Chart 10 OpenCL 优化教学
前言
这一章提供了一些示例,以演示使用前几章讨论的优化技术。除了一些简单的代码片段演示外,我们还通过使用前几章中讨论的多种实践方法,逐步优化了两个知名的图像处理 filter,即 Epsilon filter 和 Sobel filter。
10.1 博客
一些博客讨论了使用案例的优化,这些资源可以在高通开发者网络上公开获取。以下是开发人员可以参考的其中一些博客:
Table 10-1 Blogs on OpenCL optimizations and other resources
在本节中讨论的使用案例包括Epsilon滤镜和Sobel滤镜,这些案例在这些博客中有部分涉及。
10.2 Sample Code
10.2.1 算法优化
这个示例演示了如何简化一个算法以优化其性能。给定一张图像,在其上应用一个简单的 8x8 模糊滤波 (Box Filter)。
__kernel void ImageBoxFilter(__read_only image2d_t source, __write_only image2d_t dest, sampler_t sampler)
{
... // variable declaration
for( int i = 0; i < 8; i++ )
{
for( int j = 0; j < 8; j++ )
{
coor = inCoord + (int2) (i - 4, j - 4 );
// !! read_imagef is called 64 times per work item
sum += read_imagef( source, sampler, coor);
}
}
// Compute the average
float4 avgColor = sum / 64.0f;
... // write out result
}
上述代码中,两层 for 循环读取了 64 个元素,之前求平均值
为了减少纹理访问,上述内核被分成两个阶段。第一阶段计算每个工作项的2x2平均值,并将结果保存到一个中间图像中。第二阶段使用中间图像进行最终的计算。
// First pass: 2x2 pixel average
__kernel void ImageBoxFilter(__read_only image2d_t source, __write_only image2d_t dest, sampler_t sampler)
{
... // variable declaration
// Sample an 2x2 region and average the results
for( int i = 0; i < 2; i++ )
{
for( int j = 0; j < 2; j++ )
{
coor = inCoord - (int2)(i, j);
