使用Python爬取GooglePlay并从复杂的自定义数据结构中实现解析
文章目录
【作者主页】:吴秋霖
【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作!
【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布式爬虫平台感兴趣的朋友可以关注《分布式爬虫平台搭建与开发实战》
还有未来会持续更新的验证码突防、APP逆向、Python领域等一系列文章
??说到GooglePlay,自定义的数据结构,解析起来真的是让人感觉到窒息。而且基本是每间隔一段时间就会稍微的发现变动,解析规则基本持久不了太久可能就会失效,不过都是一些细微的变动,不值一提~
GooglePlay是没有对外提供任何API的,想要爬取相关的数据就需要通过Web端的方式,Git上面也有国外的大佬开源了google-play-scraper,Python跟JS版本的我记得都有,直接导包调用
但是稳定性不够好,也是基于Web端去爬取解析的,一旦结构发生变化,作者维护不够及时的话,自然也就无法使用
之后参考开源的项目,自己重新实现了数据抽取那一块逻辑,并将解析服务部署在了境外服务器上,然后通过远端调用的方式去解析
在我之前的Cloudflare反爬虫防护绕过文章中,就是以一个第三方的APK下载网站为示例进行的讲解,GooglePlay的APK包如果是在官方网站下载的话会比较麻烦,直接可以用我提到的那个第三方网站取下载就行
主要爬取内容就是APP应用的相关描述信息,如下图所示:

在点击关于此应用的时候,抓包可以看到重点数据集都嵌套在了HTML源代码中,使用JS函数定义了AF_initDataCallBack,data参数就是加载的数据

尝试将数据拷贝出来,不过发现太长了,截图都放不下,图片都给整裂开了!反正就是巨长再加上多层嵌套,需要拆解慢慢去写解析规则!
接下来,先实现对data数据的提取,实现代码如下所示:
async def extract_json_block(html, block_id):
prefix = re.compile(r"AF_init[dD]ata[cC]all[bB]ack\s*\({[^{}]*key:\s*'" + re.escape(block_id) + ".*?data:")
suffix = re.compile(r"}\s*\)\s*;")
try:
block = prefix.split(html)[1]
block = suffix.split(block)[0]
except IndexError:
raise PlayStoreException("Could not extract block %s" % block_id)
block = block.strip()
block = re.sub(r"^function\s*\([^)]*\)\s*{", "", block)
block = re.sub("}$", "", block)
block = re.sub(r", sideChannel: {$", "", block)
return block
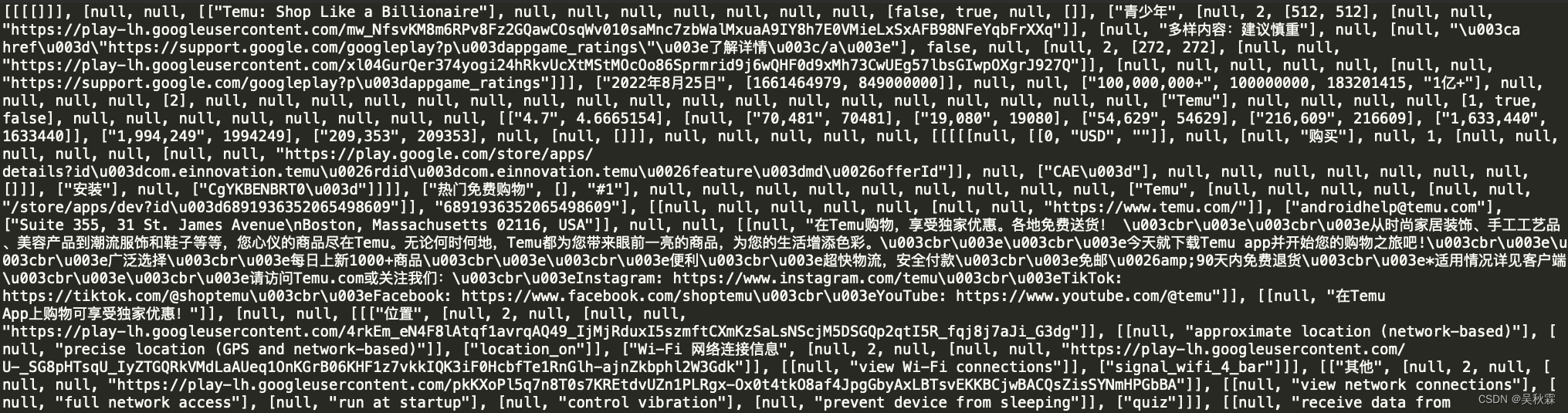
如上就是提取出来的数据,拿到数据以后,如果你是小白新手或许会因此放弃,实在是让人头大,现在开始实现解析核心逻辑代码,如下所示:
app_detail_ds_block = 'ds:7'
app_details_mapping = {
'title': [app_detail_ds_block, 1, 2, 0, 0],
'developer_name': [app_detail_ds_block, 1, 2, 68, 0],
'developer_link': [app_detail_ds_block, 1, 2, 68, 1, 4, 2],
'price_inapp': [app_detail_ds_block, 1, 2, 19, 0],
'category': [app_detail_ds_block, 1, 2, 79, 0, 0, 1, 4, 2],
'video_link': [app_detail_ds_block, 1, 2, 100, 1, 2, 0, 2],
'icon_link': [app_detail_ds_block, 1, 2, 95, 0, 3, 2],
'num_downloads_approx': [app_detail_ds_block, 1, 2, 13, 1],
'num_downloads': [app_detail_ds_block, 1, 2, 13, 2],
'published_date': [app_detail_ds_block, 1, 2, 10, 0],
'published_timestamp': [app_detail_ds_block, 1, 2, 10, 1, 0],
'pegi': [app_detail_ds_block, 1, 2, 9, 0],
'pegi_detail': [app_detail_ds_block, 1, 2, 9, 2, 1],
'os': [app_detail_ds_block, 1, 2, 140, 1, 1, 0, 0, 1],
'rating': [app_detail_ds_block, 1, 2, 51, 0, 1],
'description': [app_detail_ds_block, 1, 2, 72, 0, 1],
'price': [app_detail_ds_block, 1, 2, 57, 0, 0, 0, 0, 1, 0, 2],
'num_of_reviews': [app_detail_ds_block, 1, 2, 51, 2, 1],
'developer_email': [app_detail_ds_block, 1, 2, 69, 1, 0],
'developer_address': [app_detail_ds_block, 1, 2, 69, 2, 0],
'developer_website': [app_detail_ds_block, 1, 2, 69, 0, 5, 2],
'developer_privacy_policy_link': [app_detail_ds_block, 1, 2, 99, 0, 5, 2],
'data_safety_list': [app_detail_ds_block, 1, 2, 136, 1],
'updated_on': [app_detail_ds_block, 1, 2, 145, 0, 0],
'app_version': [app_detail_ds_block, 1, 2, 140, 0, 0, 0]
}
async def find_item_from_json_mapping(google_app_detail_request_result, app_detail_mapping):
ds_json_block = app_detail_mapping[0]
json_block_raw = await extract_json_block(google_app_detail_request_result, ds_json_block)
json_block = json.loads(json_block_raw)
return await get_nested_item(json_block, app_detail_mapping[1:])
app_details_mapping则是解析数据的核心,索引基本上变动较小!因为数据都是在list中多级嵌套,所以需要花费一点精力时间去分析,app_detail_ds_block前段时间我记得是ds:5,这个倒是会偶尔变动
class PlayStoreException(BaseException):
def __init__(self, *args):
if args:
self.message = args[0]
else:
self.message = None
def __str__(self):
if self.message:
return "PlayStoreException, {0}".format(self.message)
else:
return "PlayStoreException raised"
class GooglePlayStoreScraper(object):
def __init__(self):
self.PLAYSTORE_URL = "https://play.google.com"
self.PROXIES = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
async def _app_connection(self, url, sleeptime=2, retry=0):
for _ in range(retry + 1):
try:
async with aiohttp.ClientSession() as session:
async with session.get(url, proxy=self.PROXIES) as response:
return await response.text()
except aiohttp.ClientError:
if sleeptime > 0:
await asyncio.sleep(sleeptime)
raise PlayStoreException(f"Could not connect to : {url}")
async def get_nested_item(self, item_holder, list_of_indexes):
index = list_of_indexes[0]
if len(list_of_indexes) > 1:
return await get_nested_item(item_holder[index], list_of_indexes[1:])
else:
return item_holder[index]
async def get_app_details(self, app_id, country="nl", lang="nl"):
url = f"{self.PLAYSTORE_URL}/store/apps/details?id={quote_plus(app_id)}&hl={lang}&gl={country}"
request_result = await self._app_connection(url, retry=1)
app = {'id': app_id, 'link': url}
for k, v in app_details_mapping.items():
try:
app[k] = await self.find_item_from_json_mapping(request_result, v)
except PlayStoreException:
raise PlayStoreException(f"Could not parse Play Store response for {app_id}")
except Exception as e:
self._log_error(country, f'App Detail error for {app_id} on detail {k}: {str(e)}')
app.setdefault('errors', []).append(k)
app['developer_link'] = self.PLAYSTORE_URL + app.get('developer_link', '')
app['category'] = app.get('category', '').replace('/store/apps/category/', '')
if 'data_safety_list' in app:
app['data_safety_list'] = ', '.join(item[1] for item in app['data_safety_list'] if len(item) > 1)
soup = BeautifulSoup(request_result, 'html.parser')
list_of_categories = ', '.join(', '.join(category.text for category in element.find_all('span')) for element in soup.find_all('div', {'class': 'Uc6QCc'}))
app['list_of_categories'] = list_of_categories if list_of_categories else app.setdefault('errors', []) + ['list_of_categories']
if 'errors' in app:
plural = 's' if len(app['errors']) > 1 else ''
app['errors'] = f"Detail{plural} not found for key{plural}: {', '.join(app['errors'])}"
return app
在完成上面爬虫程序核心入口的实现以后,基本上用采集到数据解析都已经完成,只需要调用get_app_details函数,传人需要爬取的目标APP的包名即可爬取并解析数据,如下所示:

??好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- STM32_HAL Freertos按键控制LED
- 计网04-网络传输介质
- 如何上传镜像文件到hub仓库?
- Ant Design 家族繁衍再生,焕然一新!全新成员加入,全家族齐聚盛世盛宴!
- matlab appdesigner系列-常用11-文本区域、信息累积提示、信息换行、私有属性
- cmake 入门笔记
- LINUX系统安装和管理
- 宋仕强论道之华强北专业市场转型失败(四十七)
- mysql:查看线程缓存中的线程数量
- jQuery练习滑入滑出切换