Prometheus in Kubernetes

一. prometheus
- Prometheus 按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中。每个块都是一个单独的目录,里面含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。其中索引文件会将指标名称和标签索引到样板数据的时间序列中。此期间如果通过 API 删除时间序列,删除记录会保存在单独的逻辑文件
tombstone当中 - 当前样本数据所在的块会被直接保存在内存中,不会持久化到磁盘中。为了确保 Prometheus 发生崩溃或重启时能够恢复数据,Prometheus 启动时会通过预写日志(write-ahead-log(WAL))重新记录,从而恢复数据。预写日志文件保存在
wal目录中,每个文件大小为128MB。wal 文件包括还没有被压缩的原始数据,所以比常规的块文件大得多。一般情况下,Prometheus 会保留三个 wal 文件,但如果有些高负载服务器需要保存两个小时以上的原始数据,wal 文件的数量就会大于 3 个 - Prometheus 的本地存储无法持久化数据,无法灵活扩展。为了保持Prometheus的简单性,Prometheus并没有尝试在自身中解决以上问题,而是通过定义两个标准接口(remote_write/remote_read),让用户可以基于这两个接口对接将数据保存到任意第三方的存储服务中,这种方式在 Promthues 中称为 Remote Storage
1. 本地存储
-
Prometheus 2.x 默认将时间序列数据库保存在本地磁盘中,可以外接存储
-
如果你的本地存储出现故障,最好的办法是停止运行 Prometheus 并删除整个存储目录。因为 Prometheus 的本地存储不支持非 POSIX 兼容的文件系统,一旦发生损坏,将无法恢复。NFS 只有部分兼容 POSIX,大部分实现都不兼容 POSIX
-
除了删除整个目录之外,你也可以尝试删除个别块目录来解决问题。删除每个块目录将会丢失大约两个小时时间窗口的样本数据。所以,Prometheus 的本地存储并不能实现长期的持久化存储
-
Prometheus包括一个本地磁盘时间序列数据库
- chunks:用于保存具体的监控数据
- index:监控数据的记录索引
- meta.json:用来记录元数据
- wal:是Write ahead log的缩写,记录的是监控预习日志
2. 远程存储
1). read write
- 用户可以在 Prometheus 配置文件中指定 Remote Write(远程写)的 URL 地址,一旦设置了该配置项,Prometheus 将采集到的样本数据通过 HTTP 的形式发送给适配器(Adaptor)。而用户则可以在适配器中对接外部任意的服务。外部服务可以是真正的存储系统,公有云的存储服务,也可以是消息队列等任意形式
- Promthues 的 Remote Read(远程读)也通过了一个适配器实现。在远程读的流程当中,当用户发起查询请求后,Promthues 将向 remote_read 中配置的 URL 发起查询请求(matchers,ranges),
Adaptor根据请求条件从第三方存储服务中获取响应的数据。同时将数据转换为 Promthues 的原始样本数据返回给 Prometheus Server。当获取到样本数据后,Promthues 在本地使用 PromQL 对样本数据进行二次处理
2). 支持的存储
- 目前 Prometheus 社区也提供了部分对于第三方数据库的 Remote Storage 支持
- VictoriaMetrics 是 Prometheus 长期存储的理想解决方案
- 它实现了类似 PromQL 的查询语言——MetricsQL ,它在 PromQL 之上提供了改进的功能
- 与 Prometheus(Prometheus 就是一个很好的时序数据库)、Thanos 或 Cortex 相比,所需的存储空间最多减少 7 倍
- 光速查询
- 它有效地利用所有可用的 CPU 内核进行每秒数十亿行的并行处理
- 更低内存使用率
- 它使用的 RAM 比 InfluxDB 少 10 倍 ,比 Prometheus、Thanos 或 Cortex 少 7 倍
- 指标数据摄取和查询具备高性能和良好的可扩展性,性能比 InfluxDB 和 TimescaleDB 高出 20 倍
- 高性能的数据压缩方式,与 TimescaleDB 相比,可以将多达 70 倍的数据点存入有限的存储空间,与 Prometheus、Thanos 或 Cortex 相比,所需的存储空间减少 7 倍
| 存储服务 | 支持模式 |
|---|---|
| AppOptics | write |
| Chronix | write |
| Cortex | read/write |
| CrateDB | read/write |
| Elasticsearch | write |
| Gnocchi | write |
| Graphite | write |
| InfluxDB | read/write |
| IRONdb | read/write |
| Kafka | write |
| M3DB | read/write |
| OpenTSDB | write |
| PostgreSQL/TimescaleDB | read/write |
| SignalFx | write |
| Splunk | write |
| TiKV | read/write |
| VictoriaMetrics | write |
| Wavefront | write |
更多信息请查看集成文档。
3. thanos
- Thanos有两种运行模式,分别为
- Sidecar :Sidercar主动获取Prometheus数据
- Receiver:Receiver被动接收remote-write传送的数据
- Thanos 是一系列组件组成:
- Thanos Sidecar:连接 Prometheus,将其数据提供给 Thanos Query 查询,并且/或者将其上传到对象存储,以供长期存储
- Thanos Query:实现了 Prometheus API,提供全局查询视图,将来StoreAPI提供的数据进行聚合最终返回给查询数据的client(如grafana),Thanos Query 可以对数据进行聚合与去重,所以可以很轻松实现高可用:相同的 Prometheus 部署多个副本(都附带 Sidecar),然后 Thanos Query 去所有 Sidecar 查数据,即便有一个 Prometheus 实例挂掉过一段时间,数据聚合与去重后仍然能得到完整数据
- Thanos Store Gateway:将对象存储的数据暴露给 Thanos Query 去查询
- Thanos Ruler:对监控数据进行评估和告警,还可以计算出新的监控数据,将这些新数据提供给 Thanos Query 查询并且/或者上传到对象存储,以供长期存储
- Thanos Compact:将对象存储中的数据进行压缩和降低采样率,加速大时间区间监控数据查询的速度
- Thanos Receiver:从 Prometheus 的远程写入 WAL 接收数据,将其公开和/或上传到云存储
1). Receiver
- Receive 模式下,需要在每一个 Prometheus 实例中配置 remote write 将数据上传给 Thanos。此时,由于实时数据全部都存储到了 Thanos Receiver,因此不需要 Sidecar 组件即可完成查询
- Receiver 承受大量 Prometheus 的 remote write 写入,这也是这种模式的缺点,此时
Prometheus是无状态的, 只需要暴露给Receiver 给 Prometheus 访问
2). Sidecar
-
Sidecar 模式下,在每一个 Prometheus 实例旁添加一个 Thanos Sidecar 组件,以此来实现对 Prometheus 的管理。主要有两个功能:
- 接受 Query 组件的查询请求。在 Thanos 查询短期数据时,请求会转到 Sidecar。
- 上传 Prometheus 的短期指标数据。默认每两个小时,创建一个块,上传到对象存储。
优势:
- 集成容易,不需要修改原有配置
缺点:
- 近期数据需要 Query 与 Sidecar 之间网络请求完成,会增加额外耗时
- 需要 Store Gateway 能访问每个 Prometheus 实例
- 通过
thanos和Kvass来实现prometheus的 HA, 为什么用kvass,thanos解决了Prometheus的分布式存储和查询问题, 但没有解决Prometheus分布式采集的问题, 如果采集的任务和数据过多, 他是会使Pormetheus性能达到瓶颈,Kvass解决了分布式采集问题 prometheus默认只能实现联邦机制, 其本质都是将数据切分到多个采集配置中,由不同Prometheus进行采集, 对采集上来的数据进行hash,通过在不同Prometheus实例的配置文件中指定不同的moduleID来进行分片化
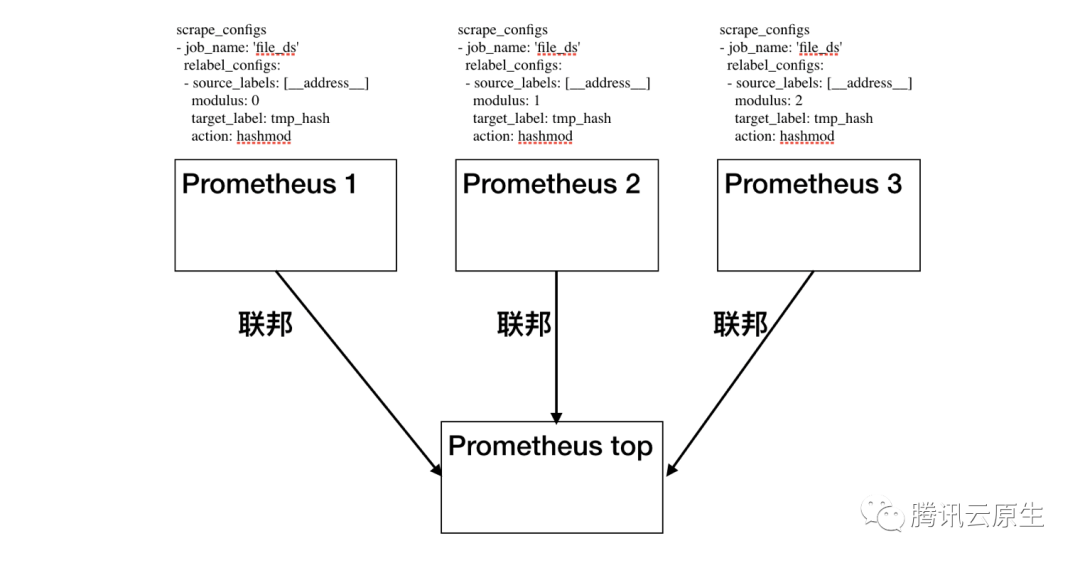
- 对预监控数据要有所了解:使用上述方法的前提是使用者必须对监控对象会上报的数据有所了解,例如必须知道监控对象会上报某个用于hash_mod的label,或者必须知道不同job的整体规模,才能对job进行划分。
- 实例负载不均衡:虽然上述方案预期都是希望将数据打散到不同Prometheus实例上,但实际上通过某些label的值进行hash_mod的,或者干脆按job进行划分的方式并不能保证每个实例最终所采集的series数是均衡的,实例依旧存在内存占用过高的风险。
- 配置文件有侵入:使用者必须对原配置文件进行改造,加入Relabel相关配置,或者将一份配置文件划分成多份,由于配置文件不再单一,新增,修改配置难度大大增加。
- 无法动态扩缩容:上述方案中的由于配置是根据实际监控目标的数据规模来特殊制定的,并没有一种统一的扩缩容方案,可以在数据规模增长时增加Prometheus个数。当然,用户如果针对自己业务实际情况编写扩缩容的工具确实是可以的,但是这种方式并不能在不同业务间复用。
- 部分API不再正常:上述方案将数据打散到了不同实例中,然后通过联邦或者Thanos进行汇总,得到全局监控数据,但是在不额外处理的情况下会导致部分Prometheus 原生API无法得到正确的值,最典型的是/api/v1/targets
二. kvass
1. Kvass概念
- Kvass项目是腾讯云开源的轻量级Prometheus横向扩缩容方案, 并用sidecar动态给Prometheus生成配置文件,从而达到不同Prometheus采集不同任务的效果。配合Thanos的全局视图,就可以轻松构建只使用一份配置文件的大规模集群监控系统, Kvass介绍, 从而实现无侵入的集群化方案,它对使用者表现出来的,是一个与原生
Prometheus配置文件一致,API兼容,可扩缩容的虚拟Prometheus- 支持数千万系列(千k8s节点)
- 一份prometheus配置文件
- 自动缩放
- 根据实际目标负载分片而不是标签哈希
- 支持多个副本
- 原理:
- 无侵入,单配置文件:我们希望使用者看到的,修改的都是一份原生的配置文件,不用加任何特殊的配置。
- 无需感知监控对象:我们希望使用者不再需要预先了解采集对象,不参与集群化的过程。
- 实例负载尽可能均衡:我们希望能根据监控目标的实际负载来划分采集任务,让实例尽可能均衡。
- 动态扩缩容:我们希望系统能够根据采集对象规模的变化进行动态扩缩容,过程中数据不断点,不缺失。
- 兼容核心PrometheusAPI:我们希望一些较为核心的API,如上边提到的/api/v1/target接口是正常的。
- 组件:
- Kvass sidecar: 用于接收Coordinator下发的采集任务,生成新的配置文件给Prometheus,也服务维护target负载情况。
- Kvass coordinator: 该组件是集群的中心控制器,负责服务发现,负载探测,targets下发等。
- Thanos 组件: 图中只使用了Thanos sidecar与Thanos query,用于对分片的数据进行汇总,得到统一的数据视图。
2. Kvass架构
-
面对大规模监控目标(数千万series)时,由于原生Prometheus只有单机版本,不提供集群化功能,开发人员不得不通过不断增加机器的配置来满足Prometheus不断上涨的内存
-
Kvass由多个组件构成,下图给出了Kvass的架构图,我们在架构图中使用了Thanos,实际上Kvass并不强依赖于Thanos
单机prometheus压测结果,
-
总series(监控指标)为100万不变, 通过改变target个数(pod 个数)
-
从表中我们发现target数目的改动对Prometheus负载的影响并不是强相关的。在target数目增长50倍的情况下,CPU消耗有小量增长,但是内存几乎不变
| target数量 | CPU (core) | mem (GB) |
|---|---|---|
| 100 | 0.17 | 4.6 |
| 500 | 0.19 | 4.2 |
| 1000 | 0.16 | 3.9 |
| 5000 | 0.3 | 4.6 |
压测结果
- 保持target数目不变,通过改变总series数
| series数量 (万) | CPU (core) | mem (GB) | 查询1000 series 15m数据(s) |
|---|---|---|---|
| 100 | 0.191 | 3.15 | 0.2 |
| 300 | 0.939 | 20.14 | 1.6 |
| 500 | 2.026 | 30.57 | 1.5 |
- 从表中,Prometheus的负载受到series的影响较大,series越多,资源消耗越大。
- 当series数据超过300万时,Prometheus内存增长较为明显,需要使用较大内存的机器来运行
Kvass集群方案架构图
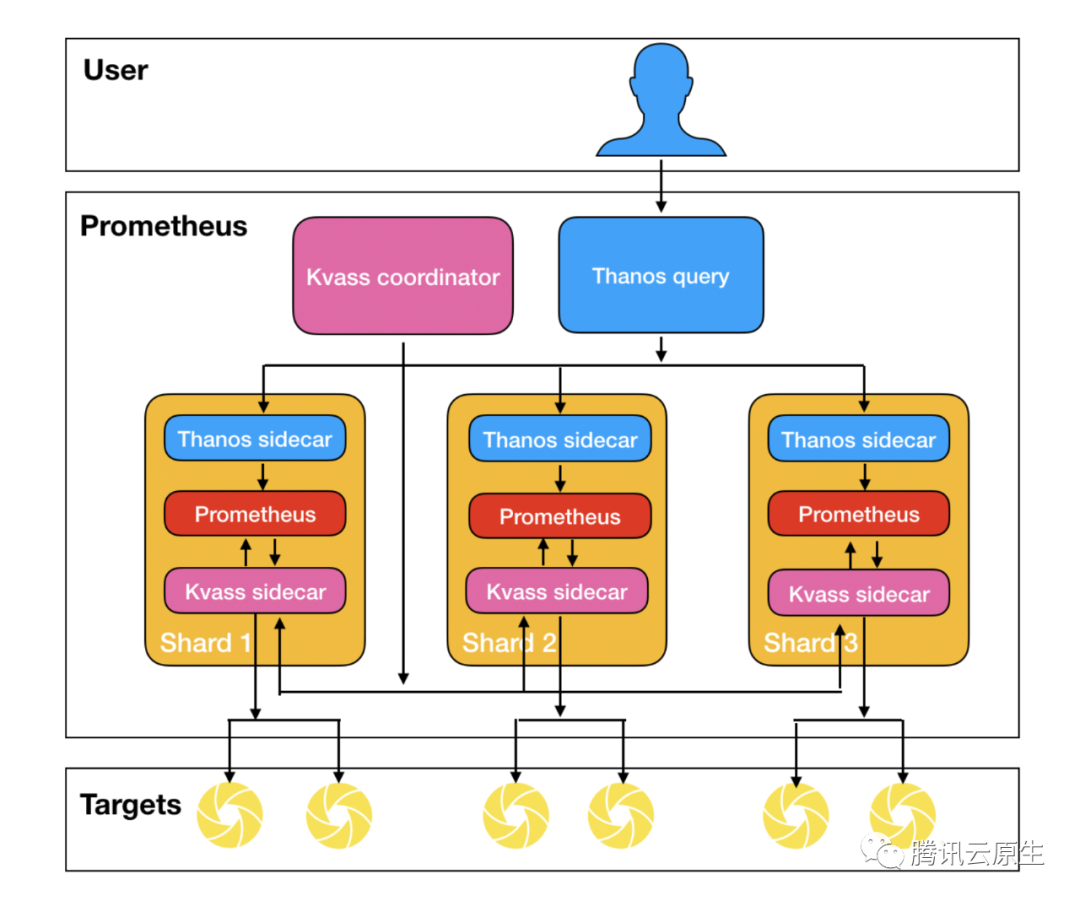
- Kvass sidecar: 边车容器, 用于接收
Coordinator下发的采集任务,生成新的配置文件给Prometheus,也服务维护target负载情况。 - Kvass coordinator: 该组件是集群的中心控制器,负责服务发现,负载探测,targets下发等。
- Thanos 组件: 图中只使用了Thanos sidecar与Thanos query,用于对分片的数据进行汇总,得到统一的数据视图。
3. 组件说明
(1). Coordinator
- Kvass coordinaor 首先会代替Prometheus对采集目标做服务发现,实时获得需要采集的target列表。
- 针对这些target,Kvass coordinaor会负责对其做负载探测,评估每个target的series数,一旦target负载被探测成功,Kvass coordinaor 就会在下个计算周期将target分配给某个负载在阈值以下的分片
