监控场景及开源监控方案选型
- 先看监控的需求来源,即监控系统可做什么
- 再跳出监控,从可观测性,看监控与日志、链路间的关系及它们各自的作用
- 最后介绍开源社区几个有代表性的方案以及它们各自的优缺点,便于你之后做技术选型。
1 监控需求来源
系统出问题我们能及时感知。随时代发展,对监控系统提出更多诉求:
- 通过监控了解数据趋势,知道系统在未来的某个时刻可能出问题,预知问题
- 通过监控了解系统的水位情况,为服务扩缩容提供数据支撑
- 通过监控来给系统把脉,感知到哪里需要优化,比如一些中间件参数的调优
- 通过监控来洞察业务,提供业务决策的数据依据,及时感知业务异常
目前监控系统越来越重要,同时也越来越完备。不但能很好地解决上面这几点诉求,还沉淀很多监控系统中的稳定性相关的知识。当然,这得益于对监控体系的持续运营,特别是一些资深工程师的持续运营的成果。
2 可观测性三大支柱
监控系统,其实只是指标监控,通常使用折线图形态呈现在图表上,如某机器的CPU利用率、某个数据库实例的流量或者网站的在线人数,都可体现为随着时间而变化的趋势图。

指标监控 只能处理数字,但它的历史数据存储成本较低,实时性好,生态庞大,是可观测性领域里最重要的一根支柱。聚焦在指标监控领域的开源产品有Zabbix、Open-Falcon、Prometheus、Nightingale等。
除了指标监控,另一个重要的可观测性支柱是 日志。从日志中可以得到很多信息,对于了解软件的运行情况、业务的运营情况都很关键。比如操作系统的日志、接入层的日志、服务运行日志,都是重要的数据源。