// 4 read_imagef per work item
sum += read_imagef( source, sampler, coor );
}
}
// equivalent of divided by 4, in case compiler does not optimize
float4 avgColor = sum * 0.25f;
... // write out result
}
// Second Pass: final average
__kernel void ImageBoxFilter16NSampling( __read_only image2d_t source, __write_only image2d_t dest, sampler_t sampler)
{
... // variable declaration
int2 offset = outCoord - (int2)(3,3);
// Sampling 16 of the 2x2 neighbors
for( int i = 0; i < 4; i++ )
{
for( int j = 0; j < 4; j++ )
{
coord = mad24((int2)(i,j), (int2)2, offset);
// 16 read_imagef per work item
sum += read_imagef( source, sampler, coord );
}
}
// equivalent of divided by 16, in case compiler does not optimize
float4 avgColor = sum * 0.0625;
... // write out result
}
修改后的算法每个工作项对图像缓冲进行20次访问(4次直接访问 + 16次其他访问),明显少于原始算法的64次read_imagef访问。
10.2.2 Vectorized load/store
该示例演示了如何在Adreno GPU上进行矢量化的加载/存储,以更好地利用带宽。
Original kernel before optimization
__kernel void MatrixMatrixAddSimple( const int matrixRows, const int matrixCols, __global float* matrixA,
__global float* matrixB, __global float* MatrixSum)
{
int i = get_global_id(0);
int j = get_global_id(1);
// Only retrieve 4 bytes from matrixA and matrixB.
// Then save 4 bytes to MatrixSum.
