字符集&字符编码
字符集
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。而字符集(Character set)则是多个字符的集合。
简单的说,字符集就规定了某个文字对应的二进制数字存放方式(编码)和某串二进制数值代表了哪个文字(解码)的转换关系。
字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、GBK字符集、GB18030字符集、BIG5字符集、Unicode字符集等。
对于一个字符集来说要正确编码转码一个字符需要三个关键元素:字库表、编码字符集、字符编码。
字库表
一套字符集不一定包含世界上所有的字符,每套编码规范都有自己的使用场景。
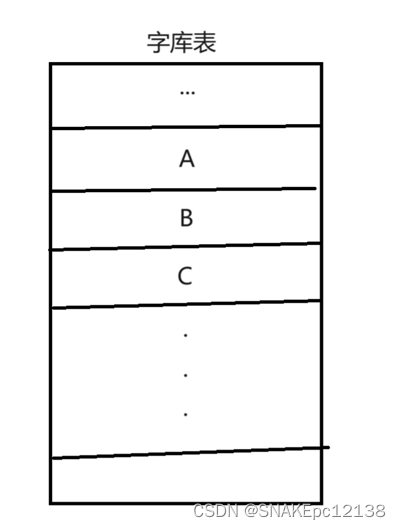
而字库表就存储了编码规范中能显示的所有字符,计算机就是根据二进制数从字库表中找到字符然后给到上层应用显示,相当于一个存储字符的数据库。
例如:几乎所有汉字都保存在GBK 字符集的字库表中。所以可以显示汉字,但法语,俄语并不在其字库表中,所以GBK不能显示法语,俄语等不包含在其中的字符。如图:
编码字符集
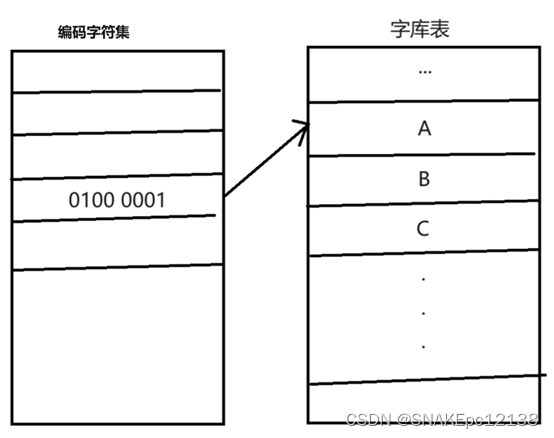
在一个字库表中,每一个字符都有一个对应的二进制地址,而编码字符集就是这些地址的集合。
例如:
在ASCII码的编码字符集中,字母A的序号(地址)是65,65的二进制就是01000001。我们可以说编码字符集就是用来存储这些二进制数的。而这个二进制数就是编码字符集中的一个元素,同时它也是字库表中字母A的地址。我们根据这个地址就可以显示出字母A。如图:
字符编码
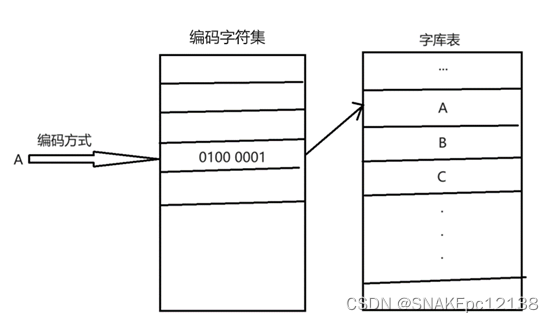
字符编码即为:字符集合中的每个字符在计算机系统中存放(编码)和表示(解码)字符对应二进制数的方式。
因为计算机存储单位一般为字节,因此各种字符编码系统以字节为基础进行表示。
计算机要准确的处理各种字符集文字,就需要进行字符编码,以便计算机能够识别和存储各种文字。
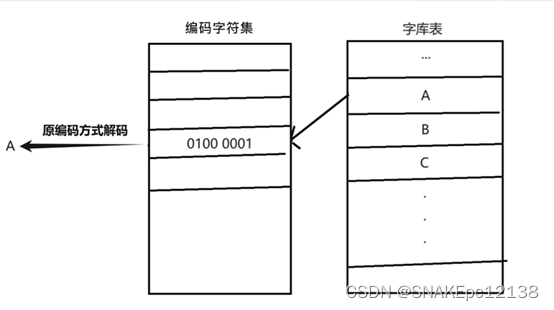
相应的解码过程如下:
乱码原因
通过上面字符编码的过程,当编码和解码不一致时,就会导致乱码出现。
例如:
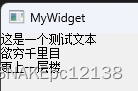
现有一个txt文本(GB2312编码),使用QFile获取文本内容:
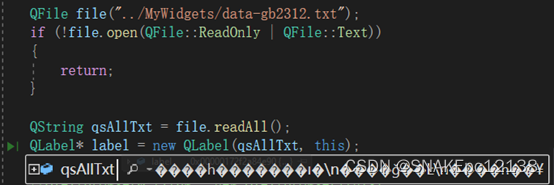
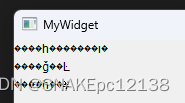
发现读取的内容乱码了。
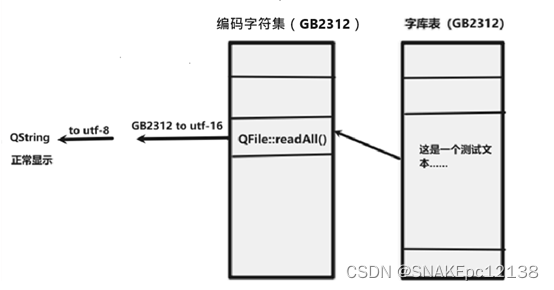
原因是我们的数据来源:GB2312编码的文本,通过QFile::readAll()获取到元素二进制数据后,赋值给QString这里使用UTF-8解码(QString默认以UTF-8保存数据)GB2312的编码,所以导致乱码。
即:源数据是以GB2312编码保存的,而在程序中使用时却以UTF-8方式解码。
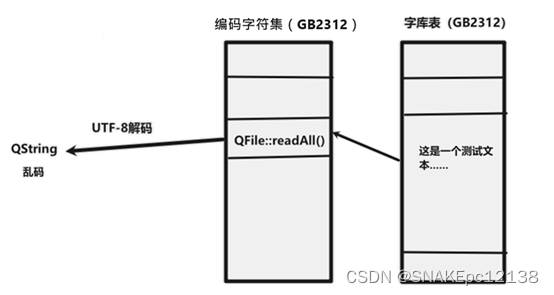
这里再明确转码操作即可正常读取:
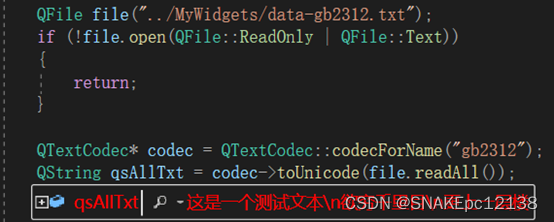
最后补充下字符集种类及其对应编码。
字符集种类
根据每个字符集中的一个字符用几个字节表示,字符集可以分为以下三大类:
单字节字符集、多字节字符集(MBCS)、Unicode字符集。
单字节字符集
