我的隐私计算学习——联邦学习(3)
本篇笔记主要是根据这位老师的知识分享整理而成【公众号:秃顶的码农】,我从他的资料里学到了很多,期间还私信询问了一些困惑,都得到了老师详细的答复,相当nice!
(五)纵向联邦学习 — 安全树思路
可以通过以下脉络学习:
决策树 ---------> 集成方法Bagging & Boosting ---------> GBDT ---------> XGBoost ---------> Secure Boost Tree
? 这个版块的内容和机器学习高度相关,关于机器学习各类模型的优化算法此处不再赘述,但对于模型效果评估,特别是分类模型,有几个容易混淆的概念需要理清:
a. 准确率,这是最常用的分类性能指标,它衡量的是分类正确的样本数量占总样本数量的比例。
b. 精确率,很容易和准确率混为一谈,事实上,它评估的是模型预测值为 1 的样本中有多少真的是 1 的,即预测出正样本里面有多少真的是正的。
c. 召回率,度量的是在所有的正样本中,有多少正样本能够被模型预测出来,即正确预测的正例数除以实际正例总数。
d. F值,又称为 F1 Score,是精确率和召回率的调和平均数。? 以上指标均依赖于混淆矩阵,然而实际的模型输出值往往不是直接的分类结果,而是每个样本属于各个类别的概率值,对于二分类问题,从概率值到类别还需要确定一个阈值,这个阈值的确定也会直接决定混淆矩阵的结果,进而对效果评估指标的计算造成影响。既然这样,是否有什么指标是不受阈值选择影响的呢?这就需要用到 AUC( Area Under Curve ) 了,即曲线下的面积,这里的曲线指的是 ROC 曲线。
? 而对于回归模型,最常见的评估指标是平均平方误差 MSE、平均绝对误差 MAE 或 均方根误差 RMSE。然而这些指标都有缺点,比如容易受到异常值的影响,以及受到预测标签本身的量级影响大,不利于效果比较等。因此,一个更好的回归模型评估指标是可决系数,又被称为 R2。
? R2 的取值范围实际上是负无穷到 1,由公式可知,其取值越大,模型的拟合效果就越好。
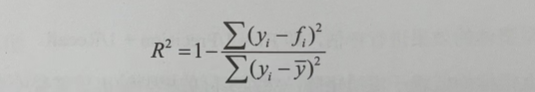
1. 决策树
? 首先需要了解熵的概念,简单来说,混乱程度越大,熵值就越高。代入一些例子可以发现,我们追求的是熵值或者基尼系数越小越好。那么如何构造一棵决策树呢?基本想法是随着树深度的增加,节点的熵迅速地降低。熵降低的速度越快越好,这样我们有望得到一颗高度最矮的决策树。关于信息熵,信息增益选取决策树根结点的过程,参考机器学习教材书实例。

---------- ID3(信息增益)----------
? 传统的根据信息增益选取根节点的算法就是 ID3 算法,但这个算法有一个很大的问题:由于我们往往会给属性各自分配一个编号,1,2,3……n,依据信息增益的原理,如果把编号作为划分属性,信息增益很有可能最大化,而我们对属性的划分当然要和其编号是无关的,所以这种方法有些弊端。
---------- C4.5(信息增益率)----------
? 光看信息增益是不靠谱的,那么在这个基础上做个改进,引入信息增益率。除了计算信息增益,还要再计算其本身的熵值,用信息增益去除以这个熵值,得到信息增益率。
---------- CART(Gini系数)----------
? 基尼系数的计算方法在上图有提到,和熵值的计算方法相差不大。
---------- 评价函数 ----------
? 我们总需要一个指标,来判断决策树是否达到决策目标或决策效果,所以此处引入评价参数。里面的 H ( t ) {H(t)} H(t) 代表的是每个叶子节点的熵值或基尼系数, N t N_t Nt? 代表的是叶子节点所拥有的样本数量,可以理解为权重值。决策树决策过后,我们希望每个叶子节点的纯度越高越好,也就是说 H ( t ) {H(t)} H(t) 应该越小越好。所以这个评价函数其实类似于损失函数。

