Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly
背景知识
why zero-shot learning?
- 传统的监督学习: 将数据映射到特征空间上,根据标签注释训练得到一个分类器
问题: 遇到一个新类样本时,分类器会将这个样本划分到已有的类中,这是不对的——实际分类器不知道该怎么做

- zero-shot learning: 将类嵌入成语义向量,学习将某类的样本特征空间映射到该类的语义空间上,最终可以实现根据新类样本来生成所属的新类的语义向量即能够判别一个新类——属于迁移学习的一个变体

广义零样本学习设置
- Zero-Shot Learning: 训练类集和测试类集之间没有交集,在训练类上训练得到的模型能够在测试阶段成功识别从未见过的测试类样例
- Generalized Zero-Shot learning: 训练阶段,只可以使用训练集(已知类样本)训练模型;而在测试阶段,测试集中可以包含训练集中已知类以及未知类——“零样本学习在测试阶段,只有未见类样例出现”, 这在实际应用中是不现实的
1 INTRODUCTION
- good aspects: 对零样本学习的研究工作逐年迅速增加
- bad aspects: 没有既定的评估方案来量化这些方法的效果如何,即使每种方法都展示了在前人的方法上取得了进展
- ugly aspects: 对最终效果上的数字的追求甚至导致了有缺陷的评估方案
想法: 在几个从小规模到大规模的数据集上,使用相同的评估方案,即训练集和测试集不相关且更多地广义零样本学习设置,去广泛深入地评估大量最近的零镜头学习方法
零样本学习的关键思想:
辅助信息 auxiliary information : 对已知类和未知类的描述/语义属性/词嵌入等信息
训练过程:能够建立样本特征空间 feature space 和 语义空间 Semantic space 之间的映射,再根据输出的语义信息确定类别
举个例子: 假设小暗(纯粹因为不想用小明)和爸爸,到了动物园,看到了马,然后爸爸告诉他,这就是马;之后,又看到了老虎,告诉他:“看,这种身上有条纹的动物就是老虎。”;最后,又带他去看了熊猫,对他说:“你看这熊猫是黑白色的。”然后,爸爸给小暗安排了一个任务,让他在动物园里找一种他从没见过的动物,叫斑马,并告诉了小暗有关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。”最后,小暗根据爸爸的提示,在动物园里找到了斑马
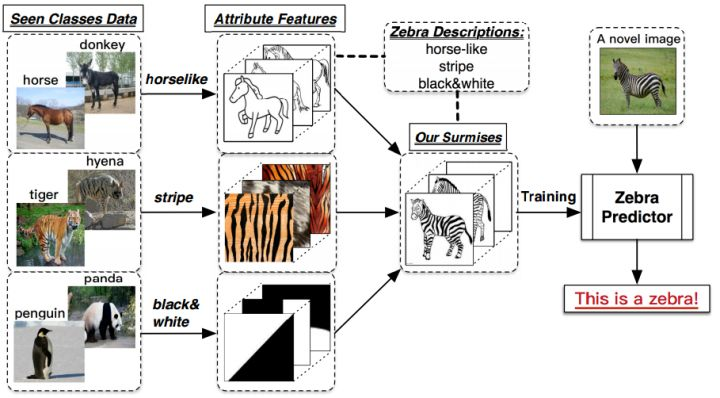
思考:
- 要实现ZSL功能似乎需要解决两个部分的问题:
- 第一个问题:获取合适的类别描述 A
- 第二个问题:建立一个合适的分类模型
- 第一个问题是大头:可以人工专家,也可以通过海量的附加数据集自动学习出来——进展缓慢
以上 from 小栗子
论文通过 m e t h o d s , d a t a s e t s , e v a l u a t i o n p r o t o c o l methods,datasets,evaluation protocol methods,datasets,evaluationprotocol三方面评估现有的零样本学习
1.1 zero-shot learning——methods
- linear compatibility learning frameworks
- nonlinear compatibility learning frameworks
注: 过往的主流,目标都是学习 independent attribute classifiers
- hybrid model between independent classifier learning and compatibility learning frameworks
1.2 zero-shot learning——datasets
- Animals with Attributes (AWA1) dataset:只是图像特征,而不是原始图像
- 问题:都是动物的图片,包括50个类别的图片,其中40个类别作为训练集,10个类别作为测试集,每个类别的语义为85维,总共有30475张图片。但是目前由于版权问题,已经无法获取这个数据集的图片了,而现有的分类模型大多根据原始图像(在ImageNet上训练),使得这些模型无法作用在该数据集上
