ClickHouse数据仓学习笔记
什么是ClickHouse数据仓
简单的理解为多个数据库的归纳汇总,属于数据库管理系统的范畴,但是同时具有自己的存储引擎和数据格式(列式存储),一般适用于大数据场景。
ClickHouse是一个开源的列式数据库管理系统,特点是整个表结构会有大量的列来管理数据,表宽度比较大,传统的类似MySQL的数据结构被称为行式数据,比如:

而列式存储的结构的表现结构为:

可以看到随着数据的增加,整个表的宽度会比较大。
下图就是比较容易理解的行式数据和列式数据储存结构图。

这种列式存储的结构特点使得整个行数据再进行拆分,并且平行储存在磁盘中,查询时比方说id为排序主键,查询条件为id=100,先会在id列数据找到等于100满足条件的行,得到行号查询name,和age的行数据。在进行大数据查询的时候列式数据的查询效率会大大超过行式数据,可以理解为天然的垂直分表并且分的很细,查询时需要开启多个线程将多个查询语句并行执行并将结果返回协调节点进行合并数据。
特点:
支持SQL语句,以及DDL和DML语句,并且提供了TCP,Http,以及JDBC的接口进行操作,那么按理说可以使用MyBatis进行操作。因为是天然的垂直分表极致优化了查询速度,所以在面对频繁的插入和修改的场景并不是很适合。所以适用于对数据实时性不高的业务场景,ClickHouse更适合周期性的数据更行。比如说每天或者每周的数据批量导入。
小结:
给我的感觉如果说行式数据存储根据主键id可以获取该行不同的字段信息的话,那么列式储存获取查询的仅仅是某个字段的所有数据,插入时应该是需要先找到对应行字段在获取最后一个数据的id,进行插入,感觉上来说不是很合理,但是对于统计某个属性进行分析的场景来说应该效率更高。
严格区分大小写。
没有布尔类型,可以使用enum枚举来代替。
ClickHouse的Enum枚举
可以创建一个为enum类型字段boolean,值为true和
create table enum('true'=0,'false'=1) engine=TinyLog;然后在该表中只能插入true和false 曲线完成布尔
ClickHouse集成操作MySQL
在数据仓中操作数据可以使用sql语句
select data,COUNT(*) FROM mysql('host:port', 'database', 'table', 'user', 'password)在这里表明需要使用数据库的连接信息进行匹配。
Mybatis操作ClickHouse
- 配置ClickHouse的JDBC驱动程序依赖:
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.1</version>
</dependency>- 在MyBatis的配置文件中配置ClickHouse数据源:
<dataSource type="POOLED">
<property name="driver" value="ru.yandex.clickhouse.ClickHouseDriver"/>
<property name="url" value="jdbc:clickhouse://localhost:8123/my_database"/>
<property name="username" value="your_username"/>
<property name="password" value="your_password"/>
</dataSource>- 编写Mapper接口和XML映射文件,定义查询和操作ClickHouse的方法:
public interface ClickHouseMapper {
@Select("SELECT * FROM my_table WHERE id = #{id}")
MyTableEntity findById(@Param("id") int id);
@Insert("INSERT INTO my_table (id, name) VALUES (#{id}, #{name})")
void insert(MyTableEntity entity);
}<mapper namespace="com.example.ClickHouseMapper">
<resultMap id="MyTableEntityResultMap" type="com.example.MyTableEntity">
<id property="id" column="id"/>
<result property="name" column="name"/>
</resultMap>
<select id="findById" resultMap="MyTableEntityResultMap">
SELECT * FROM my_table WHERE id = #{id}
</select>
<insert id="insert">
INSERT INTO my_table (id, name) VALUES (#{id}, #{name})
</insert>
</mapper>Linux中的ClickHouse
操作文档
默认数据存储目录 /var/lib/clickhouse
该目录可以在/etc/clickhouse-server/config.xml中的<path>中进行配置
默认日志位置/var/log/clickhouse-server/
安装ClickHouse
安装ClickHouse入门 虚拟机centos单点安装,DBeaver连接方式,可视化界面_centos 安装dbeaver-CSDN博客
在Liunx中安装ClickHouse首先需要放开Linux下载文件的大小限制
vi /etc/security/limits.conf
vi /etc/security/limits.d/20-nproc.conf依次打开配置文件,按insert进入编辑模式,并且在配置文件末端添加配置:
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072按ctrl+c shift+:wq! 回车保存
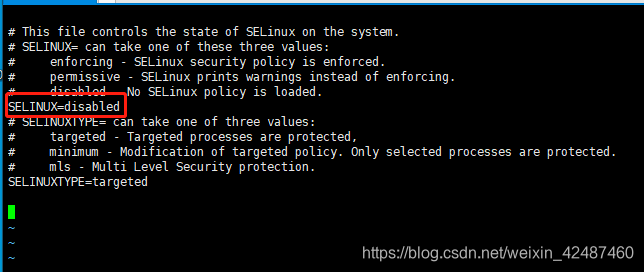
注意是两个文件都需要添加配置,放开文件数量的限制之后,取消SELINUX 这是Linux自带的安全系统
vi /etc/selinux/config修改 SELINUX=disable
重启服务器,可以使用命令 reboot 或者物理重启
关闭系统防火墙
systemctl stop firewalld
systemctl disable firewalld开始安装:
sudo yum install yum-utils libtool *unixODBC*
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
这两个库都可以试试 下面是官方的库
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
