人体姿态识别(附教程+代码)

人体姿态识别(Human Pose Estimation)是一种基于计算机视觉和深度学习的技术,用于自动检测和识别人体的姿态和动作。它可以在图像或视频中准确地确定人体各个关节的位置和运动。
人体姿态识别技术具有广泛的应用领域。在健身和运动领域,人体姿态识别可以帮助跟踪和纠正运动姿势,提供更高效、精确的训练指导。在医疗领域,它可以用于康复治疗、姿势评估等方面。在安防领域,人体姿态识别可以用于行为分析、异常检测等用途。
人体姿态识别的实现通常基于深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN)。首先,通过训练模型使用大量标记的姿势数据,模型能够学习到人体各个关节的特征表示。然后,当输入一张图像或视频时,模型会对每个关节进行定位和跟踪,进而恢复出人体的姿态。
为了实现更准确的姿态识别,研究人员还提出了一些改进技术。例如,引入上下文信息、多尺度特征融合、姿势关系建模等方法,以提高模型的鲁棒性和准确性。
总之,人体姿态识别是一项具有重要应用前景的技术。通过准确地检测和识别人体的姿态和动作,它可以在健身、医疗、安防等领域发挥重要作用,为人们的训练、康复和安全提供有效支持。
模型效果
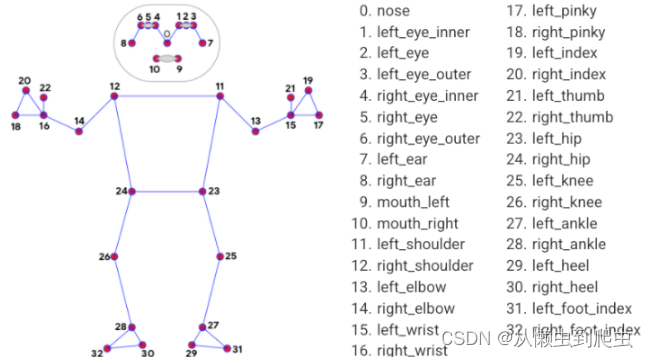
从下图可以清楚的看到,提出的模型可以对人眼以及嘴巴进行描述。
最终的是对每个关节点进行了划分和表示。
前言
从视频中进行人体姿势估计在各种应用中都扮演着关键角色,例如量化身体锻炼、手语识别和全身手势控制。例如,它可以成为瑜伽、舞蹈和健身应用的基础。它还可以在增强现实中将数字内容和信息覆盖在物理世界之上。
模型介绍
提出的人体识别模型是一种高保真度的身体姿势跟踪机器学习解决方案,可以从RGB视频帧中推断出整个身体的33个3D标记和背景分割掩码,利用先前BlazePose研究,该研究还为ML Kit Pose Detection API提供支持。值得注意的是,目前最先进的方法主要依赖于强大的桌面环境进行推断,而我们的方法可以在大多数现代手机、桌面/笔记本电脑上实现实时性能,甚至在Python和Web上也可以使用可谓是功能十分强大!
算法介绍
这个解决方案利用了一种两步探测器-跟踪器机器学习流程,决方案中已经被证明是有效的。使用探测器,该流程首先定位帧内的人/姿势感兴趣区域(ROI)。然后,跟踪器使用ROI裁剪帧作为输入,在ROI内预测姿势标记和分割掩码。请注意,对于视频用例,只有在需要时才会调用探测器,即在第一帧和跟踪器无法在上一帧中识别身体姿势存在时。对于其他帧,该流程只需从上一帧的姿势标记中派生ROI。
模型
人物/姿势检测模型(BlazePose检测器)
该检测器受我们自己的轻量级BlazeFace模型的启发,该模型用作MediaPipe面部检测的代理人物检测器。它明确预测另外两个虚拟关键点,以牢固描述人体的中心、旋转和比例,形成一个圆。灵感来自于达·芬奇的《维特鲁威人》,我们预测一个人的臀部中点、围绕整个人的圆的半径以及连接肩膀和臀部中点的线的倾斜角度。
?
算法代码
核心代码部分?顺便看下效果

?支持的配置选项:
static_image_mode(静态图像模式)
model_complexity(模型复杂度)
smooth_landmarks(平滑标记点)
enable_segmentation(启用分割)
smooth_segmentation(平滑分割)
min_detection_confidence(最小检测置信度)
min_tracking_confidence(最小跟踪置信度)
?
with mp_pose.Pose(
#全部代码----->q1309399183<---------
static_image_mode=True,
model_complexity=2,
enable_segmentation=True,
min_detection_confidence=0.5) as pose:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
image_height, image_width, _ = image.shape
# Convert the BGR image to RGB before processing.
results = pose.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
if not results.pose_landmarks:
continue
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * image_height})'
)
QQ767172261算法结论和效果展示
该流程是作为一个e图实现的,它使用了姿势标记模块中的姿势标记子图,并使用专用的姿势渲染器子图进行渲染。姿势标记子图在内部使用了姿势检测模块中的姿势检测子图。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java实战之每日海报
- NAS系统折腾记 – 系统的选择: QNAP vs Synology
- 【Py/Java/C++三种语言OD2023C卷真题】20天拿下华为OD笔试之【哈希表】2023C-跳房子I【欧弟算法】全网注释最详细分类最全的华为OD真题题解
- 基于java的SSM框架实现在线投稿网站系统项目【项目源码+论文说明】计算机毕业设计
- 基于FreeRTOS的STM32和IMX6ULL异构处理器系统设计与实现
- Android亮度调节的几种实现方法
- git stash 命令详解
- UTF8在windows控制台乱码问题
- K2P路由器刷OpenWrt官方最新版本固件OpenWrt 23.05.2方法 其他型号的智能路由器OpenWrt固件刷入方法也基本上适用
- 《操作系统A》期末考试复习题——大题51-62(手写笔记)