Linux环境docker安装Neo4j,以及Neo4j新手入门教学(超详细版本)
1、 图数据库Neo4j简介
1.1 什么是图数据库
图数据库:是基于图论实现的一种NoSQL数据库,其数据结构是和查询方式是以图论为基础的,图数据库主要用于存储更多的连接数据。
图论:用多个节点代表事物,用节点之间连线代表事务之间关系的图形。

1.2 能解决什么痛点
随着社交、电商、金融、零售、物联网等行业的快速发展,现实社会织起了了一张庞大而复杂的关系网,传统数据库很难处理关系运算。大数据行业需要处理的数据之间的关系随数据量呈几何级数增长, 急需一种支持海量复杂数据关系运算的数据库,图数据库应运而生。
使用场景:
- 社交领域:实现好友推荐等
- 电商领域:实现商品实时推荐等
- 金融领域:银行用图数据库做风控处理等
- ………………
1.3 对比关系型数据库
美国心理学家米尔格伦提出的“六度空间“理论:你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多六个人你就能够认识任何一个陌生人。
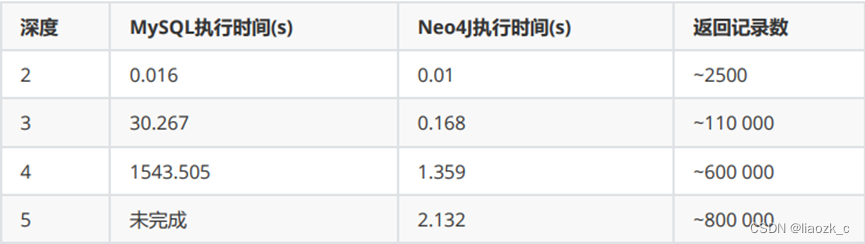
关系型数据库做法:一张用户表,一张用户和用户之间的关系表,每个人认识的没有一千也有八百,想找出想要的数据,每深入一层,难度成几何增长,但使用图数据库,难度大大降低。在关系型数据库和图数据库(Neo4j)之间进行了实验:在一个社交网络里找到最大深度为5的 朋友的朋友,他们的数据集包括100万人,每人约有50个朋友。
实验结果如下:
1.4 什么是Neo4j
Neo4j是一个开源的NoSQL图形数据库,2003 年开始开发,使用 scala和java 语言,2007年开始发布。是世界上最先进的图数据库之一,提供原生的图数据存储,检索和处理;采用属性图模型(Property graph model),极大的完善和丰富图数据模型;专属查询语言 Cypher,直观,高效;
Neo4j的特性:
- SQL就像简单的查询语言Neo4j CQL
- 它遵循属性图数据模型
- 它通过使用Apache Lucence支持索引
- 它支持UNIQUE约束
- 它包含一个用于执行CQL命令的UI:Neo4j数据浏览器
- 它支持完整的ACID(原子性,一致性,隔离性和持久性)规则
- 它采用原生图形库与本地GPE(图形处理引擎)
- 它支持查询的数据导出到JSON和XLS格式 它提供了REST API,可以被任何编程语言(如Java,Spring,Scala等)访问
- 它提供了可以通过任何UI MVC框架(如Node JS)访问的Java脚本 它支持两种Java API:Cypher API和Native Java API来开发Java应用程序
Neo4j的优点:
- 它很容易表示连接的数据
- 检索/遍历/导航更多的连接数据是非常容易和快速的
- 它非常容易地表示半结构化数据
- Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习
- 使用简单而强大的数据模型
- 它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有 连接或索引
1.5 Neo4j的构建元素
Neo4j图数据库主要有以下构建元素:
- 节点
- 属性
- 关系
- 标签
- 数据浏览器
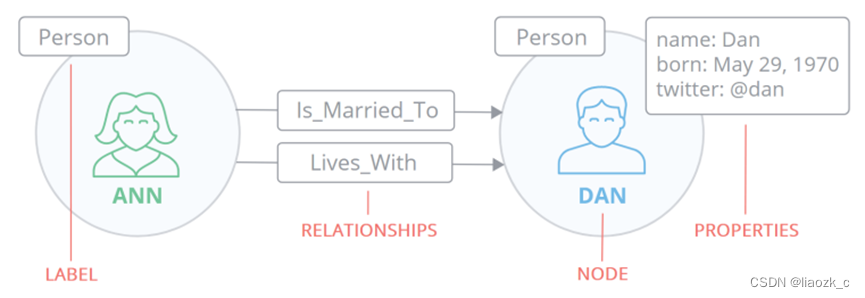
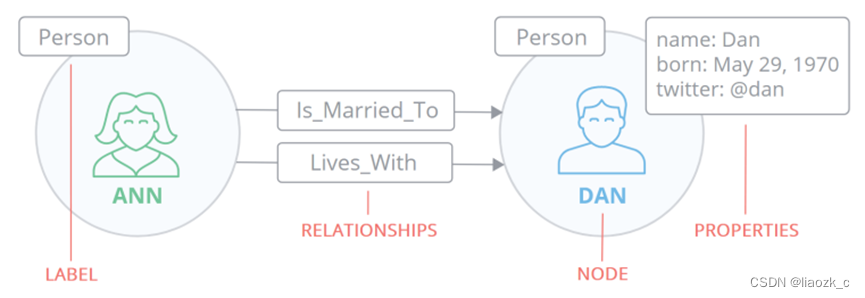
节点
- 节点(Node)是图数据库中的一个基本元素,用来表示一个实体记录,就像关系数据库中的一条记录一样。在Neo4j中节点可以包含多个属性(Property)和多个标签(Label)。