如果碰到连续值,我们可以让其离散化,比如排序后使用二分法,把原本连续的属性值划分出来,划分之后再使用决策树算法。
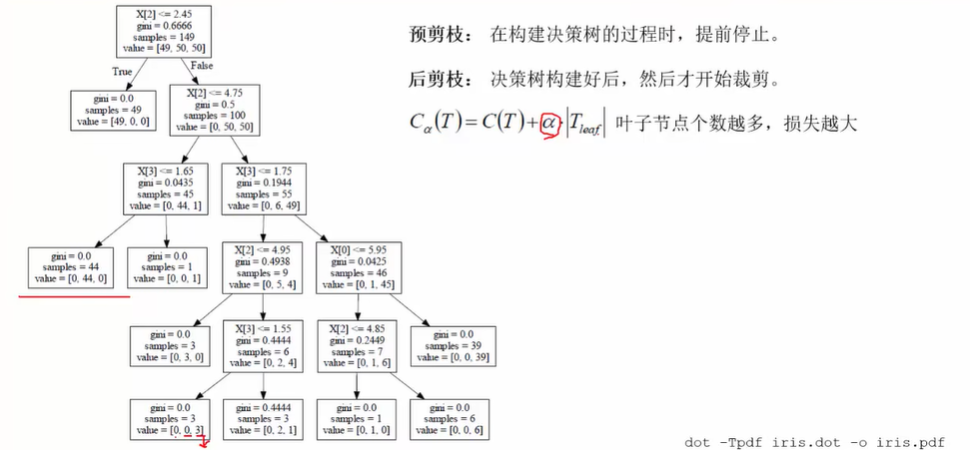
? 构造决策树的原则是让其高度尽量地矮。但有的时候决策树为了划分每一个样本,对样本的划分太碎,会构造得非常庞大,这就造成了过拟合的问题。所以在构造决策树的时候,我们常常需要进行预剪枝或者后剪枝操作。判断决策树是否有必要进行剪枝操作,我们采用这么一个 C a ( T ) C_a(T) Ca?(T) 函数,相当于对原本有关叶子节点的损失函数做个改进,如果决策树的叶子节点越多,那损失函数就会越大, α \alpha α 是一个预设的值,可以衡量叶子节点的数量增减情况。剪枝的思想就是,计算一个节点分枝前和分枝后的损失值,如果分枝后的损失值更大了,那就进行剪枝操作,否则的话就保留。
? 很多棵决策树组合到一起,就变成了随机森林,这些决策树的决策结果最终影响随机森林的决策结果。随机森林具有双重随机性,第一重是数据随机性,在选取样本构造决策树的时候,不会选取所有样本,而是随机选取一定比例的样本数据,第二重随机性是特征随机性,也是随机选取一定比例的特征数据来构造决策树。
2. 集成方法Bagging & Boosting

