机器学习笔记一
一、什么是机器学习
(一)机器学习定义一:
- 计算机通过非显著性编程获得的学习能力。
????????非显著性编程指的是:计算机自己从经验中总结出相关的规律。
????????显著性编程:需要人为把机器人所处的环境调查清楚。
例如:
????????1)让计算机区分菊花与玫瑰花。
????????显著性编程:直接给出菊花与玫瑰花的特点
????????非显著性编程:通过大量图片,计算机总结两种花的特征规律,进行区分
????????2)让机器人冲咖啡
????????显著性编程:我们要判断往哪走,什么时候停,什么时候开始冲咖啡等。
????????非显著性编程:规定机器人可以采用一系列的动作,规定特定环境下机器人采取相应措施产生的收益,某个行为产生了不好的效果(撞到、摔倒等),收益为负;产生好的效果(取到咖啡)收益为正,规定了行为和收益函数后,让计算机自己最大化收益函数。
(二)机器学习定义二:
????????计算机程序可以针对某个任务T和某个性能指标P,从经验E中学习。在任务T上被性能指标P衡量的性能,会随着经验E的增加而提高。机器学习本质就是最优化的过程
例如:
????????任务T——编写计算机程序识别菊花与 玫瑰花
????????经验E——一大堆菊花和玫瑰花的图片,(训练样本)
????????性能指标P——不同算法有不同,这里可以选择识别率
????????随着训练样本逐渐加大,识别率越来越大
????????任务T——编写程序让机器人冲咖啡
????????经验E——机器人多次尝试的行为和这些行为产生的结果
????????性能指标P——在规定时间内成功充好咖啡的次数
????????随着训练样本逐渐加大,成功充好咖啡的次数越来越多
二、机器学习的分类
(一)有监督学习:
????????所有的经验E都是人工采集并输入到计算机
? ? ? ? 传统监督学习:每一个数据都有标签。例如:支持向量机,人工神经网络,深度神经网络
? ? ? ? 非监督学习:同一类型数据在样本空间中距离更近。例如:聚类,EM算法,主成分分析
????????半监督学习:一部分有标签,另一部分没有。
? ? ? ? 分类:标签是离散值,如人脸识别
? ? ? ? 回归:标签是连续值,如设计算法预测房价走势
(二)强化学习:
????????计算机的经验是由计算机与环境互动产生的,计算机产生行为与行为的结果,我们定义行为的收益函数,对行为进行奖励或惩罚,同时要设计算法让计算机自动改变自己的模式去最大化收益函数。