- 节点是主要的数据元素
- 节点通过关系连接到其他节点
- 节点可以具有一个或多个属性(即,存储为键/值对的属性)
- 节点有一个或多个标签,用于描述其在图表中的作用
属性
- 属性(Property)是用于描述图节点和关系的键值对。其中Key是一个字符串,值可以通过使用任何 Neo4j数据类型来表示
- 属性是命名值,其中名称(或键)是字符串
- 属性可以被索引和约束
- 可以从多个属性创建复合索引
关系
关系(Relationship)同样是图数据库的基本元素。当数据库中已经存在节点后,需要将节点连接起来 构成图。关系就是用来连接两个节点,关系也称为图论的边(Edge) ,其始端和末端都必须是节点,关系不 能指向空也不能从空发起。关系和节点一样可以包含多个属性,但关系只能有一个类型(Type) - 关系连接两个节点
- 关系是方向性的
- 节点可以有多个甚至递归的关系
- 关系可以有一个或多个属性(即存储为键/值对的属性)
基于方向性,Neo4j关系被分为两种主要类型:单向关系和双向关系
标签
标签(Label)将一个公共名称与一组节点或关系相关联,节点或关系可以包含一个或多个标签。 我们可以为现有节点或关系创建新标签,我们可以从现有节点或关系中删除标签。
标签用于将节点分组
- 一个节点可以具有多个标签
- 对标签进行索引以加速在图中查找节点
- 本机标签索引针对速度进行了优化
Neo4j Browser
一旦我们安装Neo4j,我们就可以访问Neo4j数据浏览器 http://localhost:7474/browser/
个人理解:
- 标签类似MySQL中的表
- 节点类似MySQL中的每行数据对象
- 属性类似MySQL中的每个字段
- 关系类似MySQL中关联表中的数据
2. 环境搭建
2.1 安装Neo4j Community Server
注意: neo4j 4.3及以上版本对应的java版本是jdk11
jdk8可以下载Neo4j Community Edition 3.5.28
下载:https://pan.baidu.com/s/1lvn55ZSUknaicVNdMblPEQ
提取码:8a54
文档:https://neo4j.com/docs/operations-manual/3.5/
进入到bin目录,执行 neo4j console
在浏览器中访问:http://localhost:7474
使用用户名neo4j和默认密码neo4j进行连接,然后会提示更改密码。
2.2 docker 安装Neo4j Community Server
注意需要开放以下端口:
- 7474 for HTTP
- 7473 for HTTPS
- 7687 for Bolt
拉取镜像
docker pull neo4j:3.5.22-community
运行镜像
docker run -d -p 7474:7474 -p 7687:7687 --name neo4j \
-e "NEO4J_AUTH=neo4j/123456" \
-v /usr/local/soft/neo4j/data:/data \
-v /usr/local/soft/neo4j/logs:/logs \
-v /usr/local/soft/neo4j/conf:/var/lib/neo4j/conf \
-v /usr/local/soft/neo4j/import:/var/lib/neo4j/import \
neo4j:3.5.22-community
2.3 Neo4j Desktop安装
下载地址:https://neo4j.com/download-center/
启动后可以选择安装本地neo4j数据库或者连接远程neo4j数据库。
3. Neo4j - CQL使用
3.1 Neo4j - CQL简介