MatrixSum[i*matrixCols+j] = matrixA[i*matrixCols+j] + matrixB[i*matrixCols+j];
}
Modified kernel
__kernel void MatrixMatrixAddOptimized2(const int rows, const int cols, __global float* matrixA, __global float* matrixB,
__global float* MatrixSum)
{
int i = get_global_id(0);
int j = get_global_id(1);
// Utilize built-in function to calculate index offset
int offset = mul24(j, cols);
int index = mad24(i, 4, offset);
// Vectorize to utilization of memory bandwidth for performance gain.
// Now it retrieves 16 bytes from matrixA and matrixB.
// Then save 16 bytes to MatrixSum
float4 tmpA = (*((__global float4*)&matrixA[index]));
// Alternatively vload and vstore can be used in here
float4 tmpB = (*((__global float4*)&matrixB[index]));
(*((__global float4*)&MatrixSum[index])) = (tmpA+tmpB);
// Since ALU is scalar based, no impact on ALU operation.
}
int offset = mul24(j, cols);
int index = mad24(i, 4, offset);
这两行代码我觉得存在问题,至少行列的读取风格应该和 Origin 算法保持一致,应该修改为:
int offset = mul24(i, cols);
int index = mad24(j, 4, offset);
新的内核正在使用 float4 进行矢量化的加载和存储。由于这种矢量化,内核的全局工作大小应该是原始内核的 1/4。
10.2.3 image 代替 buffer
该示例为五百万对向量计算点积。原始代码使用缓冲对象,并进行了修改以使用纹理对象(read_imagef)来改善频繁的数据访问。这是一个简单的例子,但这种技术可以应用于许多情况,其中 buffer 对象的访问不如 纹理对象 的访问效率高。
Original kernel before optimization
