中,当有任务需要执行时,线程池会从队列中取出一个线程来执行任务。当任务执行完成后,线程会返回线程池,等待下一个任务的到来。线程池可以控制线程的数量,避免创建过多的线程导致系统资源的浪费。
进程池是一组预先创建好的进程,这些进程可以被重复使用来执行多个任务。进程池中的进程会被放入一个任务队列中,当有任务需要执行时,进程池会从队列中取出一个进程来执行任务。当任务执行完成后,进程会返回进程池,等待下一个任务的到来。进程池同样可以控制进程的数量,避免创建过多的进程导致系统资源的浪费。
线程池和进程池的使用场景类似,都适用于需要执行大量独立任务的情况,例如并发处理网络请求、并行计算等。线程池适用于IO密集型的任务,因为线程之间的切换开销较小;而进程池适用于CPU密集型的任务,因为多进程可以充分利用多核CPU的性能。
在Python中,可以使用concurrent.futures模块来创建和管理线程池和进程池。concurrent.futures模块提供了ThreadPoolExecutor类和ProcessPoolExecutor类,用于创建线程池和进程池,并提供了一些方法来提交任务和获取结果。使用线程池和进程池可以简化多线程和多进程的管理,提高代码的可读性和可维护性。
(2)实现线程池:
下面是一个使用concurrent.futures模块创建线程池的示例:
#encoding:utf-8
import concurrent.futures
def my_task(name):
print(f"Task {name} started")
# 执行任务的代码
print(f"Task {name} finished")
if __name__ == "__main__":
# 创建线程池对象
with concurrent.futures.ThreadPoolExecutor(max_workers=60) as executor:
# 提交任务给线程池
task1 = executor.submit(my_task, "A")
task2 = executor.submit(my_task, "B")
task3 = executor.submit(my_task, "C")
# 获取任务的结果
result1 = task1.result()
result2 = task2.result()
result3 = task3.result()
print("All tasks finished")
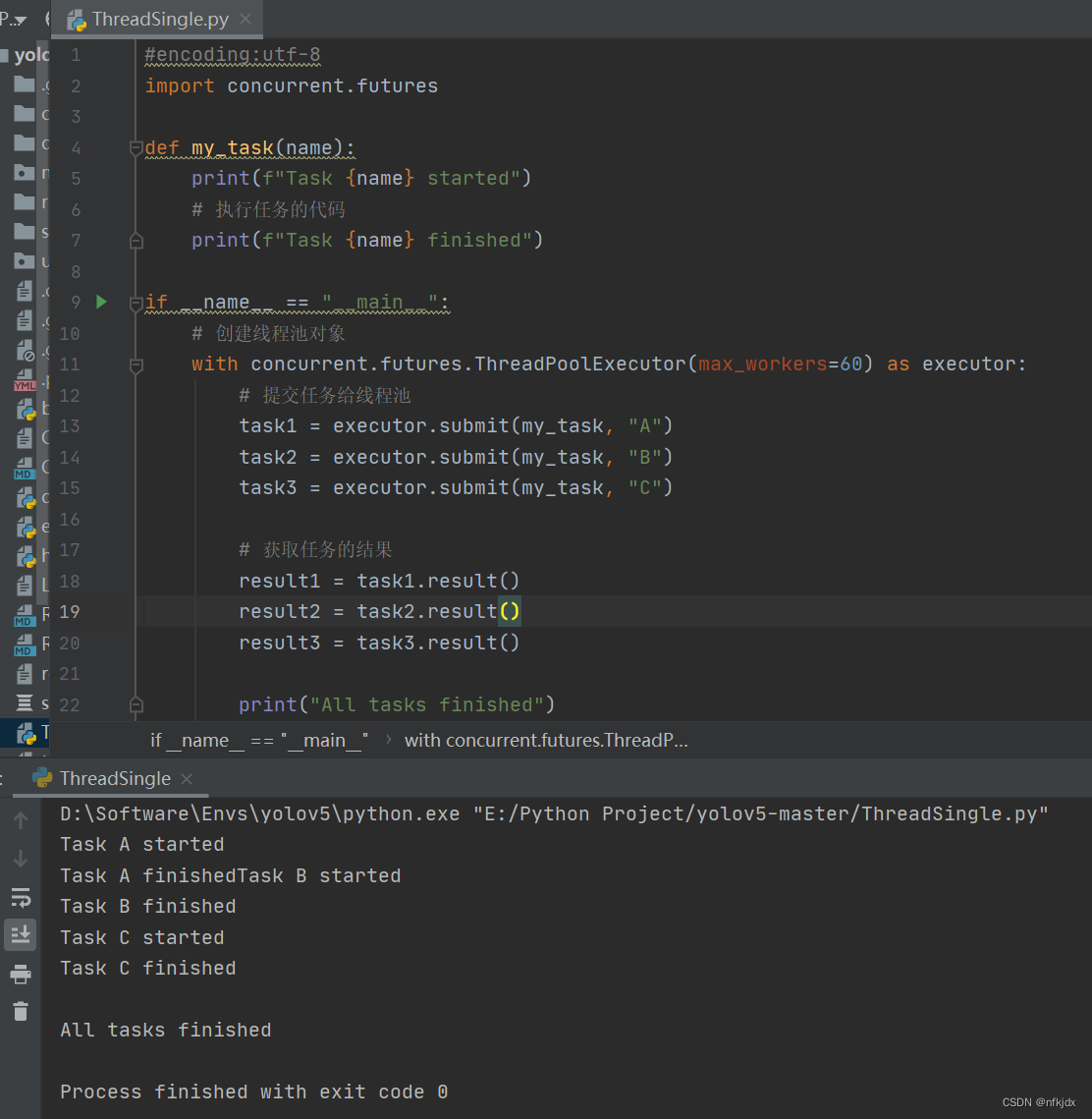
结果1:
结果2:
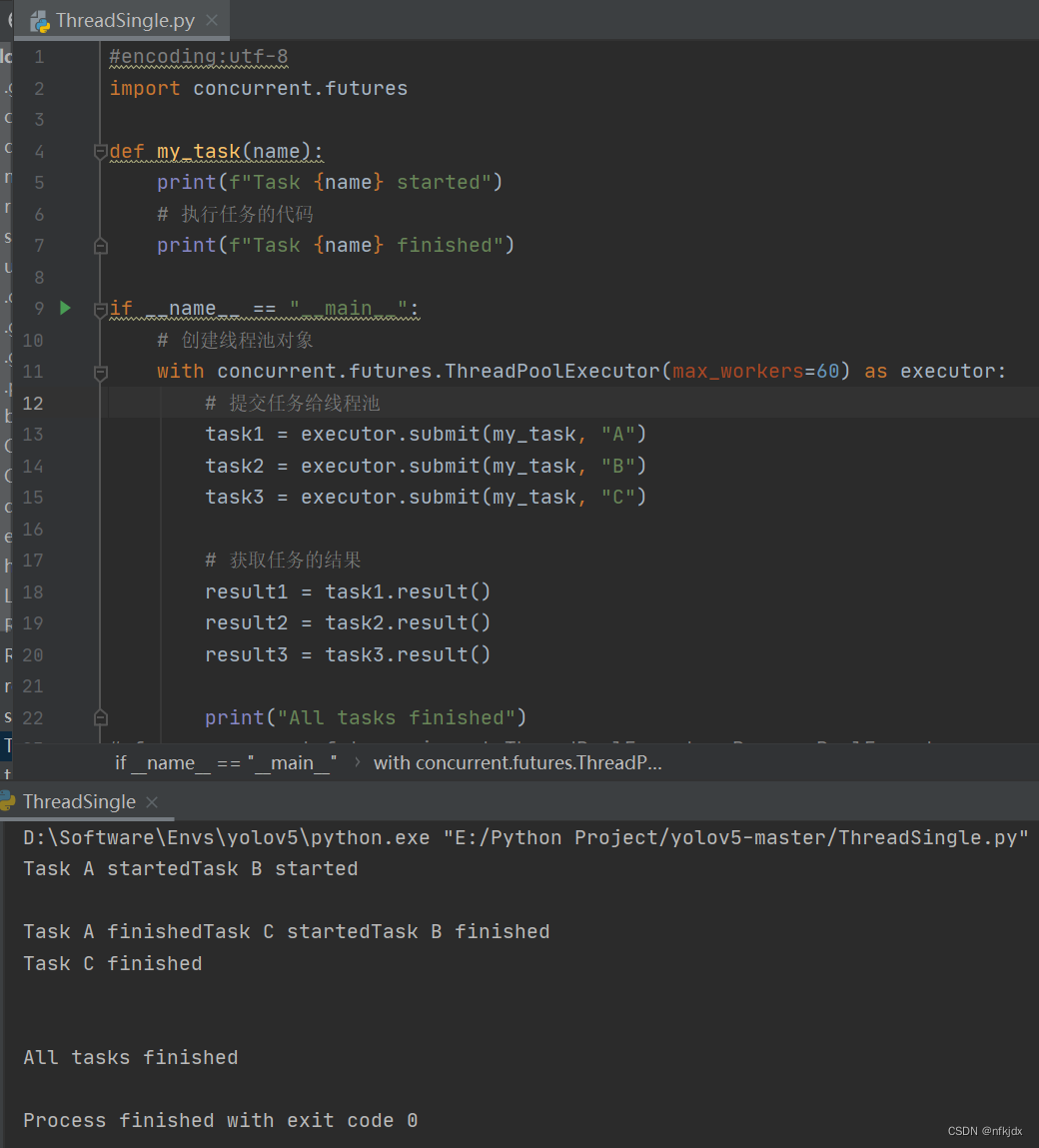
在上述示例中,我们首先定义了一个my_task()函数,它接受一个参数name,并在执行任务前后打印相应的消息。然后,我们使用concurrent.futures.ThreadPoolExecutor类创建了一个线程池对象,指定最大工作线程数为60。接着,我们使用submit()方法向线程池提交了三个任务,分别传入不同的name参数。然后,我们使用result()方法获取每个任务的结果,该方法会阻塞当前线程,直到任务完成并返回结果。最后,主线程打印一条消息表示所有任务都已经完成。
需要注意的是,使用线程池时,submit()方法会立即返回一个Future对象,表示任务的未来结果。可以通过调用result()方法来获取任务的结果。另外,使用with语句创建线程池对象可以确保在使用完毕后自动关闭线程池,释放资源。
通过使用线程池,可以简化线程的创建和管理,提高代码的可读性和可维护性。线程池会自动管理线程的生命周期,复用线程,避免频繁地创建和销毁线程,从而提高程序的性能和效率。
(3)实现进程池:逻辑与线程池类似,将 ThreadPoolExecutor 更改为 ProcessPoolExecutor 即可
#encoding:utf-8
import concurrent.futures
def my_task(name):
print(f"Task {name} started")
# 执行任务的代码
print(f"Task {name} finished")
if __name__ == "__main__":
# 创建线程池对象
with concurrent.futures.ProcessPoolExecutor(max_workers=60) as executor:
# 提交任务给线程池
task1 = executor.submit(my_task, "A")
task2 = executor.submit(my_task, "B")
task3 = executor.submit(my_task, "C")
# 获取任务的结果
result1 = task1.result()
result2 = task2.result()
result3 = task3.result()
print("All tasks finished")

六、异步编程
(1)简介
回调:回调函数可以理解为是IO事件完毕后执行提前注册的回调函数。把I/O事件的等待和监听任务交给了操作系统,操作系统在知道I/O状态发生改变后,通过回调通知调用程序。
事件循环:事件循环 “是一种等待程序分配事件或消息的编程架构”。基本上来说事件循环就是,“当A发生时,执行B”。事件循环提供一种循环机制,让你可以“在A发生时,执行B”。基本上来说事件循环就是监听当有什么发生时,同时事件循环也关心这件事并执行相应的代码。事件循环被认为是一种循环是因为它不停地收集事件并通过循环来查找如何应对这些事件。对Python 来说,用来提供事件循环的 asyncio 被加入标准库中。asyncio重点解决网络服务中的问题,事件循环在这里将来自socket的 I/O已经准备好读和/或写作为“当A发生时”(通过selectors模块)。
异步编程:异步编程是一种IO模型,异步IO模型需要一个消息循环,在消息循环中,主线程不断地重复“读取消息-处理消息”这一过程。不论什么编程语言,但凡要做异步编程,事件循环+回调这种模式是逃不掉的,尽管它可能用的不是epoll,也可能不是while循环。但是由于基于回调的异步模型会出现回调地狱、错误处理困难、堆栈撕裂等问题,所以Python在事件循环+回调的基础上衍生出了基于协程的解决方案。
在Python中协程和事件循环一起使用构成了异步编程。Python 3.4 以后通过标准库 asyncio获得了事件循环的特性(主要通过selectors模块来实现)。
(2)Python异步编程进化史
1、生成器yield
协程是为非抢占式多任务产生子程序的计算机程序组件,协程允许不同入口点在不同位置暂停或开始执行程序。从技术的角度来说,“协程就是你可以暂停执行的函数”。是不是和生成器的特性很像?