- Kvass coordinaor引用了原生Prometheus的服务发现代码,用于实现与Prometheus 100%兼容的服务发现能力,针对服务发现得到的待抓取targets,Coordinaor会对其应用配置文件中的relabel_configs进行处理,得到处理之后的targets及其label集合。服务发现后得到的target被送往负载探测模块进行负载探测
Thanos sidcar
三. 部署
(一). 配置清单
1. PrometheusAlert
告警全家桶 PrometheusAlert
需要做数据持久化, 否则重启模板不在了
kind: PersistentVolumeClaim
metadata:
name: center-alert
namespace: monitor
spec:
storageClassName: monitor-nfs-storage
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-alert
namespace: monitor
spec:
rules:
- host: center-alert.yee.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-alert-center
port:
number: 8080
tls:
- hosts:
- center-alert.yee.com
secretName: yee.com
---
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-alert-center-conf
namespace: monitor
data:
app.conf: |
#---------------------↓全局配置-----------------------
appname = PrometheusAlert
#登录用户名
login_user=prometheusalert
#登录密码
login_password=sGOrrQ%OR1#r^rO@f^Sj
#监听地址
httpaddr = "0.0.0.0"
#监听端口
httpport = 8080
runmode = dev
#设置代理 proxy = http://123.123.123.123:8080
proxy =
#开启JSON请求
copyrequestbody = true
#告警消息标题
title=PrometheusAlert
#链接到告警平台地址
GraylogAlerturl=http://graylog.org
#钉钉告警 告警logo图标地址
logourl=https://raw.githubusercontent.com/feiyu563/PrometheusAlert/master/doc/alert-center.png
#钉钉告警 恢复logo图标地址
rlogourl=https://raw.githubusercontent.com/feiyu563/PrometheusAlert/master/doc/alert-center.png
#短信告警级别(等于3就进行短信告警) 告警级别定义 0 信息,1 警告,2 一般严重,3 严重,4 灾难
messagelevel=3
#电话告警级别(等于4就进行语音告警) 告警级别定义 0 信息,1 警告,2 一般严重,3 严重,4 灾难
phonecalllevel=4
#默认拨打号码(页面测试短信和电话功能需要配置此项)
defaultphone=xxxxxxxx
#故障恢复是否启用电话通知0为关闭,1为开启
phonecallresolved=0
#是否前台输出file or console
logtype=file
#日志文件路径
logpath=logs/prometheusalertcenter.log
#转换Prometheus,graylog告警消息的时区为CST时区(如默认已经是CST时区,请勿开启)
prometheus_cst_time=1
#数据库驱动,支持sqlite3,mysql,postgres如使用mysql或postgres,请开启db_host,db_port,db_user,db_password,db_name的注释
db_driver=sqlite3
#db_host=127.0.0.1
#db_port=3306
#db_user=root
#db_password=root
#db_name=prometheusalert
#是否开启告警记录 0为关闭,1为开启
AlertRecord=0
#是否开启告警记录定时删除 0为关闭,1为开启
RecordLive=0
#告警记录定时删除周期,单位天
RecordLiveDay=7
# 是否将告警记录写入es7,0为关闭,1为开启
alert_to_es=0
# es地址,是[]string
# beego.Appconfig.Strings读取配置为[]string,使用";"而不是","
to_es_url=http://localhost:9200
# to_es_url=http://es1:9200;http://es2:9200;http://es3:9200
# es用户和密码
# to_es_user=username
# to_es_pwd=password
#---------------------↓webhook-----------------------
#是否开启钉钉告警通道,可同时开始多个通道0为关闭,1为开启
open-dingding=1
#默认钉钉机器人地址
ddurl=https://oapi.dingtalk.com/robot/send?access_token=xxxxx
#是否开启 @所有人(0为关闭,1为开启)
dd_isatall=1
#是否开启微信告警通道,可同时开始多个通道0为关闭,1为开启
open-weixin=1
#默认企业微信机器人地址
wxurl=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxx
#是否开启飞书告警通道,可同时开始多个通道0为关闭,1为开启
open-feishu=1
#默认飞书机器人地址
fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/aa7ed2ee-896d-4c82-b7ca-28d10490a171
#---------------------↓腾讯云接口-----------------------
#是否开启腾讯云短信告警通道,可同时开始多个通道0为关闭,1为开启
open-txdx=0
#腾讯云短信接口key
TXY_DX_appkey=xxxxx
#腾讯云短信模版ID 腾讯云短信模版配置可参考 prometheus告警:{1}
TXY_DX_tpl_id=xxxxx
#腾讯云短信sdk app id
TXY_DX_sdkappid=xxxxx
#腾讯云短信签名 根据自己审核通过的签名来填写
TXY_DX_sign=腾讯云
#是否开启腾讯云电话告警通道,可同时开始多个通道0为关闭,1为开启
open-txdh=0
#腾讯云电话接口key
TXY_DH_phonecallappkey=xxxxx
#腾讯云电话模版ID
TXY_DH_phonecalltpl_id=xxxxx
#腾讯云电话sdk app id
TXY_DH_phonecallsdkappid=xxxxx
#---------------------↓华为云接口-----------------------
#是否开启华为云短信告警通道,可同时开始多个通道0为关闭,1为开启
open-hwdx=0
#华为云短信接口key
HWY_DX_APP_Key=xxxxxxxxxxxxxxxxxxxxxx
#华为云短信接口Secret
HWY_DX_APP_Secret=xxxxxxxxxxxxxxxxxxxxxx
#华为云APP接入地址(端口接口地址)
HWY_DX_APP_Url=https://rtcsms.cn-north-1.myhuaweicloud.com:10743
#华为云短信模板ID
HWY_DX_Templateid=xxxxxxxxxxxxxxxxxxxxxx
#华为云签名名称,必须是已审核通过的,与模板类型一致的签名名称,按照自己的实际签名填写
HWY_DX_Signature=华为云
#华为云签名通道号
HWY_DX_Sender=xxxxxxxxxx
#---------------------↓阿里云接口-----------------------
#是否开启阿里云短信告警通道,可同时开始多个通道0为关闭,1为开启
open-alydx=0
#阿里云短信主账号AccessKey的ID
ALY_DX_AccessKeyId=xxxxxxxxxxxxxxxxxxxxxx
#阿里云短信接口密钥
ALY_DX_AccessSecret=xxxxxxxxxxxxxxxxxxxxxx
#阿里云短信签名名称
ALY_DX_SignName=阿里云
#阿里云短信模板ID
ALY_DX_Template=xxxxxxxxxxxxxxxxxxxxxx
#是否开启阿里云电话告警通道,可同时开始多个通道0为关闭,1为开启
open-alydh=0
#阿里云电话主账号AccessKey的ID
ALY_DH_AccessKeyId=xxxxxxxxxxxxxxxxxxxxxx
#阿里云电话接口密钥
ALY_DH_AccessSecret=xxxxxxxxxxxxxxxxxxxxxx
#阿里云电话被叫显号,必须是已购买的号码
ALY_DX_CalledShowNumber=xxxxxxxxx
#阿里云电话文本转语音(TTS)模板ID
ALY_DH_TtsCode=xxxxxxxx
#---------------------↓容联云接口-----------------------
#是否开启容联云电话告警通道,可同时开始多个通道0为关闭,1为开启
open-rlydh=0
#容联云基础接口地址
RLY_URL=https://app.cloopen.com:8883/2013-12-26/Accounts/
#容联云后台SID
RLY_ACCOUNT_SID=xxxxxxxxxxx
#容联云api-token
RLY_ACCOUNT_TOKEN=xxxxxxxxxx
#容联云app_id
RLY_APP_ID=xxxxxxxxxxxxx
#---------------------↓邮件配置-----------------------
#是否开启邮件
open-email=0
#邮件发件服务器地址
Email_host=smtp.qq.com
#邮件发件服务器端口
Email_port=465
#邮件帐号
Email_user=xxxxxxx@qq.com
#邮件密码
Email_password=xxxxxx
#邮件标题
Email_title=运维告警
#默认发送邮箱
Default_emails=xxxxx@qq.com,xxxxx@qq.com
#---------------------↓七陌云接口-----------------------
#是否开启七陌短信告警通道,可同时开始多个通道0为关闭,1为开启
open-7moordx=0
#七陌账户ID
7MOOR_ACCOUNT_ID=Nxxx
#七陌账户APISecret
7MOOR_ACCOUNT_APISECRET=xxx
#七陌账户短信模板编号
7MOOR_DX_TEMPLATENUM=n
#注意:七陌短信变量这里只用一个var1,在代码里写死了。
#-----------
#是否开启七陌webcall语音通知告警通道,可同时开始多个通道0为关闭,1为开启
open-7moordh=0
#请在七陌平台添加虚拟服务号、文本节点
#七陌账户webcall的虚拟服务号
7MOOR_WEBCALL_SERVICENO=xxx
# 文本节点里被替换的变量,我配置的是text。如果被替换的变量不是text,请修改此配置
7MOOR_WEBCALL_VOICE_VAR=text
#---------------------↓telegram接口-----------------------
#是否开启telegram告警通道,可同时开始多个通道0为关闭,1为开启
open-tg=0
#tg机器人token
TG_TOKEN=xxxxx
#tg消息模式 个人消息或者频道消息 0为关闭(推送给个人),1为开启(推送给频道)
TG_MODE_CHAN=0
#tg用户ID
TG_USERID=xxxxx
#tg频道name或者id, 频道name需要以@开始
TG_CHANNAME=xxxxx
#tg api地址, 可以配置为代理地址
#TG_API_PROXY="https://api.telegram.org/bot%s/%s"
#---------------------↓workwechat接口-----------------------
#是否开启workwechat告警通道,可同时开始多个通道0为关闭,1为开启
open-workwechat=0
# 企业ID
WorkWechat_CropID=xxxxx
# 应用ID
WorkWechat_AgentID=xxxx
# 应用secret
WorkWechat_AgentSecret=xxxx
# 接受用户
WorkWechat_ToUser="zhangsan|lisi"
# 接受部门
WorkWechat_ToParty="ops|dev"
# 接受标签
WorkWechat_ToTag=""
# 消息类型, 暂时只支持markdown
# WorkWechat_Msgtype = "markdown"
#---------------------↓百度云接口-----------------------
#是否开启百度云短信告警通道,可同时开始多个通道0为关闭,1为开启
open-baidudx=0
#百度云短信接口AK(ACCESS_KEY_ID)
BDY_DX_AK=xxxxx
#百度云短信接口SK(SECRET_ACCESS_KEY)
BDY_DX_SK=xxxxx
#百度云短信ENDPOINT(ENDPOINT参数需要用指定区域的域名来进行定义,如服务所在区域为北京,则为)
BDY_DX_ENDPOINT=http://smsv3.bj.baidubce.com
#百度云短信模版ID,根据自己审核通过的模版来填写(模版支持一个参数code:如prometheus告警:{code})
BDY_DX_TEMPLATE_ID=xxxxx
#百度云短信签名ID,根据自己审核通过的签名来填写
TXY_DX_SIGNATURE_ID=xxxxx
#---------------------↓百度Hi(如流)-----------------------
#是否开启百度Hi(如流)告警通道,可同时开始多个通道0为关闭,1为开启
open-ruliu=0
#默认百度Hi(如流)机器人地址
BDRL_URL=https://api.im.baidu.com/api/msg/groupmsgsend?access_token=xxxxxxxxxxxxxx
#百度Hi(如流)群ID
BDRL_ID=123456
#---------------------↓bark接口-----------------------
