GBDT-代码
sklearn代码
class sklearn.ensemble.GradientBoostingClassifier(*, loss=‘deviance’, learning_rate=0.1, n_estimators=100, subsample=1.0, criterion=‘friedman_mse’, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, init=None, random_state=None, max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
class sklearn.ensemble.GradientBoostingRegressor(*, loss=‘squared_error’, learning_rate=0.1, n_estimators=100, subsample=1.0, criterion=‘friedman_mse’, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, init=None, random_state=None, max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False, validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
参数解读
| 类型 | 参数/属性 |
|---|---|
| 迭代过程 | 参数: ?n_estimators:集成算法中弱评估器数量,对Boosting算法而言为实际迭代次数 ?learning_rate:Boosting算法中的学习率,影响弱评估器结果的加权求和过程 ?loss, alpha:需要优化的损失函数,以及特定损失函数需要调节的阈值 ?init:初始化预测结果 H 0 H_0 H0?的设置 属性: loss_ :返回具体的损失函数对象 ?init_:返回具体的初始化设置 ?estimators_:返回实际建立的评估器列表 ?n_estimators_:返回实际迭代次数 |
| 弱评估器结构 | criterion:弱评估器分枝时的不纯度衡量指标 max_depth:弱评估器被允许的最大深度,默认3 min_samples_split:弱评估器分枝时,父节点上最少要拥有的样本个数 min_samples_leaf:弱评估器的叶子节点上最少要拥有的样本个数 min_weight_fraction_leaf:当样本权重被调整时,叶子节点上最少要拥有的样本权重( 设定了一个叶节点必须拥有的相对于全部训练样本的最小权重和的比例。权重通常是样本数量,但在处理加权数据时,权重可能与样本数量不同。 控制树的复杂度:) max_leaf_nodes:弱评估器上最多可以有的叶子节点数量 min_impurity_decrease:弱评估器分枝时允许的最小不纯度下降量 |
| 提前停止 | 参数:validation_fraction:从训练集中提取出、用于提前停止的验证数据占比 n_iter_no_change:当验证集上的损失函数值连续n_iter_no_change次没有下降 或下降量不达阈值时,则触发提前停止 tol:损失函数下降量的最小阈值l 属性:n_estimators_ |
| 弱评估器的训练数据 | 参数: ?subsample:每次建树之前,从全数据集中进行有放回随机抽样的比例 ?max_features:每次建树之前,从全特征中随机抽样特征进行分枝的比例 ?random_state:随机数种子,控制整体随机模式 属性: ?oob_improvement:每次建树之后相对于上一次袋外分数的增减 ?train_score_:每次建树之后相对于上一次验证时袋内分数的增减 |
| 其他 | ccp_alpha, warm_start |
-
迭代过程
-
n_estimators:迭代次数(弱评估器次数)
对于样本 x i x_i xi?,集成算法当中一共有𝑇棵树,则参数
n_estimators的取值为T -
learning_rate:学习率(控制 ( H ( x i ) ) (H(x_i)) (H(xi?))的增长速度
H t ( x i ) = H t ? 1 ( x i ) + η ? t f t ( x i ) H_t(x_i) = H_{t-1}(x_i) + \boldsymbol{\color{red}\eta} \phi_tf_t(x_i) Ht?(xi?)=Ht?1?(xi?)+η?t?ft?(xi?)