生成器第一次在PEP 255中提出(那时也把它成为迭代器,因为它实现了迭代器协议)。生成器允许创建一个在计算下一个值时不会浪费内存空间的迭代器。让函数遇到yield表达式时暂停执行,并且能够在后面重新执行,这对于减少内存使用、生成无限序列非常有用。
为了支持用生成器做简单的协程,Python 2.5 对生成器进行了增强(PEP 342)。有了PEP 342的加持,生成器可以通过yield暂停执行和向外返回数据,也可以通过send()向生成器内发送数据,还可以通过throw()向生成器内抛出异常以便随时终止生成器的运行。
调用生成器函数时,并不会立即执行函数,而是返回一个生成器对象,然后通过next()函数触发生成器,函数执行到yield表达式时会暂停,并将yield后面的值返回给触发者,通过send()函数将值从外部传入到生成器内部,生成器继续执行,直到遇到下一个yield表达式,当生成器函数所有的代码执行完没有遇到下一个yield,就会抛出异常,如果对生成器使用for循环,for循环会自动处理异常。
其实next()和send()在一定意义上作用是相似的,区别是send()可以传递yield表达式的值进去,而next()不能传递特定的值,只能传递None进去。因此,我们可以看做c.next()和 c.send(None) 作用是一样的。因此也可以不通过next()函数,通过send(None)来触发生成器,使用send()触发第一次传入的参数必须是None,否则会报错,因为第一次触发没有yield语句来接收其他非None的值。
send(msg)和next()都会有返回值,返回值是下一个yield表达式的参数,比如说yield 5 则返回5。另外,在一个生成器中,如果没有 return,则默认执行至函数完毕,如果在执行过程中 return,则直接抛出 StopIteration 终止迭代。
2、yield from
Python3.3版本的PEP 380中添加了yield from语法。允许一个generator生成器将其部分操作委派给另一个生成器。其产生的主要动力在于使生成器能够很容易分为多个拥有send和throw方法的子生成器,像一个大函数可以分为多个子函数一样简单。Python的生成器是协程coroutine的一种形式,但它的局限性在于只能向它的直接调用者yield值。这意味着那些包含yield的代码不能想其他代码那样被分离出来放到一个单独的函数中。这也正是yield from要解决的。
yield from 后面需要加的是可迭代对象,它可以是普通的可迭代对象,也可以是迭代器,甚至是生成器。
虽然yield from主要设计用来向子生成器委派操作任务,但yield from可以向任意的迭代器委派操作。
例子:
#encoding:utf-8
#使用yield语句
def gen():
for j in 'ACB':
yield j
for i in range(1, 3):
yield i
print(list(gen()))
#使用yield from实现相同的功能
def gen():
yield from 'ACB'
yield from range(1, 3)
print(list(gen()))
结果如下:
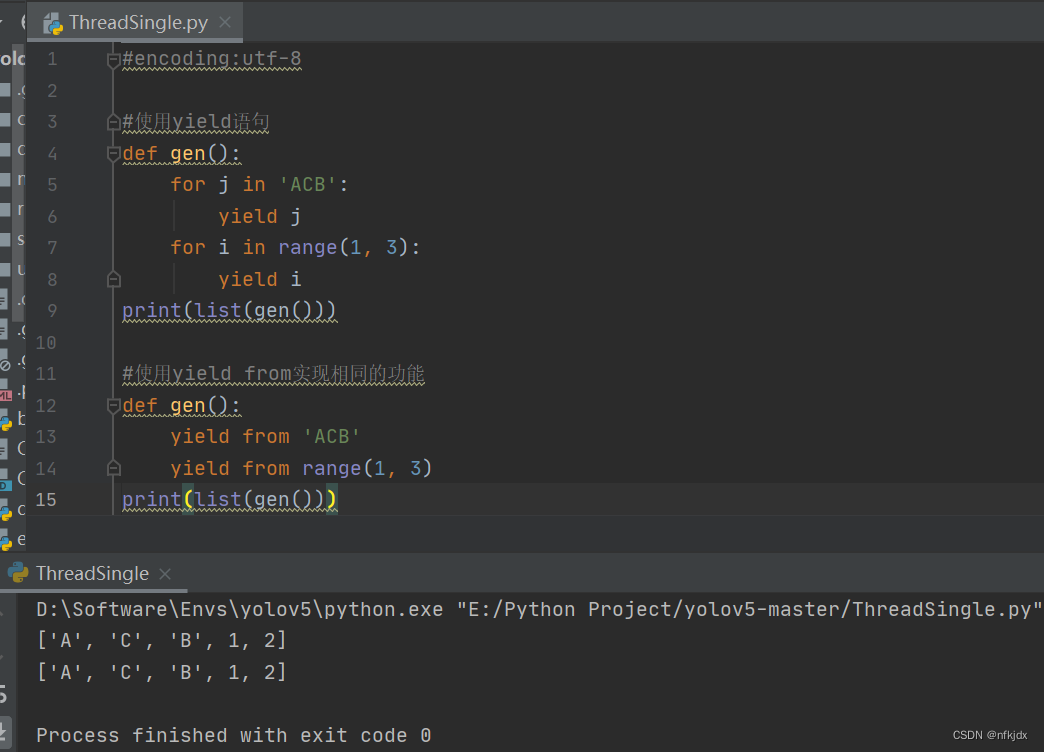
先明确几个概念:
调用方:调用委派生成器的客户端(调用方)代码
委托生成器:包含yield from表达式的生成器函数
子生成器:yield from后面加的生成器函数
但是yield from不仅仅如此,还有更加强大的功能,不同于普通的循环,yield from允许子生成器直接从调用者接收其发送的信息或者抛出调用时遇到的异常,并且返回给委派生产器一个值。
#encoding:utf-8
from collections import namedtuple
Result = namedtuple('Result', 'count average')
# the subgenerator
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield
if term is None:
break
total += term
count += 1
average = total / count
return Result(count, average)
# the delegating generator
def grouper(results, key):
while True:
#只有当生成器averager()结束,才会返回结果给results赋值
results[key] = yield from averager()
def main(data):
results = {}
for key, values in data.items():
group = grouper(results, key)
next(group)
for value in values:
group.send(value)
group.send(None)
report(results)
#如果不使用yield from,仅仅通过yield实现相同的效果,如下:
def main2(data):
for key, values in data.items():
aver = averager()
next(aver)
for value in values:
aver.send(value)
try: #通过异常接受返回的数据
aver.send(None)
except Exception as e:
result = e.value
print(result)
def report(results):
for key, result in sorted(results.items()):
group, unit = key.split(';')
print('{:2} {:5} averaging {:.2f}{}'.format(result.count, group, result.average, unit))
data = {
'girls;kg':[40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m':[1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg':[39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m':[1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46],
}
if __name__ == '__main__':
main(data)
结果如下:
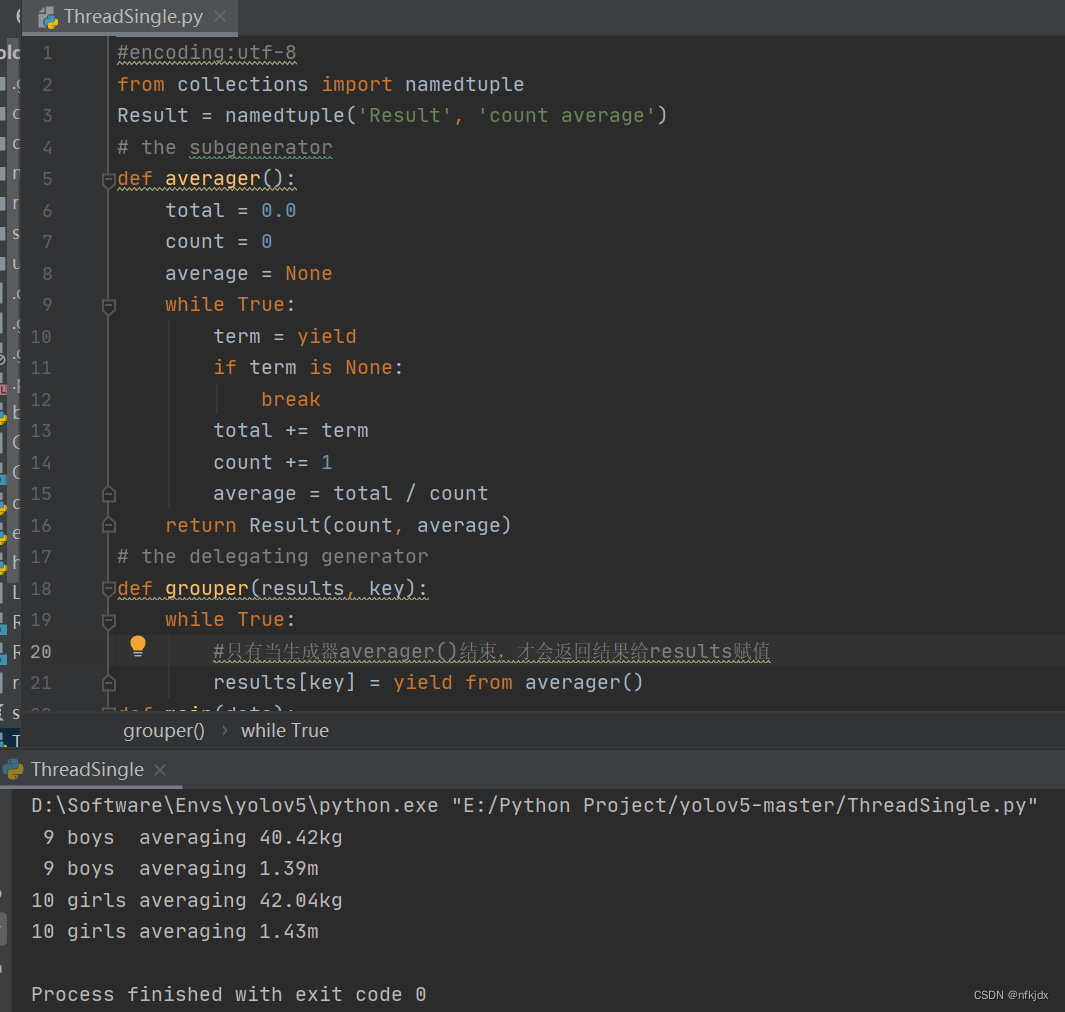
总结如下:
迭代器(即可指子生成器)产生的值直接返还给调用者任何使用send()方法发给委派生产器(即外部生产器)的值被直接传递给迭代器。如果send值是None,则调用迭代器next()方法;如果不为None,则调用迭代器的send()方法。如果对迭代器的调用产生StopIteration异常,委派生产器恢复继续执行yield from后面的语句;若迭代器产生其他任何异常,则都传递给委派生产器。
除了GeneratorExit 异常外的其他抛给委派生产器的异常,将会被传递到迭代器的throw()方法。如果迭代器throw()调用产生了StopIteration异常,委派生产器恢复并继续执行,其他异常则传递给委派生产器。
如果GeneratorExit异常被抛给委派生产器,或者委派生产器的close()方法被调用,如果迭代器有close()的话也将被调用。如果close()调用产生异常,异常将传递给委派生产器。否则,委派生产器将抛出GeneratorExit 异常。
当迭代器结束并抛出异常时,yield from表达式的值是其StopIteration 异常中的第一个参数。
.一个生成器中的return expr语句将会从生成器退出并抛出 StopIteration(expr)异常。
3、asyncio框架
用yieldfrom改进基于生成器的协程,代码抽象程度更高。至此,Python已经具备异步编程的基础能力,于是Python语言开发者们充分利用yield from,在Python 3.4 试验性引入的异步I/O框架asyncio(PEP 3156),提供了基于协程做异步I/O编写单线程并发代码的基础设施。
Python 3.4中,asyncio.coroutine修饰器用来标记作为协程的函数,这里的协程是和asyncio及其事件循环一起使用的。这赋予了Python第一个对于协程的明确定义:实现了PEP 342添加到生成器中的这一方法的对象,并通过collections.abc.Coroutine这一抽象基类表征的对象。这意味着突然之间所有实现了协程接口的生成器,即便它们并不是要以协程方式应用,都符合这一定义。为了修正这一点,asyncio要求所有要用作协程的生成器必须由asyncio.coroutine修饰。
有了对协程明确的定义(能够匹配生成器所提供的API),你可以对任何asyncio.Future对象使用 yield from,从而将其传递给事件循环,暂停协程的执行来等待某些事情的发生( future 对象并不重要,只是asyncio细节的实现)。一旦future 对象获取了事件循环,它会一直在那里监听,直到完成它需要做的一切。当 future 完成自己的任务之后,事件循环会察觉到,暂停并等待在那里的协程会通过send()方法获取future对象的返回值并开始继续执行。
在 Python 3.4 中,用于异步编程并被标记为协程的函数看起来是这样的:
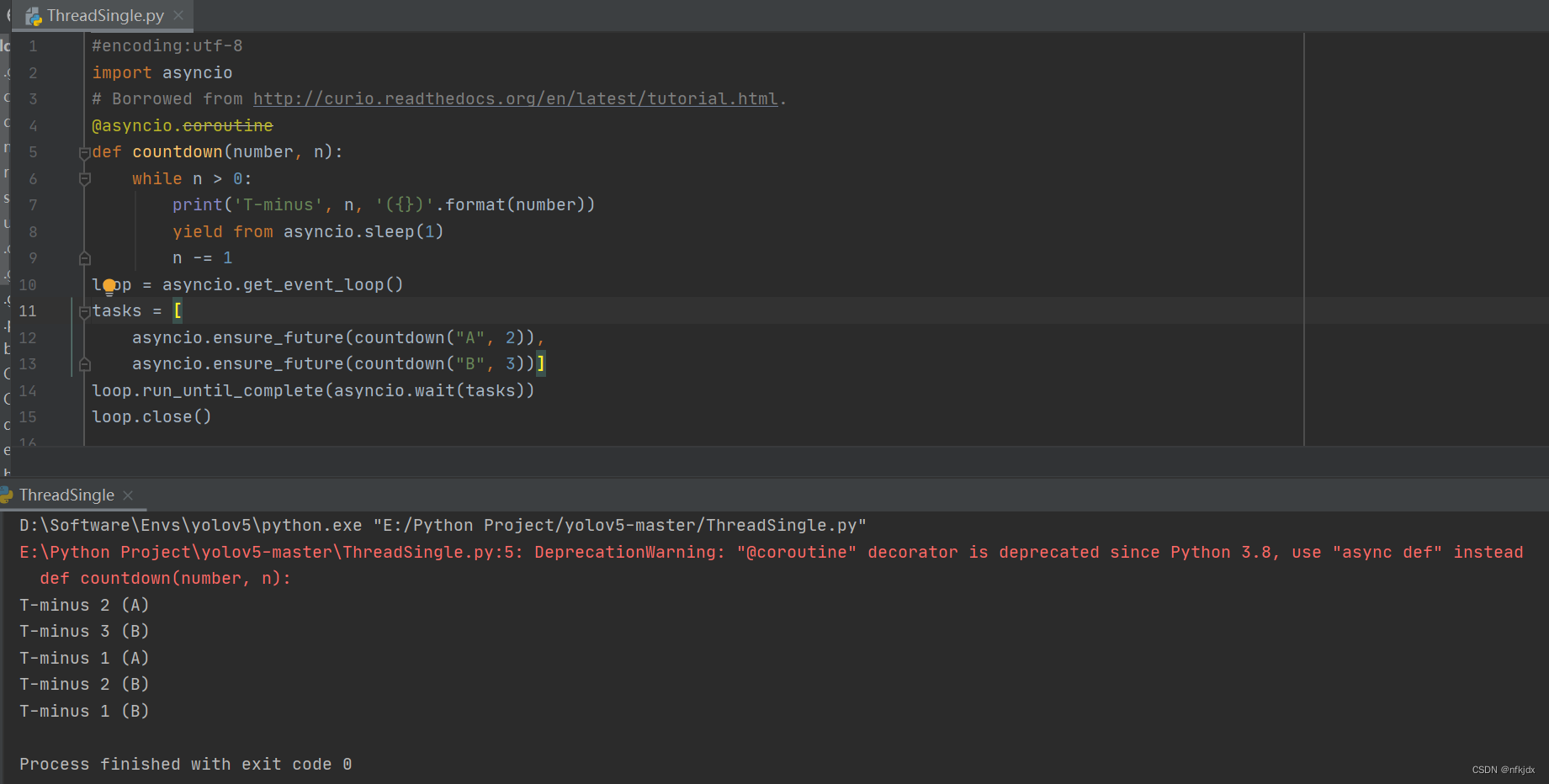
#encoding:utf-8
import asyncio
# Borrowed from http://curio.readthedocs.org/en/latest/tutorial.html.
@asyncio.coroutine
def countdown(number, n):
while n > 0:
print('T-minus', n, '({})'.format(number))
yield from asyncio.sleep(1)
n -= 1
loop = asyncio.get_event_loop()
tasks = [
asyncio.ensure_future(countdown("A", 2)),
asyncio.ensure_future(countdown("B", 3))]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
结果如下:
虽然发展到 Python 3.4 时有了yield from的加持让协程更容易了,但是由于协程在Python中发展的历史包袱所致,迭代器的过度重载,使用生成器实现协程功能有很多缺点:
协程与常规的生成器在相同语法时用以混淆,尤其是对心开发者而言。
一个函数是否是协程需要通过是否主体代码中使用了yield或者yield from语句进行检测,这样在重构代码中添加、去除过程中容易出现不明显的错误
异步调用的支持被yield支持的语法先定了,导致我们无法使用更多的语法特性,比如with和for语句。
于是根据Python 3.5 Beta期间的反馈,进行了重新设计:明确的把协程从生成器里独立出来—原生协程现在拥有了自己完整的独立类型,而不再是一种新的生成器类型。
async/await 原生协程:
Python设计者们在 3.5 中新增了async/await语法(PEP 492),将协程作为原生Python语言特性,并且将他们与生成器明确的区分开。它避免了生成器/协程中间的混淆,方便编写出不依赖于特定库的协程代码,称之为原生协程。async/await 和 yield from这两种风格的协程底层复用共同的实现,而且相互兼容。在Python 3.6 中asyncio库“转正”,不再是实验性质的,成为标准库的正式一员。
Python 3.5 添加了types.coroutine修饰器,也可以像 asyncio.coroutine 一样将生成器标记为协程。你可以用 async def 来定义一个协程函数,虽然这个函数不能包含任何形式的 yield 语句;只有 return 和 await 可以从协程中返回值。
下面的新语法用于声明原生协程:
async def read_data(db):pass
协程的主要属性包括:
async def函数始终为协程,即使它不包含await表达式。
如果在async函数中使用yield或者yield from表达式会产生SyntaxError错误。
在内部,引入了两个新的代码对象标记:
CO_COROUTINE用于标记原生协程(和新语法一起定义)
CO_ITERABLE_COROUTINE用于标记基于生成器的协程,兼容原生协程。(通过types.coroutine()函数设置)
常规生成器在调用时会返回一个genertor对象,同理,协程在调用时会返回一个coroutine对象。协程不再抛出StopIteration异常,而是替代为RuntimeError。常规生成器实现类似的行为需要进行引入future(PEP-3156)
当协程进行垃圾回收时,一个从未被await的协程会抛出RuntimeWarning异常 types.coroutine():在types模块中新添加了一个函数coroutine(fn)用于asyncio中基于生成器的协程与本PEP中引入的原生携协程互通。使用它,“生成器实现的协程”和“原生协程”之间可以进行互操作。
这个函数将生成器函数对象设CO_ITERABLE_COROUTINE标记,将返回对象变为coroutine对象。如果fn不是一个生成器函数,那么它会对其进行封装。如果它返回一个生成器,那么它会封装一个awaitable代理对象。注意:CO_COROUTINE标记不能通过types.coroutine()进行设置,这就可以将新语法定义的原生协程与基于生成器的协程进行区分。
await与yield from相似,await关键字的行为类似标记了一个断点,挂起协程的执行直到其他awaitable对象完成并返回结果数据。它复用了yield from的实现,并且添加了额外的验证参数。
await只接受以下之一的awaitable对象:
一个原生协程函数返回的原生协程对象。
一个使用types.coroutine()修饰器的函数返回的基于生成器的协程对象。
一个包含返回迭代器的await方法的对象。
协程链:协程的一个关键特性是它们可以组成协程链,就像函数调用链一样,一个协程对象是awaitable的,因此其他协程可以await另一个协程对象。
任意一个yield from链都会以一个yield结束,这是Future实现的基本机制。因此,协程在内部中是一种特殊的生成器。每个await最终会被await调用链条上的某个yield语句挂起。
关于基于生成器的协程和async定义的原生协程之间的差异,关键点是只有基于生成器的协程可以真正的暂停执行并强制性返回给事件循环。所以每个await最终会被await调用链条上的某个由types.coroutine()装饰的包含yield语句的协程函数挂起。
