C++从零开始的打怪升级之路(day2)
这是关于一个普通双非本科大一学生的C++的学习记录贴
在此前,我学了一点点C语言还有简单的数据结构,如果有小伙伴想和我一起学习的,可以私信我交流分享学习资料
那么开启正题
今天继续学习了一些C++的基础关键词,和一些简单的知识点,明天开始类和对象,感觉很高级,也很感兴趣像继续深入学习生长,希望屏幕前的你与我共勉,一起努力吧!
1.引用
1.0
昨天了解了一些引用的基本用法,现在来回顾一下,并加上今天刚学的知识
1.1引用的概念
引用不是定义一个新的空间,而是给已存在的空间取了一个别名,如同我们在不同的场合中和不同人打交道被称呼的名字不一样,引用和引用的变量共用同一块内存空间
void Test()
{
int a = 10;
int& ra = a;//类型& 引用变量名 = 引用实体
printf("%p\n",&a);
printf("%p\n",&ra);//这里打印出来的地址是一样的
}引用类型必须和引用实体的类型是一样的
1.2引用的特性
a.引用在定义时就必须初始化?
b.一个变量可以有多个引用
c.引用一旦引用一个实体,就不能引用其他实体
void Test()
{
int a = 0;
//int& ra; 这条语句在编译时候就会报错
int& ra = a;
int& rra = ra; //a,ra,rr共用同一块内存空间
int c = 10;
ra = c; //这条语句并不会将ra的引用对象改为c
//而是将c的值赋给ra
}1.3常引用
有些场景我们会对变量进行const修饰,这时就出现了常引用的概念,我们在使用时需要注意
void Test()
{
const int a = 10;
int& ra = a; //编译不会通过
//a被const修饰是只读的,而ra是可读可写的
//这里权限被放大,是不行的
int b = 20;
const int& rb = b;
//编译通过
//b是可读可写的,rb是只读的
//这里权限被缩小,是可以的
}了解到如上特性,我们还可以写如下的代码?
void Test()
{
int a = 0;
const double& b = a;
//因为b是只读的,而这里出现了隐式转换
//创建出一个临时变量,临时变量是只读的
//加上const修饰的b只读,不会权限越界,所有编译通过
}1.4使用场景
a.做参数?
作用:输出型参数、提高效率
//这是借助指针进行交换
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//这是借助引用交换
void Swap(int& p1, int& p2)
{
int tmp = p1;
p1 = p2;
p2 = tmp;
}当然以上两函数构成函数重载,是可以正常调用的
b.作返回值
作用:提高效率、?

可以看到,程序并没有输出我们想要的结果,这是因为ret是一个临时变量,在函数调用结束后,栈帧销毁,他的访问权限就没有了,而我们在main函数当中使用引用来借助c来访问它,必然是不安全的,不可靠的,实际运用当中,我们应给ret变量,也就是要输出的变量,加上static修饰,以确保它的安全性
int& Add(int x, int y)
{
static int ret = x + y;
return ret;
}
int main()
{
int& c = Add(1, 2);
cout << "hehe" << endl;
cout << c << endl;
return 0;
}1.5传值、传引用效率比较
以值作为参数或者返回类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时拷贝,因此用值作为参数或者返回值类型,效率是很低的,特别是参数或者返回类型都非常大的时候,效率就更低了?
1.6引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和实体共用用一块内存空间
在底层实现实际是有空间的,因为引用是按照指针方式来实现的
引用和指针的不同点
1.引用概念上是变量的别名,而指针存储一个变量的地址
2.引用在定义的时候就必须初始化,而指针没有要求(实质上,我们在用指针时大多情况都进行了初始化)
3.引用在引用一个实体后,就不能引用其他实体,而指针指向的变量可以变化(除const修饰情况下)
4.没有NULL引用,但有NULL指针
5.有多级指针,没有多级引用
6.引用比指针用起来更加安全
2.内联函数
2.1概念
用inline修饰的函数叫做内联函数,编译时会在调用内联函数的地方展开,没有函数栈帧的开销,提升了程序运行的效率
一般情况下在Debug版本下内联函数不会展开,在release版本下才会展开(一般20~30行代码量,太长或者递归编译器智能识别将不展开)?(如果在汇编代码中看到了call 代表没有展开)
2.2特性
a.inline函数是一个以空间换时间的做法,在优化当中,我们常需要用到这样的思想
b.inline对编译器只是一个建议,实际展开与否取决于编译器
c.inline函数不支持声明和定义分离,分离会导致链接错误,因为inline被展开,就没有了函数地址,链接也就找不到了
学到这里,我们不免想起来宏
回顾一下宏的特性
优点
1.提高代码复用性
2.提高性能
缺点
1.不能调试(因为预编译就完成了替换)
2.导致代码可读性差,可维护性差,容易误用
3.没有类型安全检查,安全性低
C++中替代宏的方式
1.常量定义? 换用 全局变量const修饰
2.短小函数定义换用内联函数
?3.auto关键字
3.1auto的使用
auto是一个智能识别类型的关键字
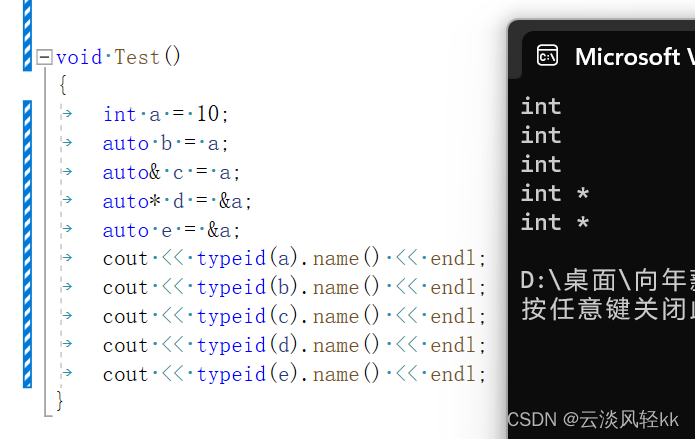
如上,typeid(变量名).name() 是一个求变量的类型的函数,借助它我们可以体会到auto的智能之处,当然在d,e两个变量时我们发现,d变量定义时*是多余的,因为auto的智能可以将类型自动识别
3.2auto的不足
auto并不是完全智能,它也有一些做不到的事情
a.不能作为函数的参数
b.不能声明数组
c.不能同时定义多个变量
void Add(auto x,auto y);//err
{
auto arr[] = { 1, 2, 3 }; // err
}
auto a = 10, b = 3.5 ; //err?4.基于范围的for循环
人生中接触到的第一个语法糖
C语言中我们的for循环经常这样使用
void Test()
{
int a[] = { 1,2,3,4,5,6 };
int i = 0;
for (i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
i *= 2;
}
}C++11中可以这样遍历数组
void Test()
{
int a[] = { 1,2,3,4,5,6 };
for (auto& e : a)
{
e *= 2;
}
}auto自动识别类型,要注意的是这里要借助引用,不然我们得到的e只是一份临时拷贝,不能对原数组进行修改
5.指针空值nullptr
?在C语言当中
NULL实质上是一个宏,而nullptr是C++11的一个宏,它们的定义大致如下
#define NULL 0;
#define nullptr (void*)(0);可见,NULL实质上就是0,而nullptr是将0强转为无类型的指针?
为了提高代码的健壮性,以后使用空指针尽量使用nullptr
今天的博客就到这里了,感谢你能看到这里,希望能对你有所帮助!我们下次再见!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!