? 集成学习主要分为两种模式,Bagging 与 Boosting 模式,由于树模型是比较有效的机器学习模型,所以集成学习里面与树模型的结合非常紧密,将 Bagging 和 Boosting 分别和树模型结合分别生成:
- Bagging + 决策树 = 随机森林
- Boosting + 决策树 = GBDT
- Boosting + 二阶可导 Loss 函数 = Xgboost
? 这两种模式的区别主要是,弱学习器的组合方式。机器学习里面有两个非常重要的基础概念:Variance 与 Bias,就是方差与偏差,用来衡量模型,但是他们两个本身其实是矛盾的,Bagging 与 Boosting 分布针对 Variance 与 Bias 进行探索。Bagging 的重点在于获得一个方差更小的集成模型,而 Boosting 则将主要生成偏差更小的集成模型(即使方差也可以被减小)。
------------------------ Bagging ---------------------------
Bagging 即套袋法,通过并行地计算多个弱学习器,将多个弱学习器的结果进行投票或者均值等粗略,进行融合凝练,表征模型的判断。
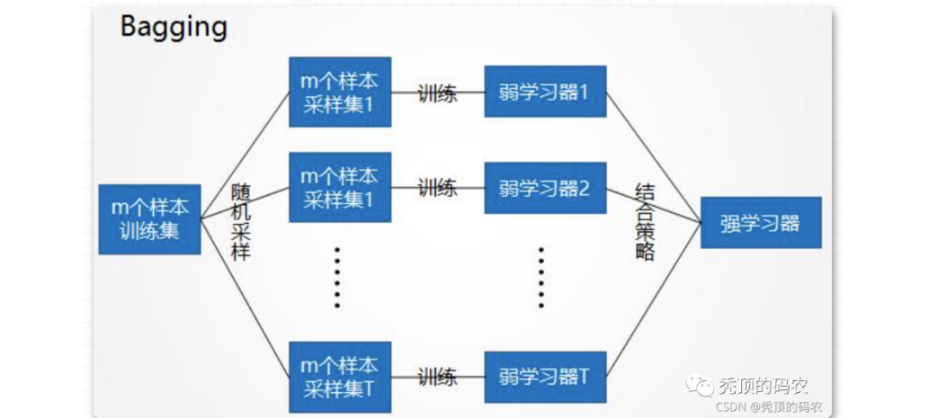
Bagging 的主要过程是这样的:
- 从原始样本集中抽取训练集。每轮从原始样本集中使用 Bootstraping 的方法抽取 n 个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行 k 轮抽取,得到 k 个训练集。( k 个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到 k 个模型。k 个模型相互独立,没有依赖关系。
- 集体智慧生成最终模型:
- 对分类问题:针对 k 个模型的结果,采用投票的方式得到分类结果
- 对回归问题,针对 k 个模型的结果,计算数学期望作为最后的结果
------------------------ Boosting ---------------------------
? 其主要思想是将弱学习器组装成一个强学习器,并且通过一些列的顺序迭代过程,通过弱学习器的迭代组合,调整关键样本权重,训练出一组弱分类器,进行模型的迭代。注意,Boosting 过程中会基于上一轮的训练结果来更新训练集的数据权重。
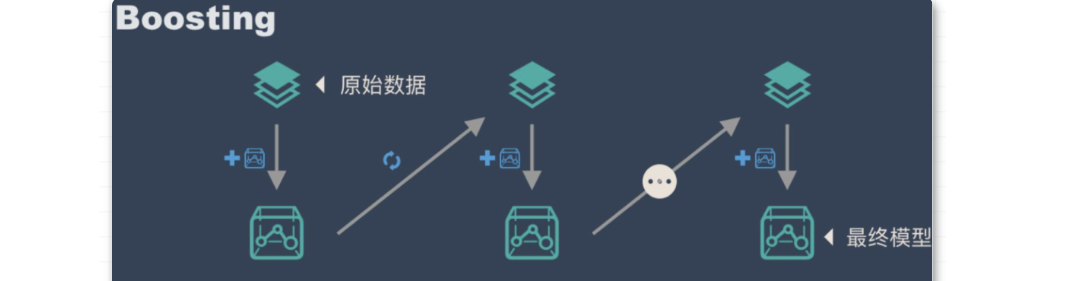
关于 Boosting 的两个核心问题:
如何改变训练数据的概率分布与样本权重?
? 通过提高那些在前一轮被弱学习器判断错误的样例的权值,减小前一轮判断准确的样本权值,达到对错误信息的纠正的目标,亦或者通过学习残差的方式进行拟合。
如何组合弱分类器?
? 通过加法模型将弱分类器进行线性组合,比如 AdaBoost 通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值,亦或基于 GBDT 的残差加法模型组合,通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。

3. GBDT、Adaboost 与 XGBoost
(1)GBDT (Gradient Boosting Decision Tree)
? 即梯度提升迭代决策树,是 Boosting 算法的一种。与 AdaBoost 不同,GBDT 每一次的计算是都为了减少上一次的残差,进而在残差减少(负梯度)的方向上建立一个新的模型。它的原理简单来说,就是所有弱分类器的结果相加等于预测值,然后下一个弱分类器去拟合误差函数对预测值的梯度/残差(这个梯度/残差就是预测值与真实值之间的误差)。当然了,它里面的弱分类器的表现形式就是各棵树。

GBDT 的约束条件是:
- 「GBDT使用的弱学习器必须是CART,且必须是回归树」。
- 「GBDT用来做回归预测,当然也可以通过阈值的方式进行分类,不过主要是进行回归预测」。
所以一定要记住,「GBDT的弱学习器一定只能是CART树」,一般是基于 MSE 的 Loss 利用最小二乘法计算**「一阶梯度」**。而 Xgb 的弱学习器非常灵活,一般只要求具备二阶导数就可以了。所以很多人把 GBDT 和 Xgb 的概念混淆,或者只说一阶导与二阶导的区别,都是太片面的。
------------------------ 什么是CART树? ---------------------------
数据挖掘或机器学习中使用的决策树有两种主要类型:
- 分类树分析是指预测结果是数据所属的类(比如某个电影去看还是不看)
- 回归树分析是指预测结果可以被认为是实数(例如房屋的价格,或患者在医院中的逗留时间)
而术语分类回归树(CART,Classification And Regression Tree)分析是用于指代上述两种树的总称。