- 解决:作者设计了Animals with Attributes 2 (AWA2) dataset——有公共许可证,且与AWA1数据集的类和属性数量完全相同
- AWA2
- Sun database(SUN):总共有717个类别,每个类别20张图片,类别语义为102维。传统的分法是训练集707类,测试集10类
- Caltech-UCSD-Birds-200-2011(CUB):全部都是鸟类的图片,总共200类,150类为训练集,50类为测试集,类别的语义为312维,有11788张图片
- Attribute Pascal and Yahoo dataset(aPY) :共有32个类,其中20个类作为训练集,12个类作为测试集,类别语义为64维,共有15339张图片。
- ImageNet
1.3 zero-shot learning——evaluation protocol
提出了一个 unified evaluation protocol :
- 调参设置:强调从训练集中分割出验证集 validation dataset来进行 进行调参(tune hyperparameters)的必要性——通过调整测试类上的参数来提高零样本学习性能违反了zero-shot assumption
- 数据集不平衡问题: 当数据集在每个类的图像数量方面没有很好地平衡时,每个类的平均top-1精度是一个重要的评估指标
- 特征提取问题: 通过预先训练的深度神经网络(DNN)在包含零样本测试类的大型数据集上提取图像特征也违反了zero-shot assumption——图像特征提取是训练过程的一部分
- 数据集选择问题:
- 在小规模和粗粒度数据集(即aPY[18])上测试模型性能得到的结果不是决定性的
- 强调很难获得细粒度稀有物体识别类的标记训练数据,这需要专家意见——也应该在不流行或很少的类上进行评估
- 实际问题: 广义零镜头学习设置
2 RELATED WORK
2.1 早期工作
- TPAMI-13-Attribute-based classification for zero-shot visual object categorization
- ICLR-14-Zero-shot learning by convex combination of semantic embeddings
- CVPR-16-Recovering the missing link: Predicting class-attribute associations for unsupervised zero-shot learning
- NIPS-14-Zero-shot recognition with unreliable attributes
- CVPR-12-Online incremental attribute-based zero-shot learning
two-stage approach:
- 首先,对输入图像的属性集进行预测
- 然后,将属性集最相似的类作为图像的标签(类也有一个属性集)
two-stage approach 存在 domain shift 问题【不同的数据集具有不同的数据分布,一般情况下训练的模型也只能用在与这种训练数据集分布相似的数据集上,而用于与训练数据集分布不同的数据集中时,则会产生具有明显差距的结果】
2.1.1 Attribute-based classification for zero-shot visual object categorization(TPAMI 2013)
关键思想:
- 根据有意义的属性 a t t r i b u t e attribute attribute列表(高级语义列表)对样本进行分类,所谓属性就如颜色、形状等,是为普遍共有抽象的东西(而特征 f e a t u r e feature feature是具体的,如颜色是红色)
- 虽然物体的类别不同,但是物体间存在相同的属性——跨越各类的边界,提炼出每一类别具有的全部属性并利用若干个学习器学习。在测试时对测试数据的属性预测,再将预测出的属性组合,对应到类别,实现对测试数据的类别预测
问题定义:

标准的分类器在上述问题定义上是无法在测试集上分类成功的,因为训练集和测试集不相交,同时分类器实际上会对训练集上的每个类训练得到一个参数向量(由某类样本直接到所属类标签的映射),结果是只能对训练集中的类进行分类,而对测试集模型不知道该怎么做
一些概率论背景知识:
- 先验概率 prior probability : 事件发生前的预判概率,可以是基于历史数据的统计,可以是由背景常识得到,也可以是人的主观观点给出,一般都是单独事件概率,如 p ( x ) p(x) p(x),但应该也称为全事件下发生概率即 p ( x ∣ Ω ) p(x|Ω) p(x∣Ω)
- 后验概率 posterior probability:考虑新信息之后事件发生的修正或更新概率,即假设事件B已经发生的情况下事件A发生的概率,表达为 p ( A ∣ B ) = p ( A ∩ B ) p ( B ) p(A|B)={p(A \cap B) \over p(B)} p(A∣B)=p(B)p(A∩B)?
Direct attribute prediction(DAP)
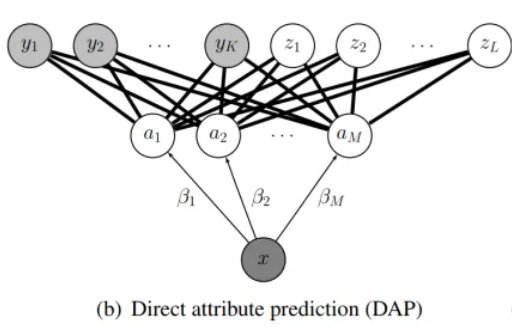
- 【训练阶段】学习每个属性
a
m
a_m
am?的概率分类器
- 训练样本:所有训练类中的所有图像
- 训练标签:一种是per-image attribute annotations, if available;另一种是从类标签对应的属性列表中推断
- 【测试阶段】
- Assumption:每个未知类z以确定的方式推导其属性向量 a z a^z az,表达为 p ( a ∣ z ) = [ [ a = a z ] ] p(a|z)=[[a=a^z]] p(a∣z)=[[a=az]]——Iverson’s bracket notation:[[P]] = 1if the condition P is true and it is 0 otherwise.【我的理解就是辅助信息】
- 首先:预测某个样本在各个属性 attribute 上的概率值(后验概率) p ( a m ∣ x ) p(a_m|x) p(am?∣x)——image-attribute layer
- 接着:根据各未知类提供的属性列表(辅助信息)来筛选属性,再将选择后的属性对应的概率连乘起来,代表样本对此未知类的预测概率大小
- 最终选择概率大的作为该样本的类
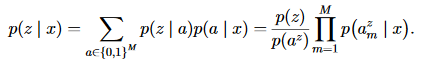