#是否开启telegram告警通道,可同时开始多个通道0为关闭,1为开启
open-bark=0
#bark默认地址, 建议自行部署bark-server
BARK_URL=https://api.day.app
#bark key, 多个key使用分割
BARK_KEYS=xxxxx
# 复制, 推荐开启
BARK_COPY=1
# 历史记录保存,推荐开启
BARK_ARCHIVE=1
# 消息分组
BARK_GROUP=PrometheusAlert
#---------------------↓语音播报-----------------------
#语音播报需要配合语音播报插件才能使用
#是否开启语音播报通道,0为关闭,1为开启
open-voice=1
VOICE_IP=127.0.0.1
VOICE_PORT=9999
#---------------------↓飞书机器人应用-----------------------
#是否开启feishuapp告警通道,可同时开始多个通道0为关闭,1为开启
open-feishuapp=1
# APPID
FEISHU_APPID=cli_xxxxxxxxxxxxx
# APPSECRET
FEISHU_APPSECRET=xxxxxxxxxxxxxxxxxxxxxx
# 可填飞书 用户open_id、user_id、union_ids、部门open_department_id
AT_USER_ID="xxxxxxxx"
---
apiVersion: v1
kind: Service
metadata:
labels:
alertname: prometheus-alert-center
name: prometheus-alert-center
namespace: monitor
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
spec:
ports:
- name: http
port: 8080
targetPort: http
selector:
app: prometheus-alert-center
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: prometheus-alert-center
alertname: prometheus-alert-center
name: prometheus-alert-center
namespace: monitor
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-alert-center
alertname: prometheus-alert-center
template:
metadata:
labels:
app: prometheus-alert-center
alertname: prometheus-alert-center
spec:
containers:
# feiyu563/prometheus-alert:v4.8
- image: harbor.yee.com:8443/library/center-alert:v4.8
name: prometheus-alert-center
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: prometheus-alert-center-conf-map
mountPath: /app/conf/app.conf
subPath: app.conf
- name: time
mountPath: /etc/localtime
- name: template
mountPath: /app/db
volumes:
- name: template
persistentVolumeClaim:
claimName: center-alert
- name: prometheus-alert-center-conf-map
configMap:
name: prometheus-alert-center-conf
- name: time
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
# 新建模板
# 飞书模板内容推荐
{{ $var := .externalURL}}{{ range $k,$v:=.alerts }} {{if eq $v.status "resolved"}} **[Prometheus 恢复通知](https://prometheus-query.yee.com/{{$v.generatorURL}})**
【恢复名称】:{{$v.annotations.point}}
【当前状态】:{{$v.status}} ?
【告警等级】:{{$v.labels.level }}
【触发时间】:{{GetCSTtime $v.startsAt}}
【恢复时间】:{{GetCSTtime $v.endsAt}}
【恢复实例】:{{$v.annotations.point}}
【恢复描述】:**{{$v.annotations.description}}**
{{else}} **[Prometheus 告警通知](https://prometheus-query.yee.com/{{$v.generatorURL}})**
【告警名称】:{{$v.labels.alertname}}
【当前状态】:{{$v.status}} 🔥
【告警等级】:{{$v.labels.level }}
【触发时间】:{{GetCSTtime $v.startsAt}}
【告警实例】:{{$v.annotations.point}}
【告警描述】:{{$v.annotations.summary}}
【告警详情】:**{{$v.annotations.description}}**
{{end}} {{ end }}
# 钉钉模板
2. Altermanager

PrometheusAlert中可以查看到 webhook_url 信息
apiVersion: v1
kind: ServiceAccount
metadata:
name: alertmanager
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: alertmanager
rules:
- apiGroups: [""]
resources: ["alertmanagers"]
verbs: ["*"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["list","watch"]
- apiGroups: [""]
resources: ["namespaces"]
verbs: ["get","list","watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["*"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["list", "delete"]
- apiGroups: [""]
resources: ["services","endpoints"]
verbs: ["get","create","update","delete"]
- apiGroups: [""]
resources: ["configmaps","secrets"]
verbs: ["*"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: alertmanager
subjects:
- kind: ServiceAccount
name: alertmanager
namespace: monitor
roleRef:
kind: ClusterRole
name: alertmanager
apiGroup: rbac.authorization.k8s.io
---
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor
data:
config.yml: |
global:
resolve_timeout: 2m
route:
group_by: ['alertname', 'namespace', 'job']
group_interval: 5m
group_wait: 50s
repeat_interval: 20h # 根据实际情况缩短
receiver: default.webhook
routes:
# - match_re:
# job: ^(dc|dc-cdh|dc-biz)$
# receiver: dc.webhook
- match_re:
namespace: yee
receiver: yee.webhook
- match_re:
namespace: zjs
receiver: zjs.webhook
- match_re:
namespace: ysd
receiver: ysd.webhook
- match_re:
namespace: digitalclinic
receiver: digitalclinic.webhook
- match_re:
namespace: bx
receiver: bx.webhook
- match_re:
namespace: th
receiver: th.webhook
- match_re:
job: ^(secure|ueba)$
receiver: secure.webhook
receivers:
- name: default.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=default-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/aa7ed2ee-896d-4c82-b7ca-28d10490a171
send_resolved: false
- name: dc.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=dc-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
send_resolved: false
- name: yee.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=yee-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
#send_resolved: true
send_resolved: false
- name: zjs.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=zjs-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
send_resolved: false
- name: ysd.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=ysd-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
send_resolved: false
- name: digitalclinic.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=digitalclinic-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
send_resolved: false
- name: immunocloud.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=immunocloud-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
send_resolved: false
- name: th.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=th-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
send_resolved: false
- name: bx.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=bx-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
send_resolved: false
- name: secure.webhook
webhook_configs:
- url: https://center-alert.yee.com/prometheusalert?type=fs&tpl=secure-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx
send_resolved: true
inhibit_rules:
- source_match:
level: Critical
target_match:
level: Warning
equal: ['alertname']
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: alertmanager
namespace: monitor
spec:
serviceName: alertmanager
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: alertmanager
template:
metadata:
labels:
app.kubernetes.io/name: alertmanager
spec:
hostAliases:
- ip: xx.xx.xx.xx # pod中加入host解析,也可以不用加
hostnames:
- "center-alert.yee.com"
containers:
- name: alertmanager
# prom/alertmanager:v0.24.0
image: harbor.yee.com:8443/library/prom/alertmanager:v0.24.0
args:
- --config.file=/etc/alertmanager/config.yml
- --cluster.listen-address=[$(POD_IP)]:9094
- --storage.path=/alertmanager
- --data.retention=120h
- --web.listen-address=:9093
- --web.route-prefix=/
- --cluster.peer=alertmanager-0.alertmanager.$(POD_NAMESPACE).svc.cluster.local:9094