__kernel void DotProduct(__global const float4 *a, __global const float4 *b, __global float *result)
{
// a and b contain 5 million vectors each
// Arrays are stored as linear buffer in global memory
result[gid] = dot(a[gid], b[gid]);
}
Modified kernel for optimization
__kernel void DotProduct(__read_only image2d_t c, __read_only image2d_t d, __global float *result)
{
// Image c and d are used to hold the data instead of linear buffer
// read_imagef goes through the texture engine
int2 gid = (get_global_id(0), get_global_id(1));
result[gid.y * w + gid.x] = dot(read_imagef(c, sampler, gid), read_imagef(d, sampler, gid));
}
10.3 Epsilon Filter
Epsilon滤波在图像处理中被广泛用于减少蚊子噪声(Mosquito noise),这是一种在图像的高频区域,如边缘发生的一种扰动。该滤波器本质上是一个非线性的逐点低通滤波器,具有空间变化的支持,只有像素值超过特定阈值的像素才会被滤波。
在这个实现中,Epsilon滤波仅应用于YUV图像的亮度(Y)分量,因为噪声主要在亮度分量中可见。此外,它假设Y分量是连续存储的(NV12格式),与UV分量分开。该实现分为两个基本步骤,如图10-1所示。
- 对于待滤波的像素,计算其相邻的9x9区域中每个像素与中心像素的绝对差值。
- 如果绝对差值低于阈值,则使用相邻像素的值进行平均。阈值通常是应用程序中预先定义的常数。
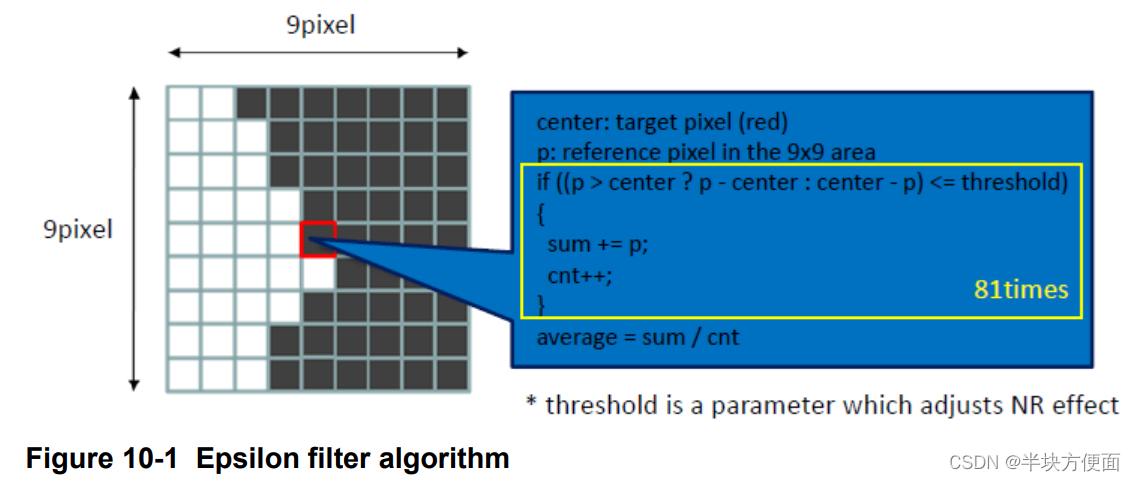
10.3.1 初始化实现
该应用的目标是具有3264x2448分辨率(宽度=3264,高度=2448)的YUV图像,每个像素为8位。此处报告的性能数据来自Snapdragon 810(MSM8994,Adreno 430)处于性能模式下。
以下是初始实施参数和策略:
- 使用 OpenCL 图像对象而不是 Buffer
- 使用图像而不是缓冲区可以避免一些边界检查,并充分利用 Adreno GPU 中的 L1 缓存。
- 使用 CL_R | CL_UNORM_INT8 图像格式/数据类型。
