Oracle merge into 语句用法 Oracle merge into 批量更新 关联更新 批量修改 关联修改
Oracle merge into 语句用法 Oracle merge into 批量更新 关联更新 批量修改 关联修改
一、概述
????????在开发任务中,遇到一个需求,同一批次的名单;根据一定的条件判断是否存在,若存在,则进行更新操作;若不存在,进行插入操作。实现方法有两种:
????????1. java代码中,使用业务逻辑来判断是否存在,存在,修改;不存在,添加。
????????2、由于使用的Oracle数据库,可以使用merge into语句来实现批量的添加、修改操作
????????本文将记录和讲解merge into 语句的使用 和 mybatis中使用 merge into 语句 。
二、代码示例
????????1、 merge into 语法规则
MERGE INTO target_table tt -- 目标表
USING source_table st -- 关联表
ON (tt.id = st.id AND tt.age = st.age ) -- 是否唯一条件,可以是多个
WHEN MATCHED AND tt.name <> st.name THEN -- 1、满足条件--带额外条件
WHEN MATCHED THEN -- 2、满足条件-- 不带额外条件
UPDATE SET -- 执行更新操作,注意没有 表名 update set
tt.name = st.name ,
tt.age = st.age
[ WHEN NOT MATCHED THEN ] -- 3、不满足条件, 可选,非必须语句
INSERT (id, name) VALUES (st.id, st.name); -- 执行添加操作,注意没有表名 insert
????????2.1、创建2张表
-- WUDI.USER_TARGET definition
CREATE TABLE "WUDI"."USER_TARGET"
( "ID" VARCHAR2(100),
"NAME" VARCHAR2(100),
"ADDR" VARCHAR2(100)
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "WUDI" ;
COMMENT ON COLUMN WUDI.USER_TARGET.ID IS '主键';
COMMENT ON COLUMN WUDI.USER_TARGET.NAME IS '名字';
COMMENT ON COLUMN WUDI.USER_TARGET.ADDR IS '地址';
--- USER_SOURCE 表创建过程略????????2.2、插入数据
-- 1.1、 USER_TARGET 初始化数据 ID= 1,2,3
INSERT INTO WUDI.USER_TARGET(ID, NAME, ADDR) VALUES('1', 'TARGET=1', '');
INSERT INTO WUDI.USER_TARGET(ID, NAME, ADDR) VALUES('2', 'TARGET=2', '');
INSERT INTO WUDI.USER_TARGET(ID, NAME, ADDR) VALUES('3', 'TARGET=3', NULL);
-- 2.1、 USER_SOURCE 初始化数据 ID= 3,4,5
INSERT INTO WUDI.USER_SOURCE (ID, NAME, ADDR) VALUES('3', 'SOURCE=3', NULL);
INSERT INTO WUDI.USER_SOURCE (ID, NAME, ADDR) VALUES('4', 'SOURCE=4', NULL);
INSERT INTO WUDI.USER_SOURCE (ID, NAME, ADDR) VALUES('5', 'SOURCE=5', NULL);
????????2.2.1、USER_TARGET 表数据如下

????????2.2.2、USER_SOURCE 表数据如下
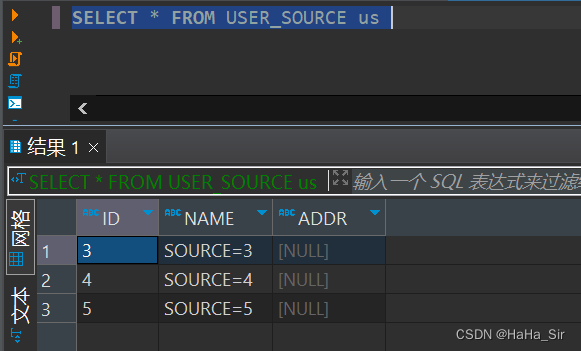
????????2.3、使用merge into 更新
-- MERGE INTO : USER_SOURCE 数据 合并到 USER_TARGET , 存在修改;不存在添加
MERGE INTO USER_TARGET T1
USING USER_SOURCE T2
ON (T1.ID = T2.ID )
WHEN MATCHED THEN
UPDATE SET T1.NAME = T2.NAME
WHEN NOT MATCHED THEN
INSERT (ID,NAME) VALUES(T2.ID,T2.NAME) ;
????????2.3.1、merge into 更新后 USER_TARGET 表数据如下
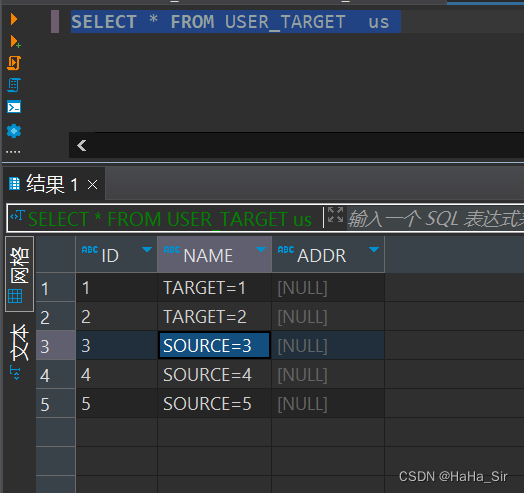
????????2.4、使用merge into 更新 --- 子查询
-- 3.2、不存在 ID=7,8 添加数据
MERGE INTO USER_TARGET T1
USING (