- --cluster.peer=alertmanager-1.alertmanager.$(POD_NAMESPACE).svc.cluster.local:9094
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
ports:
- containerPort: 9093
name: web
protocol: TCP
- containerPort: 9094
name: mesh-tcp
protocol: TCP
- containerPort: 9094
name: mesh-udp
protocol: UDP
livenessProbe:
failureThreshold: 10
httpGet:
path: /-/healthy
port: web
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
readinessProbe:
failureThreshold: 10
httpGet:
path: /-/ready
port: web
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
volumeMounts:
- name: alertmanager-config
mountPath: /etc/alertmanager
- name: alertmanager
mountPath: /alertmanager
- name: time
mountPath: /etc/localtime
volumes:
- name: alertmanager-config
configMap:
name: alertmanager
- name: alertmanager
emptyDir: {}
- name: time
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: monitor
labels:
app.kubernetes.io/name: alertmanager
spec:
selector:
app.kubernetes.io/name: alertmanager
ports:
- name: web
protocol: TCP
port: 9093
targetPort: web
3. Kvass
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- persistentvolumeclaims
verbs:
- delete
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- list
- get
- patch
- update
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
- configmaps
- secrets
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics","/probe"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
---
apiVersion: v1
kind: Service
metadata:
name: kvass-coordinator
namespace: monitor
labels:
app.kubernetes.io/name: kvass-coordinator
spec:
ports:
- name: http
port: 9090
targetPort: http
selector:
app.kubernetes.io/name: kvass-coordinator
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: kvass-coordinator
name: kvass-coordinator
namespace: monitor
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kvass-coordinator
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
labels:
app.kubernetes.io/name: kvass-coordinator
spec:
serviceAccountName: prometheus
containers:
- name: config-reload
args:
- --reload-url=http://localhost:9090/-/reload
- --config-file=/etc/prometheus/config/prometheus.yml
- --config-envsubst-file=/etc/prometheus/config_out/prometheus.env.yaml
# rancher/coreos-prometheus-config-reloader:v0.32.0
image: harbor.yee.com:8443/library/rancher/coreos-prometheus-config-reloader:v0.32.0
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 50Mi
requests:
memory: 10Mi
volumeMounts:
- mountPath: /etc/prometheus/config_out
name: config-out
- mountPath: /etc/prometheus/config
name: config
- mountPath: /etc/localtime
name: time
- mountPath: /etc/prometheus/node-target.yml
name: sd-config
subPath: node-target.yml
- mountPath: /etc/prometheus/network-probe.yml
name: network-probe
subPath: network-probe.yml
# tkestack/kvass:latest
- image: harbor.yee.com:8443/library/tkestack/kvass:latest
imagePullPolicy: IfNotPresent
args:
- coordinator
- --shard.max-series=600000 # 默认100万, prometheus 默认接受多大的 series 分片,官方推荐最大75万个
- --shard.selector=app.kubernetes.io/name=prometheus # selector to get shard StatefulSets
- --shard.namespace=$(NAMESPACE)
- --config.file=/etc/prometheus/config_out/prometheus.env.yaml
- --shard.max-idle-time=1h # prometheus 缩容时间,0 为禁止缩容,1h 为1小时缩容
env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
ports:
- containerPort: 9090
name: http
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/config
name: config
- mountPath: /etc/prometheus/config_out
name: config-out
- mountPath: /etc/localtime
name: time
- mountPath: /etc/prometheus/node-target.yml
name: sd-config
subPath: node-target.yml
- mountPath: /etc/prometheus/network-probe.yml
name: network-probe
subPath: network-probe.yml
name: kvass
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 250m
memory: 20Mi
volumes:
- name: sd-config
configMap:
name: node-target
- name: network-probe
configMap:
name: network-probe
- name: time
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: config
configMap:
name: prometheus-config
- emptyDir: {}
name: config-out
- emptyDir: {}
name: tls-assets
4. Prometheus
kind: ConfigMap
apiVersion: v1
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |-
global:
scrape_interval: 20s
evaluation_interval: 20s
external_labels:
cluster: threegene-cluster-01
scrape_configs:
- job_name: 'node_exporter'
file_sd_configs:
- files:
- /etc/prometheus/node-target.yml
refresh_interval: 2m
relabel_configs:
- source_labels: [__address__]
regex: '(.*):(9.*)'
replacement: '$1'
target_label: ip
action: replace
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9110'
target_label: __address__
action: replace
- source_labels: [__address__]
regex: '(.*):9110'
replacement: '$1'
target_label: ip
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-sd-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
#- action: labelmap
# regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9110'
target_label: __address__
action: replace
- source_labels: [__address__]
regex: '(.*):9110'
replacement: '$1'
target_label: ip
action: replace
- source_labels: [instance]
target_label: node
action: replace
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-state-metrics'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-state-metrics;kube-state-metrics
- job_name: 'kubernetes-coredns'
honor_labels: true
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_pod_name]
separator: '/'
regex: 'kube-system/coredns.+'
- source_labels: [__meta_kubernetes_pod_container_port_name]
action: keep
regex: metrics
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-ingress-nginx'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_pod_name]
separator: '/'
regex: 'kube-system/nginx-ingress-controller.+'
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- source_labels: [__meta_kubernetes_service_name]
regex: prometheus
action: drop
- job_name: 'kubernetes-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'pushgateway'
honor_labels: true
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
separator: ;
regex: pushgateway
replacement: $1
action: keep
- job_name: 'port_status'
metrics_path: /probe
params:
module: [tcp_connect]
file_sd_configs:
- files:
- /etc/prometheus/network-probe.yml
refresh_interval: 2m
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
regex: '(.*):(.*)'
replacement: '$1'
target_label: ip
- source_labels: [__param_target]
regex: '(.*):(.*)'
replacement: '$2'
target_label: port
- target_label: __address__
replacement: blackbox.monitor.svc.cluster.local:9115
- job_name: 'nacos'
metrics_path: '/nacos/actuator/prometheus'
static_configs:
- targets: ['172.17.10.14:8848','172.17.10.17:8848','172.17.10.19:8848']
relabel_configs:
- source_labels: [__address__]
regex: '(.*):(8848)'
replacement: '$1'
target_label: ip
action: replace
- job_name: 'jvm'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_jvm]
action: keep
regex: true
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- source_labels: [__meta_kubernetes_service_name]
action: replace
regex: (.+)
target_label: application
replacement: $1
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
---
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: monitor
labels:
name: prometheus-rules
data:
rules.yaml: |-
groups:
- name: ECS
rules:
- alert: ECS-CPU使用率
expr: round((1 - (sum(increase(node_cpu_seconds_total{mode="idle"}[1m]) * on(instance) group_left(nodename) (node_uname_info)) by (ip,nodename,job) / sum(increase(node_cpu_seconds_total[1m]) * on(instance) group_left(nodename) (node_uname_info)) by (ip,nodename,job))) * 100,0.01) > 95
for: 5m
labels:
level: Critical
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}: CPU使用高"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},CPU使用率为:{{ $value }}%"
#- alert: ECS-CPU使用率
# expr: round((1 - (sum(increase(node_cpu_seconds_total{mode="idle"}[1m]) * on(instance) group_left(nodename) (node_uname_info)) by (ip,nodename,job) / sum(increase(node_cpu_seconds_total[1m]) * on(instance) group_left(nodename) (node_uname_info)) by (ip,nodename,job))) * 100,0.01) > 80
# for: 4m
# labels:
# level: Warning
# annotations:
# point: "{{ $labels.ip }}"
# belong: "{{ $labels.job }}"
# summary: "{{ $labels.ip }}: CPU使用高"
# description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},CPU使用率为:{{ $value }}%"
- alert: ECS-内存使用率
expr: round(100 - ((node_memory_MemFree_bytes * on(instance) group_left(nodename) (node_uname_info)) + (node_memory_Cached_bytes * on(instance) group_left(nodename) (node_uname_info)) + (node_memory_Buffers_bytes * on(instance) group_left(nodename) (node_uname_info))) / (node_memory_MemTotal_bytes * on(instance) group_left(nodename) (node_uname_info)) * 100,0.01) > 95
for: 5m
labels:
level: Critical
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}: 内存使用过高"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},内存使用率为:{{ $value }}%"
- alert: ECS-内存使用率
expr: round(100 - ((node_memory_MemFree_bytes * on(instance) group_left(nodename) (node_uname_info)) + (node_memory_Cached_bytes * on(instance) group_left(nodename) (node_uname_info)) + (node_memory_Buffers_bytes * on(instance) group_left(nodename) (node_uname_info))) / (node_memory_MemTotal_bytes * on(instance) group_left(nodename) (node_uname_info)) * 100,0.01) > 90
for: 4m
labels:
level: Warning
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}: 内存使用过高"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},内存使用率为:{{ $value }}%"
- alert: ECS-磁盘使用
expr: round(max(((node_filesystem_size_bytes{fstype=~"ext.?|xfs", mountpoint!~"/var/lib/.*"} * on(instance) group_left(nodename) (node_uname_info)) - (node_filesystem_free_bytes{fstype=~"ext.?|xfs", mountpoint!~"/var/lib/.*"})* on(instance) group_left(nodename) (node_uname_info)) * 100 / ((node_filesystem_avail_bytes {fstype=~"ext.?|xfs", mountpoint!~"/var/lib/.*"}* on(instance) group_left(nodename) (node_uname_info)) + ((node_filesystem_size_bytes{fstype=~"ext.?|xfs", mountpoint!~"/var/lib/.*"}* on(instance) group_left(nodename) (node_uname_info)) - (node_filesystem_free_bytes{fstype=~"ext.?|xfs", mountpoint!~"/var/lib/.*"}* on(instance) group_left(nodename) (node_uname_info))))) by(mountpoint, ip, nodename,job),0.01) > 90
for: 5m
labels:
level: Critical
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}: 磁盘占用高"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},分区:{{ $labels.mountpoint }} 使用率为:{{ $value }}%"
- alert: ECS-预计5天后无可用磁盘
expr: round(predict_linear(node_filesystem_free_bytes{fstype=~"ext.?|xfs",mountpoint!~"/var/lib/.*"}[1d],5*86400) * on(instance) group_left(nodename) (node_uname_info) / 1024^3,0.01) <=0
for: 10m
labels:
level: Critical
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}: 预计5天后无可用磁盘空间"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},分区:{{ $labels.mountpoint }},5天后,可用磁盘估值:{{ $value }}G"
- alert: ECS-文件句柄
expr: sum(node_filefd_allocated * on(instance) group_left(nodename) (node_uname_info)) by (ip,job,nodename)> 60000
for: 5m
labels:
level: Critical
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}: 打开的文件数过高"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},打开的文件数为:{{ $value }}"
- alert: ECS-负载[5m]
expr: (node_load5 * on(instance) group_left(nodename) (node_uname_info)) > on(instance,ip,nodename,job) 2 * count((node_cpu_seconds_total{mode="idle"} * on(instance) group_left(nodename) (node_uname_info) )) by (instance,ip,nodename,job)
for: 5m
labels:
level: Critical
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}: 负载过高[5m]"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},5分钟内平均负载为:{{ $value }}"
- alert: ECS-TCP状态[TCP_TIMEWAIT]
expr: node_sockstat_TCP_tw * on(instance) group_left(nodename) (node_uname_info) > 6000
for: 5m
labels:
level: Warning
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}:TCP_TIMEWAIT过高"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},TCP_TIMEWAIT数量为:{{ $value }}"
- alert: ECS-磁盘IO
expr: round(avg(irate(node_disk_io_time_seconds_total[5m]) * on(instance) group_left(nodename) (node_uname_info)) by(ip,nodename,job) * 100,0.01) > 90
for: 5m
labels:
level: Critical
annotations:
point: "{{ $labels.ip }}"
belong: "{{ $labels.job }}"
summary: "{{ $labels.ip }}: 磁盘IO"
description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},流入磁盘IO使用率过高,使用率为:{{ $value }}%"
- alert: Prometheus请求延时[单位:s]
expr: round(histogram_quantile(0.5, sum(rate(prometheus_http_request_duration_seconds_bucket[5m])) by (le, handler)),0.001) > 2
for: 5m
labels:
level: Critical
annotations:
summary: "Prometheus请求延时"
description: "Prometheus接口:{{ $labels.handler }},请求延时时间为:{{ $value }}"
- alert: 端口检测
expr: probe_success == 0
for: 1m
labels:
level: Critical
annotations:
point: "{{ $labels.app }}"
summary: "端口检测失败"
description: "IP:{{ $labels.ip }},Port:{{ $labels.port }},{{ $labels.app }} 检测失败"
#- alert: ECS-网络流入
# expr: round(((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m]) * on(instance) group_left(nodename) (node_uname_info)) by (job,nodename,ip)) / 100),0.01) > 102500
# for: 5m
# labels:
# severity: immunocloud
# annotations:
# level: Critical
# point: "{{ $labels.ip }}"
# belong: "{{ $labels.job }}"
# summary: "{{ $labels.ip }}: 网络流入高"
# description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},流入网络带宽高于100M,使用量:{{ $value }}"
#- alert: ECS-网络流出