从操作系统的日志中,可以得知很多系统级事件的发生;从接入层的日志中,可以得知有哪些域名、IP、URL 收到了访问,是否成功以及延迟情况等;从服务日志中可以查到 Exception 的信息,调用堆栈等,对于排查问题来说非常关键。但是日志数据通常量比较大,不够结构化,存储成本较高。
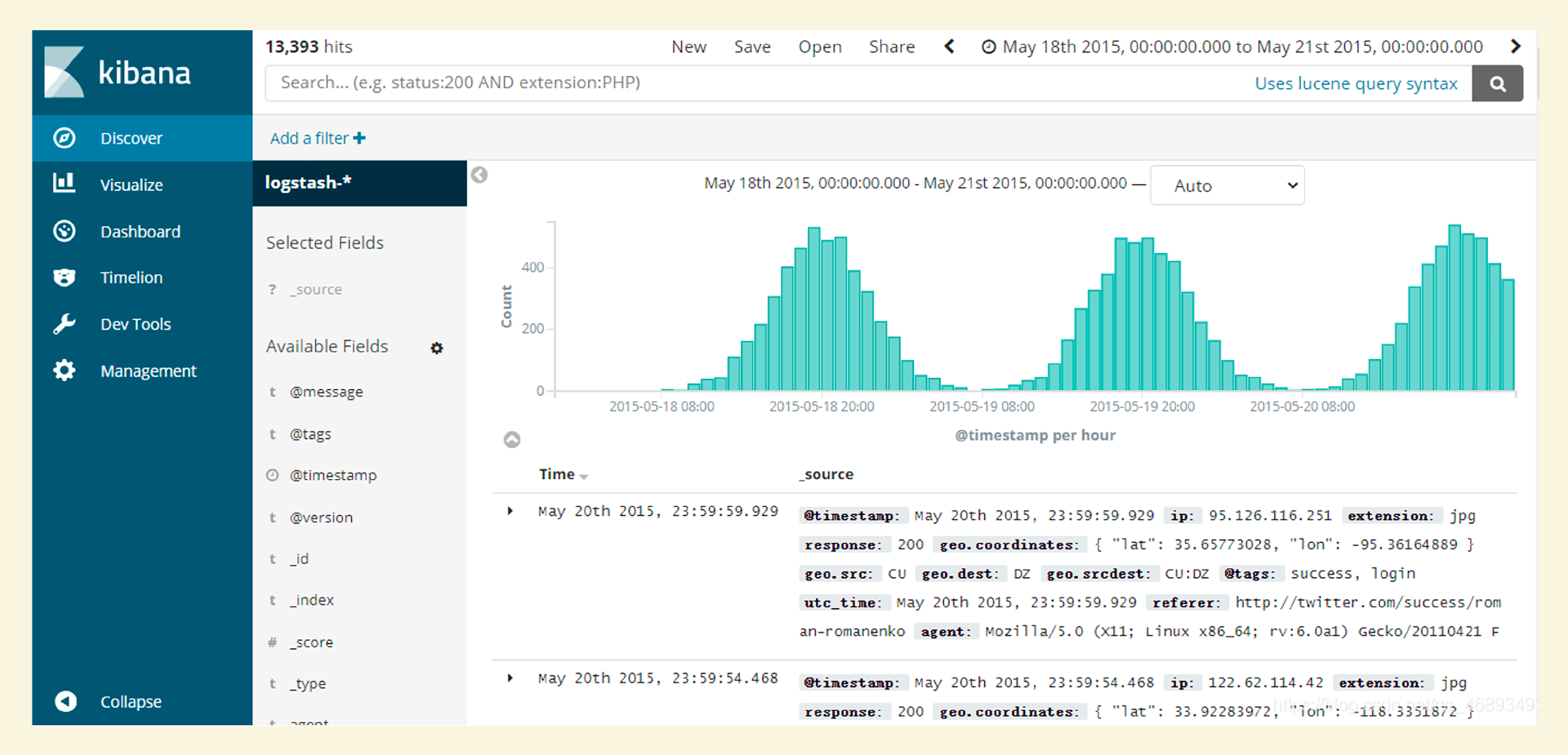
处理日志这个场景,也有很多专门的系统,比如开源产品ELK和Loki,商业产品Splunk和Datadog,下面是在 Kibana 中查询日志的一个页面。
可观测性最后一大支柱 链路追踪。微服务一个问题具体是哪个模块导致的,排查非常困难。
链路追踪思路
以请求串联上下游模块,为每个请求生成一个随机字符串作为请求ID。服务之间互相调用时,把该ID逐层往下传递,每层分别耗费多久,是否正常处理,都可收集附到该请求ID。后面追查问题时,拿着请求ID就可将串联的所有信息提取。链路追踪这个领域也有很多产品,如 Skywalking、Jaeger、Zipkin都是翘楚。
虽把可观测性领域划分3大支柱,但它们之间有很强关联关系。如经常会从日志提取指标,转存到指标监控系统,或者从日志中提取链路信息来做分析,业界都有实践。
本专栏聚焦指标监控领域,把这领域讲透,助你在工作中快速落地实践。
3 解决方案横评
了解业界方案优缺点,对选型有大助。这里主要评价开源方案。
3.1 老代整体方案代表Zabbix
企业级开源解决方案,擅长设备、网络、中间件监控。因为前几年使用监控系统主要就是用来监控设备和中间件,所以Zabbix在国内应用非常广泛。