注意: ? t \phi_t ?t?为第t棵树的权重
-
init:输入计算初始预测结果𝐻0的估计器对象。H 1 ( x i ) = H 0 ( x i ) + ? 1 f 1 ( x i ) H_1(x_i) = H_{0}(x_i) + \phi_1f_1(x_i) H1?(xi?)=H0?(xi?)+?1?f1?(xi?):由于没有第0棵树的存在,因此 H 0 ( x i ) H_0(x_i) H0?(xi?)的值在数学过程及算法具体实现过程中都需要进行单独的确定,这一确定过程由参数
init确定。在该参数中,可以输入任意评估器、字符串"zero"、或者None对象,默认为None对象。
当输入任意评估器时,评估器必须要具备fit以及predict_proba功能(因为GBDT的基学习器为CART,分类回归树),即我们可以使用决策树、逻辑回归等可以输出概率的模型。如果输出一个已经训练过、且精细化调参后的模型,将会给GBDT树打下坚实的基础。
填写为字符串"zero",则代表令 H 0 = 0 H_0 = 0 H0?=0来开始迭代。
不填写,或填写为None对象,sklearn则会自动选择类DummyEstimator中的某种默认方式进行预测作为 H 0 H_0 H0?的结果。DummyEstimator类是sklearn中设置的使用超简单规则进行预测的类,其中最常见的规则是直接从训练集标签中随机抽样出结果作为预测标签,也有选择众数作为预测标签等选项。 -
init_:当模型被拟合完毕之后,我们可以使用该属性来返回输出 H 0 H_0 H0?的评估器对象 -
n_estimators_:实际迭代次数,estimators_:实际建立的弱评估器数量在执行多分类任务时,如果我们要求模型迭代10次,模型则会按照实际的多分类标签数n_classes建立10 * n_classes个弱评估器。对于这一现象,我们可以通过属性
n_estimators_以及属性estimators_查看到。如果是二分类任务,如果我们要求模型迭代10次,则只会有10个弱评估器(而不是10*2)
-
loss- 分类器中的
loss:字符串型,可输入"deviance", “exponential”,默认值=“deviance”
其中"deviance"直译为偏差,特指逻辑回归的损失函数——交叉熵损失,而"exponential"则特指AdaBoost中使用的指数损失函数。对任意样本 i i i而言, y i y_i yi?为真实标签, y i ^ \hat{y_i} yi?^?为预测标签, H ( x i ) H(x_i) H(xi?)为集成算法输出结果, p ( x i ) p(x_i) p(xi?)为基于 H ( x i ) H(x_i) H(xi?)和sigmoid/softmax函数计算的概率值。则各个损失的表达式为:
分类损失函数
二分类交叉熵损失——
L = ? ( y log ? p ( x ) + ( 1 ? y ) log ? ( 1 ? p ( x ) ) ) L = -\left( y\log p(x) + (1 - y)\log(1 - p(x)) \right) L=?(ylogp(x)+(1?y)log(1?p(x)))
注意,log当中输入的一定是概率值。对于逻辑回归来说,概率就是算法的输出,因此我们可以认为逻辑回归中 p = H ( x ) p = H(x) p=H(x),但对于GBDT来说, p ( x i ) = S i g m o i d ( H ( x i ) ) p(x_i) = Sigmoid(H(x_i)) p(xi?)=Sigmoid(H(xi?)),这一点一定要注意。
多分类交叉熵损失,总共有K个类别——
L = ? ∑ k = 1 K y k ? log ? ( P k ( x ) ) L = -\sum_{k=1}^Ky^*_k\log(P^k(x)) L=?k=1∑K?yk??log(Pk(x))
其中, P k ( x ) P^k(x) Pk(x)是概率值,对于多分类GBDT来说, p k ( x ) = S o f t m a x ( H k ( x ) ) p^k(x) = Softmax(H^k(x)) pk(x)=Softmax(Hk(x))。 y ? y^* y?是由真实标签转化后的向量。例如,在3分类情况下,真实标签 y i y_i yi?为2时, y ? y^* y?为[ y 1 ? y^*_{1} y1??, y 2 ? y^*_{2} y2??, y 3 ? y^*_{3} y3??],取值分别为:
y 1 ? y^*_{1} y1?? y 2 ? y^*_{2} y2?? y 3 ? y^*_{3} y3?? 0 0 0 1 1 1 0 0 0 二分类指数损失——
L = e ? y H ( x ) L = e^{-yH(x)} L=e?yH(x)多分类指数损失,总共有K个类别——
L = e x p ( ? 1 K y ? ? H ? ( x ) ) = e x p ( ? 1 K ( y 1 H 1 ( x ) + y 2 H 2 ( x ) ? + ? . . . + y k H k ( x ) ) ) \begin{aligned} L &=exp \left( -\frac{1}{K}\boldsymbol{y^* · H^*(x)} \right) \\ & = exp \left( -\frac{1}{K}(y^1H^1(x)+y^2H^2(x) \ + \ ... + y^kH^k(x)) \right) \end{aligned} L?=exp(?K1?y??H?(x))=exp(?K1?(y1H1(x)+y2H2(x)?+?...+ykHk(x)))?
一般梯度提升(GBMachine)分类器默认使用交叉熵损失,如果使用指数损失,则相当于执行没有权重调整的AdaBoost算法(提升树是缩小上一轮迭代产生的误差,AdaBoost才是调整样本权重)。
-
回归器中的
loss:字符串型,可输入{“squared_error”, “absolute_error”, “huber”, “quantile”},默认值=“squared_error”其中’squared_error’是指回归的平方误差,'absolute_error’指的是回归的绝对误差,这是一个鲁棒的损失函数。'huber’是以上两者的结合。'quantile’则表示使用分位数回归中的弹球损失pinball_loss。对任意样本 i i i而言, y i y_i yi?为真实标签, H ( x i ) H(x_i) H(xi?)为预测标签
平方误差——
L = ∑ ( y i ? H ( x i ) ) 2 L = \sum{(y_i - H(x_i))^2} L=∑(yi??H(xi?))2
绝对误差——
L = ∑ ∣ y i ? H ( x i ) ∣ L = \sum{|y_i - H(x_i)|} L=∑∣yi??H(xi?)∣
Huber损失——
L = ∑ l ( y i , H ( x i ) ) L = \sum{l(y_i,H(x_i))} L=∑l(yi?,H(xi?))