为了启用协程的这一特点,一个新的魔术方法__await__被添加进来。在asyncio中,对于对象在await语句启用Future对象只需要添加await = iter这行到asyncio.Future类中。带有await方法的对象也叫做Future-like对象。
另外还新增了异步上下文管理 async with 和异步迭代器 async for。异步生成器和异步推导式都让迭代变得并发,他们所做的只是提供同步对应的外观,但是有问题的循环能够放弃对事件循环的控制,以便运行其他协程。
关于何时以及如何能够和不能使用async / await,有一套严格的规则:
使用async关键字创建一个协程函数,里面包含await或者return,调用协程函数,必须使用await获得函数返回结果。
在async异步函数中使用yield并不常见,这会创建一个异步生成器,可以使用async for来迭代异步生成器。
在async异步函数中使用yield from会抛出语法错误。同样在普通函数中使用await也是语法错误。
将 async/await 看做异步编程的 API:
Python的核心开发者David指出:async/await 实际上是异步编程的 API,人们不应该将async/await等同于asyncio,而应该将asyncio看作是一个利用async/await API 进行异步编程的框架。async/await 的设计意图就是为了让其足够灵活从而不需要依赖asyncio或者仅仅是为了适应这一框架而扭曲关键的设计决策。
下面是将async/await 看做异步编程的 API的一个完整的异步编程的例子,包括事件循环,三个countdown()协程函数并发运行:
#encoding:utf-8
import datetime
import heapq
import types
import time
class Task:
"""相当于asyncio.Task,存储协程和要执行的时间"""
def __init__(self, wait_until, coro):
self.coro = coro
self.waiting_until = wait_until
def __eq__(self, other):
return self.waiting_until == other.waiting_until
def __lt__(self, other):
return self.waiting_until < other.waiting_until
class SleepingLoop:
"""一个事件循环,每次执行最先需要执行的协程,时间没到就阻塞等待,相当于asyncio中的事件循环"""
def __init__(self, *coros):
self._new = coros
self._waiting = []
def run_until_complete(self):
# 启动所有的协程
for coro in self._new:
print(coro)
wait_for = coro.send(None)
heapq.heappush(self._waiting, Task(wait_for, coro))
# 保持运行,直到没有其他事情要做
while self._waiting:
now = datetime.datetime.now()
# 每次取出最先执行的协程
task = heapq.heappop(self._waiting)
if now < task.waiting_until:
# 阻塞等待指定的休眠时间
delta = task.waiting_until - now
time.sleep(delta.total_seconds())
print(task.coro, delta.total_seconds())
now = datetime.datetime.now()
try:
# 恢复不需要等待的协程
wait_until = task.coro.send(now)
heapq.heappush(self._waiting, Task(wait_until, task.coro))
except StopIteration:
# 捕捉协程结束的抛出异常
pass
@types.coroutine
def sleep(seconds):
"""暂停一个协程指定时间,可把他当做asyncio.sleep()"""
now = datetime.datetime.now()
wait_until = now + datetime.timedelta(seconds=seconds)
actual = yield wait_until
return actual - now
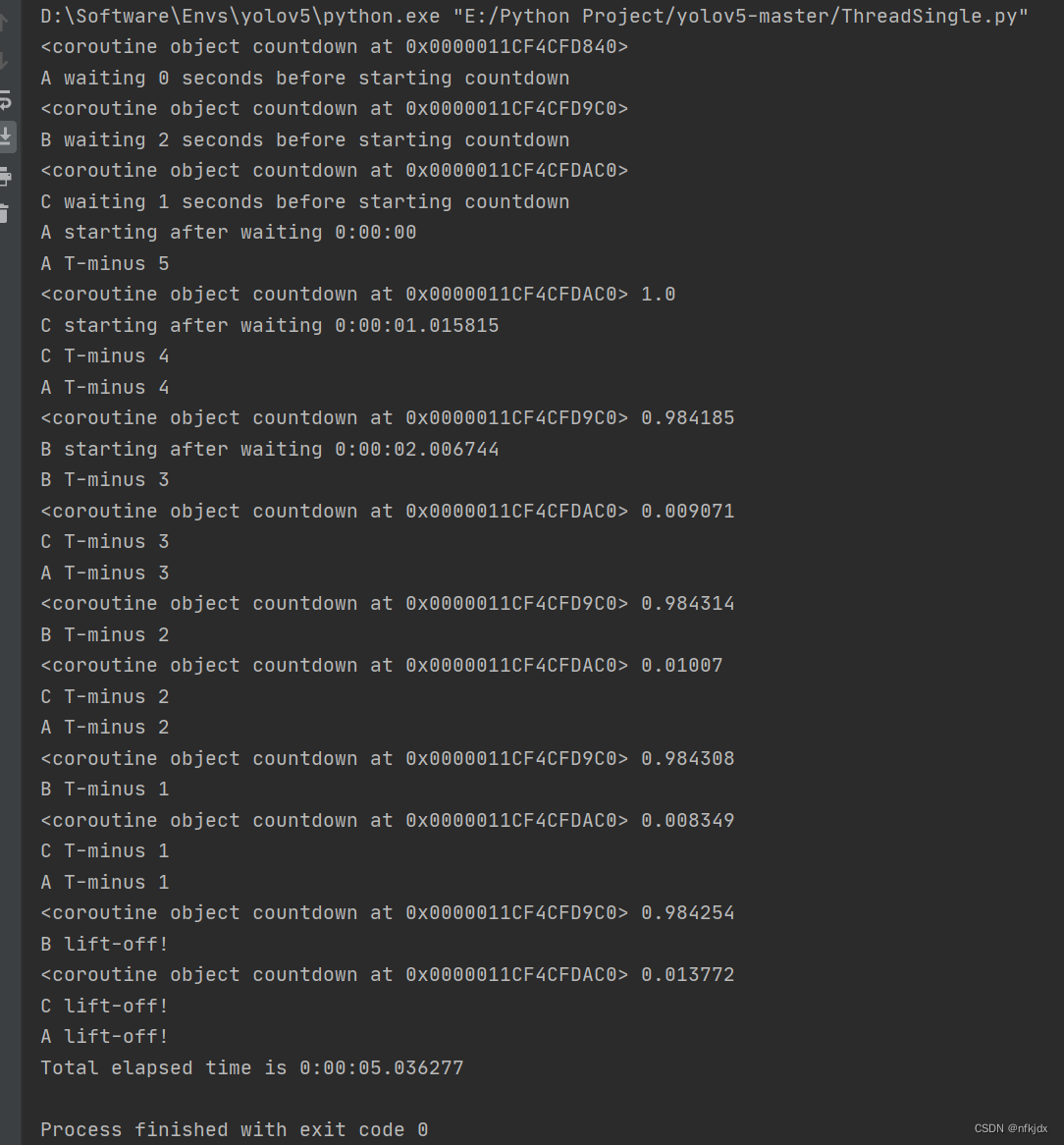
async def countdown(label, length, *, delay=0):
"""协程函数,实现具体的任务"""
print(label, 'waiting', delay, 'seconds before starting countdown')
delta = await sleep(delay)
print(label, 'starting after waiting', delta)
while length:
print(label, 'T-minus', length)
waited = await sleep(1)
length -= 1
print(label, 'lift-off!')