- 由于这仅用于 Y 分量,因此使用单通道,而 Adreno GPU 中的内置纹理管道将读取的像素归一化为 [0, 1]。
- 每个工作项生成一个输出像素。
- 使用 2D 内核,全局工作大小设置为 [3264, 2448]。
在实现中,每个工作项必须访问 81 个浮点像素。Adreno A430 GPU 的性能被用作进一步优化的基准。
10.3.2 Data pack optimization
通过比较计算量和数据负载的量,很容易得出结论,这是一个受内存限制的用例。因此,主要的优化应该集中在如何提高数据加载效率上。
首先要注意的是,使用32位浮点(fp32)来表示像素值是一种浪费内存的做法。对于许多图像处理算法,8位或16位的数据类型可能已经足够。由于 Adreno GPU 具有本机硬件支持16位浮点数据类型,即半精度或fp16,因此可以应用以下优化选项:
- 使用16位半精度数据类型,而不是32位浮点。
- 现在,每个工作项访问81个半精度数据。
- 使用CL_RGBA | CL_UNORM_INT8图像格式/数据类型。
- 使用CL_RGBA加载四个通道以更好地利用TP带宽。
- 用read_imageh替换read_imagef。TP会自动将数据转换为16位半精度。
- 每个工作项:
- 每行读取三个half4向量。
- 输出一个处理过的像素。
- 每输出像素的内存访问次数:3x9=27(half4)。
- 性能提升:1.4倍。
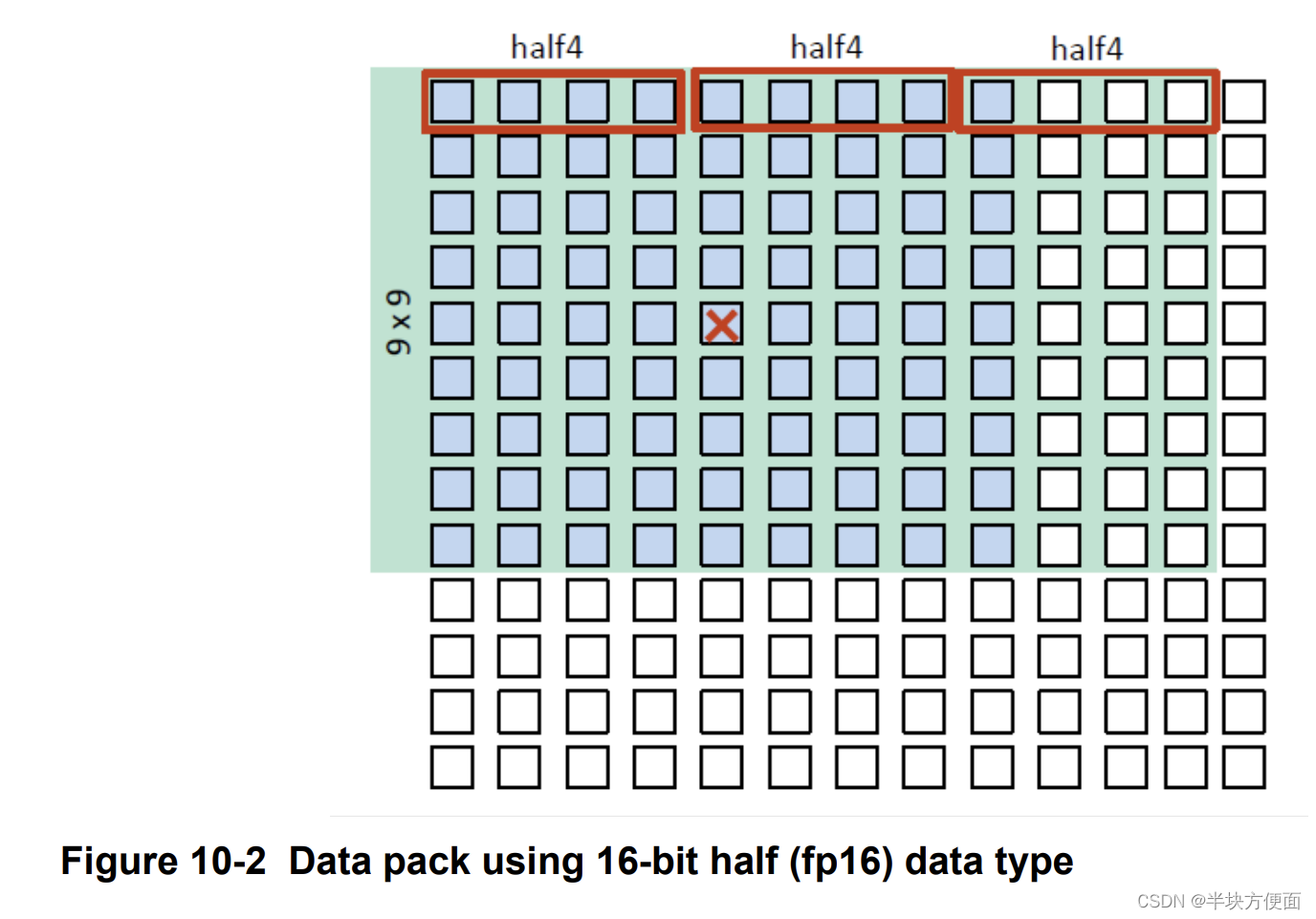
10.3.3 Vectorized load/store optimization
在前一步骤中,只输出一个像素,并加载了许多相邻像素。通过加载一些额外的像素,可以按以下方式过滤更多像素:
- 每个工作项。
- 每行读取三个half4向量。
- 输出四个像素。
- 每输出像素的内存访问次数:3x9/4 = 6.75(half4)。
- 全局工作大小:(宽度/4)x 高度。
- 对每行进行循环展开。
- 在每行内部,使用滑动窗口方法。
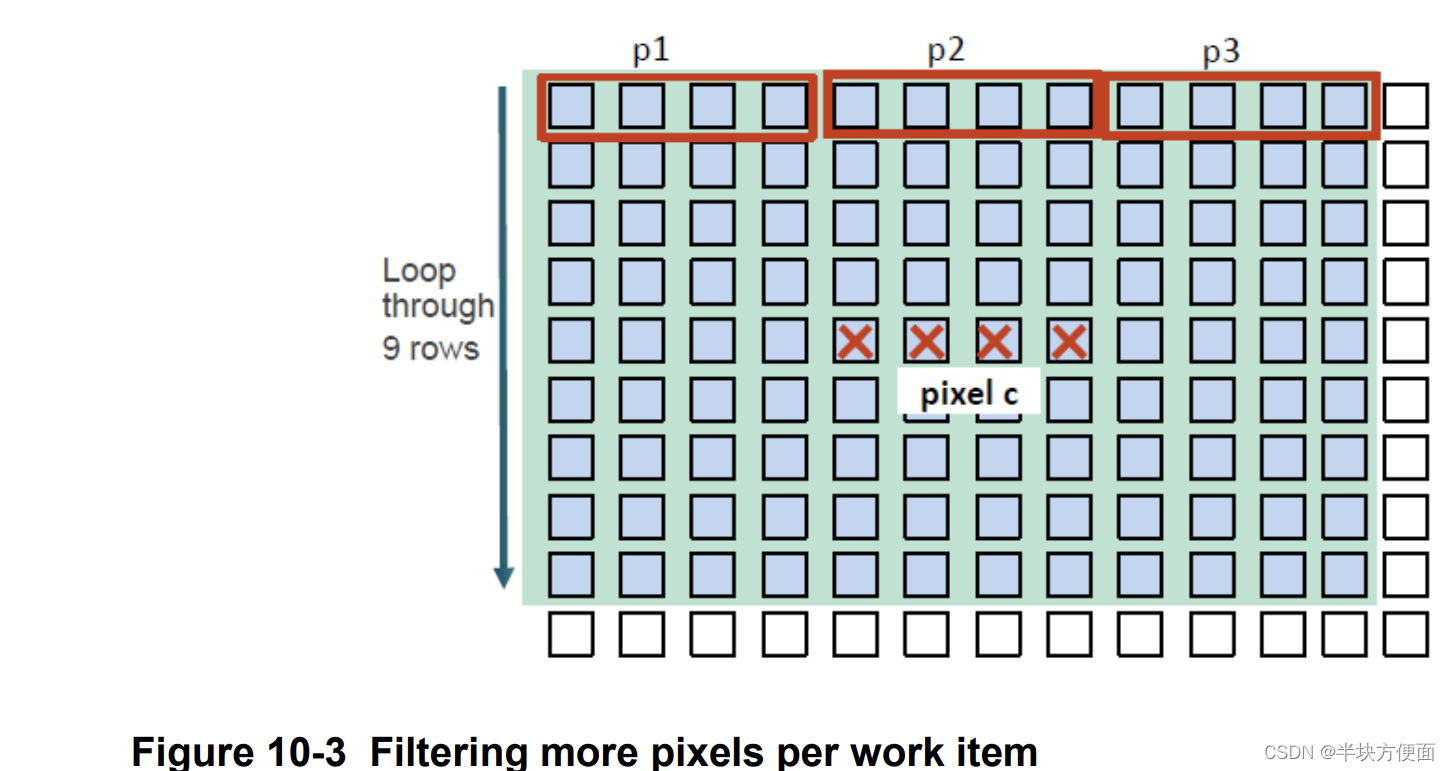
图10-3说明了如何使用额外加载的多个像素进行处理的基本图表。以下是步骤:
Read center pixel c;
For row = 1 to 9, do:
read data p1;
Perform 1 computation with pixel c;
read data p2;
Perform 4 computations with pixel c;
read data p3;
Perform 4 computations with pixel c;
end for
write results back to pixel c。
经过这一步骤,性能相比基准提高了3.4倍