单字节字符集,字符集中的每个字符只用一个字节表示。常见的单字节字符集有:
ASCII字符集(对应ASCII编码)
ASCII(对应ASCII编码):用一个字节的低7bit表示一个字符,范围从0x00 - 0x7F 共可以表示128个字符,包括英文大小写字母、数字。
EASCII字符集(对应EASCII编码)
EASCII(对应EASCII编码):ASCII扩展字符集, 使用一个字节的全部8bit表示字符,在原来基础上增加表示一些控制字符、特殊字符等。扩展后范围从0x00-0xFF共可以表示256个字符。
多字节字符集(MBCS)
ASCII只能表示127个字符,即使扩展后也只能表示256个字符,对于表示欧美国家的字符够用了,但是对于其他国家文字,比如中国的汉字,就显然不够用了。
因此其他国家为表示自己的字符集制订新的编码方案,主要方法是用多个字节表示一个字符。但是这些编码方案必须满足美国的ANSI标准,即要兼容ASCII字符集,任何新的字符集编码都必须保留0x00 - 0x7F的127个编码表示ASCII字符,其他字符的表示使用大于128(0x7F)的字节作为一个Leading Byte,紧跟在Leading Byte后的第二(甚至第三)个字符与 Leading Byte一起作为实际的编码。
所有符合ANSI标准的编码都称为ANSI编码,如:
GB2312字符集(对应GB2312编码)
GB2312字符集(对应GB2312编码):用一个小于0x7F的字节表示ASCII字符,用均大于0x7F的两个字节表示一个汉字,两个字节的编码范围为0xA1A1 - 0xFEFE,这个范围可以表示23901个汉字。
GB2312收录简化汉字及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。其中包括6763个汉字,其中一级汉字3755个,二级汉字3008个;包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
GBK字符集(GBK编码)
GBK字符集(GBK编码):表示方法和gb2312一样,只不过对两字节的编码范围进行了扩充,用0x8140 - 0xFEFE表示其他汉字,最多可以表示3万多个汉字。
GB18030字符集(GB18030编码)
GB18030字符集(GB18030编码):在GBK表示的字符集基础上进一步扩充,增加了少数民族的字符,是目前最全的中文字符集,它并没有确定所有的字形,只是规定了编码范围,留待以后扩充。
GB18030最多可以用四个字节表示一个字符,用两个字节表示时与GBK兼容,扩充部分用四个字节表示,每个字节规定不同的编码范围,其编码范围是首字节0x81-0xfe、二字节0x30-0x39、三字节0x81-0xfe、四字节0x30-0x39。
GB2312、GBK、GB18030一脉相承,因此统称为GBK。
BIG字符集(BIG5编码)
BIG字符集(BIG5编码):Big5,又称为大五码或五大码,是使用繁体中文(正体中文)社区中最常用的电脑汉字字符集标准,共收录13,060个汉字。中文码分为内码及交换码两类,Big5属中文内码,知名的中文交换码有CCCII、CNS11643。Big5虽普及于台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准。
Big5码使用了双字节储存方法,以两个字节来编码一个字。第一个字节称为“高位字节”,第二个字节称为“低位字节”。高位字节的编码范围0xA1-0xF9,低位字节的编码范围0x40-0x7E及0xA1-0xFE。