def main():
"""启动事件循环,运行三个协程"""
loop = SleepingLoop(countdown('A', 5), countdown('B', 3, delay=2),
countdown('C', 4, delay=1))
start = datetime.datetime.now()
loop.run_until_complete()
print('Total elapsed time is', datetime.datetime.now() - start)
if __name__ == '__main__':
main()
总结Python异步编程版本细节:
Python 2.5:增强生成器yield。
Python 3.3:引入yield from表达式。
Python 3.4:asyncio作为具有临时API的状态引入Python标准库中。
Python 3.5:async和await成为Python语法的一部分,用于表示和协程,但它们还不是保留关键字。
Python 3.6:引入异步生成器和异步推导式,asyncio的API被宣布为稳定版本而非临时。
Python 3.7:async和await成为保留关键字,它们旨在替换asyncio.coroutine()装饰器。 asyncio.run()被引入asyncio包,简化协程运行,其中还包括许多其他功能。
结果如下:
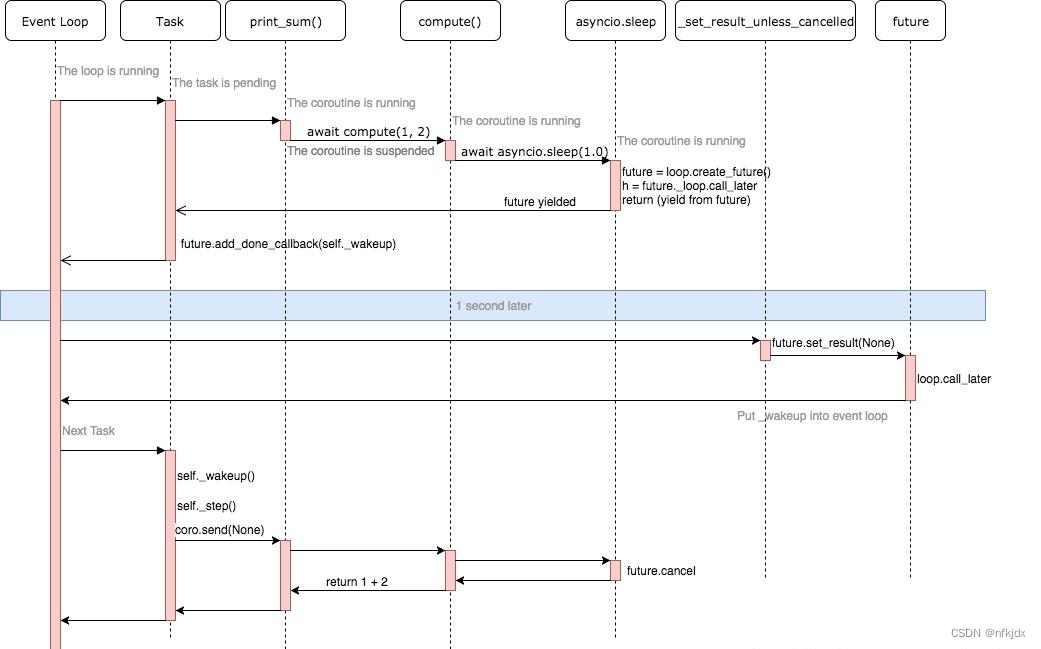
七、asyncio工作原理
简介:
前面提到异步编程是通过事件循环+回调这种模式实现的,但是这种模式会出现回调地狱、错误处理困难、堆栈撕裂等问题,所以Python在事件循环+回调的基础上衍生出了基于协程的解决方案,并不是没有回调,而是巧妙的通过Future对象将回调隐藏其中,方便使用和理解。
asyncio框架中有三个主要组件:协程对象、事件循环和Future&Task对象。
(1)协程对象
协程对象:指一个使用async关键字定义的异步函数,是需要执行的任务,它的调用不会立即执行函数,而是会返回一个协程对象。协程不能直接运行,协程对象需要注册到事件循环,由事件循环调用。
有两种方法可以从协程读取异步函数的输出:
第一种方法是使用await关键字,这只能在异步函数中使用,等待协程终止并返回结果。
第二种方法是将协程添加到事件循环中。
在Python中编写异步函数时要记住的一件事是,在def之前使用了async关键字并不意味着你的异步函数将同时运行。如果采用普通函数并在其前面添加async,则事件循环将运行函数而不会中断,因为你没有指定允许循环中断你的函数以运行另一个协同程序的位置。指定允许事件循环中断运行的位置非常简单,每次使用关键字await等待事件循环都可以停止运行你的函数并切换到运行另一个注册到循环的协同程序。
(2)事件循环
事件循环是执行我们的异步代码并决定如何在异步函数之间切换的对象。如果某个协程在等待某些资源,我们需要暂停它的执行,在事件循环中注册这个事件,以便当事件发生的时候,能再次唤醒该协程的执行。
运行异步函数我们首先需要创建一个协程,然后创建future或task对象,将它们添加到事件循环中,到目前为止,我们的异步函数中没有任何代码被执行过,只有调用loop.run_until_completed启动事件循环,才会开始执行future或task对象,loop.run_until_completed会阻塞程序直到所有的协程对象都执行完毕。
流程图如下:
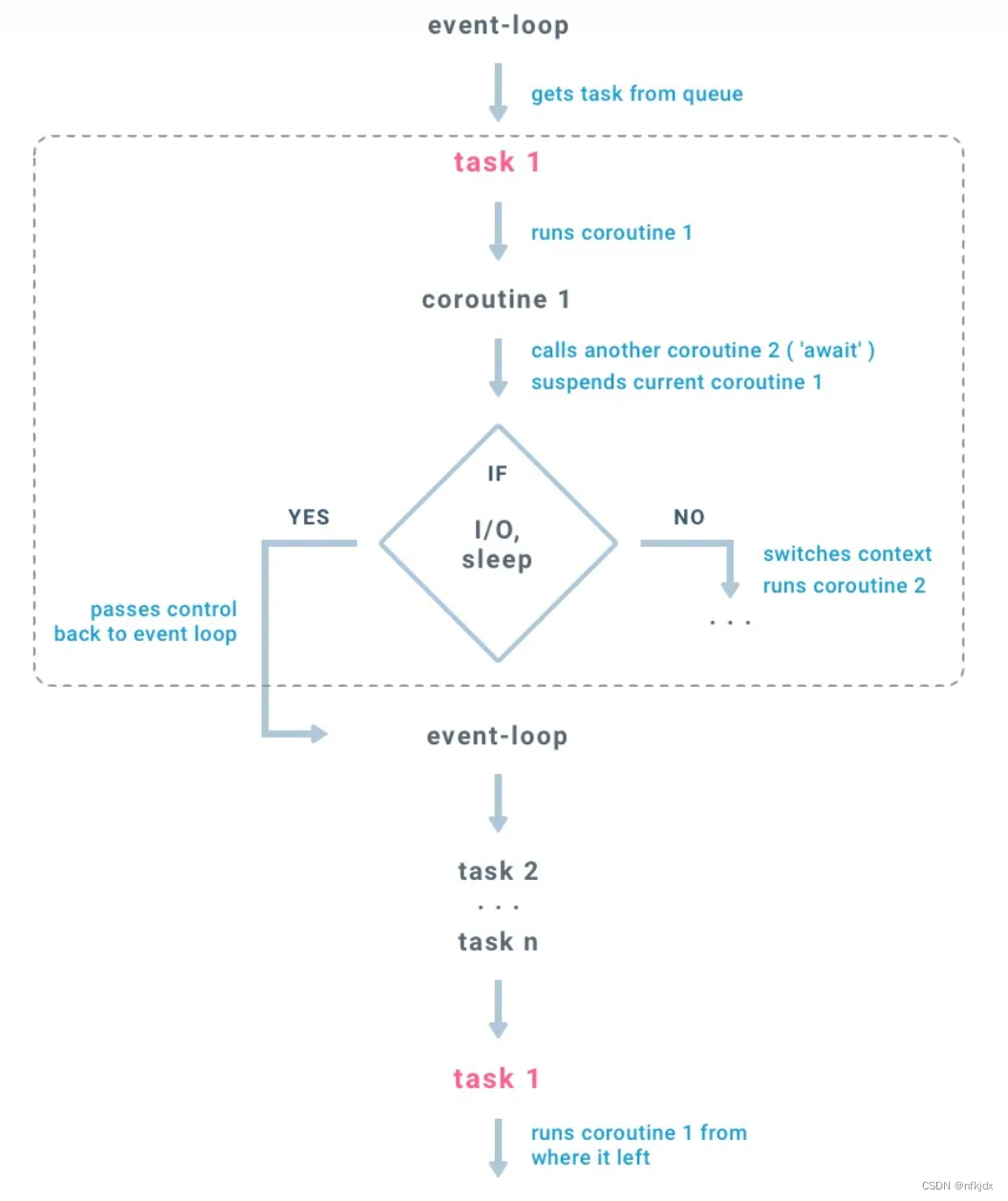
事件循环是在线程中执行
从队列中取得任务
每个任务在协程中执行下一步动作
如果在一个协程中调用另一个协程(await ),会触发上下文切换,挂起当前协程,并保存现场环境(变量,状态),然后载入被调用协程
如果协程的执行到阻塞部分(阻塞I/O,Sleep),当前协程会挂起,并将控制权返回到线程的消息循环中,然后消息循环继续从队列中执行下一个任务...以此类推
队列中的所有任务执行完毕后,消息循环返回第一个任务
(3)Future & Task对象
Future对象
Future对象:Future对象封装了一个未来会被计算的可调用的异步执行对象,他们能被放入队列,他们的状态、结果或者异常能被查询。Future对象有一个result属性,用于存放未来的执行结果。还有个set_result()方法,是用于设置result的,并且会在给result绑定值以后运行事先给Future对象添加的回调。回调是通过Future对象的add_done_callback()方法添加的。
重要的是Future对象不能被我们创建,只能被异步框架创建,有两种方法:
# 该函数在 Python 3.7 中被加入,更加高层次的函数,返回Task对象
future1 = asyncio.create_task(my_coroutine)
# 在Python 3.7 之前,是更加低级的函数,返回Future对象或者Task对象
future2 = asyncio.ensure_future(my_coroutine)
第一种方法在循环中添加一个协程并返回一个task对象,task对象是future的子类型。第二种方法非常相似,当传入协程对象时返回一个Task对象,唯一的区别是它也可以接受Future对象或Task对象,在这种情况下它不会做任何事情并且返回Future对象或者Task对象不变。
Future对象有几个状态:
Pending:就绪
Running:运行
Done:完成
Cancelled:取消
创建Future对象的时候,状态为pending,事件循环调用执行的时候就是running,调用完毕就是done,如果需要取消Future对象的调度执行,可调用Future对象的cancel()函数。
除此之外,Future对象还有下面一些常用的方法:
result():立即返回Future对象运行结果或者抛出执行时的异常,没有timeout参数,如果Future没有完成,不会阻塞等待结果,而是直接抛出InvalidStateError异常。最好的方式是通过await获取运行结果,await会自动等待Future完成返回结果,也不会阻塞事件循环,因为在asyncio中,await被用来将控制权返回给事件循环。
done():非阻塞的返回Future对象是否成功取消或者运行结束或被设置异常,而不是查看future是否已经执行完成。
cancelled():判断Future对象是否被取消。
add_done_callback():传入一个可回调对象,当Future对象done时被调用。
exception():获取Future对象中的异常信息,只有当Future对象done时才会返回。
get_loop():获取当前Future对象绑定的事件循环。
需要注意的是,当在协程内部引发未处理的异常时,它不会像正常的同步编程那样破坏我们的程序,相反,它存储在future内部,如果在程序退出之前没有处理异常,则会出现以下错误:
Task exception was never retrieved
有两种方法可以解决此问题,在访问future对象的结果时捕获异常或调用future对象的异常函数:
try:
# 调用结果时捕获异常
my_promise.result()
catch Exception:
pass
# 获取在协程执行过程中抛出的异常
my_promise.exception()
Task对象
Task对象:Task对象是Future对象的子类型,coroutine和Future联系在一起。与 Future 不同的是它包含了一个将要执行的协程,从而组成一个需要被调度的任务,Task类用来管理协同程序运行的状态,负责在事件循环中执行一个协程对象,是一个协程驱动器,用来恢复继续执行生成器,管理生成器的状态。
Task对象被用来在事件循环中运行协程。如果一个协程在等待一个Future对象,Task对象会挂起该协程的执行并等待该Future对象完成。当该Future对象完成,被暂停的协程将恢复执行。事件循环使用协作调度: 一个事件循环每次运行一个Task对象。当一个Task对象等待一个Future对象完成时,该事件循环会运行其他Task、回调或执行IO操作。
使用高层级的asyncio.create_task()函数来创建Task对象,也可用低层级的loop.create_task()或ensure_future()函数。不建议手动实例化 Task 对象。
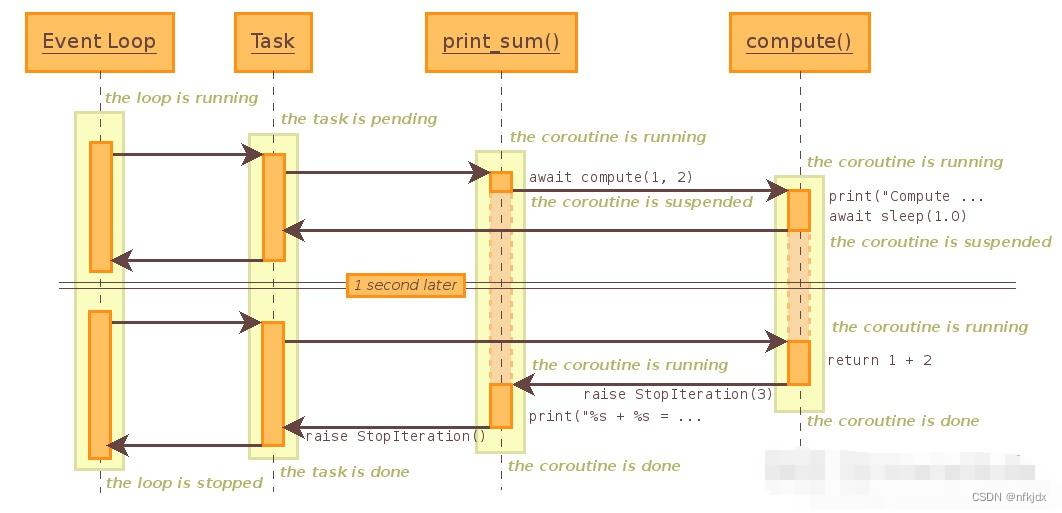
例子:
import asyncio
import time
async def compute(x, y):
print("Compute {} + {}...".format(x, y))
await asyncio.sleep(2.0)
return x+y
async def print_sum(x, y):
result = await compute(x, y)
print("{} + {} = {}".format(x, y, result))
start = time.time()
loop = asyncio.get_event_loop()
tasks = [
asyncio.ensure_future(print_sum(0, 0)),
asyncio.ensure_future(print_sum(1, 1)),
asyncio.ensure_future(print_sum(2, 2)),
]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print("Total elapsed time {}".format(time.time() - start))
结果:
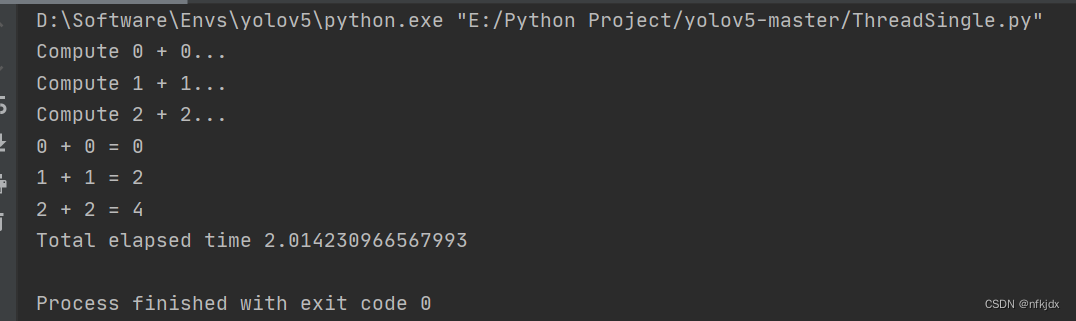
代码的执行流程:
八、asyncio使用详解
协程完整的工作流程是这样:
定义/创建协程对象
将协程转为task任务
定义事件循环对象容器
将task任务扔进事件循环对象中触发运行
协程:协程通过 async/await 语法进行声明,是编写异步应用的推荐方式。注意:简单地调用一个协程并不会将其加入执行队列。
要真正运行一个协程,asyncio 提供了三种主要机制:
1. asyncio.run() 函数用来运行最高层级的入口点协程函数。该函数运行传入的协程,负责管理asyncio事件循环并结束异步生成器。当有其他asyncio事件循环在同一线程中运行时,此函数不能被调用。如果debug为True,事件循环将以调试模式运行。该函数总是会创建一个新的事件循环并在结束时关闭。它应当被用作asyncio程序的主入口点,理想情况下应当只被调用一次。该函数在Python 3.7被引入,会隐式处理事件循环。
2.使用await关键字等待一个协程。