Neo4j的Cypher语言是为处理图形数据而构建的,CQL代表Cypher查询语言。像Oracle数据库具有查询 语言SQL,Neo4j具有CQL作为查询语言。
- 它是Neo4j图形数据库的查询语言。
- 它是一种声明性模式匹配语言 它遵循SQL语法。
- 它的语法是非常简单且人性化、可读的格式。
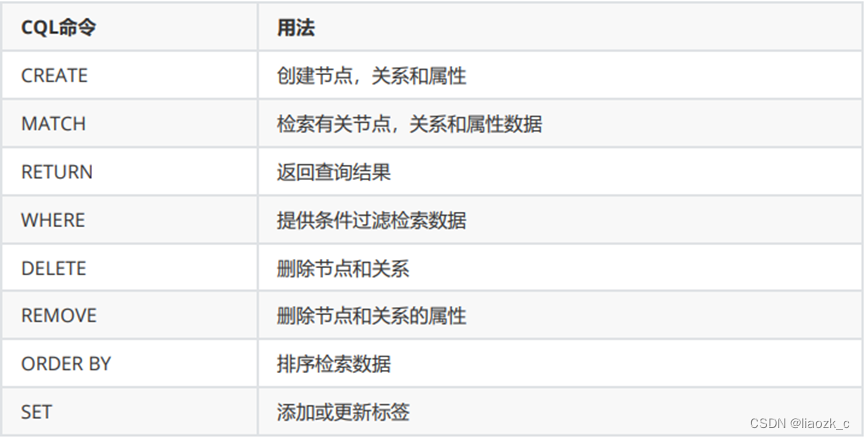
3.2 常用命令
官方英文文档:https://neo4j.com/docs/cypher-manual/3.5/clauses/
中文命令文档:https://www.w3cschool.cn/neo4j/neo4j_cql_match_command.html
CREATE创建
create语句是创建模型语句用来创建数据模型
创建节点
#创建带标签和属性的节点并返回节点
create (n:person {name:'如来'}) return n
创建关系
#使用新节点创建关系
CREATE (n:person {name:'杨戬'})-[r:师傅]->(m:person {name:'玉鼎真人'}) return type(r);
#使用已知节点创建带属性的关系
create (n:person {name:'沙僧'}) return n;
create (n:person {name:'唐僧'}) return n;
match (n:person {name:'沙僧'}),(m:person{name:'唐僧'})
create (n)-[r:`师傅`{relation:'师傅'}]->(m)
return r
#检索关系节点的详细信息
match (n:person)-[r]-(m:person) return n,m
创建全路径
create p=(:person{name:'蛟魔王'})-[:义兄]->(:person{name:'牛魔王'})<-[:义兄]- (:person {name:'鹏魔王'}) return p
MATCH查询
Neo4j CQL MATCH命令用于
- 从数据库获取有关节点和属性的数据
- 从数据库获取有关节点,关系和属性的数据
MATCH (n:person) RETURN n LIMIT 25
RETURN返回
Neo4j CQL RETURN子句用于
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
MATCH (n:person) RETURN id(n),n.name,n.tail,n.relation
WHERE子句
像SQL一样,Neo4j CQL在CQL MATCH命令中提供了WHERE子句来过滤MATCH查询的结果。
MATCH (n:person) where n.name='牛魔王' or n.name='唐僧' RETURN n
#创建关系
match (n:person),(m:person)
where n.name='唐僧' and m.name='如来'
create (n)-[r:BOSS]->(m)
return n.name,type(r),m.name
DELETE删除
Neo4j使用CQL DELETE子句
- 删除节点。
- 删除节点及相关节点和关系。
# 删除节点 (前提:节点不存在关系)
MATCH (n:person{name:"如来"}) delete n
# 删除关系
MATCH (n:person{name:"如来"})<-[r]- (m) delete r return type(r)
MATCH (n:person{name:"如来"})-[r]->(m) delete r return type(r)
MATCH (n:person{name:"如来"}) delete n
