Mysql高可用|索引|事务 | 调优
前言



文章目录
sql语句的执行顺序
我们在拿到sql片段的时候,我们去处理sql语句,见到众多的关键字时我们该如何去处理呢?
-
FROM:首先识别并检索FROM子句中指定的表或视图。如果有多个表,则进行必要的连接操作。
-
WHERE:接下来,将WHERE子句中指定的条件应用于从表或视图中检索到的行。只有满足条件的行才会被选中。
-
GROUP BY:如果有GROUP BY子句,那么结果集将根据指定的列进行分组。这一步将具有相似值的行组合成汇总行。
-
HAVING:在GROUP BY子句之后,HAVING子句用于过滤分组的行。你可以在HAVING子句中指定条件,以限制哪些组的行包含在结果中。
-
SELECT:然后对结果集应用SELECT子句,指定要检索的列。你可以使用聚合函数(如SUM、COUNT、AVG等)对分组或筛选后的数据进行计算。
-
DISTINCT:如果使用了DISTINCT关键字,将从结果集中删除重复的行。
-
ORDER BY:如果有ORDER BY子句,结果集将按照指定的列以及指定的顺序(升序或降序)进行排序。
-
LIMIT:最后,应用LIMIT子句以限制从查询结果返回的行数。这在只需要结果集的一个子集时非常有用。
关键词
连接
名字解释
- 内连接 :取得两张表中满足存在连接匹配关系的记录
- 外连接:不只取得两张表中满足存在连续匹配关系的记录,还包括某张表(或两张表)中不满足匹配关系的记录
- 交叉连接:笛卡尔积在sql中的实现
- 笛卡尔积:例如集合A={a,b},集合B={1,2,3},那么A? B={<a,o>,<a,1>,<a,2>,<b,0>,<b,1>,<b,2>,}。
sql语句
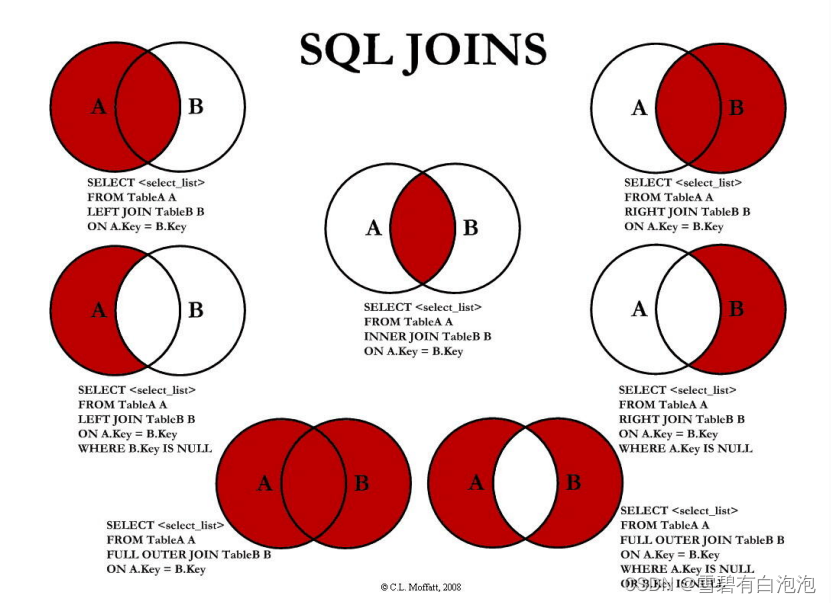
面试坑点
由于篇幅有限,我们以模拟数据库面试的角度去检验一下坑点
面试官:首先我想问一下你在建表过程中是否了解varchar和cahr的区别?
关键词:可变
面试官:若你在存储一些数据较大的类型时,blob和text是如何选择的
关键词:类型,容量,方式,操作
面试官:你知道datetime和timestamp的异同嘛?
关键词:范围,空间,时区,默认值
面试官:在mysql语句中,in和exists的区别是什么
关键词:表大小
面试官:你的项目库中有记录货币的场景嘛,用的是什么类型字段
关键词:精确数值
面试官:mysql怎么存储emoji的呢?
关键词:编码类型
面试官:你有好好了解删除操作嘛,请说出drop,delete与truncate的区别吧
关键词:类型,回滚,删除内容,删除速度
面试官:你了解过合并查询么,请说出UNION与UNION ALL的区别?
关键词:去重与性能
面试官:count(1 ) 、count(*) 、count(列名)的区别?
关键词:执行效果与执行速度
这些问题能答对几个? 是否需要回炉重造呢?