sudo yum install clickhouse-server clickhouse-client
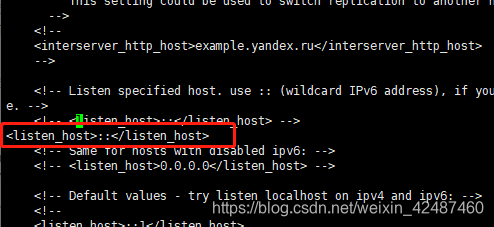
- 修改配置,便于外部连接
vi /etc/clickhouse-server/config.xml编辑内容,将<listen_host>::</listen_host>解开注释,并强制保存 这是只允许本机访问
启动服务
$ sudo /etc/init.d/clickhouse-server start启动时如果报错:Application: DB::ErrnoException: Could not calculate available disk space (statvfs), errno: 13, strerror: Permission denied
添加clickhouse用户到root用户组重新启动即可
usermod -a -G root clickhouse使用命令行操作ClickHouse
登录ClickHouse
无密码进入客户端
clickhouse-client密码登录客户端,命令输入之后键入defult用户密码。
clickhouse-client --password
或者使用
clickhouse-client --password -m 多行模式出现localhoust :) 说明连接成功,执行命令看看
select 1
说明连接成功
设置密码登录
cd /etc/clickhouse-server/
ll
vi users.xml找到密码按insert修改,然后ctrl+c,:wq! 保存退出。
<password>123456</password>重启clickhouse服务
systemctl restart clickhouse-server查看库
show databases建库进库删库
CREATE DATABASE IF NOT EXISTS test_wyp; --使用默认引擎建设数据库
use test_wyp --进入数据库
drop database test_wyp; --删除库查看表
show tables建表
create table t_order_rmt2(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
insert into t_order_rmt1 values
(101,
'sku_001',1000.00,
'2020-06-01 12:00:00'
),
(102,
'sku_002',2000.00,
'2020-06-01 11:00:00'
),
(102,
'sku_004',2500.00,
'2020-06-01 12:00:00'
),
(102,
'sku_002',2000.00,
'2020-06-01 13:00:00'
),
(102,
'sku_002',12000.00,
'2020-06-01 13:00:00'
),
(102,
'sku_002',600.00,
'2020-06-02 12:00:00'
);副本的使用
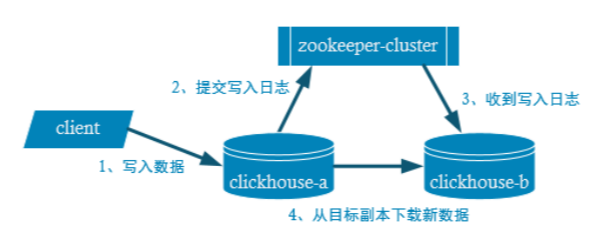
副本是为了高可用,客户端向表a写入数据,依赖zookeeper提交a写入数据,表b从a下载新数据。在副本中没有主从之分,互为副本,互相同步数据。
启动zookeeper
下载zookeeper
地址:Index of /dist/zookeeper/zookeeper-3.9.1
clickhouse要求3.4.5以上的zookeeper
zk.sh start指定zookeepr
方案一:内置指定zookeeper
进去clickhouse配置文件
vim /etc/clickhouse-server/config.xmlctrl+: 输入
/zookeeper搜索找到zookeeper标签指定zookeeper。
方案二:外置指定zookeeper (推荐)
进入配置文件夹
cd /etc/clickhouse/config.d创建配置文件,名字自定义,通常是叫这个。因为在/etc/clickhouse-server/config.xml配置文件中zokkeeper附近注释中默认读取的是etc/metrika.xml
vim metrika.xml<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>修改主机名,ctrl+:wq!保存退出。然后一定要注意修改文件所属用户和组为clickhouse:clickhouse 避免报错。
chown clickhouse:clickhouse metrika.xml
ll 查看文件所属用户和组这点一定不要忘记。
修改服务端配置,还是刚才的配置文件中进行修改读取自定义文件配置路径。
打开配置文件
vim /etc/clickhouse-server/config.xml
搜索zookepper
/zookeeper
打开文件行号
:set nu
按insert进入编辑模式
在719行<zookeeper>同级位置添加配置 新增标签
<zookeeper incl="zookeeper-servers" optional="true" /> 开启include_from标签
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
注意这里的文件名字和位置要和上面自定义的位置和名字一致shift+:wq! 保存退出。
将两个文件通过zookeeper操作同步到副本机
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.d/metrika.xm
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.xml重启两个副本
sudo clickhouse restart 这样就搞定了副本,但是副本只能同步数据,不能同步表结构,所以需要在每个副本机上手动建表:
注意的是rep_102为副本名 必须不一样
/clickhouse/table/01/t_order_rep 是zookeeper的地址路径
zookeeper地址命名规范:数据仓/表/分片/表名
①hadoop102
create table t_order_rep2 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_102')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
②hadoop103
create table t_order_rep2 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_103')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);ClickHouse分片集群部署
