Redis学习笔记(二)
1. 说一说Redis集群的应用和优劣势
参考答案
优势:
Redis Cluster是Redis的分布式解决方案,在3.0版本正式推出,有效地解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡的目的。
劣势:
Redis集群方案在扩展了Redis处理能力的同时,也带来了一些使用上的限制:
-
key批量操作支持有限。如mset、mget,目前只支持具有相同slot值的key执行批量操作。对于映射为不同slot值的key由于执行mset、mget等操作可能存在于多个节点上所以不被支持。
-
key事务操作支持有限。同理只支持多key在同一节点上的事务操作,当多个key分布在不同的节点上时无法使用事务功能。
-
key作为数据分区的最小粒度,因此不能将一个大的键值对象(如hash、list等)映射到不同的节点。
-
不支持多数据库空间。单机下的Redis可以支持16个数据库,集群模式下只能使用一个数据库空间,即DB0。
-
复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
2.说一说hash类型底层的数据结构
参考答案
哈希对象有两种编码方案,当同时满足以下条件时,哈希对象采用ziplist编码,否则采用hashtable编码:
-
哈希对象保存的键值对数量小于512个;
-
哈希对象保存的所有键值对中的键和值,其字符串长度都小于64字节。
其中,ziplist编码采用压缩列表作为底层实现,而hashtable编码采用字典作为底层实现。
压缩列表:
压缩列表(ziplist),是Redis为了节约内存而设计的一种线性数据结构,它是由一系列具有特殊编码的连续内存块构成的。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或一个整数值。
压缩列表的结构如下图所示:

该结构当中的字段含义如下表所示:
| 属性 | 类型 | 长度 | 说明 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 压缩列表占用的内存字节数; |
| zltail | uint32_t | 4字节 | 压缩列表表尾节点距离列表起始地址的偏移量(单位字节); |
| zllen | uint16_t | 2字节 | 压缩列表包含的节点数量,等于UINT16_MAX时,需遍历列表计算真实数量; |
| entryX | 列表节点 | 不固定 | 压缩列表包含的节点,节点的长度由节点所保存的内容决定; |
| zlend | uint8_t | 1字节 | 压缩列表的结尾标识,是一个固定值0xFF; |
其中,压缩列表的节点由以下字段构成:

previous_entry_length(pel)属性以字节为单位,记录当前节点的前一节点的长度,其自身占据1字节或5字节:
-
如果前一节点的长度小于254字节,则“pel”属性的长度为1字节,前一节点的长度就保存在这一个字节内;
-
如果前一节点的长度达到254字节,则“pel”属性的长度为5字节,其中第一个字节被设置为0xFE,之后的四个字节用来保存前一节点的长度;