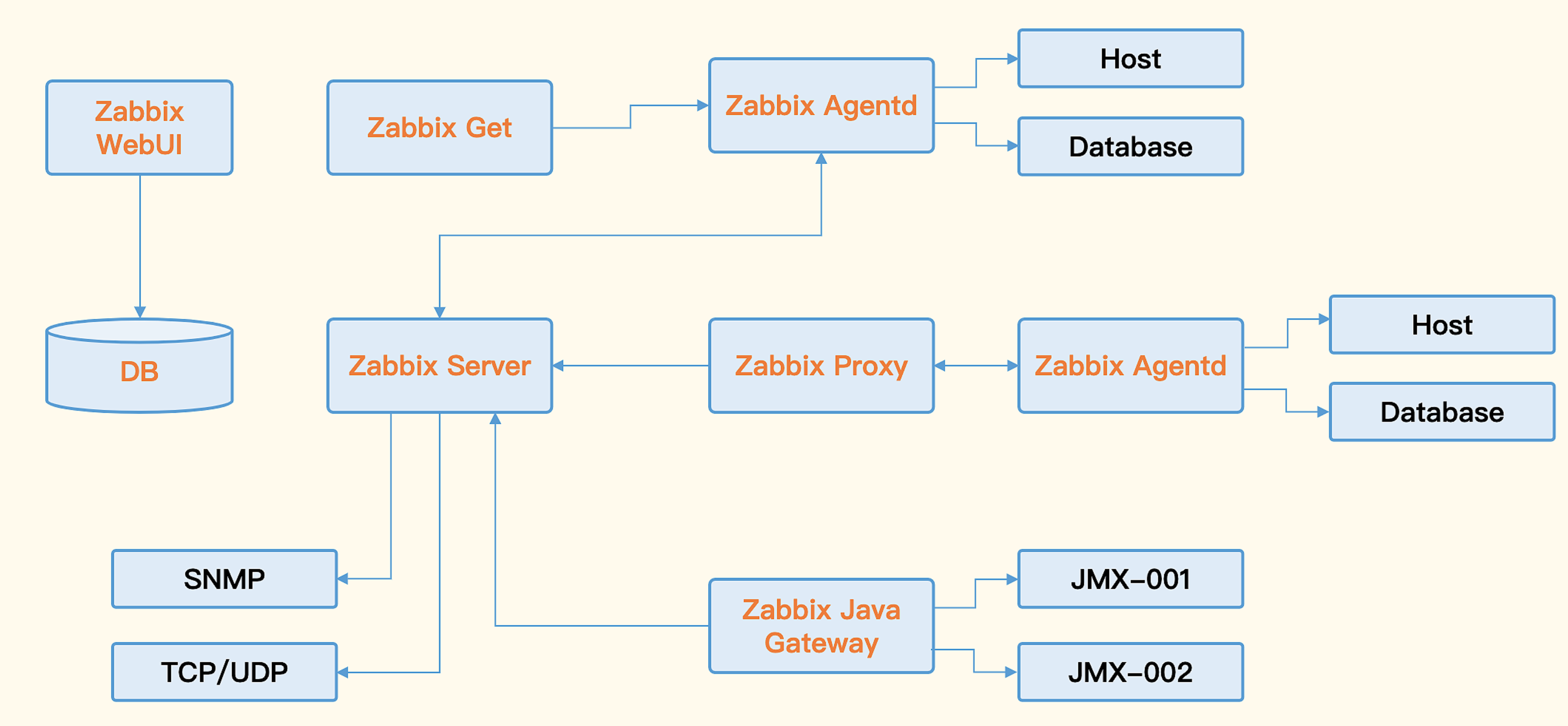
核心构成
Zabbix Server与可选组件Zabbix Agent。Zabbix Server可通过SNMP、Zabbix Agent、JMX、IPMI等多种方式采集数据,它可以运行在Linux、Solaris、HP-UX、AIX、Free BSD、Open BSD、OS X等平台。
配套组件,Zabbix Proxy、Zabbix Java Gateway、Zabbix Get、Zabbix WEB等,共同组成Zabbix整体架构:
优点
- 对各种设备的兼容性较好,Agentd不但可以在Windows、Linux上运行,也可在Aix运行
- 架构简单,使用数据库做时序数据存储,易于维护,备份和转储都较易
- 社区庞大,资料多。Zabbix大概是2012年开源的,因为发展的时间比较久,在网上可以找到海量资源
缺点
- 使用数据库做存储,无法水平扩展,容量有限。如采集频率较高,比如10秒采集一次,上限大约可监控600台设备,还要把数据库部署在一个高配机器,如SSD或NVMe的盘
- Zabbix面向资产的管理逻辑,监控指标的数据结构较为固化,没有灵活的标签设计,面对云原生架构下动态多变的环境,显得力不从心
老国产代表 Open-Falcon
Open-Falcon在Zabbix后,开发初衷就是解决Zabbix容量问题。Open-Falcon最初来自小米,14年开源,当时小米有3套Zabbix,1套业务性能监控系统perfcounter。Open-Falcon初衷想做大一统方案,来解决这乱局。Open-Falcon架构图:
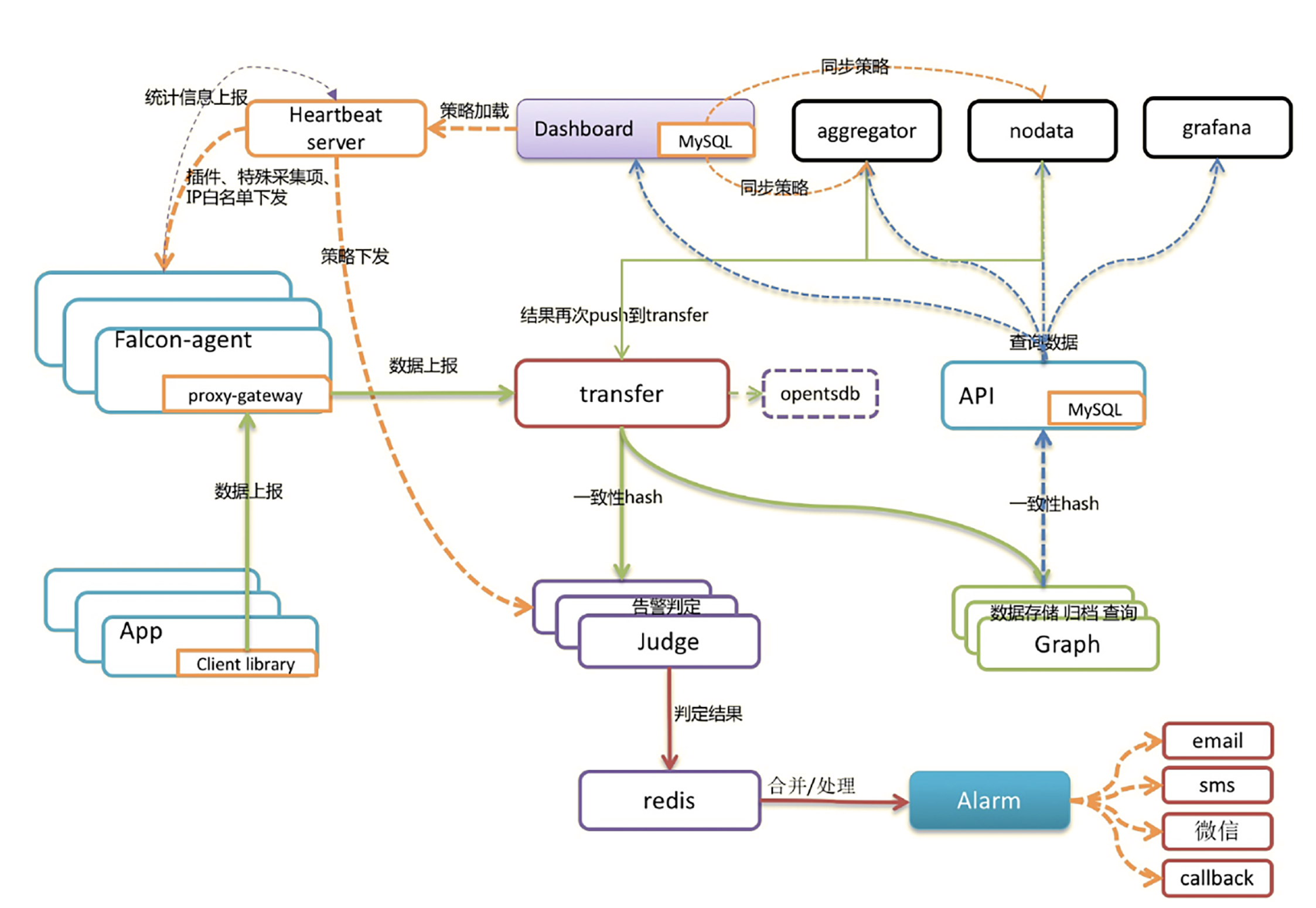
Open-Falcon基于RRDtool做了一个分布式时序存储组件Graph。这可将多台机器组成一个集群,大幅提升海量数据处理能力。前面负责转发的组件是Transfer,Transfer对监控数据求取一个唯一ID,再对ID做哈希,就可生成监控数据和Graph实例的对应关系,这就是Open-Falcon架构中最核心的分片逻辑。
告警部分用Judge模块,发送告警事件Alarm模块,采集数据Agent,心跳模块HBS,聚合监控数据的模块是Aggregator,负责处理数据缺失的模块是Nodata。和用户交互的Portal/Dashboard模块。
Open-Falcon把组件拆散,组件较多,部署较麻烦。不过每个组件的职能单一,二次开发较容易,很多互联网公司都是基于Open-Falcon二开,如美团、快网、360、金山云、新浪微博、爱奇艺、京东、SEA等。
优点
- 可以处理大规模监控场景,比Zabbix的容量要大得多,不仅可以处理设备、中间件层面的监控,也可以处理应用层面的监控,最终替换掉了小米内部的perfcounter和三套Zabbix。
- 组件拆分得比较散,大都是用Go语言开发的,Web部分是用Python,易于做二次开发。
缺点
- 生态不大,是小米公司在主导,很多公司二开,但都没回馈社区,贡献者数量较少
- 开源软件治理架构不够优秀,小米公司核心开发人员离职,项目就停滞,小米公司后续也没有大的治理投入,相比托管在基金会的项目,缺少生命力
新一代整体方案代表 Prometheus