其中 l = { 1 2 ( y i ? H ( x i ) ) 2 , ∣ y i ? H ( x i ) ∣ ≤ α α ( ∣ y i ? H ( x i ) ∣ ? α 2 ) , ∣ y i ? H ( x i ) ∣ > α , ?? α ∈ ( 0 , 1 ) l = \begin{split} \begin{cases}\frac{1}{2}(y_i - H(x_i))^2, & |y_i - H(x_i)|\leq\alpha \\ \alpha(|y_i - H(x_i)|-\frac{\alpha}{2}),& |y_i - H(x_i)|>\alpha \end{cases}\end{split}, \space \space \alpha \in (0, 1) l={21?(yi??H(xi?))2,α(∣yi??H(xi?)∣?2α?),?∣yi??H(xi?)∣≤α∣yi??H(xi?)∣>α??,??α∈(0,1)
quantile损失——
L = ∑ l ( y i , H ( x i ) ) L = \sum{l(y_i,H(x_i))} L=∑l(yi?,H(xi?))
其中 l = { α ( y i ? H ( x i ) ) , y i ? H ( x i ) > 0 0 , y i ? H ( x i ) = 0 ( 1 ? α ) ( y i ? H ( x i ) ) , y i ? H ( x i ) < 0 , ?? α ∈ ( 0 , 1 ) l = \begin{split} \begin{cases} \alpha (y_i - H(x_i)), & y_i - H(x_i) > 0 \\ 0, & y_i - H(x_i) = 0 \\ (1-\alpha) (y_i - H(x_i)), & y_i - H(x_i) < 0 \end{cases}\end{split}, \space \space \alpha \in (0, 1) l=? ? ??α(yi??H(xi?)),0,(1?α)(yi??H(xi?)),?yi??H(xi?)>0yi??H(xi?)=0yi??H(xi?)<0??,??α∈(0,1)
其中 α \alpha α是需要我们自己设置的超参数,由参数
alpha控制。在huber损失中,alpha是阈值,在quantile损失中,alpha用于辅助计算损失函数的输出结果,默认为0.9。
如何选择损失函数
-
当高度关注离群值、并且希望努力将离群值预测正确时,选择平方误差
这在工业中是大部分的情况。在实际进行预测时,离群值往往比较难以预测,因此离群样本的预测值和真实值之间的差异一般会较大。MSE作为预测值和真实值差值的平方,会放大离群值的影响,会让算法更加向学习离群值的方向进化,这可以帮助算法更好地预测离群值。 -
努力排除离群值的影响、更关注非离群值的时候,选择绝对误差
MAE对一切样本都一视同仁,对所有的差异都只求绝对值,因此会保留样本差异最原始的状态。相比其MSE,MAE对离群值不敏感,这可以有效地降低GBDT在离群值上的注意力。 -
试图平衡离群值与非离群值、没有偏好时,选择Huber或者Quantileloss
Huberloss损失结合了MSE与MAE,在Huber的公式中,当预测值与真实值的差异大于阈值时,则取绝对值,小于阈值时,则取平方。在真实数据中,部分离群值的差异会大于阈值,部分离群值的差异会小于阈值,因此比起全部取绝对值的MAE,Huberloss会将部分离群值的真实预测差异求平方,相当于放大了离群值的影响(但这种影响又不像在MSE那样大)。因此HuberLoss是位于MSE和MAE之间的、对离群值相对不敏感的损失。
- 分类器中的
-
-
弱评估器结构
-
max_depth:在原始AdaBoost理论中,AdaBoost中使用的弱分类器都是最大深度为1的树桩或最大深度为3的小树苗,因此基于AdaBoost改进的其他Boosting算法也有该限制,即默认弱评估器的最大深度一般是一个较小的数字**。**对GBDT来说,无论是分类器还是回归器,默认的弱评估器最大深度都为3,因此GBDT默认就对弱评估器有强力的剪枝机制。当随机森林处于过拟合状态时,还可通过降低弱评估器复杂度的手段(
max_depth为None)控制过拟合,但GBDT等Boosting算法处于过拟合状态时,便只能从数据上下手控制过拟合了(例如,使用参数max_features,在GBDT中其默认值为None),毕竟当max_depth已经非常小时,其他精剪枝的参数如min_impurity_decrease一般发挥不了太大的作用。 -
criterion:树分枝时所使用的不纯度衡量指标.不纯度的衡量指标有2个:弗里德曼均方误差friedman_mse与平方误差squared_error通常来说,我们求解父节点的不纯度与左右节点不纯度之和之间的差值,这个差值被称为不纯度下降量(impurity decrease)。不纯度的下降量越大,该分枝对于降低不纯度的贡献越大。
基于弗里德曼均方误差的不纯度下降量
