16、佛罗里达理工学院提出:seUNet:自动化医学图像分割领域极致的个人英雄主义
论文由美国佛罗里达理工学院三位学生于2023年11月10日,在arXiv的《Electrical Engineering and Systems Science》期刊中发表。三位作者鉴于自动化医学图像分割诊断对现代临床医学的实践变得愈发的重要,也鉴于目前机器学习算法的进步,共同提出seUNet:一种简单而有效的医学图像分割UNet-Transformer模型。

论文:《seUNet-Trans: A Simple yet Effective UNet-Transformer Model for Medical Image
Segmentation》

0、Abstract:
自动化医学图像分割在现代临床实践中变得越来越重要,这是由于对精确诊断的需求不断增长,个性化治疗计划的推动以及机器学习算法的进步,尤其是深度学习方法的应用。虽然卷积神经网络(CNN)在这些方法中很常见,但越来越多的人开始认识到Transformer-based模型在计算机视觉任务中具有巨大潜力。
为了充分发挥CNN-based和Transformer-based模型的优势,作者提出了一种简单而有效的UNet-Transformer(seUNet-Trans)模型用于医学图像分割。在作者的方法中,UNet模型被设计为特征提取器,从输入图像生成多个特征图,这些特征图传递到一个桥接层,该层被引入以顺序连接UNet和Transformer。在这个阶段,作者采用了像素级嵌入技术,而不是位置嵌入向量,以使模型更高效。
此外,作者在Transformer中应用了空间降维注意力来减少计算和内存开销。通过利用UNet架构和自注意力机制,作者的模型不仅保留了局部和全局上下文信息的保留,还能够捕捉输入元素之间的长程依赖关系。
作者在包括息肉分割在内的5个医学图像分割数据集上广泛进行了实验,以展示其有效性。与几种最先进的分割模型在这些数据集上的比较表明,seUNet-Trans Net表现出卓越的性能。
1、Introduction:
医学图像分割涉及从复杂的医学图像中识别和提取有意义的信息,这在许多临床应用中起着至关重要的作用,包括计算机辅助诊断、图像引导手术和治疗规划。迄今为止,由受过培训的专家(如放射科医师或病理学家)进行手动分割仍然是描绘解剖结构和病理异常的黄金标准。
然而,这一过程昂贵、劳动密集,通常需要丰富的经验。相比之下,基于深度学习的模型已经表现出卓越的性能,能够以高精度和速度自动分割感兴趣的目标,因为它们能够学习和理解医学图像中的复杂模式和特征。因此,基于深度学习的自动化医学图像分割在临床实践中需求旺盛且备受青睐。
作为各种图像分割模型的重要子集,卷积神经网络(CNN)已经在许多医学图像分割任务中表现出极高的效果和巨大的潜力,尤其是UNet,一种完全卷积网络,由对称的编码器和解码器结构组成,具有跳跃连接,以从编码器路径传递特征到解码器路径。然而,由于这些体系结构通常无法捕捉图像中的长程依赖和全局上下文信息,因此它们通常在纹理、形状和大小方面在患者之间存在显著差异的目标信息的分割性能较差。
为了解决这些缺点,当前的研究建议实施基于CNN属性的自注意力机制。值得注意的是,Transformer最初是为NLP框架中的序列到序列任务而构思的,它作为完全放弃卷积运算符,完全依赖注意力机制的替代架构而崭露头角,在计算机视觉(CV)社区内引发了重大争论。
与以前的基于CNN的方法不同,Transformer不仅擅长捕捉全局上下文信息,还在大规模预训练时展现出对下游任务的强大适应能力。例如,首个完全基于自注意力的视觉Transformer(ViTs)用于图像识别在ViT中首次亮相,并在使用2D图像块与位置嵌入作为输入序列,在广泛的外部数据集上进行了预训练后,在ImageNet上取得了竞争性的成绩。DETR采用了一种基于Transformer的全面端到端目标检测方法,深入探讨了目标之间的连接和整体图像背景的关系以进行目标检测。SETR用Transformer替代了标准编码器-解码器网络中的传统编码器,有效地实现了自然图像分割任务的最新成果。
虽然Transformer擅长捕捉全局上下文,但在细节方面,特别是在医学图像中,它难以把握精细的细节。为了克服这一限制,研究人员已经努力将基于CNN和Transformer的模型相互整合。特别是TransUNet和TransFuse是通过将Transformer和UNet相结合的代表性方法,用于医学图像分割。
作为不断努力发挥CNN和Transformer-based模型优势的一部分,作者提出了一种简单而有效的UNet-Transformer模型,命名为seUNet-Trans,用于医学图像分割。在作者的方法中,UNet模型被设计为特征提取器,从输入图像中提取多个特征图,然后这些特征图被输入到一个桥接层中,该层被引入以依次连接UNet和Transformer。在这个阶段,作者采用了像素级嵌入技术,而没有使用位置嵌入向量,以使模型更高效。
此外,Transformer Head在建模输入序列之间的关系和依赖关系方面起着核心作用,最终生成了输入图像的预测地图。通过利用UNet架构和Transformer机制,作者的模型不仅保留了局部和全局上下文信息的保留,还能够捕捉输入元素之间的长程关系。
2、Method:
在本节中,作者详细介绍了用于医学图像分割的提出的模型。该模型以UNet作为其Backbone,同时包括一个Transformer Head。基本上,Backbone接收输入图像,然后输出桥接层,这些桥接层由Transformer Head处理以获取最终的预测。Backbone架构以U形网络结构为特点,包括编码器部分和解码器部分。通常,seUNet-Trans的整体架构如图1所示。