三、机器学习的算法过程
以任务区分红细胞、白细胞为例:
1.观察数据(样本),总结规律:
????????根据各样本数据做成相应的曲线图(如下)观察其特征规律,图中可以发现用面积和周长可以区分开红白细胞,而圆形度虽然也有一定规律,但重合点过多,不适合用于作为特征规律。

2.如何基于上述两个特征构建算法
? ? ? ? 支持向量机:线性内核、多项式核、高斯径向分布内核
? ? ? ? 1)确定特征空间,将样本归一化处理,做出平面图(本实例是二维,有可能是多维空间或超多维空间)
? ? ? ? 2)利用上面不同的算法计算相应的分界线
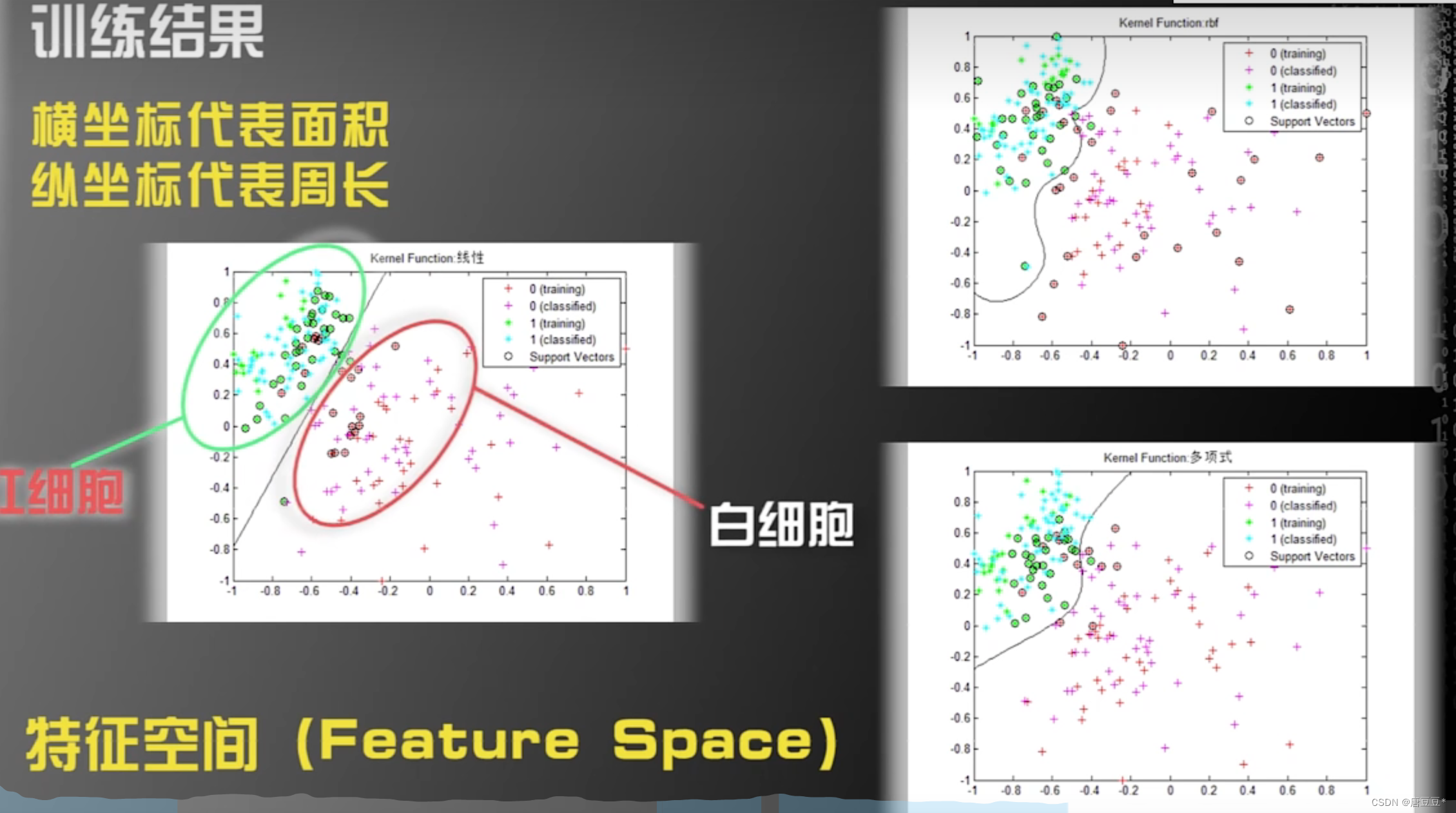
3.哪一种算法更好
由于无法穷尽所有新样本,不能得出绝对意义的好或者不好的机器学习算法。
但可以留一部分样本作为测试集,用于检验算法的优劣。
四、没有免费的午餐定理
任何一个预测函数,如果在一些训练样本上表现好,那么必然在另一些训练样本上表现不好,如果不对数据在特征空间的先验分布有一定的假设,那么表现好与表现不好的情况一样多。


假设:在特征空间上距离接近的样本,他们属于同一个类别的概率更高,所以一般机器会做出上述预判。当然,上述预判也有可能出错。
机器学习的本质是通过有限已知的数据,预测复杂高维空间的未知样本。因此再好的算法也有可能出错,没有永远最好的算法!
五、机器学习可以用来做什么
1.人脸识别? 2.人脸性别、年龄估计? 3.五子棋对战? 4.水果识别? 5.人脸特征点检测? 6.语种识别? 7.视频行为识别
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 区块链基础概念
- 触想智能工业一体机在金属3D打印机上的应用
- NLP论文阅读记录 - 2021 | WOS 基于多头自注意力机制和指针网络的文本摘要
- 生意参谋指数转换异常,有什么可替代的天猫数据查询工具?
- 5.docker容器及相关命令
- 面向移动设备的深度学习—基于TensorFlow Lite,ML Kit和Flutter
- 如何使用 Web Worker 处理大文件上传
- 亚马逊、速卖通等跨境平台如何利用自养号测评提升销量
- 【开源】基于JAVA+Vue+SpringBoot的海南旅游景点推荐系统
- 查看单元测试用例覆盖率新姿势:IDEA 集成 JaCoCo