w l w r w l ? + ? w r ? ( ∑ l ( r i ? y i ^ ) 2 w l ? ∑ r ( r i ? y i ^ ) 2 w r ) 2 \frac{w_lw_r}{w_l \space + \space w_r} * \left( \frac{\sum_l{(r_i - \hat{y_i})^2}}{w_l} - \frac{\sum_r{(r_i - \hat{y_i})^2}}{w_r}\right)^2 wl??+?wr?wl?wr???(wl?∑l?(ri??yi?^?)2??wr?∑r?(ri??yi?^?)2?)2
其中 w w w是左右叶子节点上的样本量,当我们对样本有权重调整时, w w w则是叶子节点上的样本权重。 r i r_i ri?大多数时候是样本i上的残差(父节点中样本i的预测结果与样本i的真实标签之差),也可能是其他衡量预测与真实标签差异的指标, y i ^ \hat{y_i} yi?^?是样本i在当前子节点下的预测值。所以这个公式其实可以解读成:左右叶子节点上样本量的调和平均 * (左叶子节点上均方误差 - 右叶子节点上的均方误差)^2
根据论文中的描述,弗里德曼均方误差使用调和平均数(分子上相乘分母上相加)来控制左右叶子节点上的样本数量,相比普通地求均值,调和平均必须在左右叶子节点上的样本量/样本权重相差不大的情况下才能取得较大的值(F1 score也是用同样的方式来调节Precision和recall)。这种方式可以令不纯度的下降得更快,让整体分枝的效率更高。
同时,在决策树进行分枝时,一般不太可能直接将所有样本分成两个不纯度非常低的子集(分别位于两片叶子上);相对的,树会偏向于建立一个不纯度非常非常低的子集,然后将剩下无法归入这个低不纯度子集的样本全部打包成另外一个子集。因此直接使用两个子集之间的MSE差距来衡量不纯度的下降量非常聪明,如果两个子集之间的MSE差异很大,则说明其中一个子集的MSE一定很小,对整体分枝来说是更有利的。
平方误差的不纯度下降量
∑ p ( r i ? y i ^ ) 2 w l + w r ? ( w l w l + w r ? ∑ l ( r i ? y i ^ ) 2 + w r w l + w r ? ∑ r ( r i ? y i ^ ) 2 ) \frac{\sum_p{(r_i - \hat{y_i})^2}}{w_l + w_r} - (\frac{w_l}{w_l+w_r} * \sum_l{(r_i - \hat{y_i})^2} + \frac{w_r}{w_l+w_r} * \sum_r{(r_i - \hat{y_i})^2}) wl?+wr?∑p?(ri??yi?^?)2??(wl?+wr?wl???l∑?(ri??yi?^?)2+wl?+wr?wr???r∑?(ri??yi?^?)2)
大部分时候,使用弗里德曼均方误差可以让梯度提升树得到很好的结果,因此GBDT的默认参数就是Friedman_mse。不过许多时候,我们会发现基于平方误差的分割与基于弗里德曼均方误差的分割会得到相同的结果。
-
-
提前停止
什么时候使用提前停止呢?一般有以下几种场景:
- 当数据量非常大,肉眼可见训练速度会非常缓慢的时候,开启提前停止以节约运算时间
- n_estimators参数范围极广、可能涉及到需要500~1000棵树时,开启提前停止来寻找可能的更小的n_estimators取值
- 当数据量非常小,模型很可能快速陷入过拟合状况时,开启提前停止来防止过拟合
过拟合 VS 欠拟合
在实际训练过程中,刚开始训练时,测试集和训练集上的损失一般都很高(有时,训练集上的损失甚至比测试集上的损失还高,这说明模型严重欠训练),但随着训练次数的增多,两种损失都会开始快速下降,一般训练集下降得更快,测试集下降得缓慢。直到某一次迭代时,无论我们如何训练,测试集上的损失都不再下降,甚至开始升高,此时我们就需要让迭代停下。
如下图所示,下图中横坐标为迭代次数,纵坐标为损失函数的值。当测试集上的损失不再下降、持续保持平稳时,若继续训练会浪费训练资源,迭代下去模型也会停滞不前,因此需要停止(左图)。当测试集上的损失开始升高时,往往训练集上的损失还是在稳步下降,继续迭代下去就会造成训练集损失比测试集损失小很多的情况,也就是过拟合(右侧),也需要提前停止。在过拟合之前及时停止,能够防止模型被迭代到过拟合状况下。
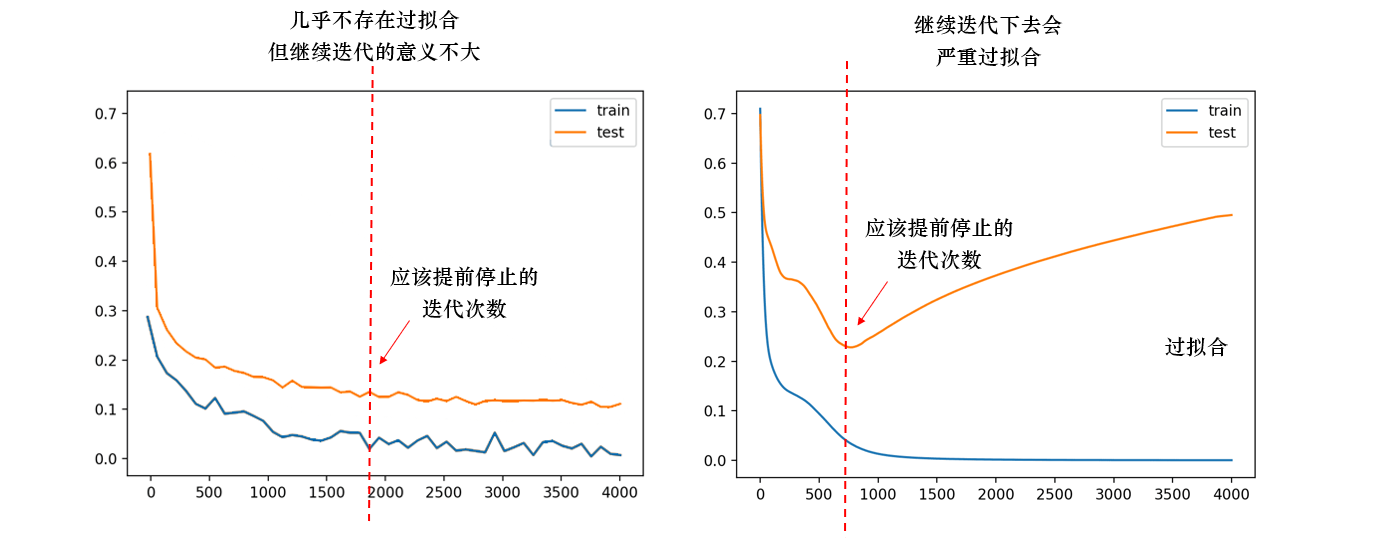
validation_fraction:从训练集中提取出、用于提前停止的验证集数据占比,值域为[0,1]。n_iter_no_change:当验证集上的损失函数值连续n_iter_no_change次没有下降或下降量不达阈值tol时,则触发提前停止。平时则设置为None,表示不进行提前停止。(即便我们规定的n_estimators或者max_iter中的数量还没有被用完,我们也可以认为算法已经非常接近“收敛”而将训练停下。这种机制就是提前停止机制Early Stopping)tol:损失函数下降的阈值,默认值为1e-4,也可调整为其他浮点数来观察提前停止的情况。
提前停止条件被触发后,梯度提升树会停止训练,即停止建树。因此,当提前停止功能被设置打开时,我们使用属性