2.1 编码器:
编码器部分负责从网络中的输入图像中提取特征。通常,它由几个卷积层组成,称为UNet块,然后是最大池化层。这些UNet块逐渐减小输入图像的空间尺寸,同时增加特征图的深度(通道数)。作者构建了包含4个UNet块的编码器部分,UNet块的构造如图2所示。
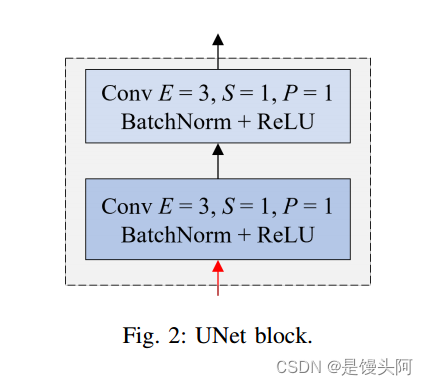
UNet块包括两个卷积神经网络(Conv),然后是批归一化函数和修正线性单元ReLU激活函数。UNet块的结构可以表示为:

2.2 解码器:
解码器部分负责将特征图上采样到原始图像大小,并生成桥接层。通常,解码器包括4个解码器块,每个解码器块包括上采样(或反卷积)、跳跃连接和UNet块。
首先,解码器上采样前一层的大小,然后使用跳跃连接将它们与编码器中对应的层进行拼接,最后将拼接的特征传递给UNet块。跳跃连接允让网络合并低级和高级特征,从而提供更多关于特征的信息。
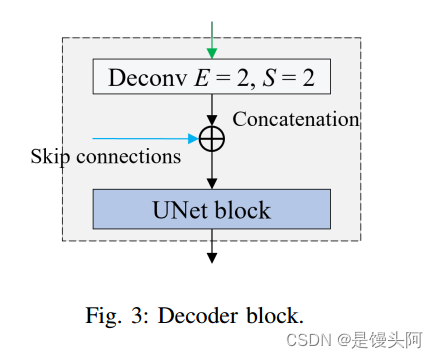
通常,解码器的最后一层通常具有单个通道(用于二进制分割)或多个通道(用于多类分割),其中每个通道表示像素属于特定类别的概率。但是,作者没有提取分割地图,而是对解码器的输出应用了另一个卷积层,以获得桥接层。这些层将用作Transformer Head的输入。
2.3??Transformer Head
Transformer Head首先通过卷积层合并桥接层的特征。随后,将这些合并的特征展平成序列,并将其传递到多头注意力(MHA)机制中。MHA的输出传递到多层感知器(MLP),主要用于将输入特征映射到输出特征。最后,从MLP的输出进行线性上采样,并在输出最终预测之前通过CBR块中的卷积层进行处理。Transformer Head的结构如图4所示。

2.3.1 特征嵌入:
具有桥接通道的桥接层的大小为(H,W,Cb),其中H、W和Cb分别表示高度、宽度和桥接通道的数量,通过使用卷积层进行合并,卷积核的大小为E,步幅为S,填充为P分别为3、4和1。经过卷积后,桥接层的输出分辨率计算为:

在图像分割的背景下,作者的目标是建立图像中像素之间的关系。这可以通过各种方法来实现,例如基于CNN的技术、注意力机制和图神经网络。对于这个特定的研究,作者利用了注意力机制,因为它在捕捉长程特征方面非常有效。
在作者的提出方法中,作者将每个像素及其在不同空间维度上的变化(由不同通道中的各种特征表示)视为单个输入向量,表示为。换句话说,合并特征被展平成序列,序列的维度为:

与视觉Transformer方法不同,本研究在输入图像展平时不使用位置嵌入向量。这个决定源自作者将输入图像合并并在像素级别嵌入合并特征的事实。通常,将合并特征合并和嵌入到序列中的过程可以表示为:
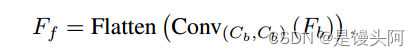
2.3.2 Transformer块:
Transformer块基本上包括多头注意力、多层感知器、LayerNorm和残差连接。Transformer块可以表示为:

此公式特殊字符太多,在此不做解释(CSDN啥时候能推一下公式编辑器啊?输入个特殊字符和公式还要打对应的代码)
此公式解释:

每个Head中的注意力计算为:

解释:

MHA的输出通过残差连接添加到其输入中。这种连接使网络能够学习残差信息或期望输出与当前预测之间的差异。通过这样做,网络可以更容易地在训练过程中捕捉和传播梯度,即使对于非常深的网络也是如此。这有助于有效地训练更深的神经网络,并减轻了梯度消失问题。
除了MHA,Transformer块还包括一个连接的前馈网络或MLP,它由两个线性变换和中间的GeLU激活组成。特别地,合并的特征被标准化,然后被馈送到MLP。与来自MHA的输出类似,这里作者还使用了另一个残差连接,将MLP的输出添加到其输入。
方程4描述了MHA和MLP的过程,其中输入特征按照标准Transformer被映射到输出特征。Transformer块的过程可以重复多次D,在本研究中,作者使用D = 3。
2.3.3 前馈网络:
前馈网络(FFN)接收来自Transformer块的嵌入序列,以提取特征并生成预测地图。由于FFN作用于序列作为输入,因此需要将这些输入重塑为所需的输入形状:
![]()
此外,如在III-C1部分中所计算的,输入形状经历了合并操作,导致大小减小了4倍。因此,重新Reshape的特征必须上采样4倍以匹配原始输入形状。此上采样过程使用双线性插值函数来增加特征图的分辨率。
在数学公式中,这一步可以表示为:


获得上采样特征后,它们被馈送到CBR块进行进一步处理,最终生成最终的预测地图。CBR块以其卷积层、批量归一化和ReLU激活而得名,它在特征的细化和空间增强方面发挥着至关重要的作用,使网络能够捕捉数据中的复杂模式和关系。
CBR由3个卷积层组成,其中前两个层的卷积核大小E为3×3,接着是批量归一化和ReLU激活,而第3个层的卷积核大小E为1×1,接受来自前一层的特征并直接输出最终的预测地图M。在数学上,这可以表示为:

解释:

3、实验
在这一部分,作者详细介绍了作者的模型在所有数据集上的结果,并进行了与SOTA模型的详细比较分析。特别地,为了进行可视化呈现,图6到图9显示了由SEMI-Net生成的代表性图像的预测结果,以及由SOTA模型生成的图像。为了提供对作者模型性能的详细定量评估,表格II到表格VI呈现了用于跨数据集评估的各种指标的数值值。
A.?Kvasir-SEG上的结果

图6a展示了SEMINet在Kvasir-SEG数据集上生成的预测。随后,作者对这些预测与其他模型生成的预测进行了比较分析。作者的模型的预测与其他模型的预测相媲美,与GT中的目标紧密对齐。

此外,计算得出的度量值总结在表格II中,显示SEMI-Net在mDC方面取得了0.922的卓越值,mIoU为0.864,mPre为0.901,mRec为0.917。
值得注意的是,SEMI-Net在mDC、mIoU和mPre方面优于其他模型,表现出卓越的性能。然而,值得一提的是,SEMI-Net的mRec相对较小,小于PraNet、HarDNetMSEG和DS-TransUNet。
B. CVC-ClinicDB上的结果
图6b展示了SEMI-Net和其他模型的预测结果。SEMINet生成的预测不仅超过了标准UNet模型,还优于SOTA模型。结果的详细比较见表格III,其中SEMI-Net取得了卓越的指标,包括mDC为0.945,mIoU为0.895,mPre为0.951,mRec为0.950。