存储引擎
MYSQL存储引擎
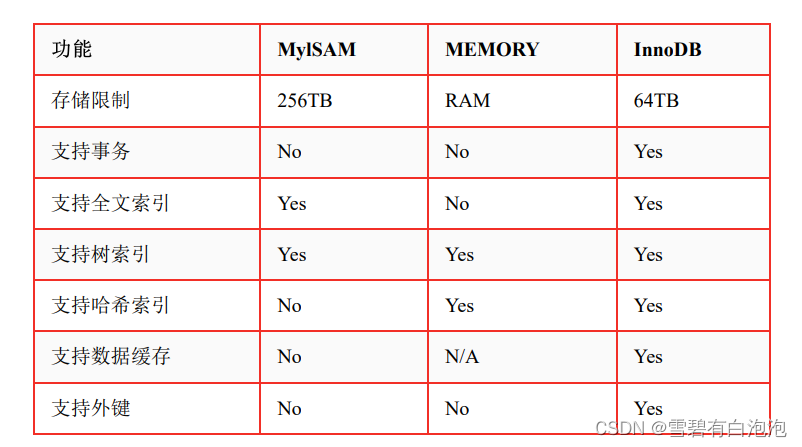
MYSQL8渐渐流行,需要了解一下MyISAM。
SQL优化
sql优化是基于慢sql进行优化,主要有以下特征
- 慢查询日志 :开启MySQL的慢查询日志,再通过一些工具比如mysqldumpslow去分析对应的慢查询日志,当然现在一般的云厂商都提供了可视化的平台。
- 服务监控 :可以在业务的基建中加入对慢SQL的监控,常见的方案有字节码插桩、连接池扩展、ORM框架过程,对服务运行中的慢SQL进行监控和告警。
慢SQL优化主要有以下的方向
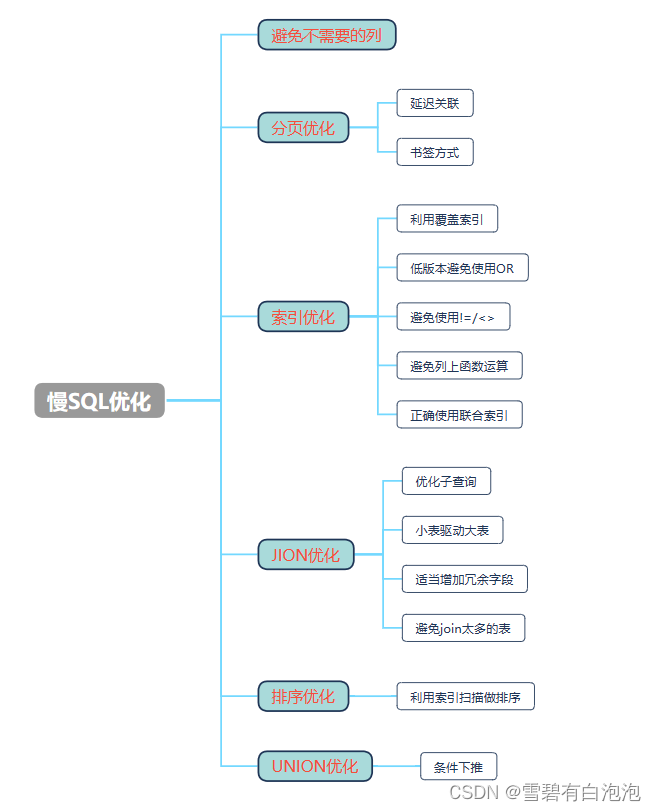
在SQL优化时,explain是优化的利器,我们平时的编写,也应该先explain,看查一下执行计划,看看是否有优化的空间
直接在select语句之前增加explain关键词,就会返回执行计划的信息

索引
这个是特别重要的内容,一定要彻底拿下
索引就像目录,帮助我们更快地查询表中的内容。当我们了解索引,我们要了解索引的物理存储方式,还要了解索引的特性,还要了解索引的方式有哪些,还有索引的对象
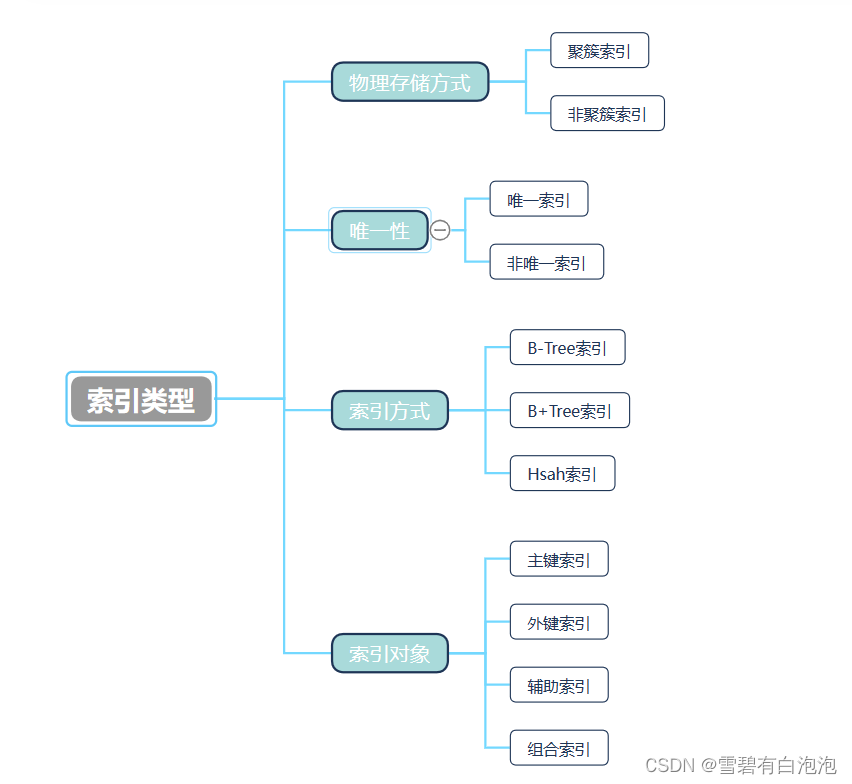
当我们在创建索引的时候我们需要注意索引的位置,和数量。我们应该将索引建在频繁查询的字段上面,不建议的有:
1. 低区分度的字段(性别)
2. 频繁更新的字段
3. 过长的字段(前缀索引):占位置太大
4. 无序值作为索引:主键有不确定性时,容易导致叶子节点频繁分裂,造成磁盘存储的碎片化
索引失效
- OR操作符
- 字段类型不匹配
- 使用了不适合索引的操作符
- 联合索引中未使用索引的列
- 索引列上使用函数或表达式
- 对索引进行运算
- 不等于或NOT IN操作符
- 使用IS NULL 或 IS NOT NULL操作符
- 关联字段编码格式不一致
- 优化器估计全表扫描更快
索引的数据结构
MySQL的默认存储引擎是InnDB,它使用B+树结构实现索引。B+树索引的结构简洁明了,具有以下特点:
+ 每个节点可以存储多个键值对,叶子节点可以存储实际的数据记录
