实战干货:用 Python 批量下载百度图片!
发布时间:2024年01月05日
为了做一个图像分类的小项目,需要制作自己的数据集。要想制作数据集,就得从网上下载大量的图片,再统一处理。
这时,一张张的保存下载,就显得很繁琐。那么,有没有一种方法可以把搜索到的图片直接下载到本地电脑中呢?
有啊!用python吧!
我以“泰迪”、“柯基”、“拉布拉多”等为关键词,分别下载了500张图片。下一篇,我打算写一个小狗分类器,不知道各位意见如何!
结果演示:
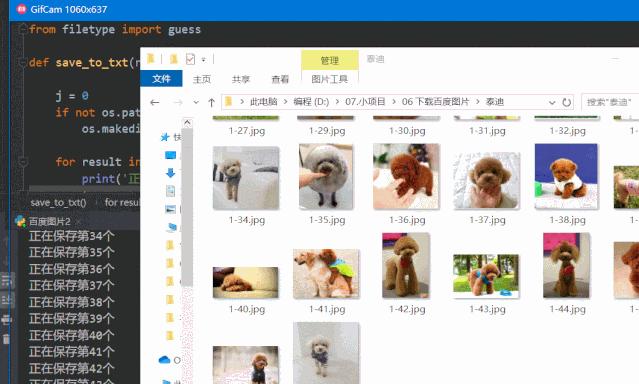
首先,打开百度图片首页,注意下图url中的index

接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片!
对比了几个url发现,pn参数是请求到的数量。通过修改pn参数,观察返回的数据,发现每页最多只能是60个图片。
注:gsm参数是pn参数的16进制表达,去掉无妨

然后,右键检查网页源代码,直接(ctrl+F)搜索 objURL

这样,我们发现了需要图片的url了。
2.把图片链接保存到本地
现在,我们要做的就是将这些信息爬取出来。注:网页中有objURL,hoverURL…但是我们用的是objURL,因为这个是原图那么,如何获取objURL?用正则表达式!那我们该如何用正则表达式实现呢?其实只需要一行代码…
results = re.findall('"objURL":"(.*?)",', html) 核心代码:
1.获取图片url代码:
# 获取图片url连接
def get_parse_page(pn,name):
for i in range(int(pn)):
# 1.获取网页
print('正在获取第{}页'.format(i+1))
# 百度图片首页的url
# name是你要搜索的关键词
# pn是你想下载的页数
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d' %(name,i*20)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400'}
# 发送请求,获取相应
response = requests.get(url, headers=headers)
html = response.content.decode()
# print(html)
# 2.正则表达式解析网页
# "objURL":"http://n.sinaimg.cn/sports/transform/20170406/dHEk-fycxmks5842687.jpg"
results = re.findall('"objURL":"(.*?)",', html) # 返回一个列表
# 根据获取到的图片链接,把图片保存到本地
save_to_txt(results, name, i)2.保存图片到本地代码:
# 保存图片到本地
def save_to_txt(results, name, i):
j = 0
# 在当目录下创建文件夹
if not os.path.exists('./' + name):
os.makedirs('./' + name)
# 下载图片
for result in results:
print('正在保存第{}个'.format(j))
try:
pic = requests.get(result, timeout=10)
time.sleep(1)
except:
print('当前图片无法下载')
j += 1
continue
# 可忽略,这段代码有bug
# file_name = result.split('/')
# file_name = file_name[len(file_name) - 1]
# print(file_name)
#
# end = re.search('(.png|.jpg|.jpeg|.gif)$', file_name)
# if end == None:
# file_name = file_name + '.jpg'
# 把图片保存到文件夹
file_full_name = './' + name + '/' + str(i) + '-' + str(j) + '.jpg'
with open(file_full_name, 'wb') as f:
f.write(pic.content)
j += 1
核心代码:
pic = requests.get(result, timeout=10)
f.write(pic.content)3.主函数代码:
# 主函数
if __name__ == '__main__':
name = input('请输入你要下载的关键词:')
pn = input('你想下载前几页(1页有60张):')
get_parse_page(pn, name)
使用说明:

# 配置以下模块
import requests
import re
import os
import time
# 1.运行 py源文件
# 2.输入你想搜索的关键词,比如“柯基”、“泰迪”等
# 3.输入你想下载的页数,比如5,那就是下载 5 x 60=300 张图片
文章来源:https://blog.csdn.net/m0_69824302/article/details/135417630
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LeetCode(67)相同的树【二叉树】【简单】
- 一键生成mybatis 相关类
- k8s---helm
- JavaScript中的变量、关键字、保留字
- Java中的八种基础数据类型及其数据库对应类型详解
- mybatis TDSQL 避免事务失效 双层service
- 鸿蒙开发基本概念
- Spss Amos 27安装包下载及安装教程
- OceanBase架构概览
- 174.【2023年华为OD机试真题(C卷)】开源项目热榜(一般排序算法实现Java&Python&C++&&JS)