n_estimators_调出的结果很可能不足我们设置的n_estimators,属性estimators_中的树数量也可能变得更少 -
弱评估器的训练数据
受到随机森林的启发,梯度提升树在每次建树之前,也允许模型对于数据和特征进行随机有放回抽样,构建与原始数据集相同数据量的自助集。在梯度提升树的原理当中,当每次建树之前进行随机抽样时,这种梯度提升树叫做随机提升树(Stochastic Gradient Boosting)。相比起传统的梯度提升树,随机提升树输出的结果往往方差更低,但偏差略高。如果我们发现GBDT的结果高度不稳定,则可以尝试使用随机提升树。
解释方差低偏差高的原因:
由于是弱评估器,也就是简单模型,特点是偏差高方差低也就是欠拟合;由于随机提升树在每一轮使用的是数据集的一个子集,因此每棵树的构建不会过分依赖于特定的数据特征或噪声,从而降低了模型整体的方差;同时,由于不是每次都使用全部数据,可能会导致一些有用的信息没有被模型完全学习到,这可能会轻微增加模型的偏差。换言之,模型可能不会完全捕捉到数据中的所有模式,从而在预测时产生一定程度的系统误差
-
subsample:每次建树之前,从全数据集中进行有放回随机抽样的比例 -
max_features:每次建树之前,从全特征中随机抽样特征进行分枝的比例 -
random_state:随机数种子,控制整体随机模式在GBDT当中,对数据的随机有放回抽样比例由参数
subsample确定,当该参数被设置为1时,则不进行抽样,直接使用全部数据集进行训练。当该参数被设置为(0,1)之间的数字时,则使用随机提升树,在每轮建树之前对样本进行抽样。对特征的有放回抽样比例由参数max_features确定,随机模式则由参数random_state确定,这两个参数在GBDT当中的使用规则都与随机森林中完全一致。需要注意的是,如果
subsample<1,即存在有放回随机抽样时,当数据量足够大、抽样次数足够多时,大约会有37%的数据被遗漏在“袋外”(out of bag)没有参与训练。在随机森林课程当中,我们详细地证明了37%的由来,并且使用这37%的袋外数据作为验证数据,对随机森林的结果进行验证。在GBDT当中,当有放回随机抽样发生时,自然也存在部分袋外数据没有参与训练。这部分数据在GBDT中被用于对每一个弱评估器的建立结果进行验证。 -
oob_improvement:每次建树之后相对于上一次袋外分数的增减
-
train_score_:每次建树之后相对于上一次验证时袋内分数的增减
每建立一棵树,GBDT就会使用当前树的袋外数据对建立新树后的模型进行验证,以此来对比新建弱评估器后模型整体的水平是否提高,并保留提升或下降的结果。这个过程相当于在GBDT迭代时,不断检验损失函数的值并捕捉其变化的趋势。在GBDT当中,这些袋外分数的变化值被储存在属性
oob_improvement_中,同时,GBDT还会在每棵树的训练数据上保留袋内分数(in-bag)的变化,且储存在属性train_score_当中。也就是说,即便在不做交叉验证的情况下,我们也可以简单地通过属性oob_improvement与属性train_score_来观察GBDT迭代的结果
GBDT的参数空间
对任意集成算法进行超参数优化之前,我们需要明确两个基本事实:
1、不同参数对算法结果的影响力大小
2、确定用于搜索的参数空间对GBDT来说,我们可以大致如下排列各个参数对算法的影响:
影响力 参数 ?????
几乎总是具有巨大影响力n_estimators(整体学习能力)
learning_rate(整体学习速率)
max_features(随机性)????
大部分时候具有影响力init(初始化)
subsamples(随机性)
loss(整体学习能力)??
可能有大影响力
大部分时候影响力不明显max_depth(粗剪枝)
min_samples_split(精剪枝)
min_impurity_decrease(精剪枝)
max_leaf_nodes(精剪枝)
criterion(分枝敏感度)?
当数据量足够大时,几乎无影响random_state
ccp_alpha(结构风险) -
在随机森林中非常关键的
max_depth在GBDT中没有什么地位,取而代之的是Boosting中特有的迭代参数学习率learning_rate。在随机森林中,我们总是在意模型复杂度(max_depth)与模型整体学习能力(n_estimators)的平衡,单一弱评估器的复杂度越大,单一弱评估器对模型的整体贡献就越大,因此需要的树数量就越少。在Boosting算法当中,单一弱评估器对整体算法的贡献由学习率参数learning_rate控制,代替了弱评估器复杂度的地位,因此Boosting算法中我们寻找的是learning_rate与n_estimators的平衡。同时,Boosting算法天生就假设单一弱评估器的能力很弱,参数max_depth的默认值也往往较小(在GBDT中max_depth的默认值是3),因此我们无法靠降低max_depth的值来大规模降低模型复杂度,更难以靠max_depth来控制过拟合,自然max_depth的影响力就变小了。特别地,参数