+ 非叶子节点用于指引搜索方向,只存储了键值
+ 叶子节点之间使用双向指针连接,形成有序链表,方便范围查询和排序操作
+ B+树高度相对较低,可以减少磁盘的 I/O 操作
我们小结一下可以说B+树是一个树高相对较低,节点存储键值指引存储数据的叶子节点,而叶子节点之间为了方便查询排序操作用双指针形成了有序链表
我们了解完索引的一些基本内容我们继续以面试题的角度去思考这些知识点
面试坑点
- 索引不适合哪些场景
- 你了解聚簇索引和非聚簇索引么
- 你了解覆盖索引么
- 索引是不是建的越多越好
- 你了解了MYSQL的数据结构是B+树,那么一棵B+树能存储多少条数据呢?
- 那为什么要用B+树,而不用二叉树和平衡二叉树
- 那Hash和B+索引的区别是什么呢
- 回表了解嘛
- 说说最左前缀原则/最左匹配原则
- 说说mysql5.6版本添加的索引下推优化
锁
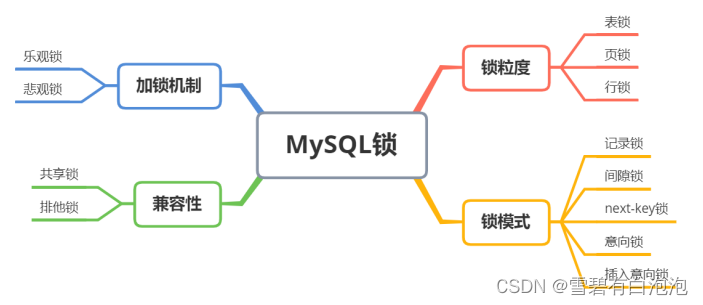
当谈到MySQL锁时,重要的内容包括锁粒度、锁模式、加锁机制和兼容性。
锁粒度是指锁定数据库对象的级别,包括行锁、页锁和表锁。行锁是最细粒度的锁,它锁定了表中的单个行,其他事务无法修改或访问该行。页锁是在页的级别上进行锁定,可以锁定一组相邻的行。表锁是最粗粒度的锁,它锁定整个表,其他事务无法修改或访问表中的任何行。
锁模式是锁定的方式,常见的锁模式包括记录锁、间隙锁、next-key锁、意向锁和插入意向锁。记录锁用于锁定行,间隙锁用于锁定区间,next-key锁是记录锁和间隙锁的组合,用于避免幻读问题。意向锁用于标识一个事务即将在某个粒度上加锁,插入意向锁用于表示事务即将在某个范围内插入新行。
加锁机制包括乐观锁和悲观锁。乐观锁假设并发操作不会产生冲突,只在提交时检查是否有其他事务修改了数据。悲观锁则假设并发操作可能会产生冲突,在整个操作过程中都持有锁,避免冲突的发生。
最后,兼容性指的是共享锁和排他锁之间的兼容性。共享锁允许多个事务同时读取但不允许修改数据,而排他锁在持有锁的事务完成之前不允许其他事务读取或修改数据。兼容性确保了事务之间的并发性和数据的一致性。
灵魂问题:mysql遇到过死锁嘛,你是如何解决的??