10.3.4 Further increase workload per work item
可以通过增加每个工作项的工作量来预期更多的性能提升。以下是选项:
- 读取一个额外的half4向量,并将输出像素数量增加到8。
- 全局工作大小:width/8 x height。
- 每个工作项。
- 每行读取四个half4向量。
- 输出八个像素。
- 每输出像素的内存访问次数:4x9/8 = 4.5(half4)。
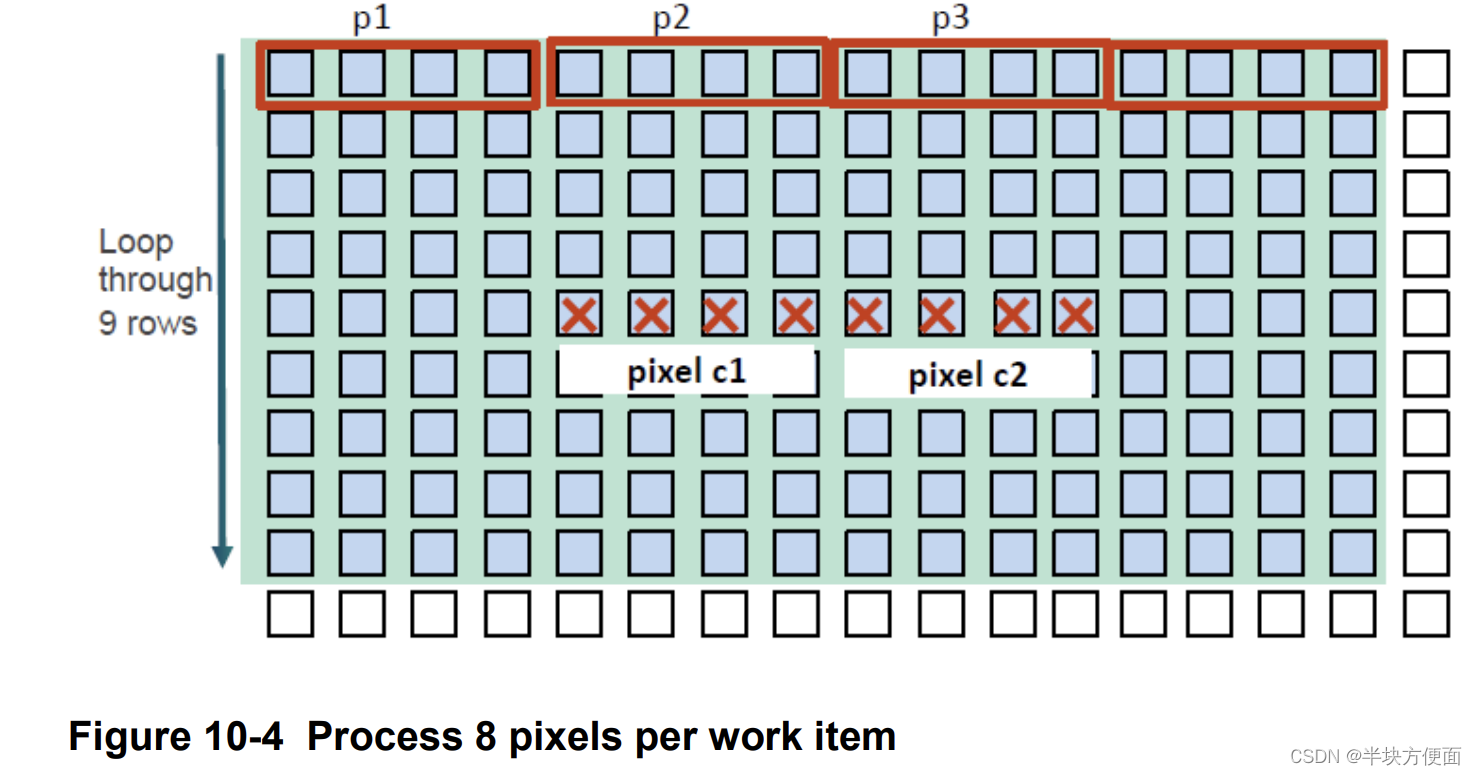
这些更改导致了轻微的性能提升,增加了0.1倍。以下是为什么效果不佳的原因:
- 缓存命中率并没有太大变化,因为在先前的步骤中已经非常优秀。
- 需要更多寄存器,导致波数减少,这会影响并行性和延迟的隐藏。
出于实验目的,可以按以下方式加载更多像素:
- 读取更多的half4向量,并将输出像素数量增加到16。
- 全局工作大小:width/16 x height。
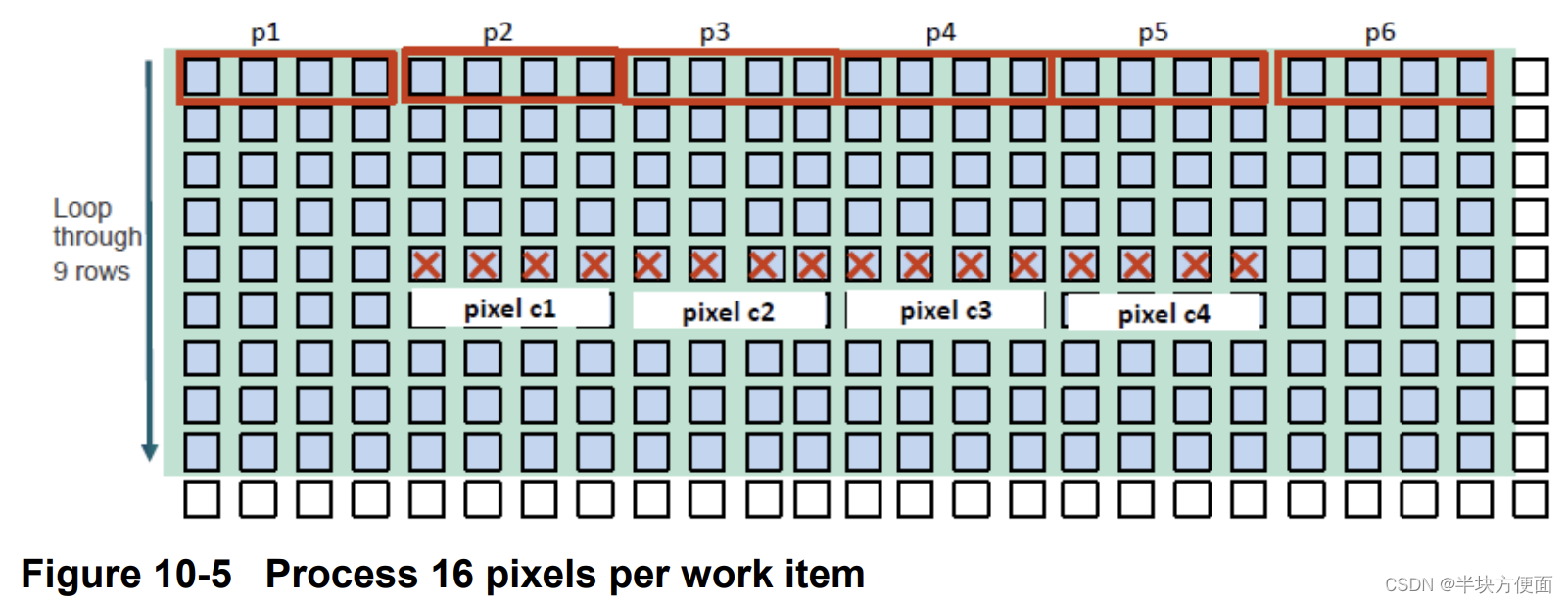
图10-5显示每个工作项执行以下操作:
- 每行读取6个half4向量。
- 输出16个像素。
- 每输出像素的内存访问次数是6x9/16 = 3.375(half4)。
经过这些更改,性能从基准的3.4倍下降到了0.5倍。将更多像素加载到一个内核中导致寄存器溢出,严重影响了性能。
10.3.5 Use local memory optimization
本地内存(Local Memory)的延迟比全局内存(Global Memory)短得多,因为它是片上内存。一种选择是将像素加载到本地内存中,避免重复从全局内存中加载。除了中心像素,还加载了9x9滤波的周围像素到本地内存,如图10-6所示。
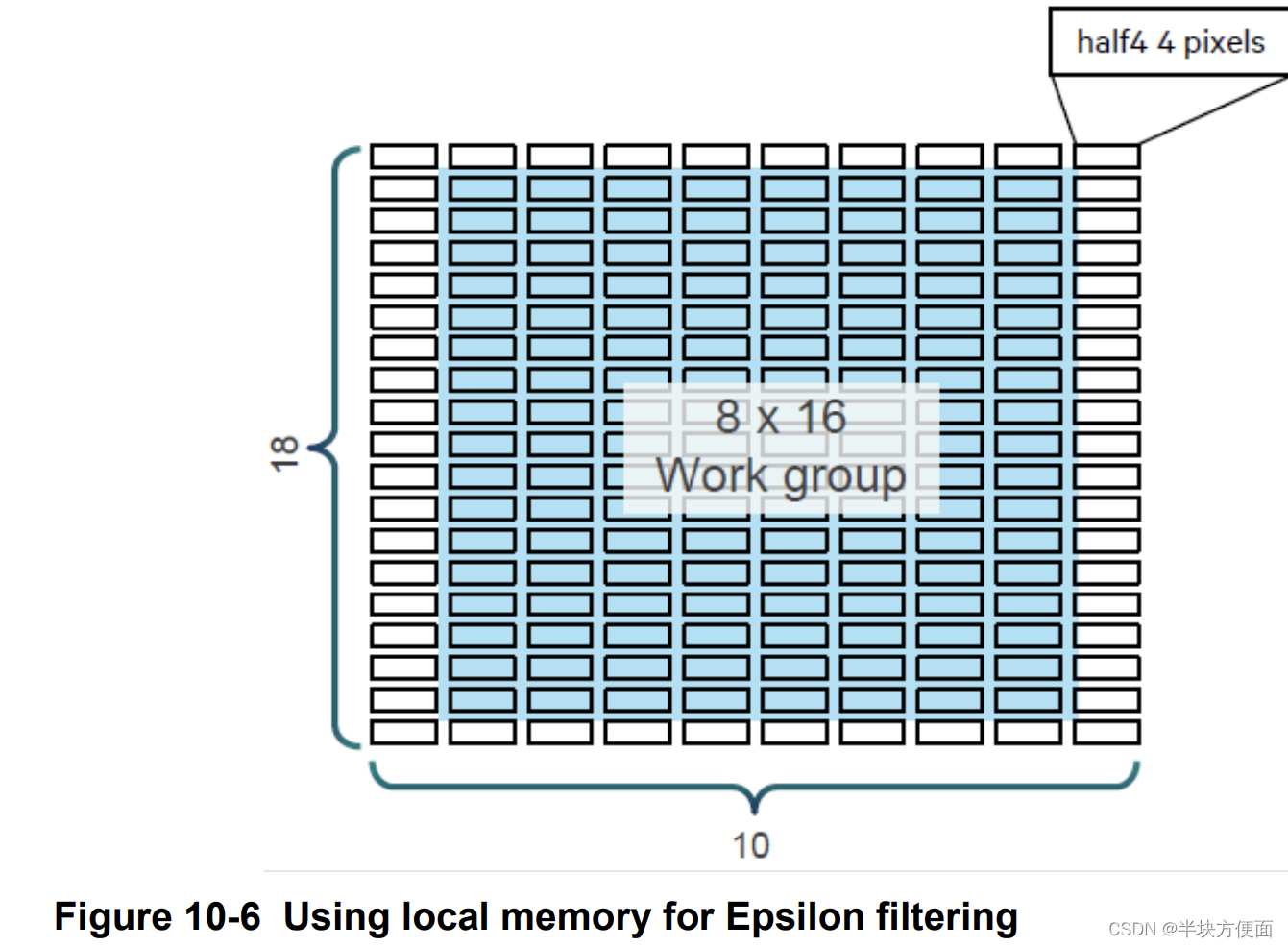
表10-2列出了两种情况的设置及其性能。整体性能比原始性能要好得多。然而,它们并没有超过第10.4.4节中的最佳性能。

正如在第7.1.1节中讨论的那样,本地内存通常需要在工作组内部进行屏障同步,而且不一定比全局内存提供更好的性能。相反,如果开销太大,性能可能更差。在这种情况下,如果全局内存具有较高的缓存命中率,那么全局内存可能更好。
10.3.6 Branch operations optimization
Epsilon滤波器需要在像素之间进行如下比较:
Cond = fabs(c -p) <= (half4)(T);
sum += cond ? p : consth0;
cnt += cond ? consth1 : consth0;
三元运算符 ?: 在硬件中会导致一些分歧,因为波中并不是所有的线程都进入相同的执行分支。分支操作可以通过ALU操作来替代,如下所示:
Cond = convert_half4(-(fabs(c -p) <= (half4)(T)));