3. asyncio.create_task()函数用来并发运行作为asyncio任务的多个协程。当一个协程通过asyncio.create_task()等函数被打包为一个Task对象,该协程将自动排入队列准备立即运行。然后通过await或者asyncio.run()自动运行该任务。该函数在Python 3.7中被加入。在Python 3.7之前,可以改用低层级的asyncio.ensure_future()函数。
三种运行方式代码如下:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
return delay
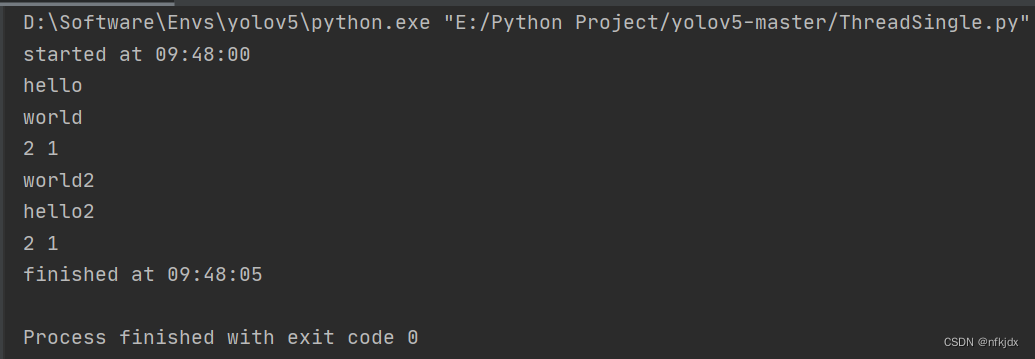
async def main():
print(f"started at {time.strftime('%X')}")
# 通过await等待运行,此时两个任务按顺序运行
result1 = await say_after(2, 'hello')
result2 = await say_after(1, 'world')
print(result1, result2)
task1 = asyncio.create_task(say_after(2, 'hello2'))
task2 = asyncio.create_task(say_after(1, 'world2'))
# 通过asyncio.task()包装为task然后await等待运行,此时两个任务并发运行
result3 = await task1
result4 = await task2
print(result3, result4)
print(f"finished at {time.strftime('%X')}")
# 通过asyncio.run()函数运行
asyncio.run(main())
# 下面相当于上面的asyncio.run()函数
# loop = asyncio.get_event_loop()
# try:
# loop.run_until_complete(main())
# finally:
# loop.close()
结果如下:
可等待对象:如果一个对象可以在await语句中使用,那么它就是可等待对象。许多 asyncio API 都被设计为接受可等待对象。可等待对象有三种主要类型:协程、Task对象和Future对象。
Future对象:Future对象是一种特殊的低层级可等待对象,表示一个异步操作的最终结果。当一个Future对象被等待,这意味着协程将保持等待直到该Future对象在其他地方操作完毕。在asyncio中需要Future对象以便允许通过async/await使用基于回调的代码。通常情况下没有必要在应用层级的代码中创建Future对象。
asyncio.sleep():阻塞delay指定的秒数。如果指定了result,则当协程完成时将其返回给调用者。sleep()总是会挂起当前任务,以允许其他任务运行。
注意:如果不在main()函数中await其他协程,其他协程可能来不及运行就被取消了。因为asyncio.run(main())调用的式是loop.run_until_complete(main()),在没有await的情况下,事件循环只关注main()函数一个协程的结束,而不管main()函数中的其他协程任务,没有await,其他协程任务可能在任务完成前被取消。如果需要获取当前待处理Task对象的列表,可以使用asyncio.all_tasks()函数,使用asyncio.current_task()函数获取当前运行的Task实例,如果没有正在运行的任务则返回None。
并发运行任务:
如上面所介绍,使用 create_task() 可以并发执行程序。asyncio 同时提供了几个函数用于方便地实现多任务并发执行:
1. asyncio.gather(*aws, return_exceptions=False)
gather() 函数接受传入多个可等待对象 aws,如果某个可等待对象是协程,则会被自动打包成 Task。gather() 返回结果是和 aws 传入顺序一致的列表。gather() 同时可以传入参数 return_exceptions 来处理异常,默认值为 False。如果为 False 时,执行过程中引发的首个异常会立即返回给等待 gather() 的任务,await 会直接结束等待并抛出异常,但是其它正常执行的 Task 不会被取消,这种情况适用于确保任务尽可能被执行完成,但是不关心返回结果,因为如果有任何一个任务出现异常,返回结果列表就不会顺利生成。如果把 return_exceptions 设为 True,异常会和正常结果一同被聚合进最终结果列表,适用于对结果有需求应用场景。
例子:
import asyncio
import time
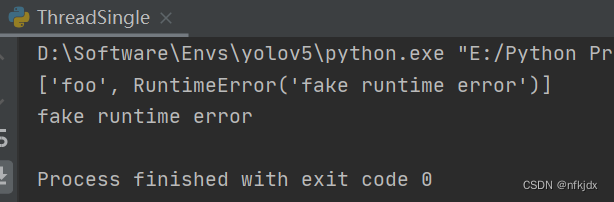
async def foo():
return 'foo'
async def bar():
raise RuntimeError('fake runtime error')
async def main():
task1 = asyncio.create_task(foo())
task2 = asyncio.create_task(bar())
# return_exceptions=True
results = await asyncio.gather(task1, task2, return_exceptions=True)
# 输出: ['foo', RuntimeError('fake runtime error')]
print(results)
# 返回结果的顺序和传参顺序一致
assert isinstance(results[1], RuntimeError)
# return_exceptions=False
try:
results = await asyncio.gather(task1, task2, return_exceptions=False)
# 此处打印并不会被执行, results 也未被赋值
print(results)
except RuntimeError as runtime_err:
# 捕获异常并打印: fake runtime error
print(runtime_err)
asyncio.run(main())
结果如下:
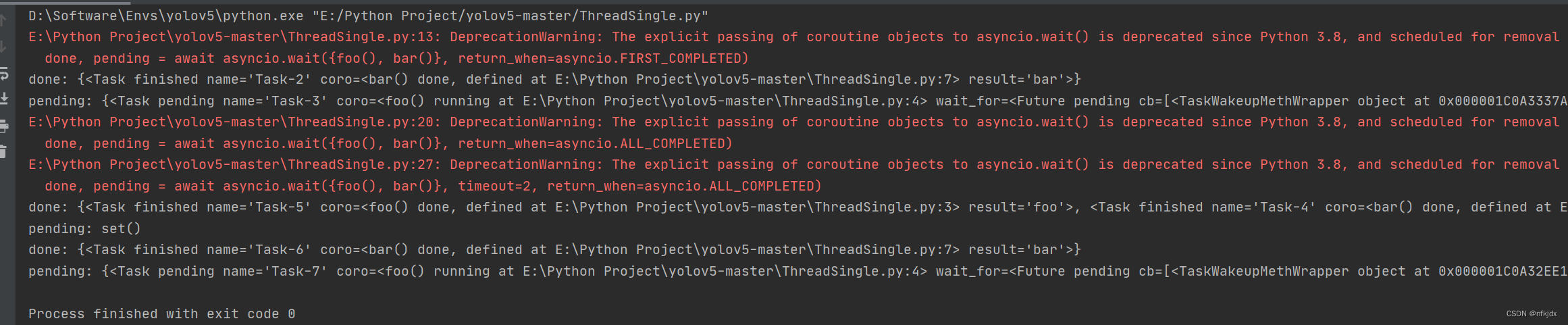
2. asyncio.wait(aws, *, timeout=None, return_when=ALL_COMPLETED)
wait() 接受 aws 任务集合传入, 然后并发执行。参数 return_when 用来控制返回条件,当 return_when=ALL_COMPLETED 时,会在所有任务完成后返回结果;当 return_when=FIRST_COMPLETED 时,任务集合中有一个任务完成就立即返回结果。timeout 参数用来控制超时时间,可以是整数或浮点数,以秒为单位。wait() 的返回值是 (done, pending) 元组,done 中包含运行完成的任务,pending 中包含未完成被挂起的任务。
代码示例如下:
import asyncio
import time
async def foo():
await asyncio.sleep(3)
return 'foo'
async def bar():
await asyncio.sleep(1)
return 'bar'
async def main():
# 有一个任务执行完成即返回, 总共耗时 1 秒
done, pending = await asyncio.wait({foo(), bar()}, return_when=asyncio.FIRST_COMPLETED)
# done 集合里包含打包成 Task 的 bar()
print(f'done: {done}')
# pendding 集合里包含打包成 Task 的 foo()
print(f'pending: {pending}')
# 所有任务执行完成后返回, 总共耗时 3 秒
done, pending = await asyncio.wait({foo(), bar()}, return_when=asyncio.ALL_COMPLETED)
# done 集合里包含被带打包成 Task 的 foo() 和 bar()
print(f'done: {done}')
# pending 集合为空
print(f'pending: {pending}')
# 所有任务执行完成, 但运行时间不能超 2 秒后返回, 总共耗时 2 秒
done, pending = await asyncio.wait({foo(), bar()}, timeout=2, return_when=asyncio.ALL_COMPLETED)
# done 集合里包含打包成 Task 的 bar()
print(f'done: {done}')
# pendding 集合里包含打包成 Task 的 foo()
print(f'pending: {pending}')
asyncio.run(main())
结果如下:
3. asyncio.as_completed(aws)
as_completed() 接受 aws 集合,然后返回一个 Future 迭代器,遍历这个迭代器会依次遍历剩余可等待对象集合中最早完成的结果。
例子:
import asyncio
import time
async def foo():
await asyncio.sleep(2)
return 'foo'
async def bar():
await asyncio.sleep(1)
return 'bar'
async def main():
for fut in asyncio.as_completed({foo(), bar()}):
earliest_result = await fut
# 会依次打印 bar 和 foo, 因为 bar() 会更早执行完毕
print(earliest_result)
asyncio.run(main())
上面介绍多任务并发时引入了超时的概念,超时也可以被应用在单独的一个任务中,使用 asyncio.wait_for(aw, timeout) 函数,该函数接受一个任务 aw 和超时时间 timeout,如果在限制时间内完成,则会正常返回,否则会被取消并抛出 asyncio.TimeoutError 异常。
为了防止任务被取消,可以使用 asyncio.shield(aw) 进行保护。shield() 会屏蔽外部取消操作,如果外部任务被取消,其内部正在执行的任务不会被取消,在内部看来取消操作并没有发生,由于内部仍正常执行,执行完毕后会触发 asyncio.CancelledError 异常,如果确保程序能忽略异常继续执行,需要在外部使用 try-except 捕获异常。如果在任务内部取消,则会被成功取消。