Indirect Attribute Prediction(IAP)
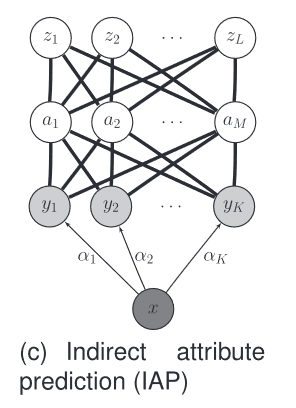

缺点:
- 要求属性列表长度是固定的
- 要求提供对未知类的描述——手工

2.1.2 Recovering the missing link: Predicting class-attribute associations for unsupervised zero-shot learning(CVPR2016)
关键思想: 能够根据未知类的类标签自动预测未其相关的属性列表
问题定义:

具体方法:
-
Vector space embedding for words——skip-gram model
需要一种合适的表示法,将names转换为向量,同时保留words的语义含义
skip-gram模型是一种神经网络,它学习words的向量表示,这些向量表示还有助于预测周围的words——因此,出现在相似上下文中的words(相邻words)在嵌入空间中会表示成彼此接近的向量表示;在大型文本语料库上进行训练 —— 泛化性好

-
Learning class-attribute relations——tensor factorization
训练过程表示: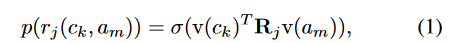
其中, R ∈ R d × d × N R \in \mathbb{R}^{d \times d \times N} R∈Rd×d×N是一个三维向量, d d d是词嵌入后的向量的维度, N N N是所有关系的数量大小, R j ∈ R d × d R_j \in \mathbb{R}^{d \times d} Rj?∈Rd×d用来计算某类和某属性的关系的双线性算子 bilinear operator; σ ( ) \sigma() σ()是逻辑运算
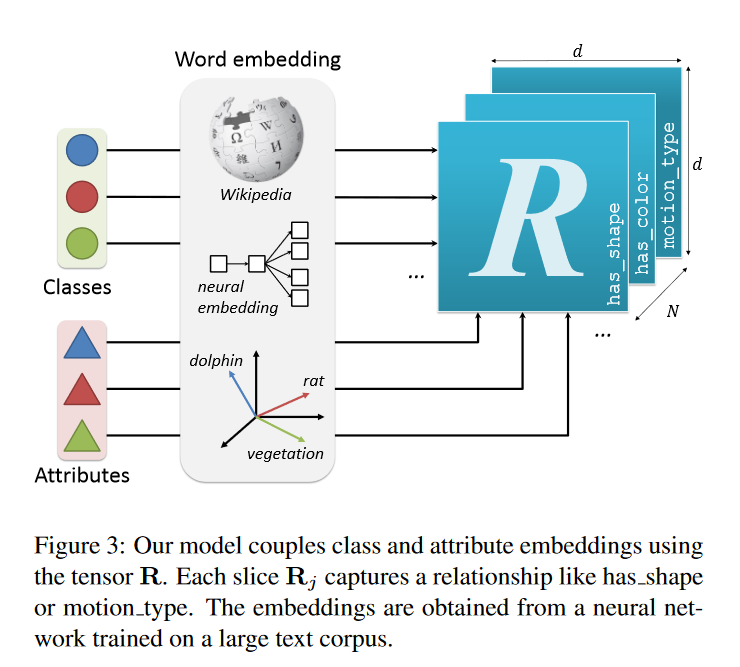
R j R_j Rj?是通过学习得到的:
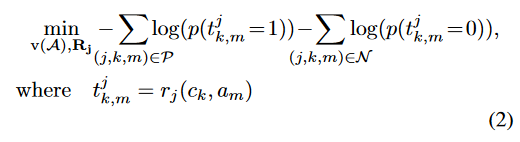
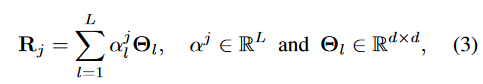
其中, α j \alpha^j αj是一个稀疏向量 sparse vector,用来加权排名第一的潜在因素Θ的贡献度,使用 λ \lambda λ来控制 α \alpha α的稀疏性即 ∣ ∣ α j ∣ ∣ < = λ ||\alpha_j|| <= \lambda ∣∣αj?∣∣<=λ,从而控制潜在因素在关系中共享的程度——使用到了latent factor model【确定某个类喜欢哪些属性】
- R. Jenatton, A. Bordes, N. L. Roux, and G. Obozinski. A Latent Factor Model for Highly Multi-relational Data. In NIPS, 2012
- 浅浅理解LFM
标签制作:
- 学习目的:能够建立起某个类和其应有的属性之间的关系【让类、属性去寻找对方】
- 问题:
- 模型的输出就是某类和某属性之间的关系程度(概率表示),怎么评判这个输出是好的,关系应当有一个参照即标签;
- 有的数据集会提共某类的属性列表,但有的不会
- 参照关系设定: 上面提到利用skip-graph学习得到的嵌入向量若相似则会离得很近,此时可以利用聚类对属性嵌入空间进行分组【一个类寻找到一个簇内的某个属性的概率与寻找该簇内其他属性的概率应该是差不多?】
特别地:
-
treat the set of categories as an open set and fix their embedding v ( c ) v(c) v(c) to the one learned 【特征空间分布对齐】——未知类的信息不可获得,domain adaptation
-
visual attributes A A A are usually restricted to entities which we have seen before ——更好地学习属性嵌入表示,通过传播梯度
- Predicting binary associations


2.1.3 Zero-shot learning by convex combination of semantic embeddings(ICLR 2014)
问题定义:

每个标签
y
y
y关联到语义嵌入向量semantic embedding vector
s
(
y
)
∈
S
s(y) \in S
s(y)∈S
关键思想:
- 训练阶段:按传统机器学习的方法利用训练集训练出一个分类器 p 0 p_0 p0?,该分类器输出是某样本预测为某标签值的概率大小即 p 0 ( y ∣ x ) p_0(y|x) p0?(y∣x),对应的预测标签为 y 0 ^ \hat{y_0} y0?^?
- 测试阶段:
- 首先,利用学习到的分类器对测试样本进行预测,选出置信度最高的前 T(超参数)个预测值包括概率值和预测的标签值(预测的是训练集上的标签)
- 接着,计算该测试样本的语义嵌入向量f(x),式子如下,其中,Z是归一化因子
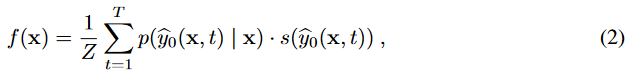

- 最后,根据 将 f(x) 与 测试集中各真实标签的语义嵌入向量进行余弦相似度计算,选取最相似的标签作为其预测标签

例子理解:

2.2 一些进展(截至2017)
2.2.1 学习直接从图像特征空间到语义空间的映射
29 30 7 9 10 31 32 33
- NIPS-2009-Zero-Shot Learning with Semantic Output Code
- TPAMI-2016-Label-Embedding for Image Classification
- NIPS-2013-DeViSE: A Deep Visual-Semantic Embedding Mode
- CVPR-2015-Evaluation of Output Embeddings for Fine-Grained Image Classification
- ICML-2015-An Embarrassingly Simple Approach to
Semi-Supervised Few-Shot Learning- CVPR-2016-Less is more: zero-shot learning from online textual documents
with noise suppression?- ECCV-2016-Improving Semantic Embedding Consistency by
Metric Learning for Zero-Shot Classification- CVPR-2017-Semantic Autoencoder for Zero-Shot Learning
2.2.1.1 Zero-Shot Learning with Semantic Output Code( NIPS 2009)
general question: 给定一个大型概念类集合(concept classses)的语义编码(semantic encoding),能否构建一个分类器来识别出未知类?
问题定义:
- Definition 1. Semantic Feature Space: 语义特征空间是一个p维的度量空间(metric space)其每个维度都是语义属性(semantic property)的编码值
举个栗子: 考虑一个5维的描述动物的high level properties的语义空间,每一维的语义属性为:有没有毛皮?有没有尾巴?可以在水下呼吸吗?是否肉食?动作缓慢吗?那么在这个语义空间中典型的狗的概念可以表示为{1,1,0,1,0}
- Definition 2. Semantic Knowledge Base : 一个包含M个类的语义知识库 是一个形如 { f , y } 1 : M \{f,y\}_{1:M} {f,y}1:M?集合,其中, f ∈ F p f \in F^p f∈Fp 是语义空间 F p F^p Fp中的一个的一个point, y ∈ Y y \in Y y∈Y 是一个类的标签;假定 类标签与类的语义空间中的点是一对一的关系
注: 语义知识库包括与已知类和未知类相关联的语义属性
- Definition 3. Semantic Output Code Classifier: 一个语义输出码分类器
H
H
H将原始输入空间
X
d
X^d
Xd中的点映射为集合
Y
Y
Y中的标签,形如
H
:
X
d
→
Y
H:X^d \rightarrow Y
H:Xd→Y
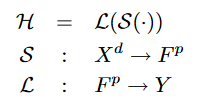
训练设置:

- 语义属性向量(语义空间中的一个点)是binary lavels(二值标签)
- 学习从原始图像到其语义编码的映射 S S S是一组PAC(可学习分类器)的集合
- 学习从预测出的语义编码到类标签的映射 L L L是使用汉明距离度量(Hamming distance metric)的1-最近邻分类器(1-nearest neighbor classifier)
2.2.1.2 An Embarrassingly Simple Approach to Semi-Supervised Few-Shot Learning( NIPS 2022)
前景知识:
- positive labels :给定样本的正确类标签
- negative pseudo-labels:伪标签是指通过某种方法来给未标记样本打上标签,负标签是指给定样本所不属于的类标签;那么结合在一起就是在给未标记样本通过某些方法打标签时的最低置信度的标签【互补标签Complementary Labels】
- negative learning paradigm :学习给定样本不属于哪个类
- 出发点是处理有噪声的标签、样本收集问题
- 举个例子:给定某个样本如动物图片,实际是一个斑马,但此时由于知识的欠缺假定是未知的,但可以确定它不是猴子,它不是狗等等
- Weakly Supervised Learning: 提供模型一些带噪声的、不够完整的、不确切的监督信息,希望其能从这些信息中有效的学习
- 不准确监督:通过一些众包平台对样本进行打标记,由于标注者质量的参差不齐,虽然绝大部分的样本能被正确的标记,但样本中还是存在着些许噪声标记
- 不完全监督:通常只有少量准确的有标记样本以及大量的未标记样本,如何利用大量未标记样本的信息来学习一个有效的模型;
- 不确切监督: 对于每个样本都会有一个候选集,并且只知道真实标记在这个候选集里面,但是具体是哪一个标记就不知道了
问题定义:

训练/测试设置:
- N-way-K-shot
- inductive inference:查询集内与基类数据集、支持集不相交
- transductive inference:三者会相交
关键思想 :
- 通过迭代地排除未标记样本的负标签,最后剩下的一个可以作为其正标签,然后再执行传统的positive learning
- 每一次的迭代在找到本次负标签后会更新分类器 f f f的参数,然后再把这个负标签从候选类中排除 exclude,进行下一次迭代

2.2.1.3 Semantic Autoencoder for Zero-Shot Learning(CVPR 2017)
related work:
- Semantic space:
- attribute space
- word vector space
- textual descriptions: Wikipedia articles , sentence descriptions
- Visual → Semantic projection:
- learn a projection function from a visual feature space to a semantic space either using conventional regression or ranking models or via deep neural network regression or ranking
- chooses the reverse projection direction,semantic → visual ;The motivation is to alleviate the hubness problem
- learn an intermediate space 【公共空间】where both the feature space and the semantic space are projected to
- Autoencoder:
- undercomplete autoencoders:基于底层特征
- overcomplete autoencoders:基于高维特征
关键想法 :使用Semantic AutoEncoder 技术解决domain shift 问题
- 为什么使用AutoEncoder:因为对更真实的视觉特征重建的需求在seen and unseen domain都是需求的,保证学习到的视觉→语义投影函数保留原始视觉特征中包含的所有信息,从而解决了domain shift 问题
- Semantic AutoEncoder: 为了使latent space 更具有语义意义,强制latent space
S
S
S 为语义表示空间 semantic representation space , 且
S
S
S的每一列是输入样本的属性向量

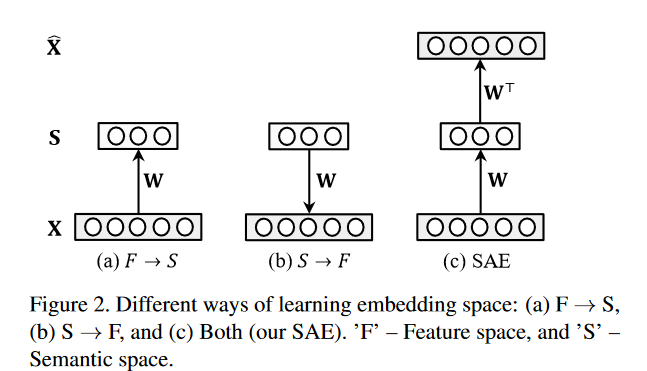
注: 优化过程,因为解决含有硬约束 hard constraint(WX=S)的问题是困难的,所以考虑将约束变宽变成软约束 soft constraint



问题定义:

测试过程:训练得到的Semantic AutoEncoder既可以在语义空间也可以在视觉上对样本进行分类
- 在语义空间上的分类-encode: 将测试样本利用学习到的编码器从视觉空间嵌入到语义空间得到语义表示,然后与每个未知类的原型的语义表示做距离度量,选择最近的一个未知类作为其标签

- 在视觉空间上的分类-decode: 将未知类的语义表示嵌入到视觉特征空间,然后计算输出与实际测试样本的样本的距离度量,选择最近的一个未知类作为标签

2.2.2 Learn non-linear multi-modal embeddings
- CVPR-2017-Latent embeddings for zero-shot classification
- NIPS-2013-cross-Zero-shot learning through cross-modal transfer
- ICCV-2015-Predicting deep zero-shot convolutional neural networks using textual descriptions
- CVPR-12017-Learning a deep embedding model for zero-shot learning
- CVPR-2017-Predicting visual exemplars of unseen classes for zero-shot learning
[11][12]
[34][35][36]
Embedding both the image and semantic features into another common intermediate space
[13]
- “Zero-shot recognition with unreliable attributes,” in Proc. 27th Int. Conf. Neural Inf. Process. Syst., 2014
- “Online incremental attribute-based zero-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2012
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2023年小结
- Goodbye2023, Hello 2024!
- Nvm版本管理工具安装使用
- python运算符详解
- openssl3.2/test/certs - 024 - EC cert with named curve
- 多家大厂的软件测试面试常见问题合集(BAT、三大流量厂商、知名大厂)
- 软件测试之黑盒测试
- 拓展操作(四) 使用nginx反向代理jenkins
- C# 学习笔记2-控制流与类型转换
- ELK分离式日志(2)