# expr: round((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m]) * on(instance) group_left(nodename) (node_uname_info)) by (ip,nodename,job)) / 100,0.01) > 102500
# for: 5m
# labels:
# severity: immunocloud
# annotations:
# level: Critical
# point: "{{ $labels.ip }}"
# belong: "{{ $labels.job }}"
# summary: "{{ $labels.ip }}: 网络流出高"
# description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},流出网络带宽高于100M,使用量:{{ $value }}"
- name: Kubernetes
rules:
- alert: Kubernetes-容器CPU使用率
expr: round(sum(irate(container_cpu_usage_seconds_total{image!="",container!="POD",container!=""}[5m]) * 100) by(pod,container,cluster,namespace,image) / sum(container_spec_cpu_quota{container!="",image!="",container!="POD",container!=""} / container_spec_cpu_period{image!="",container!="POD",container!=""}) by(pod,container,cluster,namespace,image),0.01) >= 90
for: 5m
labels:
level: Critical
annotations:
level: Critical
point: "{{ $labels.namespace }}/{{ $labels.container }}"
cluster: "{{ $labels.cluster }}"
belong: "{{ $labels.namespace }}"
summary: "{{ $labels.container }}:CPU使用率过高"
description: "Namespace:{{ $labels.namespace }},Pod名:{{ $labels.container }},镜像为:{{ $labels.image }},CPU使用率为:{{ $value }}%"
#- alert: Kubernetes-容器内存使用率[5m]
# expr: round(sum(container_memory_rss{image!="",namespace="digitalclinic"}) by(namespace,container,pod,image,cluster) / sum(container_spec_memory_limit_bytes{image!=""}) by(namespace,container,cluster,pod,image) * 100 != +Inf,0.01) >= 99
# for: 5m
# labels:
# level: Critical
# annotations:
# point: "{{ $labels.namespace }}/{{ $labels.container }}"
# cluster: "{{ $labels.cluster }}"
# belong: "{{ $labels.namespace }}"
# summary: "{{ $labels.container }}:Pod内存使用率高"
# description: "Namespace:{{ $labels.namespace }},Pod名:{{ $labels.container }},镜像为:{{ $labels.image }},内存使用率为:{{ $value }}%"
#- alert: Kubernetes-容器内存使用率
# expr: round(sum(container_memory_rss{image!=""}) by(namespace,container,pod,image,cluster) / sum(container_spec_memory_limit_bytes{image!=""}) by(namespace,container,cluster,pod,image) * 100 != +Inf,0.01) >= 90
# for: 4m
# labels:
# level: Critical
# annotations:
# point: "{{ $labels.namespace }}/{{ $labels.container }}"
# cluster: "{{ $labels.cluster }}"
# belong: "{{ $labels.namespace }}"
# summary: "{{ $labels.container }}:Pod内存使用率高"
# description: "Namespace:{{ $labels.namespace }},Pod名:{{ $labels.container }},镜像为:{{ $labels.image }},内存使用率为:{{ $value }}%"
- alert: Kubernetes-Pod重启[5m]
expr: changes(kube_pod_container_status_restarts_total[5m]) >= 1
for: 2m
labels:
level: Critical
annotations:
point: "{{ $labels.namespace }}/{{ $labels.container }}"
cluster: "{{ $labels.cluster }}"
belong: "{{ $labels.namespace }}"
summary: "{{ $labels.container }}:5分钟内重启的Pod"
description: "Namespace:{{ $labels.namespace }},Container名:{{ $labels.pod }},5分钟之内重启次数为:{{ $value }}"
- alert: Kubernetes-Pod状态异常[5m]
expr: min_over_time(sum by (namespace, pod,cluster, condition, instance, node) (kube_pod_status_ready{condition!='true'} == 1)[5m:])
for: 5m
labels:
level: Critical
annotations:
point: "{{ $labels.namespace }}/{{ $labels.pod }}"
cluster: "{{ $labels.cluster }}"
belong: "{{ $labels.namespace }}"
summary: "{{ $labels.pod }}:异常状态的Pod"
description: "Namespace:{{ $labels.namespace }},容器名:{{ $labels.pod }},状态异常,将导致Pod重启"
# 测试告警
# - alert: Kubernetes-Pod状态异常[5m]
# expr: up{job="secure"} == 1
# for: 5m
# labels:
# level: Critical
# annotations:
# point: "{{ $labels.ip }}"
# belong: "{{ $labels.job }}"
# summary: "测试告警"
# description: "IP:{{ $labels.ip }},主机名:{{ $labels.nodename }},测试告警消息"
#- alert: Kubernetes-Pod预计明天内存使用超过100%
# expr: round(sum(predict_linear(container_memory_rss{container !=""}[1d], 86400)) by(namespace,container,pod) / sum(container_spec_memory_limit_bytes{container !=""}) by(namespace,container,pod) * 100 != +Inf,0.01) >100
# for: 5m
# labels:
# level: Critical
# annotations:
# point: "{{ $labels.namespace }}/{{ $labels.container }}"
# cluster: "{{ $labels.cluster }}"
# belong: "{{ $labels.namespace }}"
# summary: "{{ $labels.container }}:预计明天内存使用超过100%"
# description: "Namespace:{{ $labels.namespace }},Pod名:{{ $labels.container }},预计明天内存使用超过100%,使用百分比估值:{{ $value }}%"
# - alert: Kubernetes-Pod重启次数[5m]
# expr: floor(sum(increase(kube_pod_container_status_restarts_total[5m])) by (namespace,pod,container,cluster)) >= 1
# for: 2m
# labels:
# level: Critical
# annotations:
# point: "{{ $labels.namespace }}/{{ $labels.container }}"
# cluster: "{{ $labels.cluster }}"
# belong: "{{ $labels.namespace }}"
# summary: "{{ $labels.container }}:Pod异常重启"
# description: "Namespace:{{ $labels.namespace }},Pod名:{{ $labels.container }},重启次数为:{{ $value }}"
# - alert: Kubernetes-Node不可调度
# expr: sum(kube_node_spec_unschedulable) by(job,instance,node) == 1
# for: 5m
# labels:
# level: Warning
# annotations:
# point: "{{ $labels.instance }}"
# cluster: "{{ $labels.cluster }}"
# belong: "{{ $labels.job }}"
# summary: "{{ $labels.node }}:节点不可调度"
# description: "{{ $labels.node }},IP:{{ $labels.instance }}节点不可调度"
# - alert: Kubernetes-Deployment部署失败
# expr: sum(kube_deployment_status_observed_generation) by (namespace,deployment,cluster) != sum(kube_deployment_metadata_generation) by (namespace,deployment,cluster)
# for: 5m
# labels:
# level: Warning
# annotations:
# point: "{{ $labels.namespace }}/{{ $labels.deployment }}"
# cluster: "{{ $labels.cluster }}"
# belong: "{{ $labels.namespace }}"
# summary: "Deployment:{{ $labels.deployment }}部署失败"
# description: "Namespace:{{ $labels.namespace }},Deployment:{{ $labels.deployment }},部署失败"
# - alert: Kubernetes-PVC剩余不足
# expr: round((avg(kubelet_volume_stats_used_bytes) by (persistentvolumeclaim,namespace,cluster) / avg(kubelet_volume_stats_capacity_bytes) by (persistentvolumeclaim,namespace,cluster)) * 100, 0.01) > 90
# for: 20m
# labels:
# level: Critical
# annotations:
# point: "{{ $labels.namespace }}/{{ $labels.persistentvolumeclaim }}"
# cluster: "{{ $labels.cluster }}"
# belong: "{{ $labels.namespace }}"
# summary: "PVC:{{ $labels.persistentvolumeclaim }} PVC剩余空间不足"
# description: "Namespace:{{ $labels.namespace }},PVC:{{ $labels.persistentvolumeclaim }},PVC使用率为:{{ $value }}%"
# - alert: Kubernetes-Pod未就绪
# expr: sum by (namespace, pod) (max by(namespace, pod) (kube_pod_status_phase{phase=~"Pending|Unknown"}) * on(namespace, pod) group_left(owner_kind) max by(namespace, pod) (kube_pod_owner{owner_kind!="Job"})) > 0
# for: 5m
# labels:
# level: Warning
# annotations:
# point: "{{ $labels.namespace }}/{{ $labels.pod }}"
# belong: "{{ $labels.namespace }}"
# summary: "Container:{{ $labels.pod }}部署失败"
# description: "Namespace:{{ $labels.namespace }},Container:{{ $labels.pod }},未就绪"
# - alert: Kubernetes-Pod初始化容器处于等待状态
# expr: sum by (namespace, pod, container,cluster) (kube_pod_container_status_waiting_reason) > 0
# for: 2m
# labels:
# level: Warning
# annotations:
# point: "{{ $labels.namespace }}/{{ $labels.container }}"
# cluster: "{{ $labels.cluster }}"
# belong: "{{ $labels.namespace }}"
# summary: "Deployment:{{ $labels.container }}初始化容器处于等待状态"
# description: "Namespace:{{ $labels.namespace }},Deployment:{{ $labels.container }},Pod:{{ $labels.pod }}在等待状态中"
---