# 删除整个标签内容
match (n:person) detach delete n
REMOVE删除
有时基于客户端要求,我们需要向现有节点或关系添加或删除属性。我们使用Neo4j CQL REMOVE子句来删除节点或关系的现有属性。
- 删除节点或关系的标签
- 删除节点或关系的属性
#创建多个节点
create (a:person {name:"test111",age:20,sex:"男"}),
(b:person {name:"test222",age:30,sex:"女"}),
(c:person {name:"test333",age:40,sex:"男"})
return a,b,c
#删除属性
MATCH (n:person {name:"test111"}) remove n.age return n
#删除标签
match (m:person {name:"test222"}) remove m:person return m
SET子句
有时,根据我们的客户端要求,我们需要向现有节点或关系添加新属性。要做到这一点,Neo4j CQL提 供了一个SET子句。
- 向现有节点或关系添加新属性
- 添加或更新属性值
MATCH (n:person {name:"test111"}) set n.age=32 return n
ORDER BY排序
Neo4j CQL在MATCH命令中提供了“ORDER BY”子句,对MATCH查询返回的结果进行排序。
我们可以按升序或降序对行进行排序。默认情况下,它按升序对行进行排序。 如果我们要按降序对它们 进行排序,我们需要使用DESC子句。
#升序
MATCH (n:person) RETURN id(n),n.name order by id(n) asc
#降序
MATCH (n:person) RETURN id(n),n.name order by id(n) desc
UNION子句
与SQL一样,Neo4j CQL有两个子句,将两个不同的结果合并成一组结果
- UNION:它将两组结果中的公共行组合并返回到一组结果中。 它不从两个节点返回重复的行。
限制:结果列类型和来自两组结果的名称必须匹配,这意味着列名称应该相同,列的数据类型应该相同。 - UNION ALL:它结合并返回两个结果集的所有行成一个单一的结果集。它还返回由两个节点重复行。
限制:结果列类型,并从两个结果集的名字必须匹配,这意味着列名称应该是相同的,列的数据类型应该 是相同的。
MATCH (n:person) RETURN n.name as name
UNION
MATCH (m:person) RETURN m.name as name
MATCH (n:person) RETURN n.name as name
UNION all
MATCH (m:person) RETURN m.name as name
LIMIT和SKIP子句
Neo4j CQL已提供LIMIT子句和 SKIP 来过滤或限制查询返回的行数。
LIMIT返回前几行,SKIP忽略前几行。
# 前两行
MATCH (n:person) RETURN n.name limit 2
# 忽略前两行
MATCH (n:person) RETURN n.name SKIP 2
NULL值
Neo4j CQL将空值视为对节点或关系的属性的缺失值或未定义值。
当我们创建一个具有现有节点标签名称但未指定其属性值的节点时,它将创建一个具有NULL属性值的新节点。
match (n: person) where n.label is null return id(n),n.name,n.tail,n.label
IN操作符
与SQL一样,Neo4j CQL提供了一个IN运算符,以便为CQL命令提供值的集合。