各编码范围对应的字符类型如下:0xA140-0xA3BF为标点符号、希腊字母及特殊符号,另外于0xA259-0xA261,存放了双音节度量衡单位用字:兙兛兞兝兡兣嗧瓩糎;0xA440-0xC67E为常用汉字,先按笔划再按部首排序;0xC940-0xF9D5为次常用汉字,亦是先按笔划再按部首排序。
小结
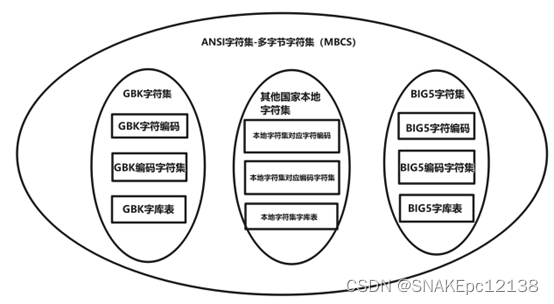
以上这些字符集(GB2312字符集、GBK字符集、GB18030字符集、BIG5字符集)都符合ANSI标准,因此其对应的编码(GB2312编码、GBK编码、GB18030编码、BIG5编码)统称为ANSI编码。
从ANSI标准派生的字符集统称为ANSI字符集,每种ANSI字符集编码时使用的字节数不是固定的(例如gb2312用一个或者两个字节表示、GB18030用一个、两个或者四个字节表示。
),因此它们都称为MBCS(Multi-Byte Chactacter System,即多字节字符系统)
。
ANSI字符集汇总如下:
简单示例:
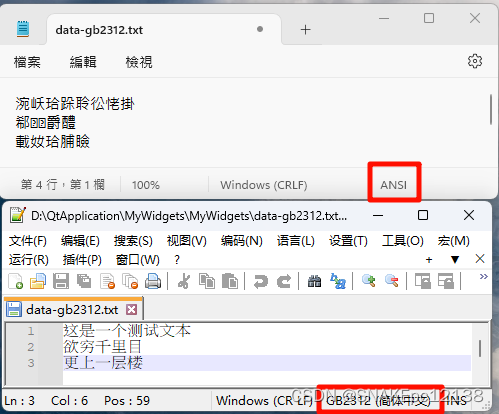
同一个文件,用Notepad++打开则显示的GB2312编码、用Windows记事本打开右下角显示的是ANSI编码(记事本未细分GBK、BIG5等编码,统称为ANSI)。
上面记事本显示乱码是因为我本地系统编码是BIG5,即记事本程序内部使用BIG5解码GB2312编码的内容,导致乱码。
对于如何判断文件的编码,因篇幅有限,后续也会详细讲解。
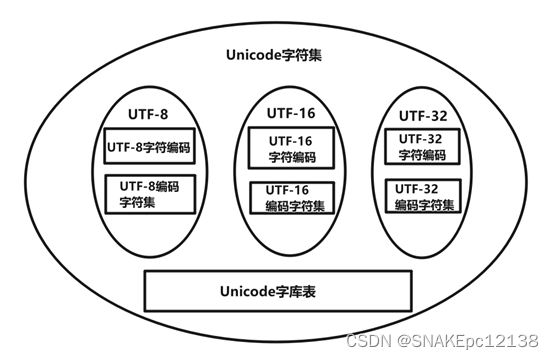
Unicode字符集
每个国家都制定一个符合ANSI标准的字符集,有可能同一个编码对应不同字符集中的不同字符,会造成乱码。
因此,将全世界的所有字符整理成统一的字符集,统一编码,所有国家都使用这个字符集就不会出现乱码问题,这就是Unicode字符集。
Unicode包含了全世界所有的字符,Unicode最多可以保存4个字节容量的字符。
也就是说,要区分每个字符,每个字符的地址需要4个字节。这是十分浪费存储空间的,于是,程序员就设计了几种字符编码方式,比如:UTF-8,UTF-16,UTF-32。
UTF-8编码
注意是字符编码不是字符集。
UTF-8是一种变长的编码方案,使用 1~6 个字节来存储。
UTF-8 的编码规则很简单:如果只有一个字节,那么最高的比特位为 0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
110xxxxx 10xxxxxx:双字节编码形式;
1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式;
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式。
xxx 就用来存储 Unicode 中的字符编号。
UTF-32编码
注意是字符编码不是字符集。
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
UTF-16编码
注意是字符编码不是字符集。
UTF-16编码介于 UTF-8编码 和 UTF-32编码 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。
对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
小结
只有 UTF-8 兼容 ASCII,UTF-32 和 UTF-16 都不兼容 ASCII,因为它们没有单字节编码。
另外,通常所说的Unicode编码为UTF16编码。
最后汇总图如下:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!