kind: Service
apiVersion: v1
metadata:
name: prometheus
namespace: monitor
labels:
app.kubernetes.io/name: prometheus
spec:
type: ClusterIP
clusterIP: None
selector:
app.kubernetes.io/name: prometheus
ports:
- name: web
protocol: TCP
port: 8080
targetPort: web
- name: grpc
port: 10901
targetPort: grpc
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: prometheus
name: prometheus-rep
namespace: monitor
spec:
# must set as Parallel
podManagementPolicy: Parallel
replicas: 0
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/name: prometheus
kvass/rep: "0"
serviceName: prometheus
template:
metadata:
labels:
app.kubernetes.io/name: prometheus
kvass/rep: "0"
thanos-store-api: "true"
spec:
containers:
- name: thanos
# thanosio/thanos:v0.25.1
image: harbor.yeemiao.com:8443/library/thanos:v0.25.1
args:
- sidecar
- --log.level=warn
- --tsdb.path=/prometheus
- --prometheus.url=http://localhost:8080
- --reloader.config-file=/etc/prometheus/config/prometheus.yml
- --reloader.config-envsubst-file=/etc/prometheus/config_out/prometheus.env.yaml
#- --objstore.config-file=/etc/secret/thanos.yaml
ports:
- name: http-sidecar
containerPort: 10902
- name: grpc
containerPort: 10901
resources:
limits:
cpu: 4
memory: 4Gi
requests:
cpu: 250m
memory: 20Mi
livenessProbe:
httpGet:
port: 10902
path: /-/healthy
readinessProbe:
httpGet:
port: 10902
path: /-/ready
volumeMounts:
- mountPath: /etc/prometheus/config_out
name: config-out
- mountPath: /etc/prometheus/config
name: config
- mountPath: /etc/localtime
name: time
- mountPath: /etc/prometheus/node-target.yml
name: sd-config
subPath: node-target.yml
#- mountPath: /etc/secret
# name: object-storage-config
# readOnly: false
- mountPath: /prometheus
name: data
- name: kvass
args:
- sidecar
- --store.path=/prometheus/ # where to store kvass local data
- --config.file=/etc/prometheus/config_out/prometheus.env.yaml # origin config file
- --config.output-file=/etc/prometheus/config_out/prometheus_injected.yaml # injected config file. this is the file prometheus use
# tkestack/kvass:latest
image: harbor.yeemiao.com:8443/library/tkestack/kvass:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/localtime
name: time
- mountPath: /etc/prometheus/config_out
name: config-out
- mountPath: /etc/prometheus/node-target.yml
name: sd-config
subPath: node-target.yml
# sidecar need pvc to store targets list, see '--store.path" flag
# sidecar will reload targets list in initialization phase
- mountPath: /prometheus
name: data
ports:
- containerPort: 8080
name: web
protocol: TCP
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 250m
memory: 20Mi
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: prometheus
args:
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention.time=30d # prometheus 数据保存时间, 默认是15天
- --web.enable-lifecycle # 支持热加载
- --storage.tsdb.no-lockfile
- --web.enable-admin-api
- --storage.tsdb.max-block-duration=2h
- --storage.tsdb.min-block-duration=2h
- --config.file=/etc/prometheus/config_out/prometheus_injected.yaml # use injected config file instead of origin config file
- --log.level=debug
# prom/prometheus:v2.33.3
image: harbor.yeemiao.com:8443/library/prom/prometheus:v2.33.3
ports:
- containerPort: 9090
name: server
protocol: TCP
resources:
limits:
cpu: 6
memory: 8Gi
requests:
cpu: 250m
memory: 400Mi
volumeMounts:
- mountPath: /etc/prometheus/config
name: config
- mountPath: /etc/prometheus/config_out
name: config-out
- mountPath: /prometheus
name: data
- mountPath: /etc/localtime
name: time
- mountPath: /etc/prometheus/node-target.yml
name: sd-config
subPath: node-target.yml
- mountPath: /etc/prometheus/network-probe.yml
name: network-probe
subPath: network-probe.yml
restartPolicy: Always
serviceAccountName: prometheus
securityContext:
runAsUser: 0
volumes:
- name: config
configMap:
name: prometheus-config
defaultMode: 420
- name: network-probe
configMap:
name: network-probe
- name: sd-config
configMap:
name: node-target
- emptyDir: {}
name: config-out
- emptyDir: {}
name: tls-assets
#- name: object-storage-config
# secret:
# secretName: thanos-objectstorage
- name: time
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
volumeClaimTemplates:
- metadata:
labels:
k8s-app: prometheus
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
storageClassName: monitor-nfs-storage
volumeMode: Filesystem
updateStrategy:
rollingUpdate:
partition: 0
type: RollingUpdate
5. Thanos
thanos-query
apiVersion: v1
kind: Service
metadata:
name: thanos-query
namespace: monitor
labels:
app.kubernetes.io/name: thanos-query
spec:
ports:
- name: grpc
port: 10901
targetPort: grpc
- name: http
port: 9090
targetPort: http
selector:
app.kubernetes.io/name: thanos-query
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: thanos-query
namespace: monitor
labels:
app.kubernetes.io/name: thanos-query
spec:
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: thanos-query
template:
metadata:
labels:
app.kubernetes.io/name: thanos-query
spec:
containers:
- args:
- query
- --log.level=debug
- --query.auto-downsampling
- --grpc-address=0.0.0.0:10901
- --http-address=0.0.0.0:9090
- --query.partial-response
- --store=dnssrv+_grpc._tcp.prometheus.$(NAMESPACE).svc.cluster.local
- --store=dnssrv+_grpc._tcp.thanos-rule.$(NAMESPACE).svc.cluster.local
#- --store=dnssrv+thanos-store.$(NAMESPACE).svc.cluster.local
# thanosio/thanos:v0.25.1
image: harbor.yeemiao.com:8443/library/thanos:v0.25.1
env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
resources:
limits:
cpu: 4
memory: 4Gi
requests:
cpu: 250m
memory: 20Mi
volumeMounts:
- mountPath: /etc/localtime
name: time
livenessProbe:
failureThreshold: 4
httpGet:
path: /-/healthy
port: 9090
scheme: HTTP
periodSeconds: 30
name: thanos-query
ports:
- containerPort: 10901
name: grpc
- containerPort: 9090
name: http
readinessProbe:
failureThreshold: 20
httpGet:
path: /-/ready
port: 9090
scheme: HTTP
periodSeconds: 5
terminationMessagePolicy: FallbackToLogsOnError
volumes:
- name: time
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
terminationGracePeriodSeconds: 120
thanos-rule,rules配置在 Prometheus 中
apiVersion: v1
kind: Service
metadata:
name: thanos-rule
namespace: monitor
labels:
app.kubernetes.io/name: thanos-rule
spec:
ports:
- name: grpc
port: 10901
targetPort: grpc
- name: http