基于“pel”属性,程序便可以通过指针运算,根据当前节点的起始地址计算出前一节点的起始地址,从而实现从表尾向表头的遍历操作。
content属性负责保存节点的值(字节数组或整数),其类型和长度则由encoding属性决定,它们的关系如下:
| encoding | 长度 | content |
|---|---|---|
| 00 xxxxxx | 1字节 | 最大长度为26 -1的字节数组; |
| 01 xxxxxx bbbbbbbb | 2字节 | 最大长度为214-1的字节数组; |
| 10 __ bbbbbbbb ... ... ... | 5字节 | 最大长度为232-1的字节数组; |
| 11 000000 | 1字节 | int16_t类型的整数; |
| 11 010000 | 1字节 | int32_t类型的整数; |
| 11 100000 | 1字节 | int64_t类型的整数; |
| 11 110000 | 1字节 | 24位有符号整数; |
| 11 111110 | 1字节 | 8位有符号整数; |
| 11 11xxxx | 1字节 | 没有content属性,xxxx直接存[0,12]范围的整数值; |
字典:
字典(dict)又称为散列表,是一种用来存储键值对的数据结构。C语言没有内置这种数据结构,所以Redis构建了自己的字典实现。
Redis字典的实现主要涉及三个结构体:字典、哈希表、哈希表节点。其中,每个哈希表节点保存一个键值对,每个哈希表由多个哈希表节点构成,而字典则是对哈希表的进一步封装。这三个结构体的关系如下图所示:
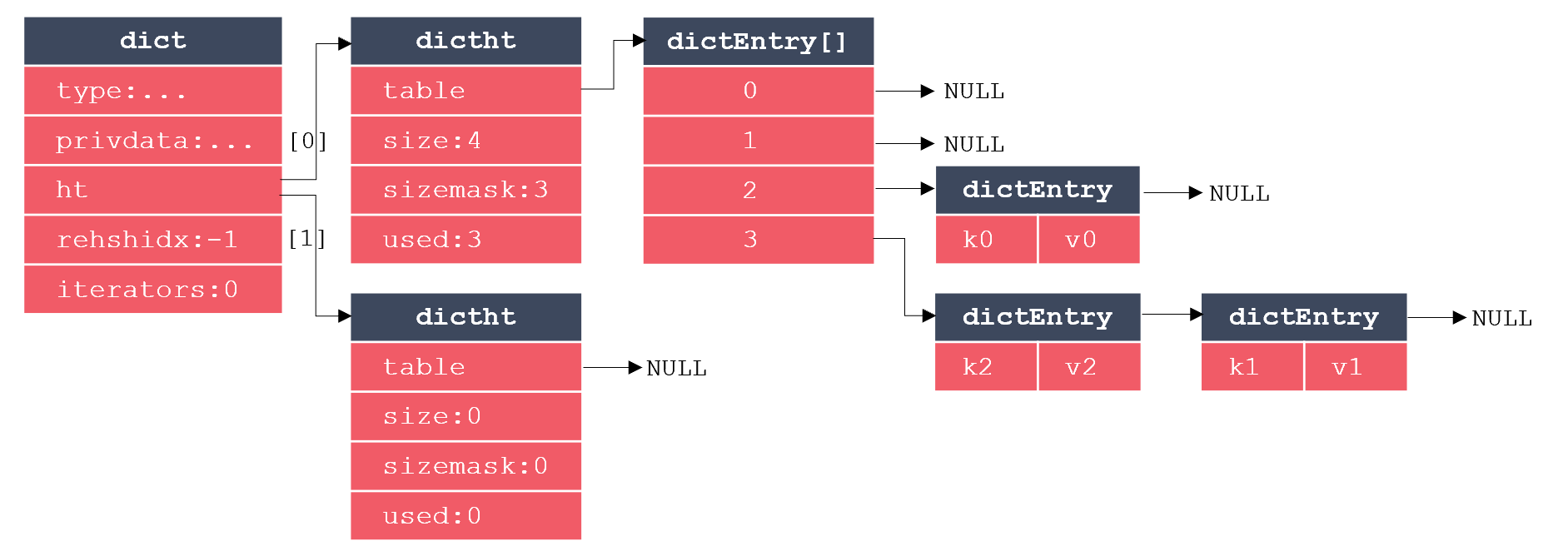
其中,dict代表字典,dictht代表哈希表,dictEntry代表哈希表节点。可以看出,dictEntry是一个数组,这很好理解,因为一个哈希表里要包含多个哈希表节点。而dict里包含2个dictht,多出的哈希表用于REHASH。当哈希表保存的键值对数量过多或过少时,需要对哈希表的大小进行扩展或收缩操作,在Redis中,扩展和收缩哈希表是通过REHASH实现的,执行REHASH的大致步骤如下:
-
为字典的ht[1]哈希表分配内存空间
如果执行的是扩展操作,则ht[1]的大小为第1个大于等于ht[0].used*2的2n。如果执行的是收缩操作,则ht[1]的大小为第1个大于等于ht[0].used的2n。
-
将存储在ht[0]中的数据迁移到ht[1]上
重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
-
将字典的ht[1]哈希表晋升为默认哈希表
迁移完成后,清空ht[0],再交换ht[0]和ht[1]的值,为下一次REHASH做准备。
当满足以下任何一个条件时,程序会自动开始对哈希表执行扩展操作:
-
服务器目前没有执行bgsave或bgrewriteof命令,并且哈希表的负载因子大于等于1;
-
服务器目前正在执行bgsave或bgrewriteof命令,并且哈希表的负载因子大于等于5。
为了避免REHASH对服务器性能造成影响,REHASH操作不是一次性地完成的,而是分多次、渐进式地完成的。渐进式REHASH的详细过程如下:
-
为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表;
