Mysql面试题
发布时间:2023年12月21日
题外话:
update是行锁吗?
答:update的话其实mysql中有不同的引擎,myisam只有表锁,innodb的话,其实也不一定是行锁,要看这个字段有没有索引,没有的话就是表锁,有索引的话那就是行锁,当然也可能是行锁的x锁啊、间隙锁啊,要看这个字段存在不存在。
1. Mysql用的b+树为什么不用b树
b树它其实非叶子节点也会存储数据,而b+只会在叶子节点存储数据,那这样其实b+树效率更高一点,因为其实我们查的话都是要先将磁盘中的数据页加载进来,b+树的话它存的都是有用的东西,都是目录项嘛,而b树它会有一些用不到的信息,因为它还会存储当前节点的key的数据,那相当于b+树就变相的减少了磁盘的读入,磁盘操作是比较耗时的,另外的话其实索引也是有序的,b+树定位到叶子节点后,那如果范围查询的话因为每个数据页也是有双向链表的,范围的定位的话都在一块,所以一个一个读就可以,b树的话因为它非叶子节点也会存数据,导致这种范围查询的话没有b+树性能好。
2. Mysql超大分页怎么处理



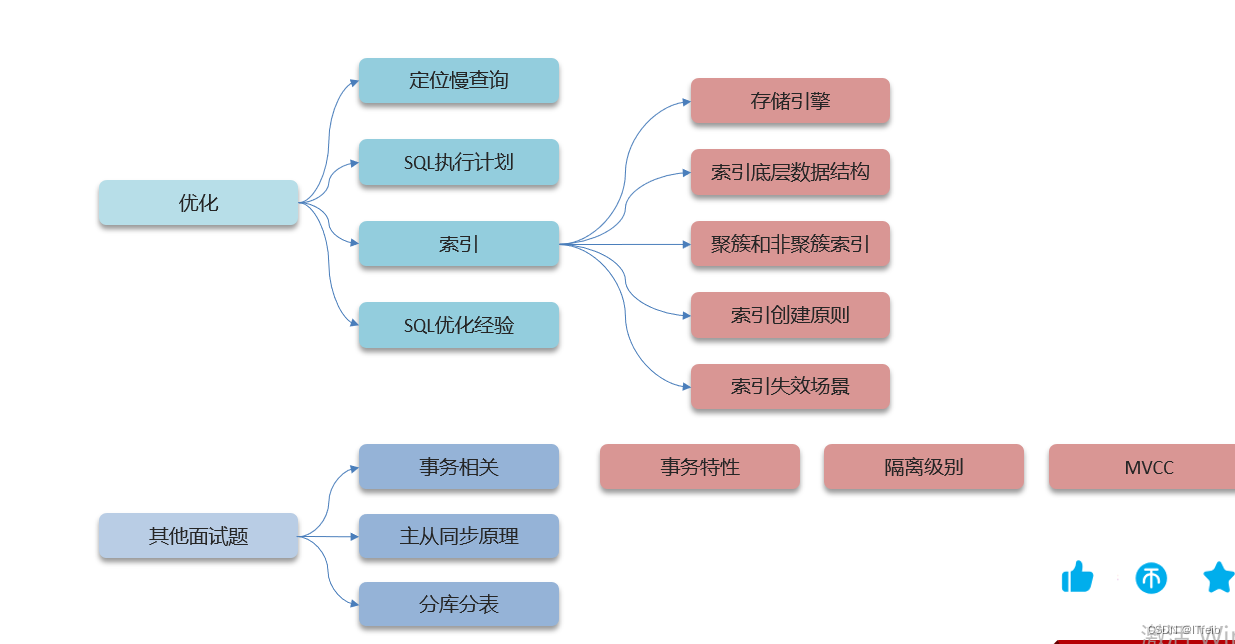
3. 索引创建原则

4. 索引失效

5. 谈谈你对sql的优化的经验


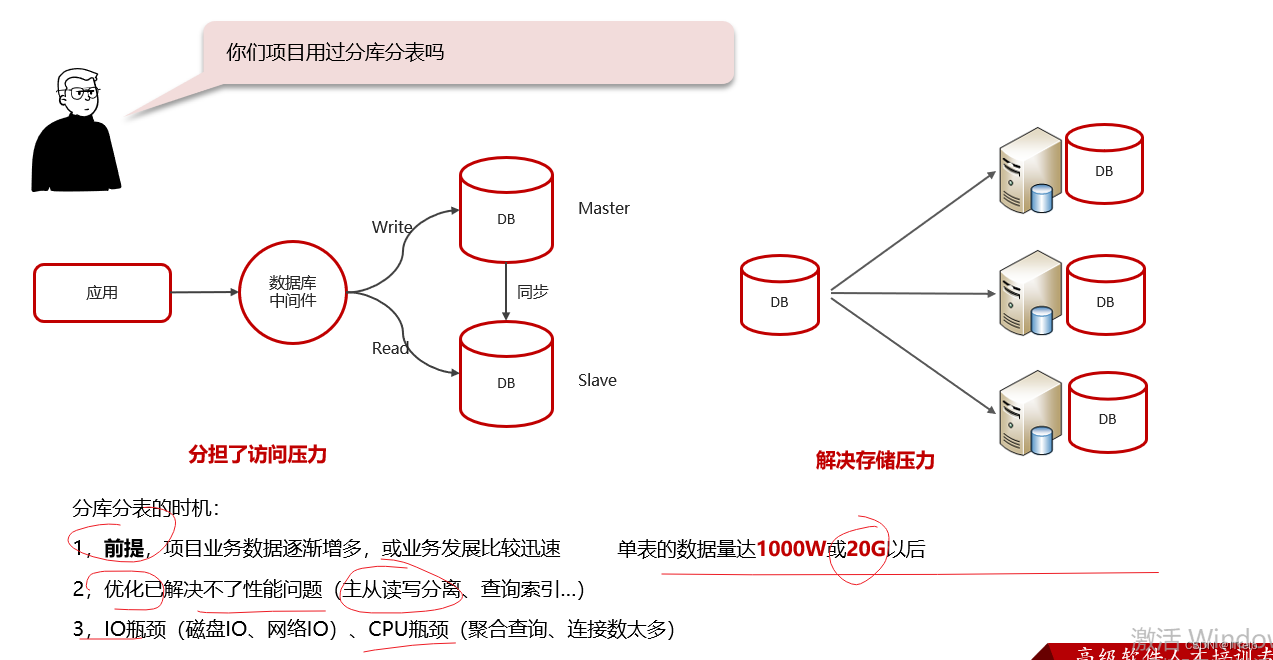
6. 分库分表了解过吗
主要用的多的是
垂直分库:微服务
垂直分表:冷热数据分离
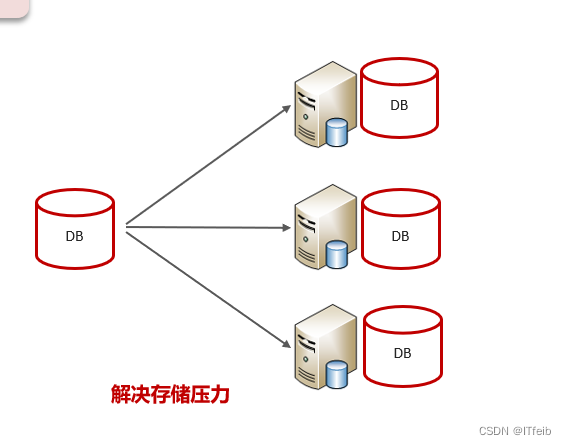
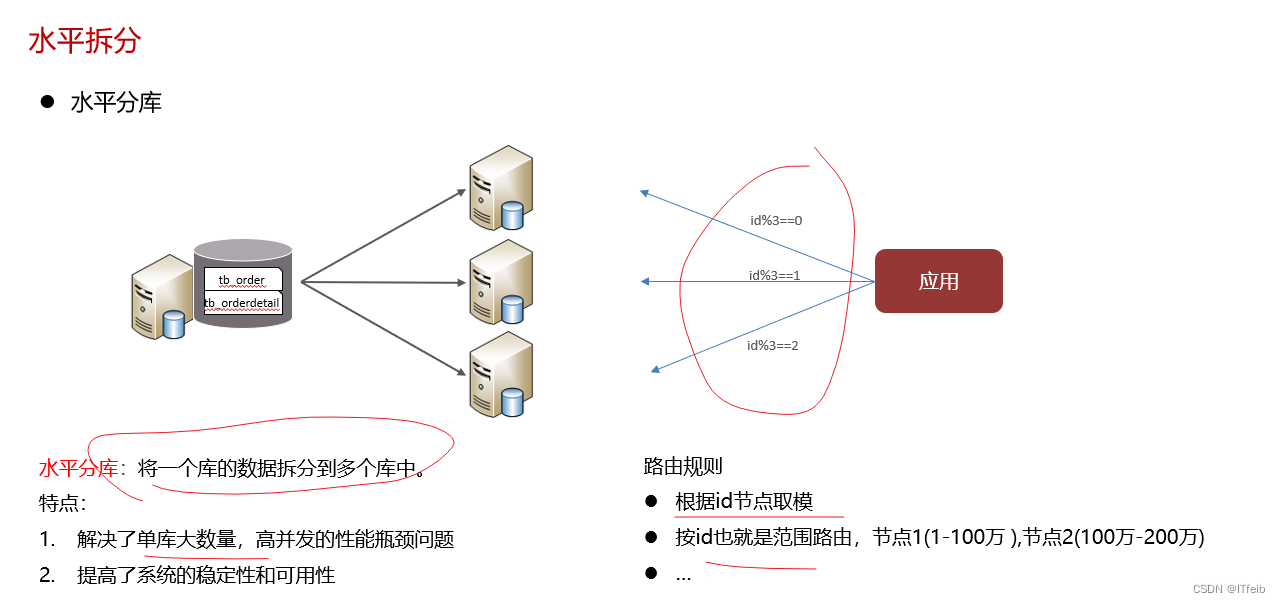
水平分库:将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题。
垂直分库: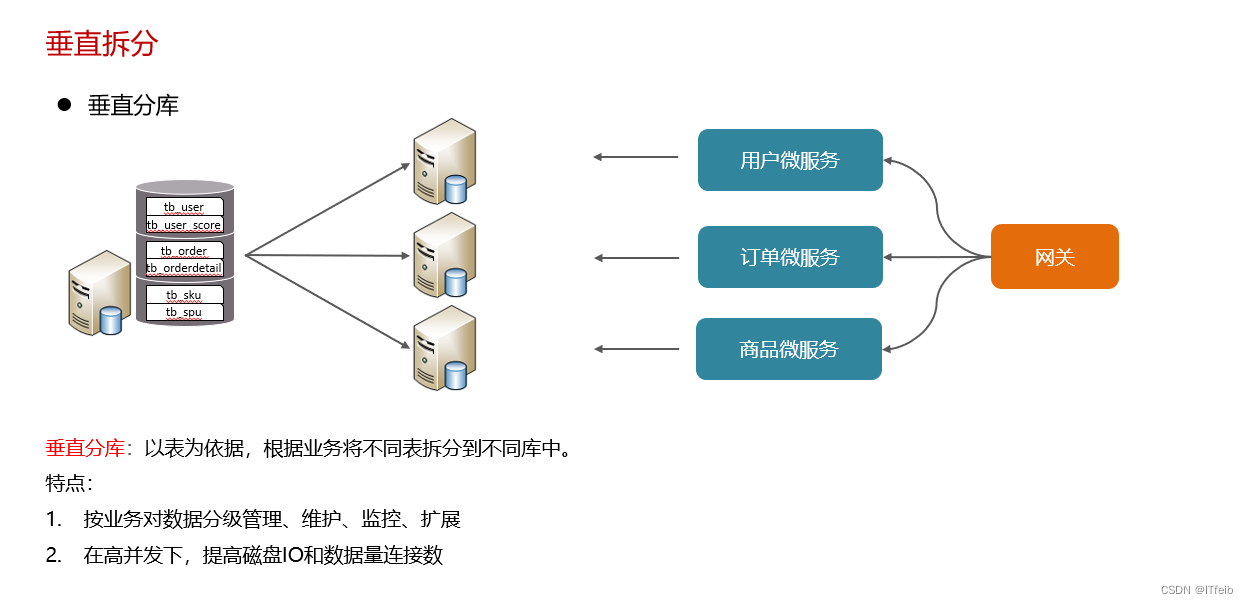
水平分库:一个表数据量超过1000万,进行水平分库,开了三台服务器,采用Mycat分片,都是根据id自增取模的方式来存储的
垂直分表:
文章来源:https://blog.csdn.net/qq_51240148/article/details/135133569
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Flutter排版格式:如何去除行末的,
- Elasticsearch基本操作之索引操作
- C#设计模式教程(3):抽象工厂模式
- 互动直播 之 播放器 类
- kubernetes
- docker-compose一键搭建zookeeper集群
- 最新国内使用GPT4教程,GPT语音对话使用,Midjourney绘画,ChatFile文档对话总结+DALL-E3文生图
- django开发
- 腾讯云主机活动内容:领取总面值2000元代金券礼包
- 力扣:438. 找到字符串中所有字母异位词 题解