init对GBDT的影响很大,如果在参数init中填入具体的算法,过拟合可能会变得更加严重如果无法对弱评估器进行剪枝,最好的控制过拟合的方法就是增加随机性/多样性,因此
max_features和subsample就成为Boosting算法中控制过拟合的核心武器.比起Bagging,Boosting更加擅长处理小样本高维度的数据(Boosting更专注于前一个模型的错误,更加重视分类错误的样本,而Bagging是独立构建每一棵树),因为Bagging数据很容易在小样本数据集上过拟合(但在小样本数据集上,由于样本多样性有限【模型可能会学习到数据中的随机噪声,而不是潜在的真实模式,这就是过拟合】)在GBDT当中,
max_depth的调参方向是放大/加深,以探究模型是否需要更高的单一评估器复杂度。相对的在随机森林当中,max_depth的调参方向是缩小/剪枝,用以缓解过拟合GBDT的参数空间几乎不依赖于树的真实结构进行调整,且大部分参数都有固定的范围,因此我们只需要对无界的参数稍稍探索即可
先会考虑所有影响力巨大的参数(5星参数),当算力足够/优化算法运行较快的时候,我们可以考虑将大部分时候具有影响力的参数(4星)也都加入参数空间,如果样本量较小,我们可能不选择
subsample。除此之外,我们还需要部分影响弱评估器复杂度的参数,例如max_depth。如果算力充足,我们还可以加入criterion这样或许会有效的参数
在此例中,具体每个参数的初始范围确定如下:
| 参数 | 范围 |
|---|---|
loss | 回归损失中4种可选损失函数 [“squared_error”,“absolute_error”, “huber”, “quantile”] |
criterion | 全部可选的4种不纯度评估指标 [“friedman_mse”, “squared_error”, “mse”, “mae”] |
init | HyperOpt不支持搜索,手动调参(此列中按照init=rf来初始) |
n_estimators | 经由提前停止确认中间数50,最后范围定为(25,200,25) |
learning_rate | 以1.0为中心向两边延展,最后范围定为(0.05,2.05,0.05) *如果算力有限,也可定为(0.1,2.1,0.1) |
max_features | 所有字符串,外加sqrt与auto中间的值 |
subsample | subsample参数的取值范围为(0,1],因此定范围(0.1,0.8,0.1) *如果算力有限,也可定为(0.5,0.8,0.1) |
max_depth | 以3为中心向两边延展,右侧范围定得更大。最后确认(2,30,2) |
min_impurity_decrease | 只能放大(默认值为0)、不能缩小的参数,先尝试(0,5,1)范围 |
GradientBoostingRegreesor实现-默认参数
# 导入相关库
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingRegressor as GBR
from sklearn.ensemble import GradientBoostingClassifier as GBC
from sklearn.ensemble import AdaBoostRegressor as ABR
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.model_selection import cross_validate, KFold
# 读取train_encode文件
data = pd.read_csv(r"D:\Pythonwork\2021ML\PART 2 Ensembles\datasets\House Price\train_encode.csv",index_col=0)
# 定义特征数据集和标签数据集
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
# 定义所需的5折交叉验证方式:随机数为1412和封装函数RMSE查看
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
def RMSE(result,name):
return abs(result[name].mean())
# 实例化默认参数的GBR模型
gbr = GBR(random_state=1412) #实例化
# 对其进行交叉验证
result_gbdt = cross_validate(gbr,X,y,
cv=cv,
scoring="neg_root_mean_squared_error",#负均方根误差
return_train_score=True,
verbose=True,
n_jobs=-1)
# 查看训练集和测试集上的RMSE
RMSE(result_gbdt,"train_score"), RMSE(result_gbdt,"test_score")
GradientBoostingClassifier实现–默认参数
#分类数据