事务
四大特性
MySQL事务的四大特性,也被称为ACID特性,指的是原子性(Atomicity)、一致性
(Consistency)、隔离性(Isolation)和持久性(Durability)。
事务的隔离级别
事务的隔离级别决定了并发事务之间的可见性和影响范围,包括读取未提交数据(ReadUncommitted)、读取已提交数据(Read Committed)、可重复读(RepeatableRead)和串行化(Serializable)。
MySQL的默认隔离级别是可重复读(Repeatable Read),核心内容是保证在事务期间读取的数据不会受到其他并发事务的修改影响。然而,可重复读隔离级别仍可能导致幻读(Phantom Read)、脏读(Dirty Read)和不可重复读(Non-repeatable Read)的问题,其中幻读指的是一个事务在读取某个范围内的数据时,另一个事务在该范围内插入了新的数据,导致第一个事务的结果集发生变化;脏读指的是一个事务读取了另一个未提交事务的数据;不可重复读指的是在同一个事务中,多次读取同一条数据的结果不一致。
MVCC
MVCC是一种并发控制技术,通过为每个事务创建多个版本的数据来实现隔离性和并发性。
读写分离
数据库的读写分离是一种架构设计,旨在优化数据库性能并提高系统的可扩展性。它将数据库操作分为读操作和写操作,然后将这些操作分配给不同的数据库实例来处理。
实现读写分离的过程通常涉及以下几个步骤:
-
配置主数据库(写库):为系统配置一个主数据库实例,负责处理所有写操作(如插入、更新、删除)。
-
配置从数据库(读库):配置一个或多个从数据库实例,用于处理读操作(如查询)。
-
同步主数据库和从数据库:确保从数据库与主数据库的数据保持同步。这可以通过数据库复制技术来实现,主数据库将写操作的日志传输给从数据库,并在从数据库上重放这些日志来保持数据一致性。
-
路由读操作到从数据库:在应用程序中使用合适的策略将读操作路由到从数据库。这可以通过使用负载均衡器或在应用程序代码中进行手动配置来完成。
-
处理写操作到主数据库:所有写操作都发送到主数据库进行处理。
我们了解完一些基本内容我们继续以面试题的角度去思考这些知识点
面试坑点
- 主从复制原理你了解多少
- 主从同步延迟你了解么,该如何处理
- 你一般是如何分库的
- 那你一般是怎么分表的
- 水平分表有哪几种路由方式
- 不停机扩容如何实现
- 常用的分库分表中间件有哪些
- 说了这么多分表分库,你觉得这样会带来什么影响呢
- 百万级别以上的数据如何删除
- 百万千万级的大表改如何添加字段
- MySQL数据库cpu飙升怎么办
面对这篇文章的面试问题,你是否需要回炉重造呢?
这本热销并累计十万的评论的书安利给大家,并以活动的形式送出1-3本
京东链接 :https://item.jd.com/13393259.html#crumb-wrap

书籍推荐

- 🎁本次送书1~3本【取决于阅读量,阅读量越多,送的越多】👈
- ??活动时间:截止到2023-12月15号
- ??参与方式:关注博主+三连(点赞、收藏、评论)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 为什么Go不像Java需要Tomcat等服务器就可以直接运行?
- 【消息中间件】Rabbitmq消息可靠性、持久化机制、各种消费
- 2023.12.14,搜索遍历,走迷宫,青蛙跳
- SwinTransformer
- 「用户与社区的深度对话」2023年度IvorySQL满意度调研
- Cocos在VsCode中调试-端口安全问题 net::ERR_UNSAFE_PORT
- N-139基于springboot,vue宠物领养系统
- #Uniapp:引入fonts&目录结构&全局样式&启动模式&全局变量
- 【软件质量】代码质量综合指南:最佳实践和工具
- 部署本地GPT