-
在字典中的索引计数器rehashidx设置为0,表示REHASH操作正式开始;
-
在REHASH期间,每次对字典执行添加、删除、修改、查找操作时,程序除了执行指定的操作外,还会顺带将ht[0]中位于rehashidx上的所有键值对迁移到ht[1]中,再将rehashidx的值加1;
-
随着字典不断被访问,最终在某个时刻,ht[0]上的所有键值对都被迁移到ht[1]上,此时程序将rehashidx属性值设置为-1,标识REHASH操作完成。
REHSH期间,字典同时持有两个哈希表,此时的访问将按照如下原则处理:
-
新添加的键值对,一律被保存到ht[1]中;
-
删除、修改、查找等其他操作,会在两个哈希表上进行,即程序先尝试去ht[0]中访问要操作的数据,若不存在则到ht[1]中访问,再对访问到的数据做相应的处理。
3.介绍一下zset类型底层的数据结构
参考答案
有序集合对象有2种编码方案,当同时满足以下条件时,集合对象采用ziplist编码,否则采用skiplist编码:
-
有序集合保存的元素数量不超过128个;
-
有序集合保存的所有元素的成员长度都小于64字节。
其中,ziplist编码的有序集合采用压缩列表作为底层实现,skiplist编码的有序集合采用zset结构作为底层实现。
其中,zset是一个复合结构,它的内部采用字典和跳跃表来实现,其源码如下。其中,dict保存了从成员到分支的映射关系,zsl则按分值由小到大保存了所有的集合元素。这样,当按照成员来访问有序集合时可以直接从dict中取值,当按照分值的范围访问有序集合时可以直接从zsl中取值,采用了空间换时间的策略以提高访问效率。
typedef struct zset { ? ?dict *dict; // 字典,保存了从成员到分值的映射关系; ? ?zskiplist *zsl; // 跳跃表,按分值由小到大保存所有集合元素; } zset;
综上,zset对象的底层数据结构包括:压缩列表、字典、跳跃表。
压缩列表:
压缩列表(ziplist),是Redis为了节约内存而设计的一种线性数据结构,它是由一系列具有特殊编码的连续内存块构成的。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或一个整数值。
压缩列表的结构如下图所示:

该结构当中的字段含义如下表所示:
| 属性 | 类型 | 长度 | 说明 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 压缩列表占用的内存字节数; |
| zltail | uint32_t | 4字节 | 压缩列表表尾节点距离列表起始地址的偏移量(单位字节); |
| zllen | uint16_t | 2字节 | 压缩列表包含的节点数量,等于UINT16_MAX时,需遍历列表计算真实数量; |
| entryX | 列表节点 | 不固定 | 压缩列表包含的节点,节点的长度由节点所保存的内容决定; |
| zlend | uint8_t | 1字节 | 压缩列表的结尾标识,是一个固定值0xFF; |
其中,压缩列表的节点由以下字段构成:

previous_entry_length(pel)属性以字节为单位,记录当前节点的前一节点的长度,其自身占据1字节或5字节:
-
如果前一节点的长度小于254字节,则“pel”属性的长度为1字节,前一节点的长度就保存在这一个字节内;
-
如果前一节点的长度达到254字节,则“pel”属性的长度为5字节,其中第一个字节被设置为0xFE,之后的四个字节用来保存前一节点的长度;
基于“pel”属性,程序便可以通过指针运算,根据当前节点的起始地址计算出前一节点的起始地址,从而实现从表尾向表头的遍历操作。
content属性负责保存节点的值(字节数组或整数),其类型和长度则由encoding属性决定,它们的关系如下:
| encoding | 长度 | content |
|---|---|---|
| 00 xxxxxx | 1字节 | 最大长度为26 -1的字节数组; |
| 01 xxxxxx bbbbbbbb | 2字节 | 最大长度为214-1的字节数组; |
| 10 __ bbbbbbbb ... ... ... | 5字节 | 最大长度为232-1的字节数组; |
| 11 000000 | 1字节 | int16_t类型的整数; |
| 11 010000 | 1字节 | int32_t类型的整数; |
| 11 100000 | 1字节 | int64_t类型的整数; |
| 11 110000 | 1字节 | 24位有符号整数; |
| 11 111110 | 1字节 | 8位有符号整数; |
| 11 11xxxx | 1字节 | 没有content属性,xxxx直接存[0,12]范围的整数值; |
字典:
字典(dict)又称为散列表,是一种用来存储键值对的数据结构。C语言没有内置这种数据结构,所以Redis构建了自己的字典实现。
Redis字典的实现主要涉及三个结构体:字典、哈希表、哈希表节点。其中,每个哈希表节点保存一个键值对,每个哈希表由多个哈希表节点构成,而字典则是对哈希表的进一步封装。这三个结构体的关系如下图所示:
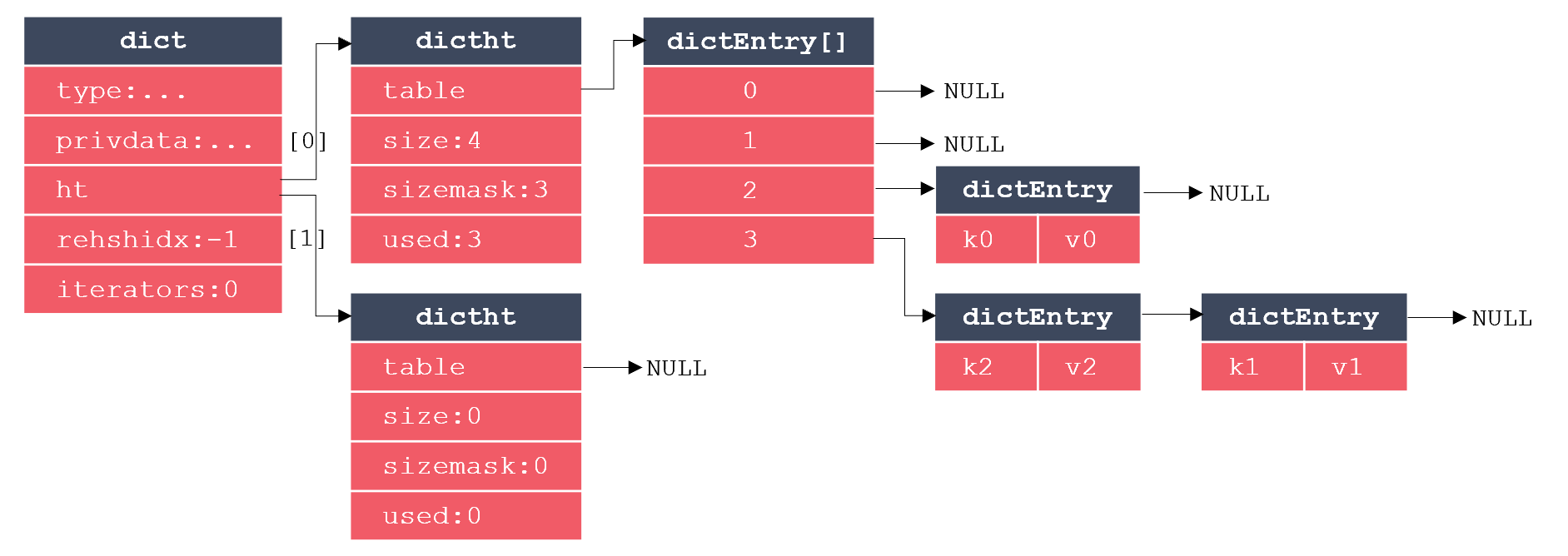
其中,dict代表字典,dictht代表哈希表,dictEntry代表哈希表节点。可以看出,dictEntry是一个数组,这很好理解,因为一个哈希表里要包含多个哈希表节点。而dict里包含2个dictht,多出的哈希表用于REHASH。当哈希表保存的键值对数量过多或过少时,需要对哈希表的大小进行扩展或收缩操作,在Redis中,扩展和收缩哈希表是通过REHASH实现的,执行REHASH的大致步骤如下:
-
为字典的ht[1]哈希表分配内存空间
如果执行的是扩展操作,则ht[1]的大小为第1个大于等于ht[0].used*2的2n。如果执行的是收缩操作,则ht[1]的大小为第1个大于等于ht[0].used的2n。
-
将存储在ht[0]中的数据迁移到ht[1]上
重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
-
将字典的ht[1]哈希表晋升为默认哈希表
迁移完成后,清空ht[0],再交换ht[0]和ht[1]的值,为下一次REHASH做准备。
当满足以下任何一个条件时,程序会自动开始对哈希表执行扩展操作:
-
服务器目前没有执行bgsave或bgrewriteof命令,并且哈希表的负载因子大于等于1;