(2)Adaboost(Adaptive Boosting)
? 它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。具体说来,整个 Adaboost 迭代算法就 3步:
-
初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
-
训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
-
将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
(3)XGBoost
? 对于回归树,我们没法再用分类树那套信息增益、信息增益率、基尼系数来判定树的节点分裂了,需要采取新的方式评估效果,包括预测误差(常用的有均方误差、对数误差等)。而且节点不再是类别,是数值(预测值),那么怎么确定呢?有的是节点内样本均值,有的是最优化算出来的比如 Xgboost。Xgboost 本质上还是一个GBDT,但是力争把速度和效率发挥到极致。
? XGBoost 属于 Boosting 方法,基于残差去训练模型来拟合真实数据场景,基于梯度直方图进行高效计算,实现了超大规模并行计算 Boosting Tree,是目前最快最好的开源 Boosting Tree 框架,比常见的其他框架快 10 倍以上。类似的实现方式还有 LightGBM、HistGradientBoostingClassifier 等。详情可参考博客文章辅助理解: 通俗理解 kaggle 比赛大杀器 XGBoost




4. 安全树
对于 Secure Boost Tree来说,只需要进行简单的同态运算就解决,达到和 Xgboost 同样的建模效果。在深入理解 Secure Boost Tree 之前,务必要回顾上面所记录的 Xgb 的关键流程,因为我们要做的事情是基于整个底层的构建,整个模型训练运行态的隐私保护,并不是在 Xgb 上套个壳就可以解决的,所以需要对底层有着深刻的理解与认知,清楚其理念、流转机制、关键数据结构与关键算法。
首先引入一个需要适配的场景,方便理清问题的本质:

根据以上,我们要做到的是:
- 保护双方的特征不被泄露。
- 保护持有label的一方的标签不被泄露。
- 在不泄露双方数据信息的基础上完成联合建模,提振业务。
? 也就是说,对经过 Xgboost 或其他 boosting 算法生成的树群,是需要隐私保护的。可以供选择的隐私计算方法其实还是比较多的,包含同态加密、秘钥分享、混淆电路以及不经意传输等,不过不同的加密有不同的适配场景。接下来看看 Xgboost 这个算法过程哪里需要加密,如何加密:
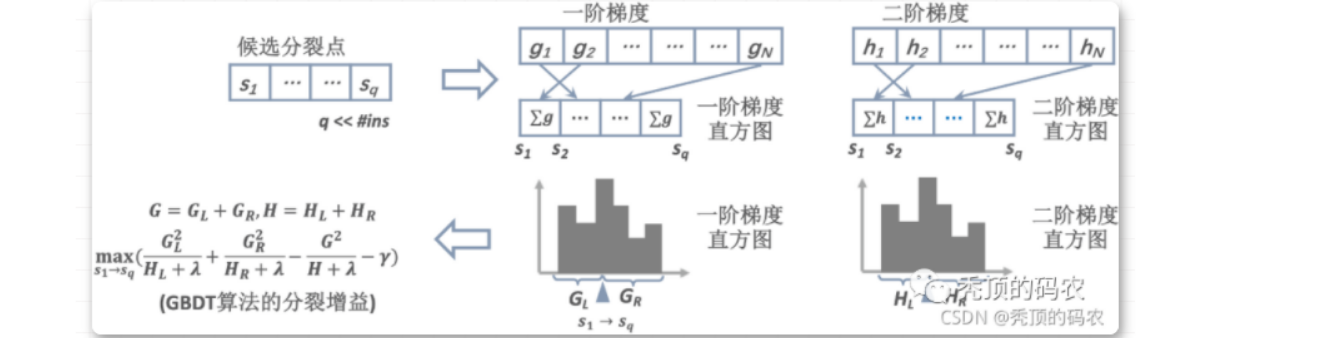
? 整个 Xgb 计算的核心在于梯度直方图的计算,但是梯度直方图的计算是需要 label 的,所以需要持有 label 的一方将计算好的一阶与二阶梯度加密传递给没有label 的一方,进行梯度直方图的构建。
? 但是,如果直接传输一阶与二阶导数,以分类任务中常用的 Logistic Loss 为例,观察一阶梯度,那么对于正样本,其梯度恒负,对于负样本,其梯度恒正,所以直接传输会暴露 label 标签,所以我们需要进行隐私加密算法的引入。由于梯度直方图的建立过程中只需要使用加法计算(一阶导与二阶导分别累加,然后代入最终的目标函数),所以可以采用同态加密(半同态,只有加法运算)的方式将梯度传递给无 label 的一侧,进行梯度直方图的构建,梯度直方图构建好之后,再传递给持有 label 的一方进行整体的计算,这样的话 feature 和 label 都没有泄露。
? 同时,由于通过了梯度直方图,实现了未持有 label 一侧特征数据分布的压缩变换刻画,使其不具备具体的精确信息,所以基于大数据、特征分布离散的情况下,想要针对这个进行反推,基本是不太可能。
? 综上,Secure Boost Tree 算法需要对样本梯度进行加密保护。由于梯度直方图的构建只含有加法运算,所以满足加法同态。接下来讲解下这个具体的全链路轮转流程:(首先,定义持有 label 一方为 Active Party;不持有 label 的一方称为 Passive Party。)
-
Actice Party 侧对梯度的加密:在建立一颗新的树的构建过程中,以 Active Party 的视角进行分析
-
对于特征在本侧即 Active Party 侧,因为无需与 Passive Party 进行交互,所以直接计算分裂点的信息增益,无需同步到 Passive Party 侧。
-
对于特征在对侧即 Passive Party 侧,则需要 Acive Party 侧根据当前预测值(初始自己设置超参,比如 0)和 label 进行计算一阶与二阶导数,并将一阶与二阶导数进行半同态加密(可以采用比较出名的 Paillier 库),然后发送至 Passive Party 侧。
-
-
构建梯度直方图
-
双侧根据自己的特征数据建立梯度(一阶与二阶导数)直方图,并且 Passive Party 侧将加密后的梯度直方图发送给 Active Party 侧。
-
至此,Active Party 拥有全部的特征的直方图信息,本侧的直方图是明文,对侧发来的是加密的,使用半同态加密方法进行解密。