相比之下,标准UNet模型的度量值较低,mDC、mIoU、mPre和mRec分别为0.872、0.804、0.868和0.917。这个比较强调了SEMI-Net在CVCClinicDB数据集上相对于基准UNet模型和其他SOTA模型的卓越性能。
C. GlaS上的结果

图7显示了SEMINet在GlaS数据集上生成的预测,相关的度量值详见表格IV。在最先进的模型中,SEMI-Net以其在腺体分割中的强大性能脱颖而出。它不仅胜过其他模型,还在视觉上与DS-TranUNet相媲美。具体来说,图7在视觉上突出了SEMI-Net的卓越性能,异常值较少,预测更准确。

如IV-A部分所述,尽管该数据集中的训练和测试样本数量有限,但相对于其他模型,该模型表现良好。表格IV进一步强调了SEMI-Net的专业能力,显示其度量值超过其他模型。具体来说,它在GlaS数据集上实现了mDC和mIoU分数分别为89.04和80.86,突显了其在腺体分割方面的专业能力。
D. ISIC 2018上的结果

图8展示了作者的模型在ISIC 2018数据集上生成的预测,相关的度量值详见表格V。与GT相比,作者的模型在代表性图像上表现出色,尽管在一些方面略逊于DS-TransUNet。通过观察图8,可以明显看出,SEMI-Net在代表性图像上表现出色,但在性能上与DS-TransUNet相媲美。

然而,当考虑度量值时,SEMINet在ISIC 2018上仍然取得了令人钦佩的分数,mDC、mIoU、mPre和mRec分别为0.938、0.883、0.925和0.937。这些指标显示了该模型的强大性能,即使DS-TransUNet在某些方面稍微优于它,其值分别为0.913、0.852、0.922和0.927。
E. 2018数据科学碗上的结果

作者的SEMI-Net在2018年数据科学碗数据集上的结果在图9中可视化,相关的定量指标汇总在表VI中。通过目视检查,可以看出作者模型的预测不包括异常值,与其他模型形成鲜明对比,相关的度量值相对较高。

具体地,SEMI-Net取得了卓越的度量值,mDC、mIoU、mPre和mRec分别为0.930、0.869、0.923和0.937。相比之下,DS-TransUNet虽然仍然表现出色,但度量值略低,分别为0.922、0.861、0.938和0.912。这突出了SEMI-Net在2018年数据科学碗数据集上的专业能力,其预测明显不包括异常值。
F. 混合息肉分割结果

如第IV-A节所述,作者的SEMI-Net是在混合息肉分割案例的4个不同数据集的综合数据集上训练的。模型在测试集上的性能如图10所示,其中作者模型的mDC和mIoU超过了UNet、PraNet和DS-TransUNet等SOTA模型。

具体来说,SEMI-Net在Kvasir数据集上取得了令人印象深刻的mDC和mIoU分数,分别为0.962和0.932,在ClinicDB数据集上分别为0.965和0.935,如表格VII所示。值得注意的是,即使在未经明确训练的数据集上,包括ColonDB和EndoScene,SEMI-Net也展现出卓越的预测准确性。在ColonDB上,它分别取得了0.905和0.864的mDC和mIoU,而在EndoScene上,这些指标分别为0.903和0.861,展示了该模型的强大性能和适应性。
4、总结:
本文介绍了一种名为seUNet-Trans的新方法,该方法将CNN的鲁棒特征提取能力与基于transformer的模型的复杂上下文理解相结合,以推进医学图像分割。seUNet-Trans采用混合设计,将全卷积网络UNet与基于transformer的模型集成在一起。这种集成的核心是一个特别设计的桥接层,它充当桥接层,将丰富的特性映射从UNet依次导入到Transformer中。这种设计使框架能够利用UNet识别的空间层次结构和Transformer识别的全局依赖关系,从而提供更精确和上下文感知的分割性能。
5、狗蛋-布莱克博士

目前咋感觉狗蛋为了AI博士毕业咋有点头秃?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!