X_clf = data.iloc[:,:-2]
y_clf = data.iloc[:,-2]
# GBDT分类过程的实现(code)
clf = GBC(random_state=1412) #实例化
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_clf = cross_validate(clf,X_clf,y_clf,cv=cv
,return_train_score=True
,verbose=True
,n_jobs=-1)
# 查看模型在测试集和训练集上的表现
result_clf["train_score"].mean(), result_clf["test_score"].mean()
基于TPE对GBDT进行优化
# 导入基本库和sklearn相关库
import pandas as pd
import numpy as np
import sklearn
import matplotlib as mlp
import matplotlib.pyplot as plt
import time
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.ensemble import GradientBoostingRegressor as GBR
from sklearn.model_selection import cross_validate, KFold
# 导入优化算法相关库
import hyperopt
from hyperopt import hp, fmin, tpe, Trials, partial
from hyperopt.early_stop import no_progress_loss
# 读取数据
data = pd.read_csv(r"train_encode.csv",index_col=0)
# 设置特征数据集和特征数据集
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
| 算法 | RF | AdaBoost | GBDT | RF (TPE) | AdaBoost (TPE) |
|---|---|---|---|---|---|
| 5折验证 运行时间 | 1.29s | 0.28s | 0.49s | 0.22s | 0.27s |
| 最优分数 (RMSE) | 30571.267 | 35345.931 | 28783.954 | 28346.673 | 35169.730 |
rf = RFR(n_estimators=89, max_depth=22, max_features=14,min_impurity_decrease=0
,random_state=1412, verbose=False, n_jobs=-1)
-
定义目标函数、参数空间、优化函数、验证函数
-
目标函数
def hyperopt_objective(params): reg = GBR(n_estimators = int(params["n_estimators"]) ,learning_rate = params["lr"] ,criterion = params["criterion"] ,loss = params["loss"] ,max_depth = int(params["max_depth"]) ,max_features = params["max_features"] ,subsample = params["subsample"] ,min_impurity_decrease = params["min_impurity_decrease"] ,init = rf ,random_state=1412 ,verbose=False) cv = KFold(n_splits=5,shuffle=True,random_state=1412) validation_loss = cross_validate(reg,X,y ,scoring="neg_root_mean_squared_error" ,cv=cv ,verbose=False ,n_jobs=-1 ,error_score='raise' ) return np.mean(abs(validation_loss["test_score"])) -
参数空间
参数 范围 loss回归损失中4种可选损失函数
[“squared_error”,“absolute_error”, “huber”, “quantile”]criterion全部可选的4种不纯度评估指标
[“friedman_mse”, “squared_error”, “mse”, “mae”]initHyperOpt不支持搜索,手动调参 n_estimators经由提前停止确认中间数50,最后范围定为(25,200,25) learning_rate以1.0为中心向两边延展,最后范围定为(0.05,2.05,0.05)