Prometheus设计思路来自Google的Borgmon,师出名门,就像Borgmon为Borg而生,Prometheus就是为Kubernetes而生。它针对Kubernetes直接支持,提供多种服务发现机制,大幅简化Kubernetes的监控。
在Kubernetes环境下,Pod创建和销毁非常频繁,监控指标生命周期大幅缩短,导致类似Zabbix这种面向资产的监控系统力不从心,而且云原生环境下大都是微服务设计,服务数量变多,指标量也呈爆炸态势,对时序数据存储提出高要求。
Prometheus 1.0设计较差,但2.0重新设计时序库,性能、可靠性都大幅提升,社区涌现越来越多的Exporter采集器,非常繁荣。
Prometheus架构图:
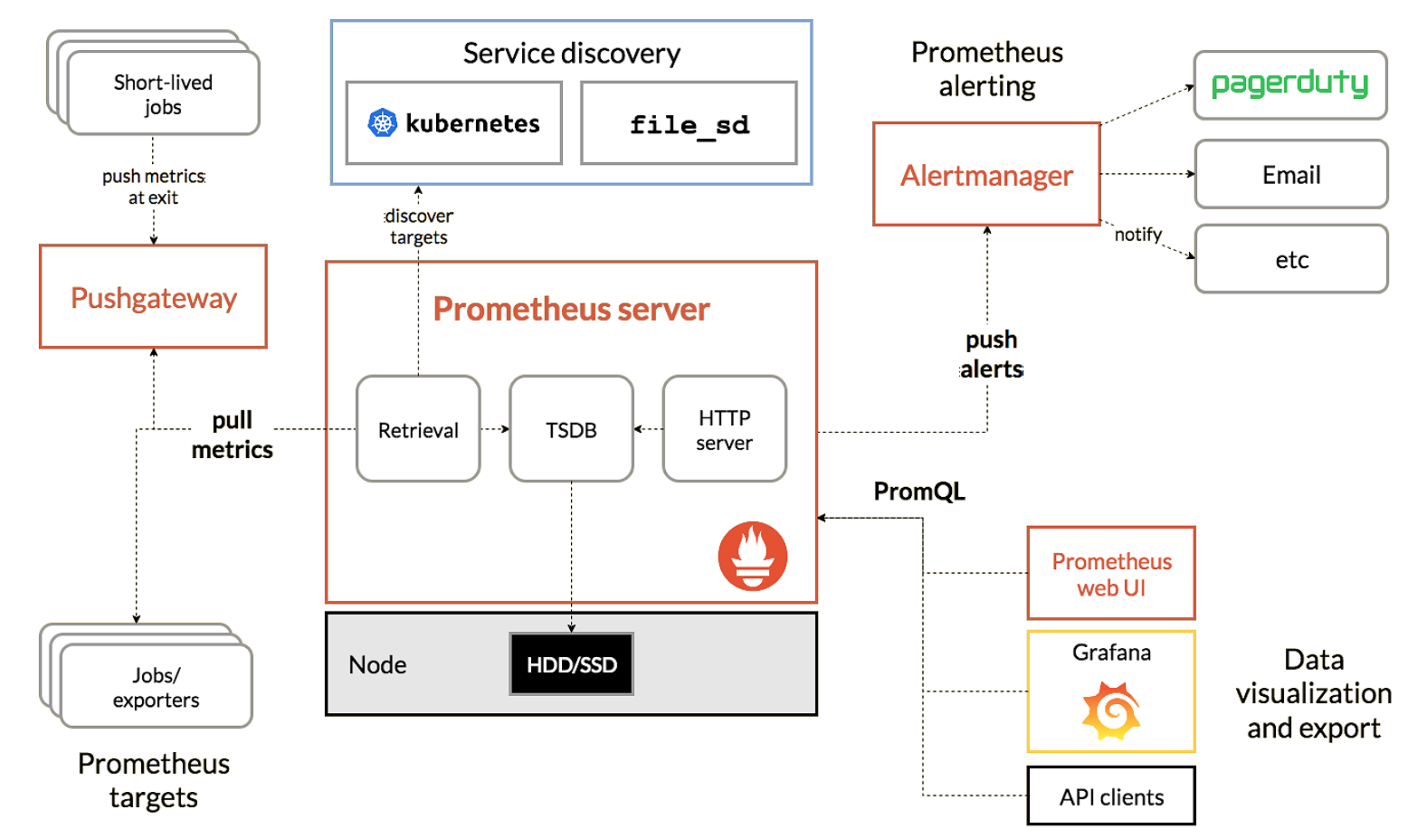
Prometheus优点:
- 对Kubernetes支持很好,目前看,Prometheus就是Kubernetes监控标配
- 生态庞大,有各种各样Exporter,支持各种时序库作为后端存储,也很好支持多种不同语言SDK,供业务代码嵌入埋点
缺点
- 易用性差些,如告警策略需要修改配置文件,协同起来比较麻烦。当然了,对于IaC落地较好的公司,反而认为这样更好,不过在国内当下的环境来看,还无法走得这么靠前,大家还是更喜欢用Web界面来查看监控数据、管理告警规则。
- Exporter参差不齐,通常是一个监控目标一个Exporter,管理起来成本比较高。
- 容量问题,Prometheus默认只提供单机时序库,集群方案需要依赖其他的时序库。
