Python:最简单的神经网络分类模型(附带详细注释说明)+ 训练结果可视化+ 模型可视化
发布时间:2024年01月19日
# 神经网络的搭建--分类任务 #
# PyTorch由4个主要包装组成:
# 1.Torch:类似于Numpy的通用数组库,可以在将张量类型转换为(torch.cuda.TensorFloat)并在GPU上进行计算。
# 2.torch.autograd:用于构建计算图形并自动获取渐变的包
# 3.torch.nn:具有共同层和成本函数的神经网络库
# 4.torch.optim:具有通用优化算法(如SGD,Adam等)的优化包
import torch # 深度学习库
import matplotlib.pyplot as plt # 画图用的库函数
import torch.nn.functional as F # 激励函数都在这
import numpy as np
# x0,x1是数据,y0,y1是标签
n_data = torch.ones(100, 2) # 数据的基本形态:100*2的二维张量(tensor)
x0 = torch.normal(2 * n_data, 1) # 样本类型0 x data (tensor), shape=(100, 2), normal() 生成均值=2,标准差=1的正态分布的随机数
y0 = torch.zeros(100) # 样本类型0 y data (tensor), shape=(100, )
x1 = torch.normal(-2 * n_data, 1) # 样本类型1 x data (tensor), shape=(100, 1), normal() 生成均值=-2,标准差=1的正态分布的随机数
y1 = torch.ones(100) # 样本类型1 y data (tensor), shape=(100, )
# 注意 x, y 数据的数据形式是一定要像下面一样 (torch.cat 是在合并数据)
# torch.cat((x0, x1), dim = 0) 按行拼接
# torch.cat((x0, x1), dim = 1) 按列拼接
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # FloatTensor = 32-bit floating
y = torch.cat((y0, y1), 0).type(torch.LongTensor) # LongTensor = 64-bit integer
# x.data.numpy()将张量转换为与其共享底层存储的 n 维 numpy 数组
# c:表示的是色彩或颜色序列,s:表示的是大小,是一个标量或者是一个shape大小为(n,)的数组,cmap:Colormap,标量或者是一个colormap的名字,cmap仅仅当c是一个浮点数数组的时候才使用
# plt.scatter()函数解析(最清晰的解释):https://blog.csdn.net/TeFuirnever/article/details/88944438
plt.figure(1)
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.show() # 图形显示
# 建立神经网络
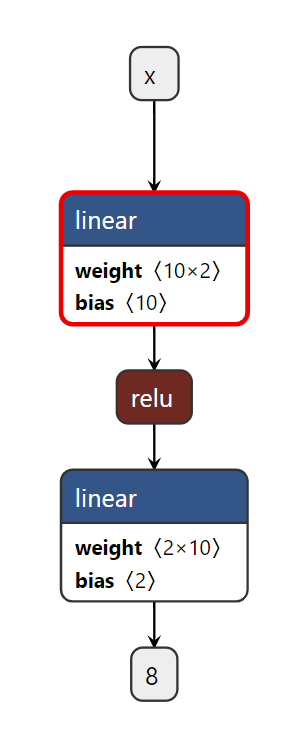
class Net(torch.nn.Module): # 继承 torch 的 Module,它是所有的神经网络的根父类! 你的神经网络必然要继承
def __init__(self, n_feature, n_hidden, n_output): # n_feature=特征数量, n_hidden=隐藏层个数, n_output=类别数量
super(Net, self).__init__() # 继承 __init__ 功能
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐藏层线性输出
self.out = torch.nn.Linear(n_hidden, n_output) # 输出层线性输出
def forward(self, x): # 正向传播输入值, 神经网络分析出输出值
x = F.relu(self.hidden(x)) # ReLU激励函数(隐藏层的线性值)
x = self.out(x) # 输出值, 但是这个不是预测值, 预测值还需要再另外计算
return x
net = Net(n_feature=2, n_hidden=10, n_output=2) # 几个类别就几个 output
# 训练网络
# 算误差的时候, 注意真实值不是one-hot形式的, 而是1D Tensor, (batch,),但是预测值是2D tensor (batch, n_classes)
# torch.optim是实现各种优化算法的包,学习率lr=0.02
# SGD 就是随机梯度下降 opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
# momentum 动量加速,在SGD函数里指定momentum的值即可 opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
# RMSprop 指定参数alpha ,opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
# Adam 参数betas=(0.9, 0.99),opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
# torch.nn.CrossEntropyLoss交叉熵损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
loss_func = torch.nn.CrossEntropyLoss()
plt.figure(2)
plt.ion() # 动态画图窗口
plt.show()
lossAll = []
for t in range(100): # 训练100次
out = net(x) # 喂给 net 训练数据 x, 输出分析值
loss = loss_func(out, y) # 计算两者的误差
lossAll.append(loss.data.numpy())
optimizer.zero_grad() # optimizer.zero_grad() 清空过往梯度;
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新网络参数
# 可视化展示
if t % 2 == 0:
plt.cla() # 清除figure(2)的内容
# SoftMax:https://blog.csdn.net/weixin_43643082/article/details/134731130
# F.softmax(input, dim=0) # 按列SoftMax,列和为1
# F.softmax(input, dim=1) # 按行SoftMax,行和为1
# torch.max(input, dim=0) # 按列取max
# torch.max(input, dim=1) # 按行取max
prediction = torch.max(F.softmax(out), 1)[1] # 过了一道 softmax 的激励函数后的最大概率才是预测值
# np.squeeze()函数可以删除数组形状中的单维度条目,即把shape中为1的维度去掉,但是对非单维的维度不起作用
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = sum(pred_y == target_y) / 200. # 计算准确度
plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff() # 停止画图
plt.show()
lossAll = np.array(lossAll)
plt.figure(3)
plt.plot(range(lossAll.size), lossAll,
marker='o', # 标记样式:圆点
linestyle='-', # 线条样式:实线
color='green', # 线条颜色:蓝色
linewidth=2, # 线宽:2
markersize=10)
plt.title('Loss')
plt.show()
import netron
scripted_model = torch.jit.script(net) # 保存模型
torch.jit.save(scripted_model, '.net.pth')
netron.start('.net.pth') # 可视化
https://blog.csdn.net/qq_37333048/article/details/110479438
文章来源:https://blog.csdn.net/jane0819/article/details/135695251
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一个超强的 python GUI 库
- 12.28数算编程专练
- SQL的联合主键
- docker安装ElasticSearch
- Android Framework | AOSP源码下载及编译指南(基于Android13)
- 恢复.EKING勒索病毒加密数据:数据安全的必备知识
- 安装miniconda、tensorflow、libcudnn
- Tensorflow2.0笔记 - Tensor的数据索引和切片
- MySQL面试题
- android 使用GSON 序列化对象出现字段被优化问题解决方案