GCC 内联汇编
前面写了三篇,是自我摸索三篇,摸着石头过河,有些或许是错误的细节,不必在意!? 今天我们直接用GCC编译C语言代码,且在C语言里面内嵌AT&T风格的汇编!?前三篇大家了解即可,我们重点放在内嵌汇编里,简单快捷舒服!
GCC支持在C/C++代码中嵌入汇编代码,这些汇编代码被称作GCC Inline ASM——GCC内联汇编。
这是一个非常有用的功能,有利于我们将一些C/C++语法无法表达的指令直接潜入C/C++代码中,另外也允许我们直接写C/C++代码中使用汇编编写简洁高效的代码。其实为了装逼和护城河!
gcc 编译器支持?2 种形式的内联 asm 代码:
基本 asm 格式:不支持操作数;
扩展 asm 格式:支持操作数;
1. 语法规则
asm [volatile] ("汇编指令")
所有指令,必须用双引号包裹起来;
超过一条指令,必须用\n分隔符进行分割,为了排版,一般会加上\t;
多条汇编指令,可以写在一行,也可以写在多行;
关键字 asm 可以使用?asm?来替换;
volatile 是可选的,编译器有可能对汇编代码进行优化,使用 volatile 关键字之后,告诉编译器不要优化手写的内联汇编代码。
基本内联汇编的格式是
__asm__ __volatile__("Instruction List");可选风格?有比较多种,不过测试了下 就下面代码的风格支持得好,
每行汇编命令 要加冒号和\N\T 确实麻烦. 不过可以使用软件前后追加特定符号就行了.
下面是基本格式 不支持操作数,它必须使用全局变量,这限制太麻烦了
#include?<stdio.h>
int?a?=?1;
int?b?=?2;
int?c;
int?main()
{
????asm?volatile?(
????????"movl?a,?%eax\n\t"
????????"addl?b,?%eax\n\t"
????????"movl?%eax,?c"
????????);
????printf("c?=?%d?\n",?c);
????return?0;
}
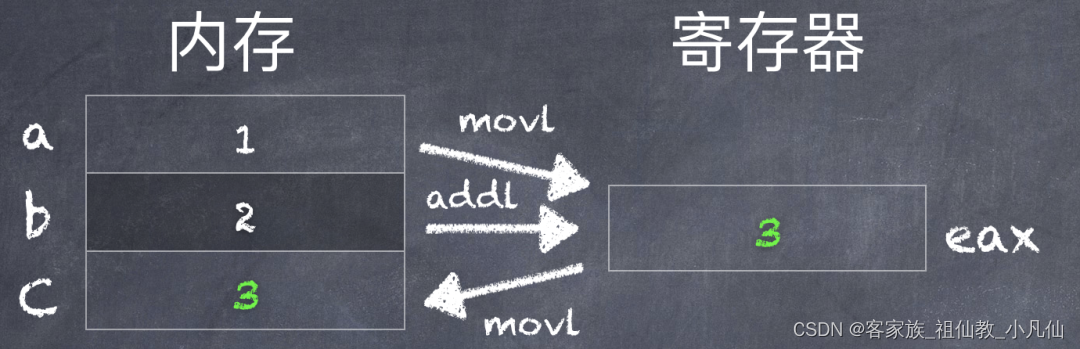
其实汇编内嵌 相当于调用个C函数而已,不过这C函数是汇编函数而已
#include?<stdio.h>
int?main()
{
????int?data1?=?1;
????int?data2?=?2;
????int?data3;
????asm?volatile
????(
????????"movl?%%ebx,?%%eax\n\t"
????????"addl?%%ecx,?%%eax"
????????:?"=a"(data3)?:?"b"(data1),"c"(data2)
);
/*asm?[volatile]?("汇编指令\n\t"?:?"输出操作数列表"?:?"输入操作数列表"?:?"改动的寄存器")*/
????printf("data3?=?%d?\n",?data3);
????return?0;
}
这里必须使用扩展ASM格式,才能不使用全局变量当作参数传入汇编函数里
所以汇编命令?寄存器要多个%号?"movl %%ebx,%%eax" 把EBX的值覆盖进EAX里.
所有汇编命令结束后?最后个小挂号前 开始定义我们的函数参数
第一个冒开始是 输出参数? ?:"=a"(data3)
第二个冒号开始是 输入参数 有多个参数用逗号分隔
第三个冒号是不要优化寄存器列表
其中??:"=a"(data3) 的 data3 是C的变量 用小挂号保护起来, 前面的=A
叫做"修饰符"?