port: 10902
targetPort: http
selector:
app.kubernetes.io/name: thanos-rule
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: thanos-rule
namespace: monitor
spec:
rules:
- host: rules-thanos.yee.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: thanos-rule
port:
number: 10902
tls:
- hosts:
- rules-thanos.yee.com
secretName: yee.com
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: thanos-rule
namespace: monitor
labels:
app.kubernetes.io/name: thanos-rule
spec:
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: thanos-rule
serviceName: ""
template:
metadata:
labels:
app.kubernetes.io/name: thanos-rule
spec:
volumes:
- name: rules
configMap:
name: prometheus-rules
defaultMode: 420
- name: time
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
containers:
- args:
- rule
- --rule-file=/etc/thanos/rules/*.yaml
- --alertmanagers.url=dns+http://alertmanager.$(NAMESPACE).svc.cluster.local:9093
- --grpc-address=:10901
- --http-address=:10902
- --data-dir=/var/thanos/rule
- --query=dnssrv+_http._tcp.thanos-query.$(NAMESPACE).svc.cluster.local
- --eval-interval=20s
- --tsdb.retention=30d
env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
resources:
limits:
cpu: 4
memory: 4Gi
requests:
cpu: 250m
memory: 20Mi
# thanosio/thanos:v0.25.1
image: harbor.yee.com:8443/library/thanos:v0.25.1
volumeMounts:
- name: rules
mountPath: /etc/thanos/rules
- name: time
mountPath: /etc/localtime
livenessProbe:
failureThreshold: 4
httpGet:
path: /-/healthy
port: 10902
scheme: HTTP
periodSeconds: 30
name: thanos-query
ports:
- containerPort: 10901
name: grpc
- containerPort: 10902
name: http
readinessProbe:
failureThreshold: 20
httpGet:
path: /-/ready
port: 10902
scheme: HTTP
periodSeconds: 5
terminationMessagePolicy: FallbackToLogsOnError
terminationGracePeriodSeconds: 120
6. proxy
nginx的 auth_basic 认证
htpasswd -bdc htpasswd ${username} ${password} # 然后将转为 base64 即可获得
kind: ConfigMap
apiVersion: v1
metadata:
name: prometheus-proxy
namespace: monitor
data:
default.conf: |-
server {
listen 80;
location / {
auth_basic on;
auth_basic_user_file /etc/prom-auth/auth-file;
proxy_pass http://thanos-query.monitor.svc.cluster.local:9090;
}
}
---
apiVersion: v1
kind: Secret
metadata:
name: proxy-auth
namespace: monitor
type: Opaque
data:
auth-file: cHJvbWV0aGV1cy1wcm9kOiRhcHIxJGxRdnBqODBGJxxxVC5vN1c3czEK
---
apiVersion: v1
kind: Service
metadata:
name: prometheus-proxy
namespace: monitor
labels:
app: prometheus-proxy
spec:
ports:
- name: http
port: 80
targetPort: 80
selector:
app: prometheus-proxy
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-proxy
namespace: monitor
annotations:
kubernetes.io/ingress.class: nginx
spec:
rules:
- host: prometheus-query.yee.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-proxy
port:
number: 80
tls:
- hosts:
- prometheus-query.yee.com
secretName: yee.com
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-proxy
namespace: monitor
labels:
app: prometheus-proxy
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-proxy
template:
metadata:
labels:
app: prometheus-proxy
spec:
containers:
- name: proxy
image: nginx:latest
imagePullPolicy: Always
ports:
- containerPort: 80
volumeMounts:
- name: proxy-auth
mountPath: /etc/prom-auth
- name: auth-conf
mountPath: /etc/nginx/conf.d/default.conf
subPath: default.conf
volumes:
- name: proxy-auth
secret:
secretName: proxy-auth
- name: auth-conf
configMap:
name: prometheus-proxy
7. iplist
kind: ConfigMap
apiVersion: v1
metadata:
name: node-target
namespace: monitor
data:
node-target.yml: |-
#
- labels:
project: dc
job: dc-cdh
targets:
- 172.16.63.169:9100
- 172.16.63.173:9100
- labels:
project: ueba
job: secure
targets:
- 172.17.110.154:9100
8. node_exporter
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
# prom/node-exporter:v1.3.0
image: harbor.yeemiao.com:8443/library/node-exporter:v1.3.0
# 因的containerd配置文件写的state = "/data/containerd/run", 故排除data/containerd/
# docker默认的为/var/lib/docker/
args:
- --web.listen-address=$(HOSTIP):9110
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --collector.filesystem.mount-points-exclude==^/(dev|proc|sys|data/containerd/|var/lib/docker/.+)($|/)
- --collector.filesystem.fs-types-exclude=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9110
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 300m
memory: 512Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
# master节点都有污点,但是master节点也需要被监控,加入容忍污点,也就可以在master上部署一个客户端
tolerations:
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
9. Grafana
参考之前的文章 Grafana 高可用 Grafana高可用-LDAP
LDAP 可以不用配置
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: monitor
#annotations:
#volume.beta.kubernetes.io/storage-class: "nfs"
spec:
storageClassName: monitor-nfs-storage
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
kind: ConfigMap
apiVersion: v1
metadata:
name: grafana-config
namespace: monitor
data:
grafana.ini: |
[database]
type = mysql
host = mysql.prometheus.svc.cluster.local:3306
name = grafana
user = grafana
password = Man10f&3^H_98est$
[auth.ldap]
enabled = true
config_file = /etc/grafana/ldap.toml
[log]
level = debug
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana
namespace: monitor
spec:
rules:
- host: grafana-panel.yee.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
tls:
- hosts:
- grafana-panel.yee.com
secretName: yee.com
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: monitor
spec:
replicas: 2
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
securityContext:
runAsUser: 0
containers:
- name: grafana
# grafana/grafana:9.5.7
image: harbor.yeemiao.com:8443/library/rbac-grafana:9.5.7
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: Manifest%0304
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 2
memory: 2Gi
requests:
cpu: 150m
memory: 512Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: storage
- mountPath: /etc/grafana/grafana.ini
subPath: grafana.ini
name: config
# - mountPath: /etc/grafana/ldap.toml
# subPath: ldap.toml
# name: ldap
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
- name: config
configMap:
name: grafana-config
# - name: ldap
# configMap:
# name: grafana-ldap
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitor
spec:
type: ClusterIP
ports:
- port: 3000
selector:
app: grafana
四. 维护
- 在更改Prometheus 配置或者thanos-rule配置的时候,需要重启 这可以直接重启 kvass-coordinator 和 thanos-rule
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C# Break 和 Continue 语句以及数组详解
- 基于EEMD-SpEn(样本熵)联合小波阈值去噪
- 从零开始学Python系列课程第14课:Python中的循环结构(下)
- C#中如何稳定精确地每隔5ms执行某个函数?
- MongoDB入门介绍与实战
- 谈谈曲线与曲面
- c++算法之枚举
- python爬虫---网页爬虫,图片爬虫,文章爬虫,Python爬虫爬取新闻网站新闻!
- 【LeetCode每日一题】2744. 最大字符串配对数目
- python subprocess执行cmd同时输入密码获取参数