match (n: person) where n.name in['沙僧','唐僧'] return id(n),n.name,n.tail,n.label
INDEX索引
Neo4j SQL支持节点或关系属性上的索引,以提高应用程序的性能。
我们可以为具有相同标签名称的所有节点的属性创建索引。
我们可以在MATCH或WHERE或IN运算符上使用这些索引列来改进CQL Command的执行。
Neo4J索引操作
- Create Index 创建索引
- Drop Index 丢弃索引
# 创建索引
create index on :person (name)
# 删除索引
drop index on : person (name)
UNIQUE约束
在Neo4j数据库中,CQL CREATE命令始终创建新的节点或关系,这意味着即使您使用相同的值,它也会 插入一个新行。 根据我们对某些节点或关系的应用需求,我们必须避免这种重复。像SQL一样,Neo4j数据库也支持对NODE或Relationship的属性的UNIQUE约束
UNIQUE约束的优点
- 避免重复记录。
- 强制执行数据完整性规则
#创建唯一约束
create constraint on (n:person) assert n.name is unique
#删除唯一约束
drop constraint on (n:person) assert n.name is unique
DISTINCT
这个函数的用法就像SQL中的distinct关键字,返回的是所有不同值。
match (n:person) return distinct(n.name)
3.3 常用函数
字符串函数
与SQL一样,Neo4J CQL提供了一组String函数,用于在CQL查询中获取所需的结果。
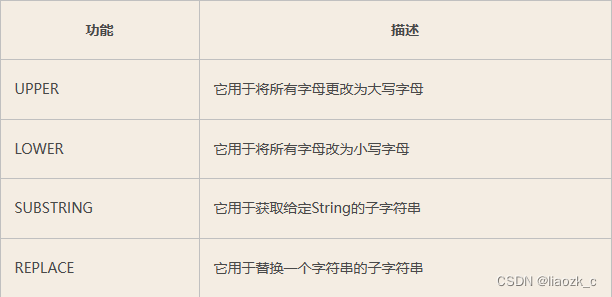
MATCH (e) RETURN id(e),e.name,substring(e.name,0,2)
AGGREGATION聚合
和SQL一样,Neo4j CQL提供了一些在RETURN子句中使用的聚合函数。 它类似于SQL中的GROUP BY 子句。
我们可以使用MATCH命令中的RETURN +聚合函数来处理一组节点并返回一些聚合值。
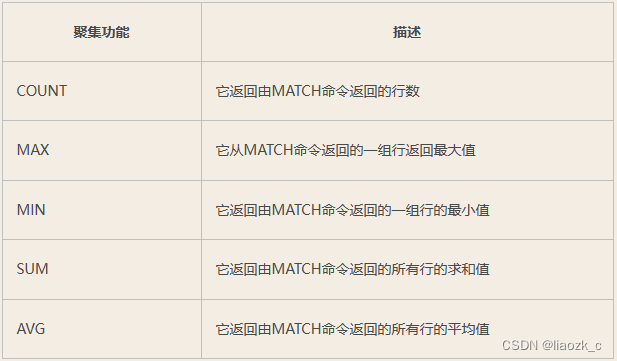
MATCH (e) RETURN count(e)
关系函数
Neo4j CQL提供了一组关系函数,以在获取开始节点,结束节点等细节时知道关系的细节。
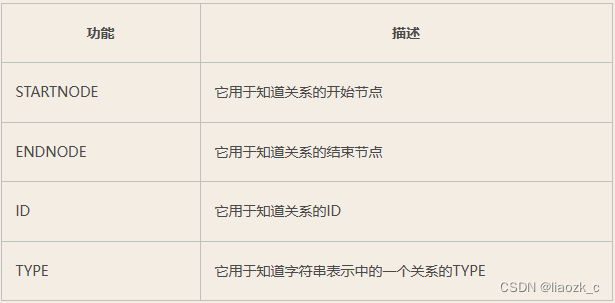
match (a)-[r] ->(b) return id(r),type(r)
3.4 neo4j-admin使用
数据库备份
对Neo4j数据进行备份、还原、迁移的操作时,要关闭neo4j
cd %NEO4J_HOME%/bin
#关闭
neo4j neo4j stop
#备份
neo4j-admin dump --database=graph.db --to=/neo4j/backup/graph_backup.dump
数据库恢复
还原、迁移之前 ,要关闭neo4j服务。
#数据导入
neo4j-admin load --from=/neo4j/backup/graph_backup.dump --database=graph.db – force
#重启服务
neo4j start
3.5 利用CQL构建西游关系图谱
远程文件地址:(文件放任意位置,配置Nginx之后能访问到就行)
#导入西游人物数据
load csv from 'http://124.223.79.77/neo4j/import/西游人物.csv' as line create (:西游人物 {name:line[0]})