sum += cond * p;
cnt += cond;
这个优化是建立在第10.3.2节描述的优化基础之上的,性能从基准的3.4倍提高到了5.4倍。
关键的区别在于新代码在高度并行化的ALU中执行,波中的所有线程基本上执行相同的代码片段。相对而言,变量Cond可能具有不同的值,而旧的代码则使用一些昂贵的硬件逻辑来处理分歧。
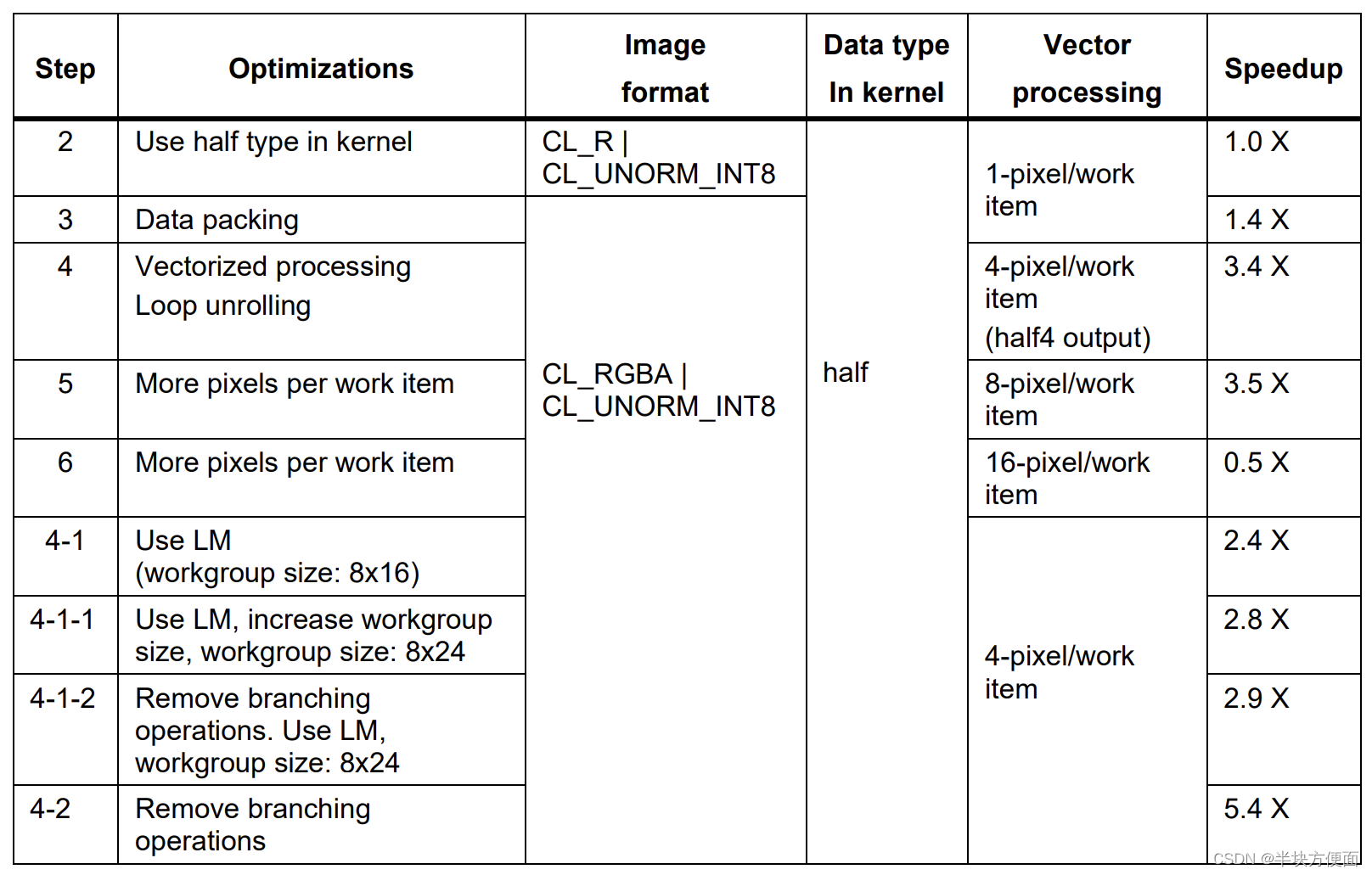
10.3.7 Summary
优化步骤及其性能指标总结在表10-3中。最初,该算法受到内存的限制。通过进行数据打包和矢量化加载,它变得更多地依赖于ALU。总体而言,这个用例的关键优化是最优地加载数据。许多受内存限制的用例可以通过使用类似的技术来加速。

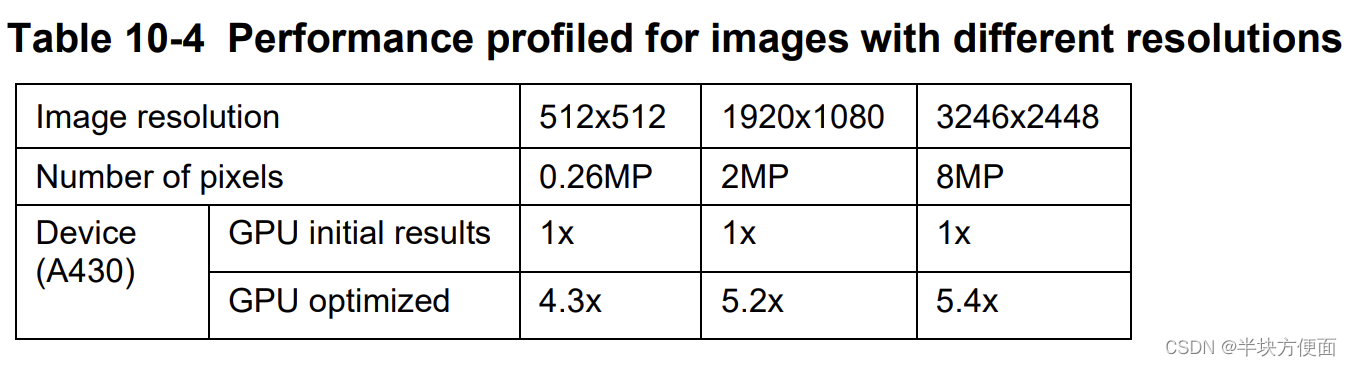
Epsilon滤波器在三种不同分辨率下的OpenCL性能显示在表10-4中。对于较大的图像,收益更为明显。对于3264x2448的图像,与初始的OpenCL代码相比,观察到了5.4倍的性能提升,而对于512x512的图像,性能提升为4.3倍。与工作负载无关的内核执行与固定成本相关,随着工作负载的增加,其在整体性能中的权重变得较低。
10.4 Sobel filter
Sobel滤波器,也称为Sobel算子,用于许多图像处理和计算机视觉算法中进行边缘检测。它使用两个3x3的核与原始图像相结合,以近似求导。有两个核:一个用于水平方向,另一个用于垂直方向,如图10-7所示。
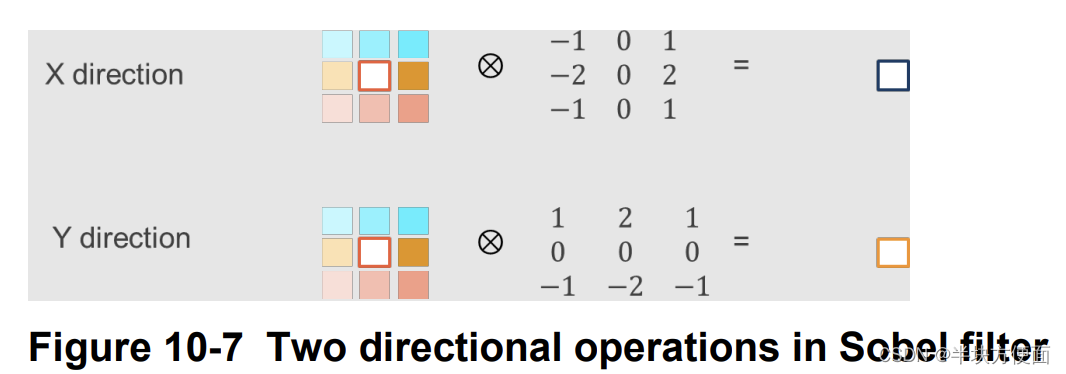
10.4.1 Algorithm optimization
Sobel滤波器是一个可分解的滤波器,可以分解如下:
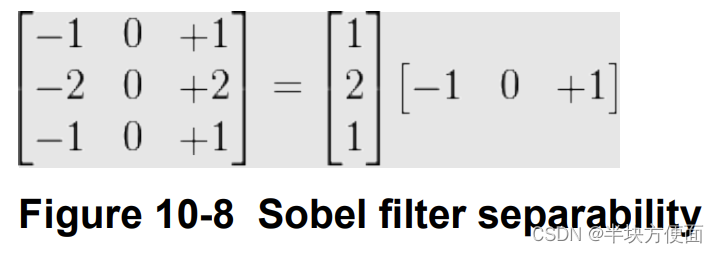
与不可分解的2D滤波器相比,2D可分离滤波器可以将复杂度从O(n^2)降低到O(n)。由于2D的高复杂性和计算成本,使用可分离的滤波器而不是不可分离的滤波器是非常可取的。
10.4.2 Data pack optimization
尽管可分离滤波器显著减少了计算量,但对于每个点的滤波所需的像素数量是相同的,即对于这个3x3的核,是八个相邻像素加上中心像素。很容易看出这是一个受内存限制的问题。因此,如何有效地将像素加载到GPU是性能的关键。下面的图中说明了三种选项:
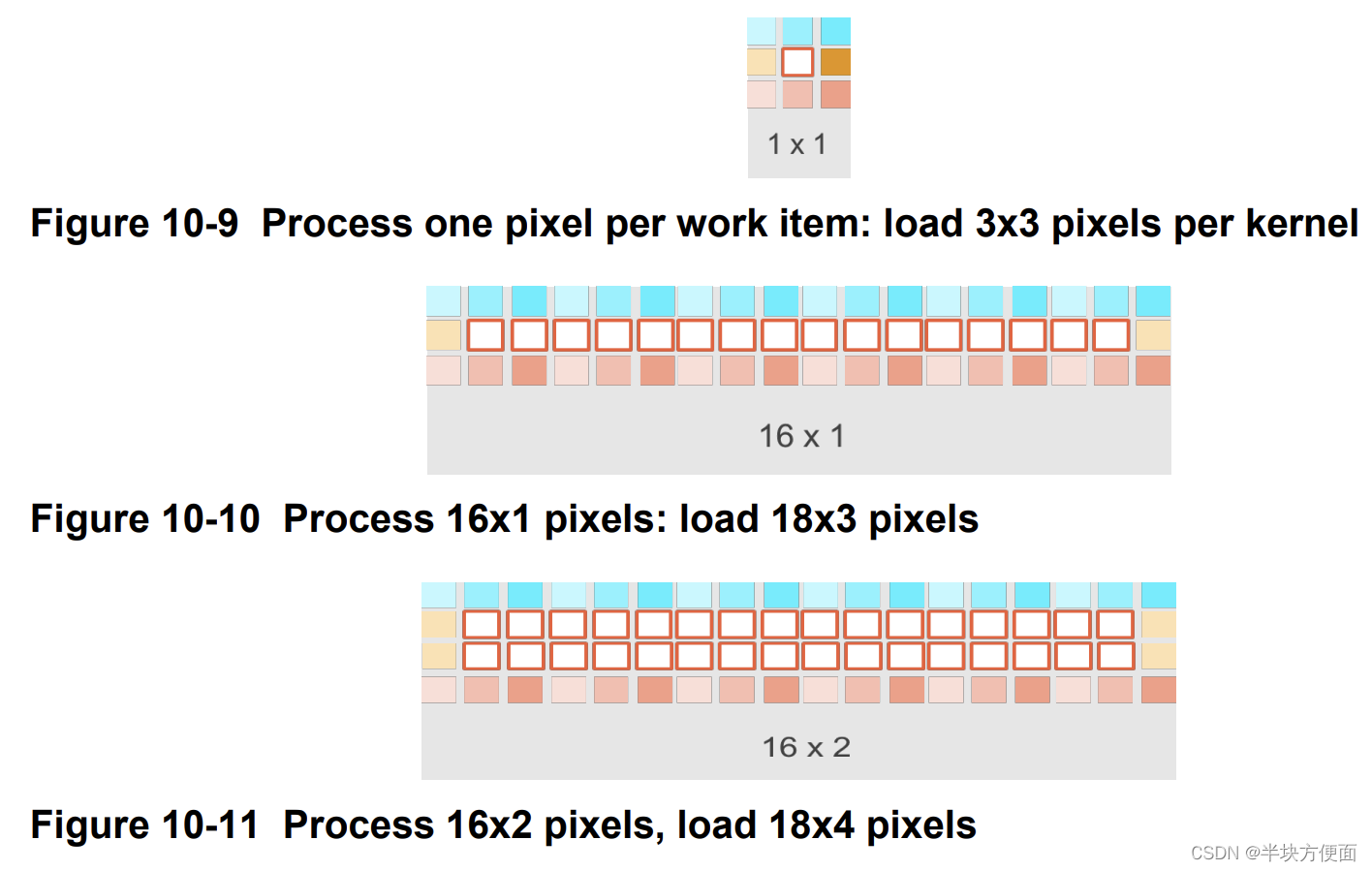
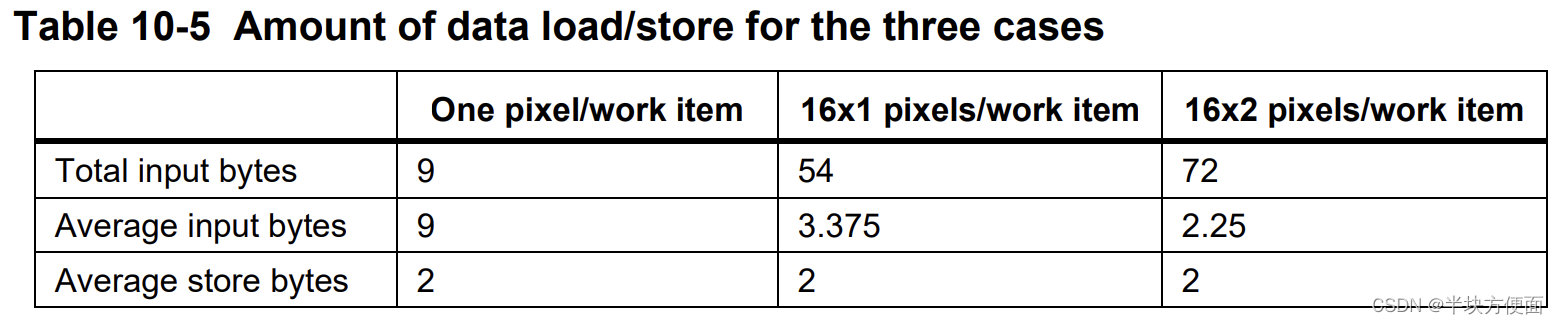
以下表格总结了每种情况下所需的总字节数和平均字节数。在图10-9中的第一种情况中,每个工作项只对一个像素进行Sobel滤波。随着每个工作项的像素数量增加,图10-10和图10-11中所示的情况下要加载的数据量减少。这通常减少了从全局内存到GPU的数据流量,从而获得更好的性能。