- 寻找最优分裂点:到这里,Active Party 侧已经完成了对端的梯度直方图的解密,拥有双方联合的所有特征的梯度直方图,所以并根据分裂增益计算公式,枚举每个特征基于直方图进行计算最优解,找到全局最优分裂点;
- 若最优分裂点属于 Active Party 侧,则无需传递分裂信息到对端。
- 若最优分裂点属于 Passive Party 侧,Active Party 侧需要将分裂信息(ID 分位线,不包含信息增益)返回给 Passive Party 方进行解析。

- 树结点:拥有最优分裂点的一侧,对该树结点上的样本进行分裂,划分成左右两个子数据集,并将划分结果发送给对侧,作为子节点的分裂样本。
- 预测值的更新:Active Party 侧根据计算公式,计算叶子结点的预测值;但是不会同步,所以 Passive Party 侧无法得知叶子结点的权重。
至此,整体全链路流程描述完毕。以上就是 Secure Boost Tree 算法完整的构建过程。
扩展:这个方案有没有不安全的地方?
? 上述流程中,针对双方交互中传输的信息,进行隐私安全分析,主要针对两个维度,一个是 label 的维度,一个是 feature 的维度,这个也是整个训练过程中涉及到的所有的数据要素,要泄露也就是从这两方面有隐患了。
? 那么,针对以上问题,建模训练的时候可以注意:


2023年10月份新开了一个GitHub账号,里面已放了一些密码学,隐私计算电子书资料了,之后会整理一些我做过的、或是我觉得不错的论文复现、代码项目也放上去,欢迎一起交流!Ataraxia-github
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前端开发必备 HTML的常用标签(一)
- 【复现】D-Tale SSRF漏洞(CVE-2024-21642)_26
- 大模型 RAG 优化 收集一
- 宿舍安全用电监控系统解决方案
- leetcode-位1的个数
- ModuleNotFoundError: No module named ‘cv2‘,‘yaml‘,‘einops‘,安装指令
- 系统学习Python——类(class):静态方法(staticmethod)和类方法(classmethod)-[使用静态方法和类方法]
- JAVA 版多商家入驻 直播带货 商城系统 B2B2C 之 鸿鹄云商B2B2C产品概述
- vivado 慢速到快速时钟之间的多循环
- Javascript-中常用运算符