回调
可通过task.add_done_callback()方法给任务添加回调函数,当任务执行完成时会自动调用该函数并传入Task对象。
import asyncio
def callback(task):
print(task, "done")
async def hello():
print("hello")
await asyncio.sleep(0)
async def main():
task = asyncio.create_task(hello())
task.add_done_callback(callback)
await task
asyncio.run(main())
结果如下:

队列
asyncio框架的队列设计的和queue模块的很类似。尽管asyncio模块的队列不是线程安全的,它们被设计为专门用于async/await代码。需要注意的是asyncio的队列没有timeout参数,可使用asyncio.wait_for()函数进行超时等待。
import asyncio
import itertools as it
import os
import random
import time
async def makeitem(size: int = 5) -> str:
return os.urandom(size).hex()
async def randint(a: int, b: int) -> int:
return random.randint(a, b)
async def randsleep(a: int = 1, b: int = 5, caller=None) -> None:
i = await randint(a, b)
if caller:
print(f"{caller} sleeping for {i} seconds.")
await asyncio.sleep(i)
async def produce(name: int, q: asyncio.Queue) -> None:
"""生产者"""
n = await randint(1, 5)
for _ in it.repeat(None, n): # 同步添加任务
await randsleep(caller=f"Producer {name}")
i = await makeitem()
t = time.perf_counter()
await q.put((i, t))
print(f"Producer {name} added <{i}> to queue.")
async def consume(name: int, q: asyncio.Queue) -> None:
"""消费者"""
while True:
await randsleep(caller=f"Consumer {name}")
i, t = await q.get()
now = time.perf_counter()
print(f"Consumer {name} got element <{i}>"
f" in {now - t:0.5f} seconds.")
q.task_done()
async def main(nprod: int, ncon: int):
q = asyncio.Queue()
# asyncio.run()会自动运行消费者和生产者
producers = [asyncio.create_task(produce(n, q)) for n in range(nprod)]
consumers = [asyncio.create_task(consume(n, q)) for n in range(ncon)]
await asyncio.gather(*producers) # 等待生产者结束
await q.join() # 阻塞直到队列中的所有项目都被接收和处理
# 取消消费者
for c in consumers:
c.cancel()
if __name__ == "__main__":
random.seed(444)
start = time.perf_counter()
asyncio.run(main(2, 3))
elapsed = time.perf_counter() - start
print(f"Program completed in {elapsed:0.5f} seconds.")
上面的代码逻辑流程如下:
将向队列put任务的操作单独编写为一个生产者协程。
启动生产者和消费者
等待生产者结束,通过await producer()或者await gather(*producers),或者其他方式。
一旦生产者结束,通过await q.join()等待队列中所有的项目被接受和处理完
取消消费者任务,否则消费者会一直等待不可能出现的下一个任务。
结果如下:

结合线程和进程:
多线程
默认情况下,事件循环在主线程中运行,并在其线程中执行所有回调和任务,同一时刻只有一个任务在执行。需要注意的是:要处理信号和执行子进程,必须在主线程中运行事件循环。
如何将异步代码和多线程结合在一起使用,有下面几种方法:
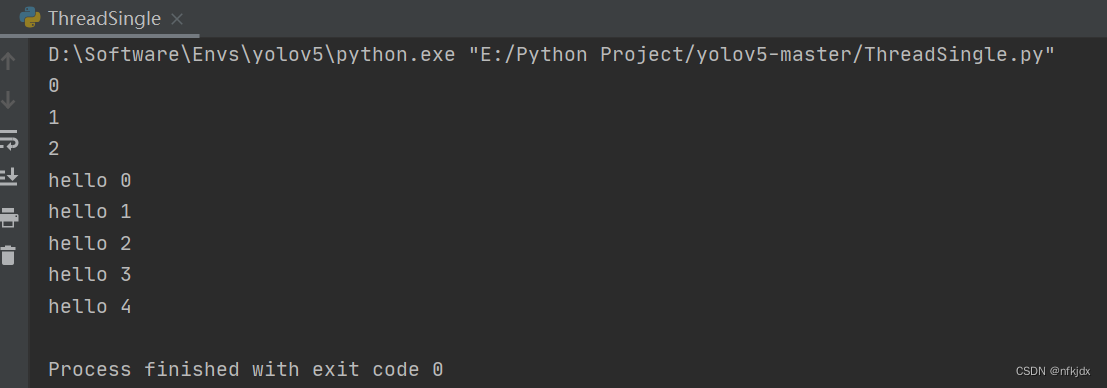
方法一:启动一个子线程,在子线程中运行异步代码:
import asyncio
from threading import Thread
async def hello(i):
print("hello", i)
await asyncio.sleep(i)
return i
async def main():
tasks = [asyncio.create_task(hello(i)) for i in range(5)]
await asyncio.gather(*tasks)
def async_main():
asyncio.run(main())
# 在子线程中运行异步任务
t = Thread(target=async_main)
t.start()
# 不会干扰主线程
for i in range(3):
print(i)
结果如下:
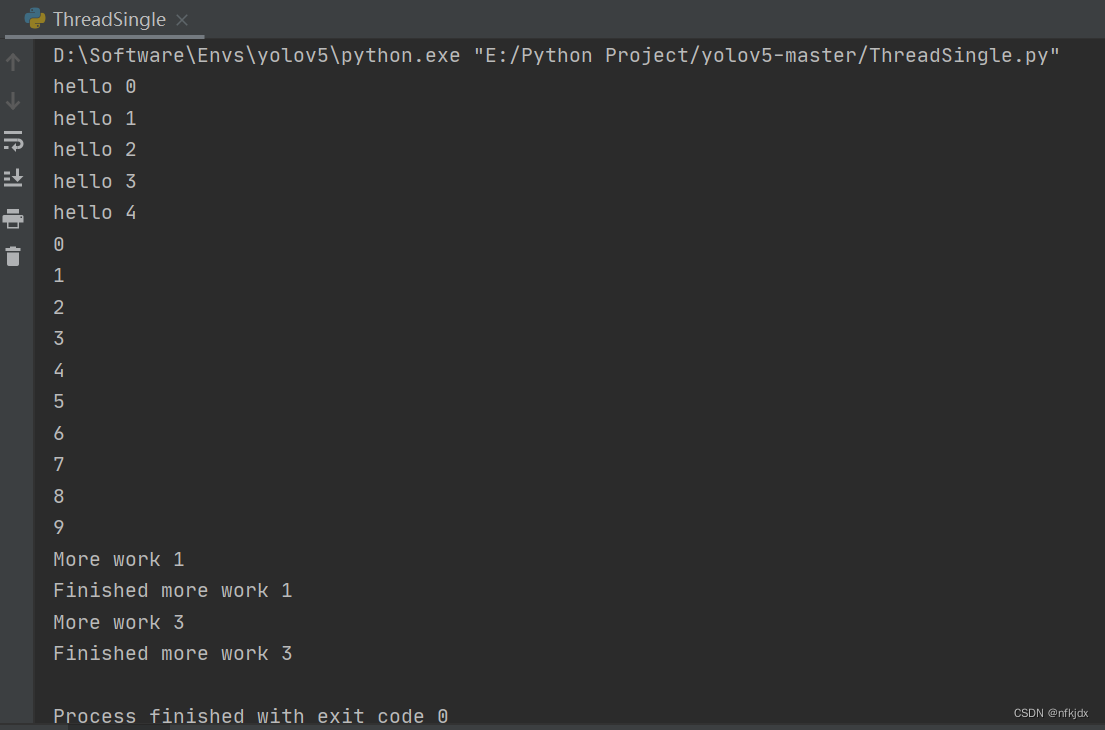
方法二:loop.call_soon_threadsafe()函数
loop.call_soon()用于注册回调,当异步任务执行完成时会在当前线程按顺序执行注册的普通函数。
loop.call_soon_threadsafe()用于在一个线程中注册回调函数,在另一个线程中执行注册的普通函数。
from threading import Thread
import asyncio
import time
async def hello(i):
print("hello", i)
await asyncio.sleep(i)
return i
async def main():
tasks = [asyncio.create_task(hello(i)) for i in range(5)]
await asyncio.gather(*tasks)
def start_loop(loop):
asyncio.set_event_loop(loop)
loop.run_until_complete(main())
def more_work(x):
print('More work {}'.format(x))
time.sleep(x)
print('Finished more work {}'.format(x))
# 在主线程创建事件循环,并在另一个线程中启动
new_loop = asyncio.new_event_loop()
t = Thread(target=start_loop, args=(new_loop,))
t.start()
# 在主线程中注册回调函数,在子线程中按顺序执行回调函数
new_loop.call_soon_threadsafe(more_work, 1)
new_loop.call_soon_threadsafe(more_work, 3)
# 不会阻塞主线程
for i in range(10):
print(i)
结果:
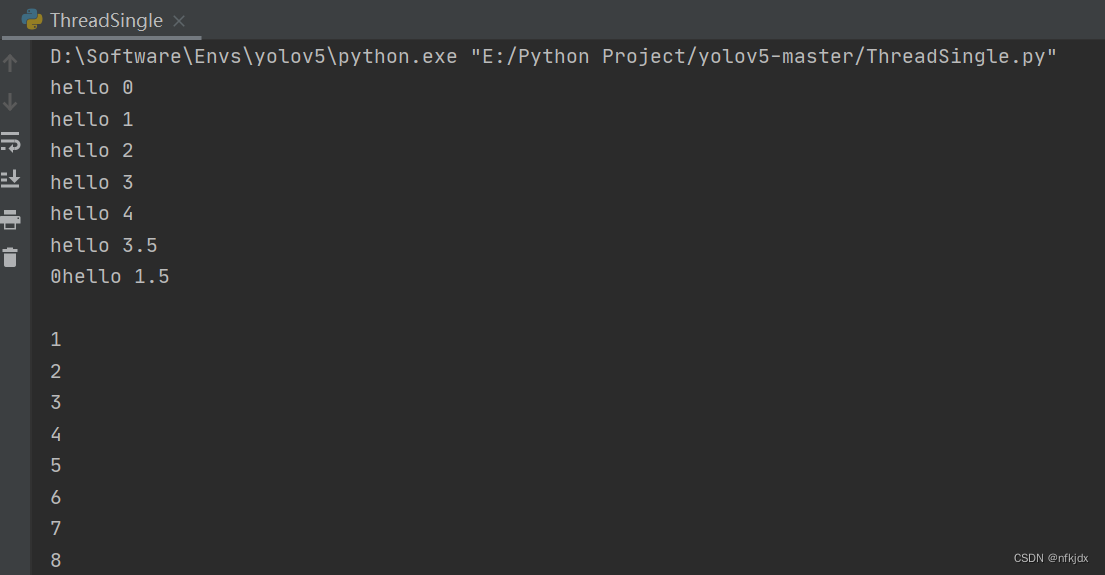
方法三:asyncio.run_coroutine_threadsafe()函数
loop.call_soon_threadsafe()函数是同步执行回调函数,asyncio.run_coroutine_threadsafe()函数则是异步执行回调函数,传入写成函数
from threading import Thread
import asyncio
import time
async def hello(i):
print("hello", i)
await asyncio.sleep(i)
return i
async def main():
tasks = [asyncio.create_task(hello(i)) for i in range(5)]
await asyncio.gather(*tasks)
def start_loop(loop):
asyncio.set_event_loop(loop)
loop.run_until_complete(main())
# 在主线程创建事件循环,并在另一个线程中启动
new_loop = asyncio.new_event_loop()
t = Thread(target=start_loop, args=(new_loop,))
t.start()
# 在主线程中注册回调协程函数,在子线程中按异步执行回调函数
asyncio.run_coroutine_threadsafe(hello(3.5), new_loop)
asyncio.run_coroutine_threadsafe(hello(1.5), new_loop)
# 不会阻塞主线程
for i in range(10):
print(i)
结果:
方法四:loop.run_in_executor(executor, func, *args)
asyncio的事件循环在背后维护着一个ThreadPoolExecutor对象,我们可以调用run_in_executor方法,把可调用对象发给它执行。
loop.run_in_executor()函数用于在特定的executor中执行函数。executor参数必须是 concurrent.futures.Executor实例对象,传入None表示在默认的executor中执行。返回一个可等待的协程对象。
import asyncio
import concurrent.futures
import time
def blocks(n):
"""阻塞任务"""
time.sleep(0.1)