-
服务器目前正在执行bgsave或bgrewriteof命令,并且哈希表的负载因子大于等于5。
为了避免REHASH对服务器性能造成影响,REHASH操作不是一次性地完成的,而是分多次、渐进式地完成的。渐进式REHASH的详细过程如下:
-
为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表;
-
在字典中的索引计数器rehashidx设置为0,表示REHASH操作正式开始;
-
在REHASH期间,每次对字典执行添加、删除、修改、查找操作时,程序除了执行指定的操作外,还会顺带将ht[0]中位于rehashidx上的所有键值对迁移到ht[1]中,再将rehashidx的值加1;
-
随着字典不断被访问,最终在某个时刻,ht[0]上的所有键值对都被迁移到ht[1]上,此时程序将rehashidx属性值设置为-1,标识REHASH操作完成。
REHSH期间,字典同时持有两个哈希表,此时的访问将按照如下原则处理:
-
新添加的键值对,一律被保存到ht[1]中;
-
删除、修改、查找等其他操作,会在两个哈希表上进行,即程序先尝试去ht[0]中访问要操作的数据,若不存在则到ht[1]中访问,再对访问到的数据做相应的处理。
跳跃表:
跳跃表的查找复杂度为平均O(logN),最坏O(N),效率堪比红黑树,却远比红黑树实现简单。跳跃表是在链表的基础上,通过增加索引来提高查找效率的。
有序链表插入、删除的复杂度为O(1),而查找的复杂度为O(N)。例:若要查找值为60的元素,需要从第1个元素依次向后比较,共需比较6次才行,如下图:

跳跃表是从有序链表中选取部分节点,组成一个新链表,并以此作为原始链表的一级索引。再从一级索引中选取部分节点,组成一个新链表,并以此作为原始链表的二级索引。以此类推,可以有多级索引,如下图:
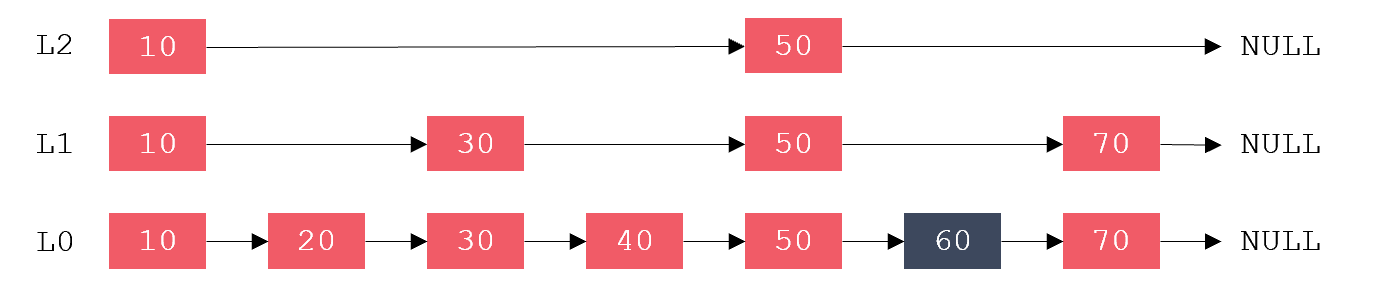
跳跃表在查找时,优先从高层开始查找,若next节点值大于目标值,或next指针指向NULL,则从当前节点下降一层继续向后查找,这样便可以提高查找的效率了。
跳跃表的实现主要涉及2个结构体:zskiplist、zskiplistNode,它们的关系如下图所示:
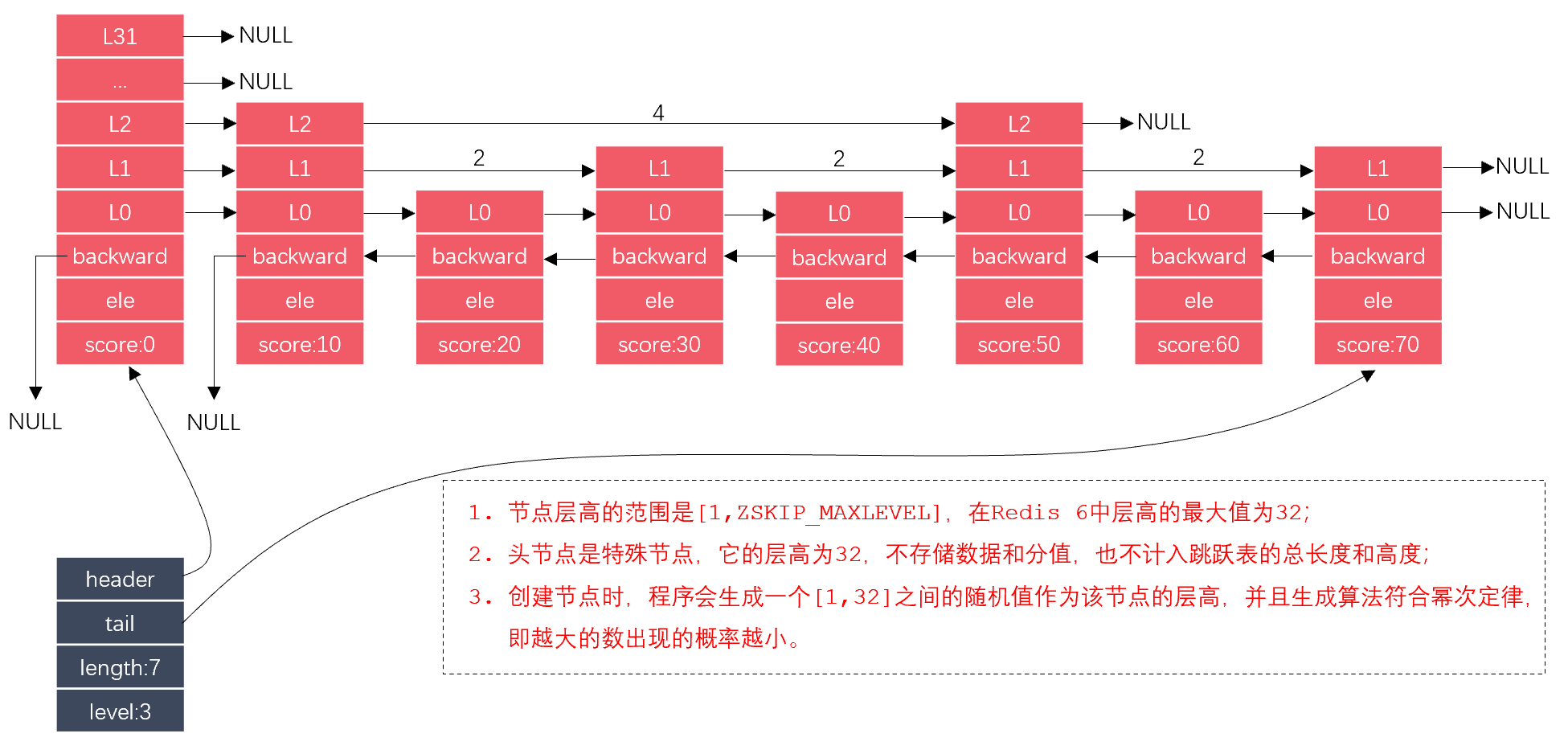
其中,蓝色的表格代表zskiplist,红色的表格代表zskiplistNode。zskiplist有指向头尾节点的指针,以及列表的长度,列表中最高的层级。zskiplistNode的头节点是空的,它不存储任何真实的数据,它拥有最高的层级,但这个层级不记录在zskiplist之内。
4.如何利用Redis实现分布式Session?
参考答案
在web开发中,我们会把用户的登录信息存储在session里。而session是依赖于cookie的,即服务器创建session时会给它分配一个唯一的ID,并且在响应时创建一个cookie用于存储这个SESSIONID。当客户端收到这个cookie之后,就会自动保存这个SESSIONID,并且在下次访问时自动携带这个SESSIONID,届时服务器就可以通过这个SESSIONID得到与之对应的session,从而识别用户的身。如下图:

现在的互联网应用,基本都是采用分布式部署方式,即将应用程序部署在多台服务器上,并通过nginx做统一的请求分发。而服务器与服务器之间是隔离的,它们的session是不共享的,这就存在session同步的问题了,如下图:
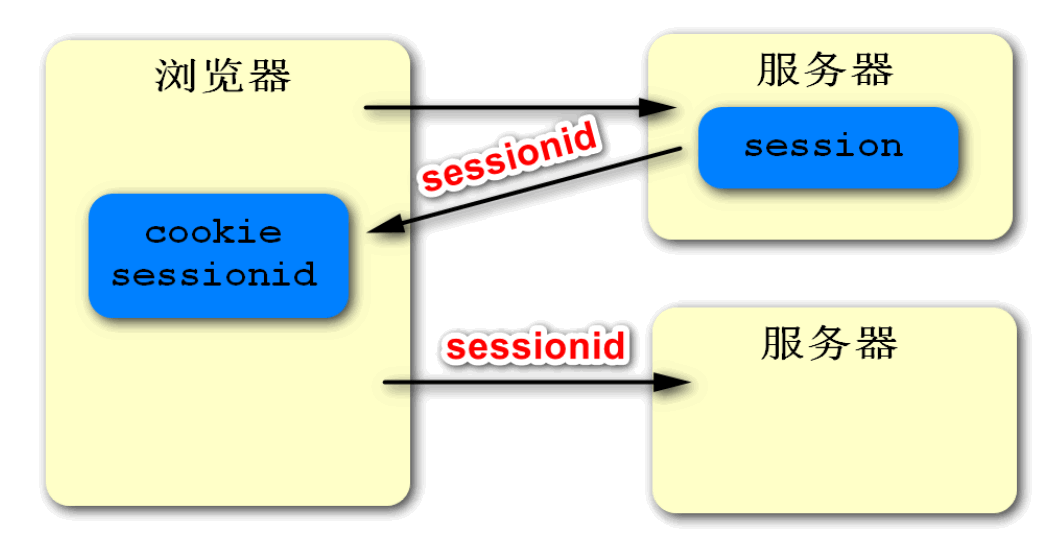
如果客户端第一次访问服务器,请求被分发到了服务器A上,则服务器A会为该客户端创建session。如果客户端再次访问服务器,请求被分发到服务器B上,则由于服务器B中没有这个session,所以用户的身份无法得到验证,从而产生了不一致的问题。
解决这个问题的办法有很多,比如可以协调多个服务器,让他们的session保持同步。也可以在分发请求时做绑定处理,即将某一个IP固定分配给同一个服务器。但这些方式都比较麻烦,而且性能上也有一定的消耗。更合理的方式就是采用类似于Redis这样的高性能缓存服务器,来实现分布式session。
从上面的叙述可知,我们使用session保存用户的身份信息,本质上是要做两件事情。第一是保存用户的身份信息,第二是验证用户的身份信息。如果利用其它手段实现这两个目标,那么就可以不用session,或者说我们使用的是广义上的session了。
具体实现的思路如下图,我们在服务端增加两段程序:
第一是创建令牌的程序,就是在用户初次访问服务器时,给它创建一个唯一的身份标识,并且使用cookie封装这个标识再发送给客户端。那么当客户端下次再访问服务器时,就会自动携带这个身份标识了,这和SESSIONID的道理是一样的,只是改由我们自己来实现了。另外,在返回令牌之前,我们需要将它存储起来,以便于后续的验证。而这个令牌是不能保存在服务器本地的,因为其他服务器无法访问它。因此,我们可以将其存储在服务器之外的一个地方,那么Redis便是一个理想的场所。
第二是验证令牌的程序,就是在用户再次访问服务器时,我们获取到了它之前的身份标识,那么我们就要验证一下这个标识是否存在了。验证的过程很简单,我们从Redis中尝试获取一下就可以知道结果。

5. 如何利用Redis实现一个分布式锁?
参考答案
何时需要分布式锁?
在分布式的环境下,当多个server并发修改同一个资源时,为了避免竞争就需要使用分布式锁。那为什么不能使用Java自带的锁呢?因为Java中的锁是面向多线程设计的,它只局限于当前的JRE环境。而多个server实际上是多进程,是不同的JRE环境,所以Java自带的锁机制在这个场景下是无效的。
如何实现分布式锁?
采用Redis实现分布式锁,就是在Redis里存一份代表锁的数据,通常用字符串即可。实现分布式锁的思路,以及优化的过程如下:
-
加锁:
第一版,这种方式的缺点是容易产生死锁,因为客户端有可能忘记解锁,或者解锁失败。
setnx key value
第二版,给锁增加了过期时间,避免出现死锁。但这两个命令不是原子的,第二步可能会失败,依然无法避免死锁问题。
setnx key value expire key seconds
第三版,通过“set...nx...”命令,将加锁、过期命令编排到一起,它们是原子操作了,可以避免死锁。
set key value nx ex seconds
-
解锁:
解锁就是删除代表锁的那份数据。
del key
-
问题:
看起来已经很完美了,但实际上还有隐患,如下图。进程A在任务没有执行完毕时,锁已经到期被释放了。等进程A的任务执行结束后,它依然会尝试释放锁,因为它的代码逻辑就是任务结束后释放锁。但是,它的锁早已自动释放过了,它此时释放的可能是其他线程的锁。

想要解决这个问题,我们需要解决两件事情:
-
在加锁时就要给锁设置一个标识,进程要记住这个标识。当进程解锁的时候,要进行判断,是自己持有的锁才能释放,否则不能释放。可以为key赋一个随机值,来充当进程的标识。
-
解锁时要先判断、再释放,这两步需要保证原子性,否则第二步失败的话,就会出现死锁。而获取和删除命令不是原子的,这就需要采用Lua脚本,通过Lua脚本将两个命令编排在一起,而整个Lua脚本的执行是原子的。
按照以上思路,优化后的命令如下:
# 加锁 set key random-value nx ex seconds # 解锁 if redis.call("get",KEYS[1]) == ARGV[1] then ? return redis.call("del",KEYS[1]) else ? return 0 end
基于RedLock算法的分布式锁:
上述分布式锁的实现方案,是建立在单个主节点之上的。它的潜在问题如下图所示,如果进程A在主节点上加锁成功,然后这个主节点宕机了,则从节点将会晋升为主节点。若此时进程B在新的主节点上加锁成果,之后原主节点重启,成为了从节点,系统中将同时出现两把锁,这是违背锁的唯一性原则的。
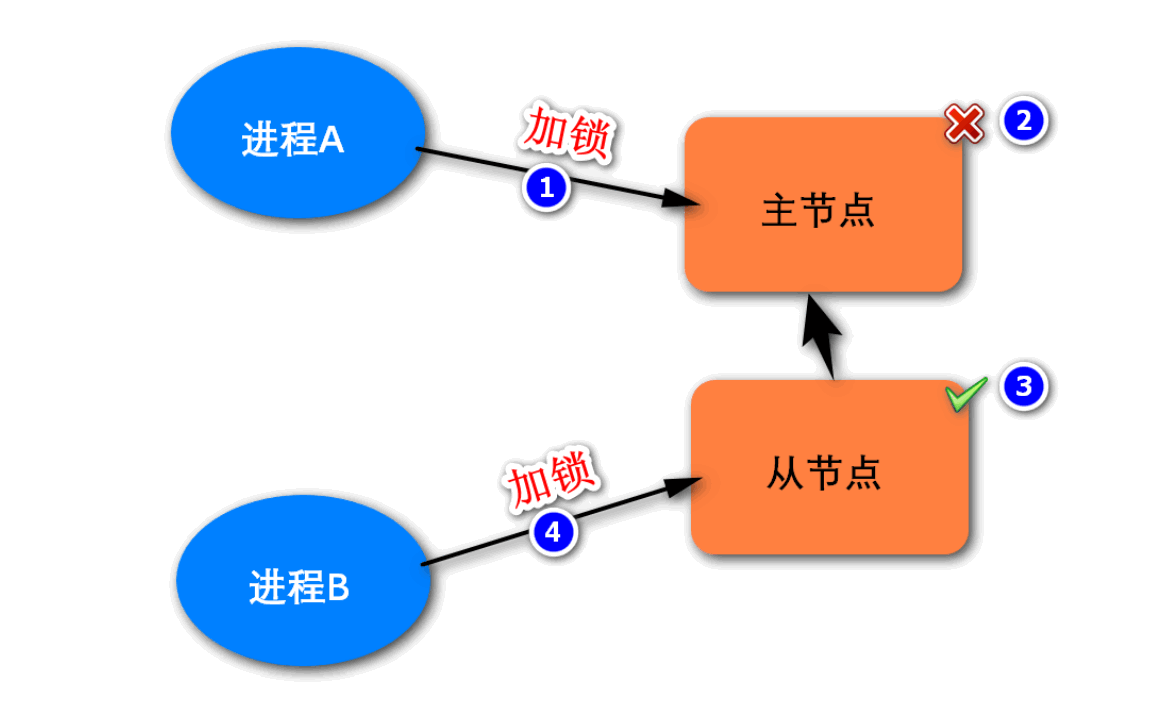
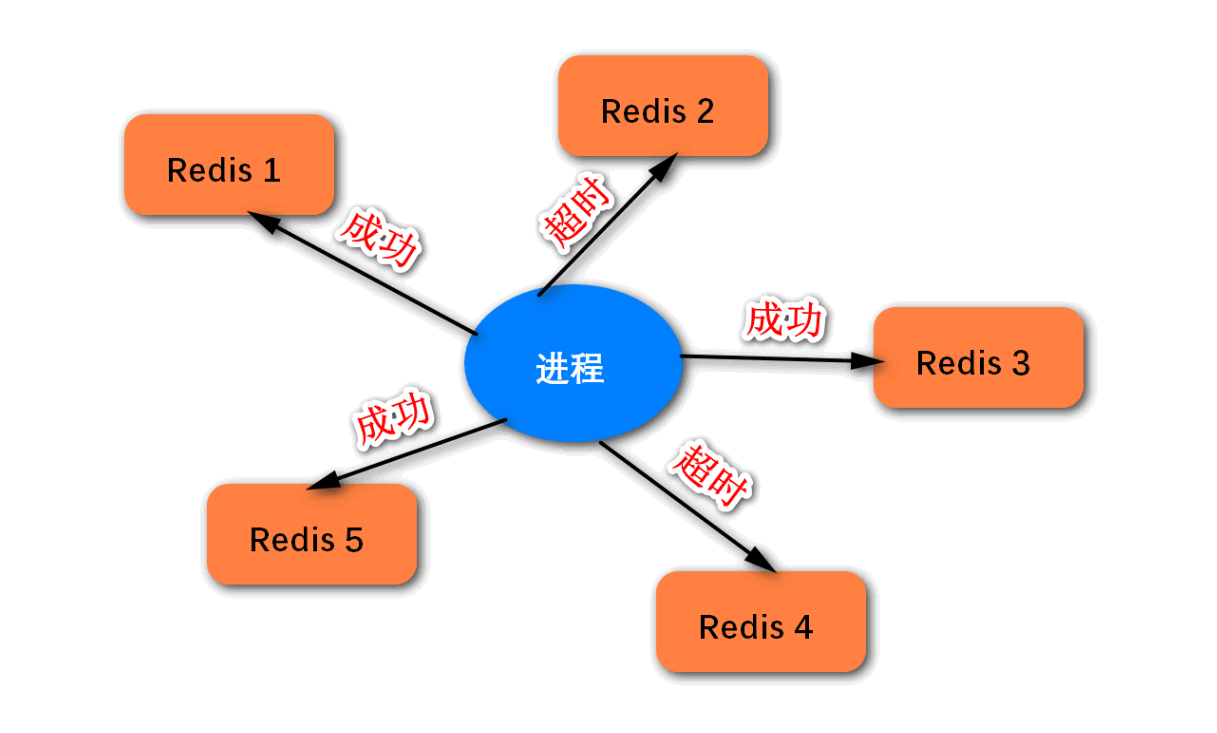
总之,就是在单个主节点的架构上实现分布式锁,是无法保证高可用的。若要保证分布式锁的高可用,则可以采用多个节点的实现方案。这种方案有很多,而Redis的官方给出的建议是采用RedLock算法的实现方案。该算法基于多个Redis节点,它的基本逻辑如下:
-
这些节点相互独立,不存在主从复制或者集群协调机制;
-
加锁:以相同的KEY向N个实例加锁,只要超过一半节点成功,则认定加锁成功;
-
解锁:向所有的实例发送DEL命令,进行解锁;
RedLock算法的示意图如下,我们可以自己实现该算法,也可以直接使用Redisson框架。
6.说一说你对布隆过滤器的理解
参考答案
布隆过滤器可以用很低的代价,估算出数据是否真实存在。例如:给用户推荐新闻时,要去掉重复的新闻,就可以利用布隆过滤器,判断该新闻是否已经推荐过。
布隆过滤器的核心包括两部分:
-
一个大型的位数组;
-
若干个不一样的哈希函数,每个哈希函数都能将哈希值算的比较均匀。
布隆过滤器的工作原理:
-
添加key时,每个哈希函数都利用这个key计算出一个哈希值,再根据哈希值计算一个位置,并将位数组中这个位置的值设置为1。
-
询问key时,每个哈希函数都利用这个key计算出一个哈希值,再根据哈希值计算一个位置。然后对比这些哈希函数在位数组中对应位置的数值:
-
如果这几个位置中,有一个位置的值是0,就说明这个布隆过滤器中,不存在这个key。
-
如果这几个位置中,所有位置的值都是1,就说明这个布隆过滤器中,极有可能存在这个key。之所以不是百分之百确定,是因为也可能是其他的key运算导致该位置为1。
-
7.多台Redis抗高并发访问该怎么设计?