10.4.3 Vectorized load/store optimization
对于16x1和16x2的情况,可以通过使用OpenCL中的矢量化加载存储函数(如float4、int4、char4等)进一步减少加载/存储的数量。表10-6显示了矢量化情况下的加载/存储请求数量(假设像素数据类型为8位char)。

进行矢量化加载的代码片段如下:
short16 line_a = convert_short16(as_uchar16(*((__global uint4 *)(inputImage+offset))));
在边界有两个像素需要加载,如下所示:
short2 line_b = convert_short2(*((__global uchar2 *)(inputImage + offset + 16)));
注意:每个工作项处理的像素数量的增加可能会导致寄存器占用的压力加大,导致寄存器溢出到私有内存并导致性能下降。
10.4.4 Performance and summary
在应用了这两个优化步骤之后,观察到了显著的性能提升,如图10-12所示,其中在MSM8992(Adreno 418)上的原始性能(每个工作项一个像素)被归一化为1。
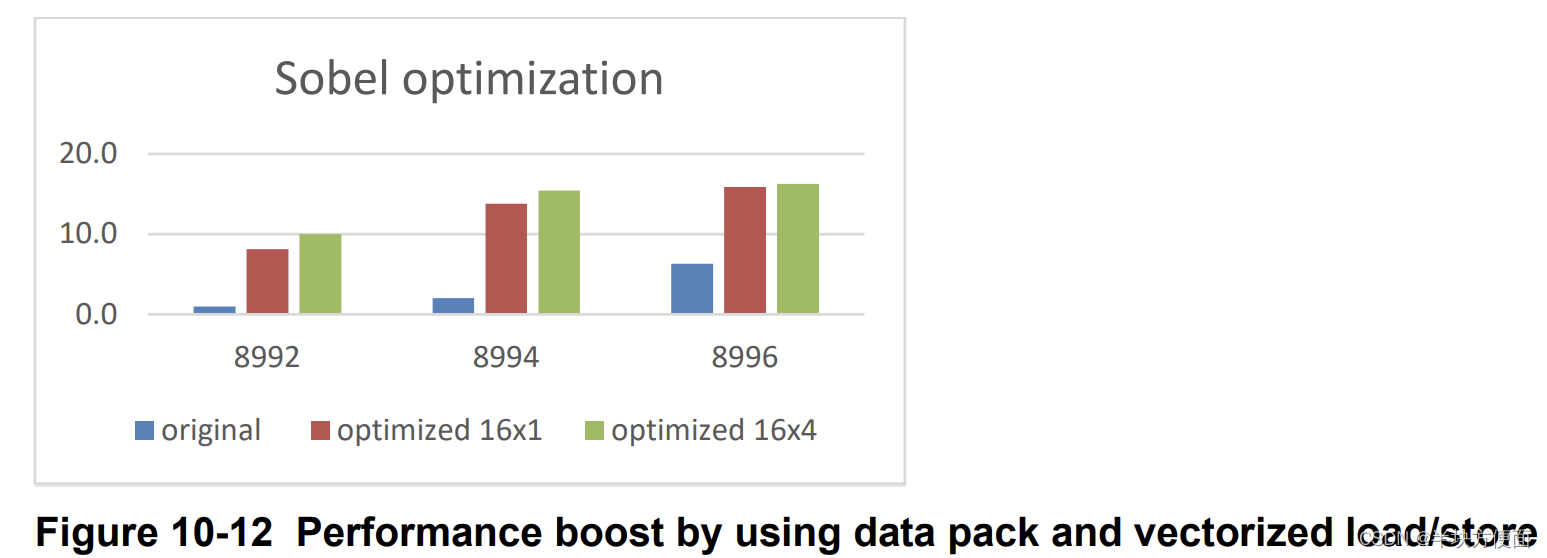
总结一下,以下是这个用例优化的关键点。
- 数据打包提高了内存访问效率。
- 使用矢量化加载/存储来减少内存流量。
- 在这种情况下,短类型优于整数或字符类型。
在这种情况下,没有使用本地内存。数据打包和矢量化加载/存储已经最小化了可重复使用的数据重叠。因此,使用本地内存并不一定会提高性能。可能还有其他选项来提升性能,例如使用纹理而不是全局缓冲区。
10.5 总结
本章提供了一些示例和代码片段,演示了前几章介绍的优化规则以及性能的变化。开发人员应该尝试在真实设备上跟随这些步骤。由于编译器和驱动程序的升级,不是所有的结果都能够完全重现。但总体而言,通过这些优化步骤应该能够实现类似的性能提升。
本节根据案例讲解优化技巧,可以进行参考,没有给出具体的代码。后续研究我会写一些完整的案例供参考。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 安卓检查通话自动录音功能是否开启,并跳转到开启页面
- 如何高效测试APP,快速定位bug?
- 179.【2023年华为OD机试真题(C卷)】最大坐标值(模拟实现Java&Python&C++&&JS)
- rtsp视频在使用unity三维融合播放后的修正
- Python+requests搭建接口自动化测试框架
- Oracle 拼接字符串
- C++面试实战问题之队列、链表
- 超分辨率重建
- watchdog,一个无敌的 Python 库
- 国产开源模型标杆,能力比肩ChatGPT!书生·浦语2.0发布,支持免费商用