新一代国产代表 Nightingale
Nightingale 可看做 Open-Falcon 的一个延续,因为开发人员是一拨人,不过两个软件的定位截然不同,Open-Falcon 类似 Zabbix,更多的是面向机器设备,而Nightingale 不止解决设备和中间件的监控,也希望能一并解决云原生环境下的监控问题。
但 Kubernetes 环境下,Prometheus 已大行其道,再重复造轮意义不大,所以 Nightingale 是和 Prometheus 做良好的整合,打造更完备方案。当下的架构,主要是把 Prometheus 当成一个时序库,作为 Nightingale 的一个数据源。如果不使用 Prometheus 也没问题,如用 VictoriaMetrics 时序库。
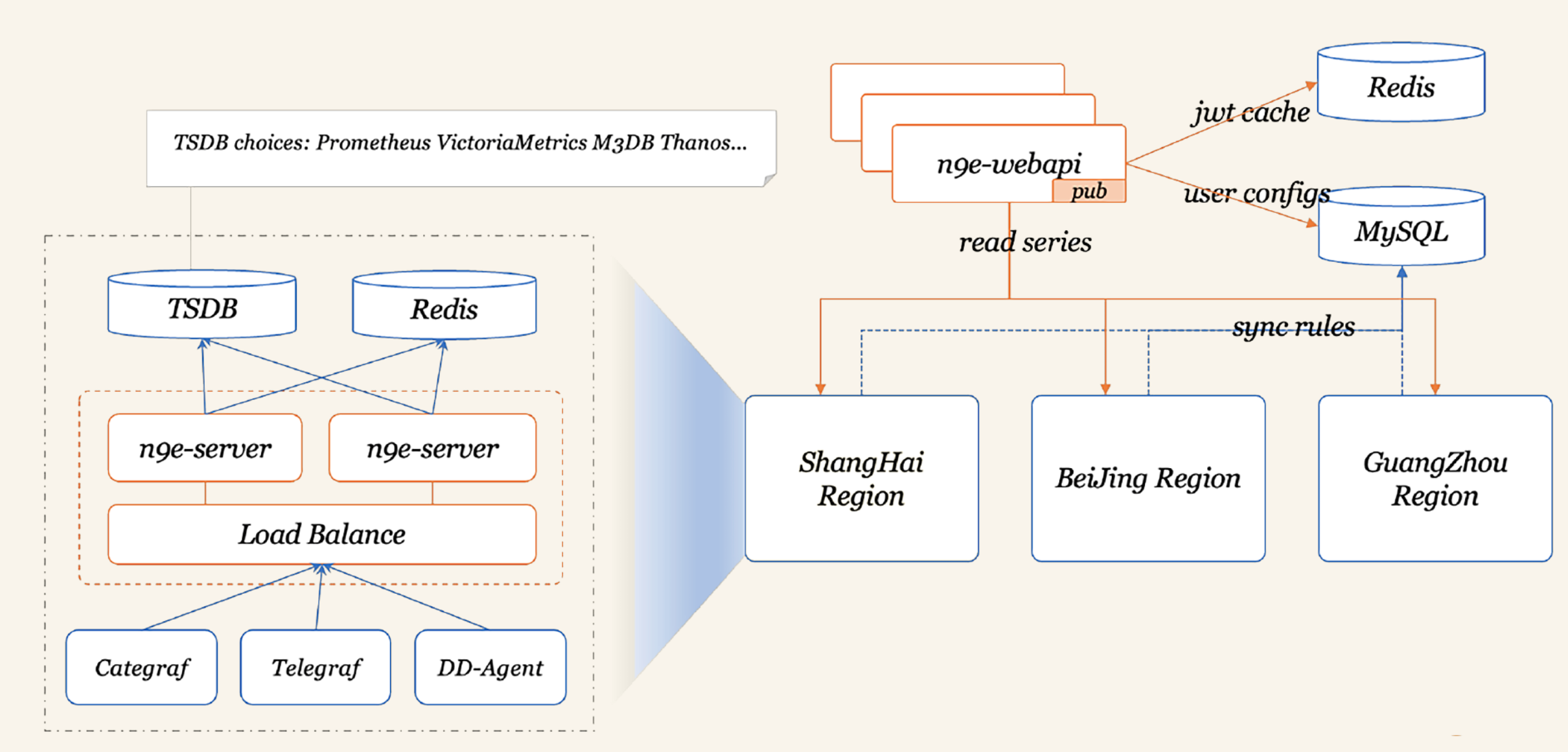
优点
- 有比较完备的UI,有权限控制,产品功能比较完备,可以作为公司级统一的监控产品让所有团队共同使用。Prometheus一般是每个团队自己用自己的,比较方便。如果一个公司用同一套Prometheus系统来解决监控需求会比较麻烦,容易出现我们上面说的协同问题,而Nightingale在协同方面做得相对好一些。
- 兼容并包,设计上比较开放,支持对接 Categraf、Telegraf、Grafana-Agent、Datadog-Agent 等采集器,还有Prometheus生态的各种Exporter,时序库支持对接 Prometheus、VictoriaMetrics、M3DB、Thanos 等。