参考答案
Redis Cluster是Redis的分布式解决方案,在3.0版本正式推出,有效地解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡的目的。
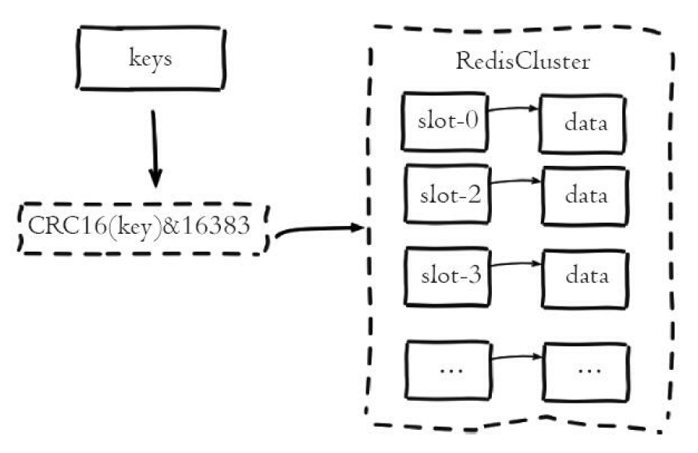
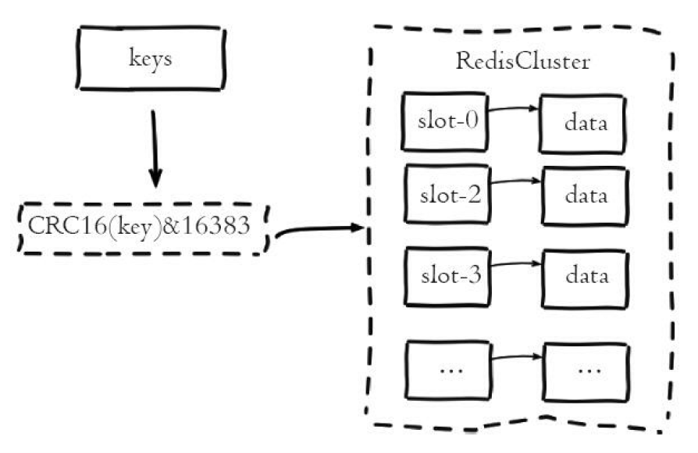
Redis集群采用虚拟槽分区来实现数据分片,它把所有的键根据哈希函数映射到0-16383整数槽内,计算公式为slot=CRC16(key)&16383,每一个节点负责维护一部分槽以及槽所映射的键值数据。虚拟槽分区具有如下特点:
-
解耦数据和节点之间的关系,简化了节点扩容和收缩的难度;
-
节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据;
-
支持节点、槽、键之间的映射查询,用于数据路由,在线伸缩等场景。
Redis集群中数据的分片逻辑如下图:
8.如果并发量超过30万,怎么设计Redis架构?
参考答案
Redis Cluster是Redis的分布式解决方案,在3.0版本正式推出,有效地解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡的目的。
Redis集群采用虚拟槽分区来实现数据分片,它把所有的键根据哈希函数映射到0-16383整数槽内,计算公式为slot=CRC16(key)&16383,每一个节点负责维护一部分槽以及槽所映射的键值数据。虚拟槽分区具有如下特点:
-
解耦数据和节点之间的关系,简化了节点扩容和收缩的难度;
-
节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据;
-
支持节点、槽、键之间的映射查询,用于数据路由,在线伸缩等场景。
Redis集群中数据的分片逻辑如下图:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 拉普拉斯变换,傅里叶变换以及Z变化之间的关系
- 接口自动化框架设计必备利器之参数传递!
- 简单FTP客户端软件开发——搭建FTP服务器
- 【lesson16】MySQL表的基本操作update(更新)和delete(删除)
- Java数据结构--List、Set和Map
- Mysql字段的各种时间类型
- 「已解决」ssh: connect to host github.com port 22: Connection timed out
- YTM32的HSM模块在信息安全场景中的应用
- [我的rust付费栏目]rust跟我学(一)已上线
- 第十四章 RabbitMQ应用