对输出寄存器或内存地址提供额外的说明,包括下面4个修饰符:
+:被修饰的操作数可以读取,可以写入;
=:被修饰的操作数只能写入;
%:被修饰的操作数可以和下一个操作数互换;
&:在内联函数完成之前,可以删除或者重新使用被修饰的操作数;
其中A?使用寄存器的别名?"=a" 表示只能写A的寄出器(EAX)
?通俗讲下面的叫约束
a: 使用 eax/ax/al 寄存器;
b: 使用?ebx/bx/bl 寄存器;
c: 使用 ecx/cx/cl 寄存器;
d: 使用 edx/dx/dl 寄存器;
r: 使用任何可用的通用寄存器;
m: 使用变量的内存位置;
b(data1)表示?data1变量的值复制到B寄出器里
在内联汇编代码中,没有声明“改动的寄存器”列表,也就是说可以省略掉(前面的冒号也不需要);
使用占位符来代替寄存器名称
如果操作数有很多,那么在内联汇编代码中去写每个寄存器的名称,就显得很不方便。占位符有点类似于批处理脚本中,利用?2...来引用输入参数一样,内联汇编代码中的占位符,从输出操作数列表中的寄存器开始从?0?编号,一直编号到输入操作数列表中的所有寄存器。
?
#include?<stdio.h>
int?main()
{
????int?data1?=?1;
????int?data2?=?2;
????int?data3;
????asm(????????"movl?%1,?%%eax\n\t"
????????"addl?%2,?%0"
?????????:?"=r"(data3)?:?"r"(data1),"r"(data2) );
????printf("data3?=?%d?\n",?data3);
????return?0;
}
%0 是输入参数??依次是 两个输入参数?%1 %2
内联汇编的C语言?正常编译就好了
[root@dsmart=>LINUX_ASM]$gcc?main_add.c?-o?main.add.exe
[root@dsmart=>LINUX_ASM]$./main.add.exe?
data3?=?3?
我们可以查看下GCC 汇编的代码
[root@dsmart=>LINUX_ASM]$gcc?-S?main_add.c?-o?main_add.asm[root@dsmart=>LINUX_ASM]$vim?main_add.asm
下面是我们GCC把MAIN_ADD.C全部翻译成了汇编代码,而我们重点的内嵌汇编用蓝色注解#APP----#NOAPP 范围内
????????.file???"main_add.c"
????????.section????????.rodata
.LC0:
????????.string?"data3?=?%d?\n"
????????.text
????????.globl??main
????????.type???main,?@function
main:
.LFB0:
????????.cfi_startproc
????????pushq???%rbp
????????.cfi_def_cfa_offset?16
????????.cfi_offset?6,?-16
????????movq????%rsp,?%rbp
????????.cfi_def_cfa_register?6
????????subq????$16,?%rsp
????????movl????$1,?-4(%rbp)
????????movl????$2,?-8(%rbp)
????????movl????-4(%rbp),?%eax
????????movl????-8(%rbp),?%edx
#APP
#?9?"main_add.c"?1
????????movl?%eax,?%eax
????????addl?%edx,?%eax
#?0?""?2
#NO_APP
????????movl????%eax,?-12(%rbp)
????????movl????-12(%rbp),?%eax
????????movl????%eax,?%esi
????????movl????$.LC0,?%edi
????????movl????$0,?%eax
????????call????printf
????????movl????$0,?%eax
????????leave
????????.cfi_def_cfa?7,?8
????????ret
????????.cfi_endproc
.LFE0:
????????.size???main,?.-main
????????.ident??"GCC:?(GNU)?5.5.0"??? .section? ? ? ? .note.GNU-stack,"",@progbits里面这段代码不是%1了,被具体替换成了寄出器名.
这段是C语言调用汇编函数进行参数压栈操作,分别把参数1,2压入栈底
movl $1, -4(%rbp)movl $2, -8(%rbp)movl -4(%rbp), %eaxmovl -8(%rbp), %edx
rsp : 栈指针寄存器,指向栈顶
rbp : 栈基址寄存器,指向栈底
返回参数:
movl %eax, -12(%rbp)movl -12(%rbp), %eax
把结果 压入栈底 -12位置,然后出栈 把RBP栈的值 返回给EAX
好像这有点多余
下面准备调用PRINTF函数edi : 函数参数
rsi/esi : 函数参数
下面我们进行O3优化下看
[root@dsmart=>LINUX_ASM]$gcc main_add.c -S -O3 -o main_add.asm代码确实少了些
.file "main_add.c".section .rodata.str1.1,"aMS",@progbits,1.LC0:.string "data3 = %d \n".section .text.unlikely,"ax",@progbits.LCOLDB1:.section .text.startup,"ax",@progbits.LHOTB1:.p2align 4,,15.globl main.type main, @functionmain:.LFB11:.cfi_startprocsubq $8, %rsp.cfi_def_cfa_offset 16movl $2, %esimovl $1, %eax#APP# 9 "main_add.c" 1movl %eax, %eaxaddl %esi, %esi# 0 "" 2#NO_APPmovl $.LC0, %edixorl %eax, %eaxcall printfxorl %eax, %eaxaddq $8, %rsp.cfi_def_cfa_offset 8ret.cfi_endproc.LFE11:.size main, .-main.section .text.unlikely.LCOLDE1:.section .text.startup.LHOTE1:.ident "GCC: (GNU) 5.5.0"????????.section????????.note.GNU-stack,"",@progbits
????????
结果优化的不像人样了,volatile?也无法禁止优化内嵌汇编!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!