缺点
- 考虑到机房网络割裂问题,告警引擎单独拆出一个模块下沉部署到各机房,但很多中小公司无需这么复杂架构,部署维护起来较麻烦
- 告警事件发送缺少聚合降噪收敛逻辑,官方解释是未来会单独做一个事件中心的产品,支持Nightingale、Zabbix、Prometheus等多种数据源的告警事件,但目前还没放出
如主要需求是监控设备,推荐Zabbix;如主要需求是监控Kubernetes,可选Prometheus+Grafana;如既兼顾传统设备、中间件监控场景,又兼顾Kubernetes做成公司级方案,推荐Nightingale。
4 总结
监控产品的需求来源,即监控问题域,从及时感知系统出现的问题,到现在希望预知问题,并可洞察业务经营数据,越来越多诉求让我们意识到监控重要性。
指标监控是可观测性三大支柱产品之一,日志监控和链路追踪三者联系紧密,共同辅助我们衡量系统内外部健康状况。指标监控因历史数据存储成本较低,实时性好,生态庞大,是可观测性领域里最重要的一根支柱,也是我们关注的重点。
最后对指标监控领域的多个开源解决方案横评对比,助技术方案选型。针对指标监控的几个开源方案的优缺点比较思维导图:

关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都国企技术专家兼架构,多家大厂后台研发和架构经验,负责复杂度极高业务系统的模块化、服务化、平台化研发工作。具有丰富带团队经验,深厚人才识别和培养的积累。
参考:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!