打开从机的文件数量限制
关闭防火墙
关闭自带安全中心selinux
从机安装clickhouse
修改配置文件放开允许他机访问
新建etc/metrika.xml --这是集群强制要求
<yandex> <!--公司名-->
<clickhouse_remote_servers>
<perftest_3shards_1replicas> <!--可以自定义-->
<shard> <!--分片-->
<internal_replication>true</internal_replication><!--是否开启自动复制-->
<replica> <!--副本-->
<host>n1</host> <!--副本名-->
<port>9000</port> <!--默认端口-->
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>n2</host>
<port>9000</port>
</replica>
</shard>
</perftest_3shards_1replicas>
</clickhouse_remote_servers>
<zookeeper-servers> <!--高可用-->
<node index="1">
<host>n1</host>
<port>2181</port>
</node>
<node index="2">
<host>n2</host>
<port>2181</port>
</node>
<node index="3">
<host>n3</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros> <!--每台机器不一样 本节点主机名 记住每个节点不一样-->
<replica>n1</replica>
</macros>
<!--<networks> --> <!-- 是否允许远程连接-->
<!-- <ip>::/0</ip> -->
<!--</networks> -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
如果配置了zookeper需要开启zookeeper,没有就把zookeeper干掉。
启动主机和从机的ClickHouse
使用命令查询集群
select * from system_clusters集群成功后自动加入数据库。
数据类型
int8 -- byte
int16 -- short
int32 -- int
int64 -- long
float32 -- float
float64 -- double
布尔 没有布尔 可以使用Uint8 ,0和1表示,或者enum
Decimal32 -- 精度9位,比如123.456789
Decimal64 -- 精度18位
Decimal128 -- 精度38位
String -- 普通字符串
FixedString() -- 固定长度
Enum -- 枚举
表引擎
ClickHouse中每个表都必须需要指定引擎。engine=TinyLog 严格区分大小写。默认表和表数据存储在/var/lib/clickhouse data是数据,medate是元数据表结构。
TinyLog
存在磁盘中默认/var/clickhouse,小数据量,不支持索引,没有并发控制。适用于小表和查询。增删改几乎不发生,比如国家表。
Memory
记忆内存,基于内存,快,和TinyLog不同的是存内存中,当前启动有效,重启服务清空,特点是快。每秒10G。上限一亿条数据。不支持索引。
Merge
合并引擎,本身不存数据,用来合并其他表的数据,不支持写入数据。创建时需要设置参数,一个数据库名和一个正则表达式。只针对当前数据库中符合正则表达式的数据。会自动合并显示。支持查询。
MergeTree(重点)
合并树,最强大的引擎,类似一个管理员,用来维护管理merge。
建表语句:创建一个名为table t_order_mt的表,mt表示引擎。指定字段,引擎,分区根据字段,主键,排序根据。
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);插入数据:
insert into t_order_mt values
(101,
'sku_001',1000.00,
'2020-06-01 12:00:00'
) ,
(102,
'sku_002',2000.00,
'2020-06-01 11:00:00'
),
(102,
'sku_004',2500.00,
'2020-06-01 12:00:00'
),
(102,
'sku_002',2000.00,
'2020-06-01 13:00:00'
),
(102,
'sku_002',12000.00,
'2020-06-01 13:00:00'
),
(102,
'sku_002',600.00,
'2020-06-02 12:00:00'
);使用 show tables 展示效果
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘可以看到数据根据创建时间进行了分片存放,并且在同一分片中按照id进行排序。使用可视化工具查看是没有分区的效果的。
注意:
需要注意主键不具备唯一性。并且主键并不是必须的。在clickhouse中是稀疏索引。
分区也不是必须的,分区主要是为了优化查询,避免全表扫描。如果不写分区依据默认使用all,所有数据都会在一起。一般来说建议使用按天分区。分区由分区键进行区分。
但是order by是必须的。
ReplacingMergeTree
变种合并树,多一个去重功能,但是去重不是实时的,只有在合并时进行去重。所以在生产中需要注意这一点,要进行实时去重需要百度相应方案,只保证最终一致性,并且只在分区内进行数据去重,使用时依然是指定engine表引擎。
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);参数为版本字段。
插入两次数据:
insert into t_order_rmt values
(101,
'sku_001',1000.00,
'2020-06-01 12:00:00'
) ,
(102,
'sku_002',2000.00,
'2020-06-01 11:00:00'
),
(102,
'sku_004',2500.00,
'2020-06-01 12:00:00'
),
(102,
'sku_002',2000.00,
'2020-06-01 13:00:00'
),
(102,
'sku_002',12000.00,
'2020-06-01 13:00:00'
),
(102,
'sku_002',600.00,
'2020-06-02 12:00:00'
);查询
select * from t_order_rmt
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
手动合并...