return n ** 2
async def run_blocking_tasks(executor):
loop = asyncio.get_event_loop()
# 在线程池中执行阻塞任务
blocking_tasks = [
loop.run_in_executor(executor, blocks, i)
for i in range(6)
]
completed, pending = await asyncio.wait(blocking_tasks)
results = [t.result() for t in completed]
print(results)
# 创建线程池
executor = concurrent.futures.ThreadPoolExecutor(max_workers=3)
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(run_blocking_tasks(executor))
finally:
event_loop.close()
结果:

结合多进程
方法一:启动一个子进程,在子进程中运行异步代码
import asyncio
import multiprocessing
async def hello(i):
print("hello", i)
await asyncio.sleep(1)
def strap(tx, rx):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(hello(3))
# 启动一个子线程,在子线程中运行异步代码
p = multiprocessing.Process(target=strap, args=(1, 3))
p.start()
# 子进程和主进程不会相互干扰
for i in range(10):
print(i)
方法二:loop.run_in_executor(executor, func, *args)
和多线程一样,只不过是把线程池换成进程池。
import asyncio
import concurrent.futures
import time
def blocks(n):
"""阻塞任务"""
time.sleep(0.1)
return n ** 2
async def run_blocking_tasks(executor):
loop = asyncio.get_event_loop()
# 在进程池中执行阻塞任务
blocking_tasks = [
loop.run_in_executor(executor, blocks, i)
for i in range(6)
]
completed, pending = await asyncio.wait(blocking_tasks)
results = [t.result() for t in completed]
print(results)
# 创建进程池
executor = concurrent.futures.ProcessPoolExecutor(max_workers=3)
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(run_blocking_tasks(executor))
finally:
event_loop.close()
方法三:第三方库aiomultiprocess
第三方库aiomultiprocess可以方面的将异步代码和多进程结合使用,下面是官方demo:
import asyncio
from aiohttp import request
from aiomultiprocess import Worker
async def get(url):
async with request("GET", url) as response:
return await response.text("utf-8")
async def main():
p = Worker(target=get, args=("https://jreese.sh", ))
response = await p
asyncio.run(main())
aiomultiprocess,我认为他确实是 Python 升级到 3.8 之后一个特性的总结库,包括静态检查和性能提升。作者实际上结合了 Python 的三个特性:
multiprocess
asyncio
map/reduce
这三个库其实都是很普通的库,使用过 Python3 之后的版本,基本上都会接触到,那为什么作者可以从这三个库上面获取到比较好的性能?主要是因为他在这三个库的基础上优化了协程的调度方式。
优化后的协程调度方式更加类似于 Golang 的调度方式,唯一的差异是少了抢占式调度的思路,仅仅使用了 RoundRobin 的方式,所以 IO 性能跟 Go 还有差距,但是肯定比 Nodejs 的性能要好一些。
aiomultiprocess 为什么更快?
aiomultiprocess 将异步 IO 和多进程结合起来了,很好的利用了多核和异步 IO 的优势,前面说到 Python 是单进程的,所以即使有 AsyncIO 那么也并没有充分利用操作系统的资源,相对来说还不是很快,但是结合了多进程之后,性能就可以线性增长了。
Golang 为什么更快?
既然充分了利用了多核,那么为什么还是比 Golang 慢?主要还是调度器的原因,Golang 是抢占式调度,目前 facebook 的这个版本主要是通过 RoundRobin 调度的,默认认为每一个任务和每一个 worker 的执行时间是固定的,但是如果出现比较意外的情况,比如系统资源占用,就会导致进程出现假死,那么依附在进程队列上面的任务也不能得到调度,为此作者增加了进程的生命之周期管理 TTL,执行一定的任务之后,自毁并重新创建进程,这种方式可以缓解调度问题,但是粒度还是比较粗。
用法
在子进程中执行协程
import asyncio
from aiohttp import request
from aiomultiprocess import Process
async def put(url, params):
async with request("PUT", url, params=params) as response:
pass
async def main():
p = Process(target=put, args=("https://jreese.sh", {}))
await p
if __name__ == "__main__":
asyncio.run(main())
如果您想从协程中获取结果Worker,请使用以下方法:
import asyncio
from aiohttp import request
from aiomultiprocess import Worker
async def get(url):
async with request("GET", url) as response:
return await response.text("utf-8")
async def main():
p = Worker(target=get, args=("https://jreese.sh", ))
response = await p
if __name__ == "__main__":
asyncio.run(main())
如果您需要一个托管的工作进程池,请使用Pool:
import asyncio
from aiohttp import request
from aiomultiprocess import Pool
async def get(url):
async with request("GET", url) as response:
return await response.text("utf-8")
async def main():
urls = ["https://jreese.sh", ...]
async with Pool() as pool:
result = await pool.map(get, urls)
if __name__ == "__main__":
asyncio.run(main())
简单顺序执行:
import asyncio
async def task1():
print("Task 1 started")
await asyncio.sleep(2) # 模拟耗时操作
print("Task 1 completed")
async def task2():
print("Task 2 started")
await asyncio.sleep(1) # 模拟耗时操作
print("Task 2 completed")
async def main():
# 顺序执行任务
await task1()
await task2()
def run_main():
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main())
finally:
loop.close()
# 运行主函数
run_main()
简单并发执行:
import asyncio
async def task1():
print("Task 1 started")
await asyncio.sleep(2) # 模拟耗时操作
print("Task 1 completed")
async def task2():
print("Task 2 started")
await asyncio.sleep(1) # 模拟耗时操作
print("Task 2 completed")
async def main():
# 并发执行任务
await asyncio.gather(task1(), task2())
# 运行主函数
asyncio.run(main())
以上就是关于线程、进程与异步的简单介绍和实现,里面可能有一些不足之处,大家可以指出和借鉴!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 单例模式---JAVA
- RK3568驱动指南|第十二篇 GPIO子系统-第129章 GPIO控制和操作实验
- TKEStack容器管理平台实战之部署wordpress应用
- Zookeeper注册中心实战
- do{ __HAL_RCC_GPIOH_CLK_ENABLE(); }while(0);
- C#Winform+DevExpress打开相机拍照功能实例
- 【自动化测试】selenium元素定位方式大全!
- C# Wpf MVVM 框架下的线程并发与异步编程
- 静态代理还是动态代理?来聊聊Java中的代理设计模式
- fastadmin传递参数给html和js,通过身份判断动态显示列表头部住店和离店按钮