*如果算力有限,也可定为(0.1,2.1,0.1)max_features所有字符串,外加sqrt与auto中间的值 subsamplesubsample参数的取值范围为(0,1],因此定范围(0.1,0.8,0.1)
*如果算力有限,也可定为(0.5,0.8,0.1)max_depth以3为中心向两边延展,右侧范围定得更大。最后确认(2,30,2) min_impurity_decrease只能放大、不能缩小的参数,先尝试(0,5,1)范围 param_grid_simple = {'n_estimators': hp.quniform("n_estimators",25,200,25) ,"lr": hp.quniform("learning_rate",0.05,2.05,0.05) ,"criterion": hp.choice("criterion",["friedman_mse", "squared_error"]) ,"loss":hp.choice("loss",["squared_error","absolute_error", "huber", "quantile"]) ,"max_depth": hp.quniform("max_depth",2,30,2) ,"subsample": hp.quniform("subsample",0.1,0.8,0.1) ,"max_features": hp.choice("max_features",["log2","sqrt",16,32,64]) ,"min_impurity_decrease":hp.quniform("min_impurity_decrease",0,5,1) } -
优化函数
def param_hyperopt(max_evals=100): #保存迭代过程 trials = Trials() #设置提前停止 early_stop_fn = no_progress_loss(100) #定义代理模型 params_best = fmin(hyperopt_objective , space = param_grid_simple , algo = tpe.suggest # TPE具有强随机性 , max_evals = max_evals , verbose=True , trials = trials , early_stop_fn = early_stop_fn ) #打印最优参数,fmin会自动打印最佳分数 print("\n","\n","best params: ", params_best, "\n") return params_best, trials -
验证函数(可选)
def hyperopt_validation(params): reg = GBR(n_estimators = int(params["n_estimators"]) ,learning_rate = params["learning_rate"] ,criterion = params["criterion"] ,loss = params["loss"] ,max_depth = int(params["max_depth"]) ,max_features = params["max_features"] ,subsample = params["subsample"] ,min_impurity_decrease = params["min_impurity_decrease"] ,init = rf ,random_state=1412 #GBR中的random_state只能够控制特征抽样,不能控制样本抽样 ,verbose=False) cv = KFold(n_splits=5,shuffle=True,random_state=1412) validation_loss = cross_validate(reg,X,y ,scoring="neg_root_mean_squared_error" ,cv=cv ,verbose=False ,n_jobs=-1 ) return np.mean(abs(validation_loss["test_score"]))
-
-
训练贝叶斯优化器
# 以最大次数为30训练贝叶斯优化器 params_best, trials = param_hyperopt(30)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- js:锚点滚动到页面对应区域
- CDH 6.3.2集成flink 1.18 zookeeper版本不匹配Flink-yarn启动失败
- 关于Sneaky DogeRAT特洛伊木马病毒网络攻击的动态情报
- JVM的对象内存分配
- docker 部署 sentinel
- 如何使用copilot自动制作PPT——一分钟代替你半天的工作量
- EST-100身份证社保卡签批屏按捺终端PC版web版本http协议接口文档,支持web网页开发对接使用
- 【个人笔记】由浅入深分析 ClickHouse
- 新农村管理系统(JSP+java+springmvc+mysql+MyBatis)
- Solidity-003 BoolContract.sol