optimize table t_order_mt3 final
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
数据写入和合并
任何数据的写入都会产生临时分区,异步进行合并操作。举例,再次插入一样的数据:
insert into t_order_mt values
(101,
'sku_001',1000.00,
'2020-06-01 12:00:00'
) ,
(102,
'sku_002',2000.00,
'2020-06-01 11:00:00'
),
(102,
'sku_004',2500.00,
'2020-06-01 12:00:00'
),
(102,
'sku_002',2000.00,
'2020-06-01 13:00:00'
),
(102,
'sku_002',12000.00,
'2020-06-01 13:00:00'
),
(102,
'sku_002',600.00,
'2020-06-02 12:00:00'
);show tables
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘可以看到新增加的数据又生成了新的分区。大概15分钟后会进行异步合并数据并且清理该分区。
primary key 主键介绍(可选)
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);上面建表时指定的主键字段为id,但是在clickhouse中主键是可与重复的没有唯一约束。并且被称之为稀疏索引,比方说id记录123456789,稀疏索引可能只会记录369,当你查询id为5的时候使用二分查找定位3-6之间的数据进行查找。
order by 排序介绍(必选)
比主键还重要,因为使用稀疏索引必须保证数据有序才可以建立跳数索引进行二分查找。所以在建表时order by 是必须的。并且排序必须为主键的第一个字段。主键可以有两个字段,允许重复。
二级索引
在跳数索引的基础上增加一次索引,比方说123456789跳数索引建立13479,二级索引建立为[1,4] [4,9] 将5个索引又分一次。增加查询速度。
数据列级TTL
数据列的生命周期功能,这是Clickhouse对数据建立过期删除时间,可以在建表的时候添加TTL语句指定字段,字段要求必须是日期类型,不能是主键。
创建测试表指定字段total_amount在 create_time10秒后过期。
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);插入数据
insert into t_order_mt3 values
(106,
'sku_001',1000.00,
'2023-11-07 16:19:30'
),
(107,
'sku_002',2000.00,
'2023-12-07 16:19:30'
),
(110,
'sku_003',600.00,
'2023-11-07 16:19:30'
);合并一下
optimize table t_order_mt3 final查询一下
select * from t_order_mt3
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 106 │ sku_001 │ 1000 │ 2023-11-07 16:04:30 │
│ 107 │ sku_002 │ 2000 │ 2023-11-07 16:04:30 │
│ 110 │ sku_003 │ 600 │ 2023-11-07 16:04:30 │
└─────┴─────────┴──────────────┴─────────────────────┘
等待过期...
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 106 │ sku_001 │ 0 │ 2023-11-07 16:04:30 │
│ 107 │ sku_002 │ 0 │ 2023-11-07 16:04:30 │
│ 110 │ sku_003 │ 0 │ 2023-11-07 16:04:30 │
└─────┴─────────┴──────────────┴─────────────────────┘清空total_amount的值条件就是系统时间达到─create_time的后10秒。
执行以下语句
数据表级TTL
这句语句会在创建时间后10秒对整表进行删除,影响整张表。
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
能够使用的时间周期:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机毕业设计 | springboot 图书商城(附源码)
- 【JS】Object.defineproperty方法
- 前端-关于移动端适配,你必须要知道的
- LeetCode 每日一题 Day 16 || 二分
- UTONMOS:前所未有的元宇宙游戏体验
- 知网查重链接(知网个人版)
- 阿赵UE学习笔记——解决UE资源不能正常显示缩略图的问题
- Java多线程&并发篇----第二十一篇
- Android--Jetpack--WorkManager详解
- C语言之枚举类型