#导入西游关系数据
load csv from 'http://124.223.79.77/neo4j/import/西游关系.csv' as line
create (:西游关系 {from:line[0],to:line[1],relation:line[3]})
#将两者之间的数据进行关联
match (a:`西游人物`),(b:`西游关系`),(c:`西游人物`)
where a.name=b.from and c.name=b.to
create (a)-[:人物关系{relation:b.relation}]->(c)
return a
#清空人物关系数据
match (a:`西游人物`)-[r]->(b) delete r return type(r)
本地文件地址:(文件放Neo4j的import目录下)
#导入西游人物数据
load csv from ''file:///西游人物.csv' as line create (:西游人物 {name:line[0]})
#导入西游关系数据
load csv from ''file:///西游关系.csv' as line
create (:西游关系 {from:line[0],to:line[1],relation:line[3]})
#将两者之间的数据进行关联
match (a:`西游人物`),(b:`西游关系`),(c:`西游人物`)
where a.name=b.from and c.name=b.to
create (a)-[:人物关系{relation:b.relation}]->(c)
return a
#清空人物关系数据
match (a:`西游人物`)-[r]->(b) delete r return type(r)
部分进阶语法
https://www.jianshu.com/p/5022b413ec3a
https://blog.csdn.net/liucy007/article/details/120967186
#shortestPath函数返回最短的Path
match p=shortestPath(
(a:`西游人物` {name:"秦琼"})-[*]-(b:`西游人物` {name:"孙悟空"})
)
return length(p),nodes(p)
#查看节点层级数据
match (a:`西游人物`{name:"唐僧"})<-[r:`人物关系`*1..4]-(b) return a,b,r
match (a:`西游人物`{name:"唐僧"})-[r:`人物关系`*1..4]->(b) return a,b,r
集成到spring boot 开源示例
https://gitee.com/JasonYangMeng/springdata-neo4j.git
附件:
文档中包含的附件获取方式:https://www.yuque.com/liaozk/hkmkrq/traam3ag3iy67gl7
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 鸿蒙开发DevEco Studio搭建
- npm ERR! Cannot read properties of null (reading ‘matches‘)
- 如何在 SwiftUI 中使用 AccessibilityCustomContentKey 修饰符
- 软件系统部署方案书(Word)
- mysql 数据编译安装以及参数说明 安装包下载
- YOLOv8算法改进【NO.100】引入最新发布AKConv
- 一文读懂 c++ 容器
- Apifox 最新更新:迭代分支功能上线、在线文档支持多格式导出!
- day05、关系模型之关系演算
- web worker的介绍和使用(包含使用案例)