SELECT 7 AS ID , 'SOURCE=7' AS NAME FROM DUAL
UNION ALL
SELECT 8 AS ID , 'SOURCE=8' AS NAME FROM DUAL
)T2
ON (T1.ID = T2.ID)
WHEN NOT MATCHED THEN
INSERT (ID,NAME) VALUES(T2.ID,T2.NAME) ; ????????2.4.1、merge into 更新---子查询 USER_TARGET 表数据如下
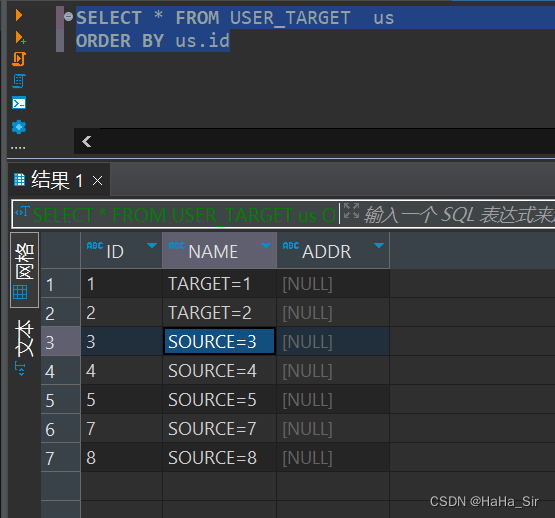
????????3、MyBatis中使用示例
<update id="updateBatch" parameterType="list">
MERGE INTO USER_TARGET T1
USING (
<foreach collection="list" item="e" separator="UNION ALL">
SELECT #{e.id} AS ID , #{e.name} AS NAME FROM DUAL
</foreach>
) T2
ON (T1.ID = T2.ID )
WHEN MATCHED THEN
UPDATE SET T1.NAME = T2.NAME
WHEN NOT MATCHED THEN
INSERT (ID,NAME) VALUES(T2.ID,T2.NAME) ;
</update>
????????4、merge into NULL值问题
????????在使用merge into语句时,若遇到 on 中遇到的两个字段值,都是null值的情况,不会执行 when matched then 语句,会一直执行 when not matched then ... , 也就 on条件中 null=null 的条件是false , 如本示例中 ,会一直执行 when not matched then 。
ON (T1.ID = T2.ID AND T1.ADDR = T2.ADDR )MERGE INTO USER_TARGET T1
USING (
SELECT * FROM USER_SOURCE a WHERE a.id ='3'
)T2
-- ON 条件不满足,会执行insert插入数据
ON (T1.ID = T2.ID AND T1.ADDR= T2.ADDR)
WHEN MATCHED THEN
UPDATE SET T1.NAME = T2.NAME
WHEN NOT MATCHED THEN
INSERT (ID,NAME) VALUES(T2.ID,T2.NAME) ; 
????????4.1、COALESCE函数解决 merge into null 值问题
????????使用 COALESCE 函数,可以将NULL值转换为某个固定的值,来进行判断,这样遇到 NULL=NULL的情况,可以转换为 1=1 ,这样就可以避免NULL值的时候,判断情况不准确的问题。
MERGE INTO USER_TARGET T1
USING (
SELECT * FROM USER_SOURCE a WHERE a.id ='3'
)T2
-- COALESCE 函数,将NULL值转换为1
ON (T1.ID = T2.ID AND COALESCE(T1.ADDR,'1') = COALESCE( T2.ADDR,'1'))
WHEN MATCHED THEN
UPDATE SET T1.NAME = T2.NAME
WHEN NOT MATCHED THEN
INSERT (ID,NAME) VALUES(T2.ID,T2.NAME) ;
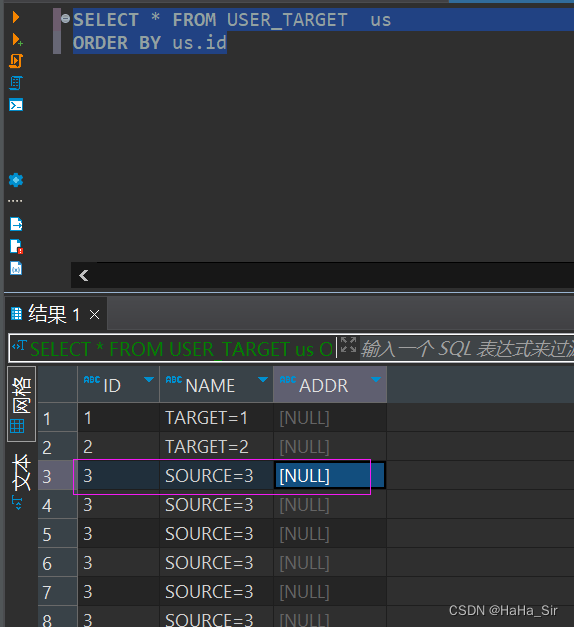
三、总结
????????1、on后面的关联条件成立时:
????????on后面的关联条件成立时: WHEN MATCHED THEN ,可以 update、delete 。
????????2、on后面的关联条件不成立时:
????????on后面的关联条件不成立时: WHEN NOT MATCHED THEN ,可以insert
????????3、只会改变 目标表数据 MERGE INTO TABLE , 不会改变 源表数据 USING TABLE
????????4、USING TBALE 支持: 视图 view 、表table 、子查询 subQuery
????????5、WHEN MATCHED THEN 和 WHEN NOT MATCHED THEN , 可以二选其一,也可以同时存在。
参考资料:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 从物联网到数字孪生:智慧社区的未来之路
- Spring Boot的启动器Starter
- 多云环境下的Docker部署策略
- 宝塔部署flask添加ssl即https
- P1019 [NOIP2000 提高组] 单词接龙 刷题笔记
- Linux环境编程基础
- Pytest测试 —— 如何使用属性来标记测试函数!
- wpf使用Popup封装数据筛选框--粉丝专栏
- 多媒体相关知识
- 得帆云X锦江酒店(中国区),iPaaS是传统ESB升级的最佳方案