CMU15-445-Spring-2023-Project #3 - Query Execution
前置知识,参考上一篇博客:CMU15-445-Spring-2023-Project #3 - 前置知识(lec10-14
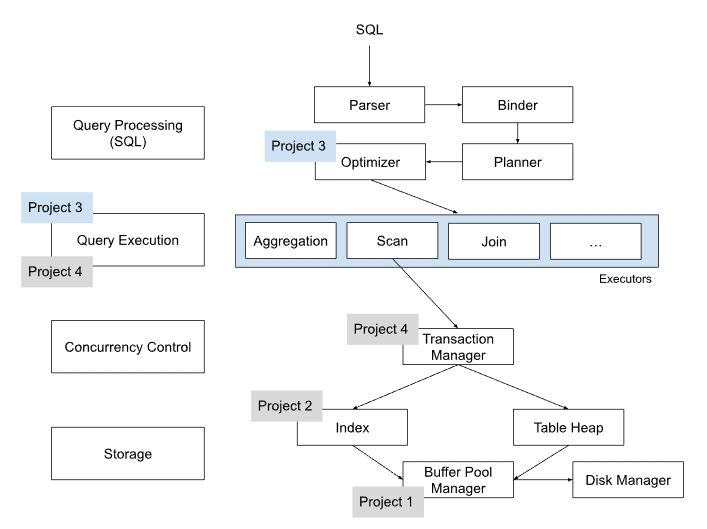
- Parser:将SQL query转变为AST
- Binder:将查询语句与数据库元数据进行绑定,验证查询的正确性和有效性
- Planner:为查询生成逻辑计划,描述查询操作的顺序和方式
- Optimizer:对逻辑计划进行优化转换和选择最优的执行计划,以提高查询性能。
为 BusTub 添加新的运算符执行器和查询优化。BusTub 使用迭代查询处理模型(火山模型),其中每个执行器都实现了一个 Next 函数,用于获取下一个元组结果。当 DBMS 调用执行器的 Next 函数时,执行器会返回 (1) 一个元组或 (2) 一个没有更多元组的指示符。通过这种方法,每个执行器都实现了一个循环,不断调用其子执行器的 Next 来检索元组并逐个处理。
在 BusTub 的迭代器模型实现中,每个执行器的 Next 函数除了返回一个元组外,还会返回一个记录标识符(RID)。记录标识符是元组的唯一标识符。
目录的全部实现都在 src/include/catalog/catalog.h 中。注意成员函数 Catalog::GetTable() 和 Catalog::GetIndex()。在执行器的实现中使用这些函数来查询目录中的表和索引。
对于表修改执行程序(InsertExecutor、UpdateExecutor 和 DeleteExecutor),必须修改操作目标表的所有索引。Catalog::GetTableIndexes() 函数在查询为特定表定义的所有索引时非常有用。一旦获得表中每个索引的 IndexInfo 实例,就可以在底层索引结构上调用索引修改操作。
BusTub 优化器是一种基于规则的优化器。大多数优化器规则以自下而上的方式构建优化计划。由于查询计划具有树形结构,因此在对当前计划节点应用优化器规则之前,首先要对其子节点递归应用规则。
在每个计划节点上,应确定源计划结构是否与要优化的计划结构相匹配,然后检查该计划中的属性,看是否能优化为目标优化计划结构。
/**
* Execute a query plan.
* @param plan The query plan to execute
* @param result_set The set of tuples produced by executing the plan
* @param txn The transaction context in which the query executes
* @param exec_ctx The executor context in which the query executes
* @return `true` if execution of the query plan succeeds, `false` otherwise
*/
// NOLINTNEXTLINE
auto Execute(const AbstractPlanNodeRef &plan, std::vector<Tuple> *result_set, Transaction *txn,
ExecutorContext *exec_ctx) -> bool {
BUSTUB_ASSERT((txn == exec_ctx->GetTransaction()), "Broken Invariant");
// Construct the executor for the abstract plan node
auto executor = ExecutorFactory::CreateExecutor(exec_ctx, plan);
// Initialize the executor
auto executor_succeeded = true;
try {
executor->Init();
PollExecutor(executor.get(), plan, result_set);
PerformChecks(exec_ctx);
} catch (const ExecutionException &ex) {
executor_succeeded = false;
if (result_set != nullptr) {
result_set->clear();
}
}
return executor_succeeded;
}
Task #1 - Access Method Executors
Impl:

- SeqScan
- SeqScanPlanNode 可通过 SELECT * FROM 表语句进行plan。
- SeqScanExecutor 对表进行遍历,每次返回一个表元。
- note:通过MakeIterator()生成迭代器遍历tuple。
- Insert
- 可以使用 INSERT 语句生成 InsertPlanNode。请注意,指定 VARCHAR 值时需要使用单引号。
- InsertExecutor 向表中插入元组并更新任何受影响的索引。该执行器有一个子执行器,可产生要插入表中的值。planner 将确保这些值与表的模式相同。执行器将生成一个整数类型的元组作为输出,表示有多少行被插入表中。如果表中有相关索引,请记住在插入表时更新索引。
- note:更新索引时,通过KeyFromTuple()生成key。
- Update
- UpdatePlanNode 可以用 UPDATE 语句进行生成。它有一个子节点,包含表中要更新的记录。
- UpdateExecutor 会修改指定表中的现有tuple。执行器将产生一个整数类型的元组作为输出,显示有多少行被更新。切记要更新受更新影响的索引。
- note:先删除,再更新(expr->evalutate),后插入。
- Delete
- DeletePlanNode 可以用 DELETE 语句进行生成。它有一个子节点,包含要从表中删除的记录。删除执行器应产生一个整数输出,表示从表中删除的记录数。它还需要更新任何受影响的索引。
- 假定 DeleteExecutor 始终处于它所出现的查询计划的根节点。DeleteExecutor 不应修改其结果集。
- IndexScan
- IndexScanExecutor 会遍历索引以检索tuple的 RID。然后,算子使用这些 RID 在相应的表中检索其tuple。然后,它会一次一个地emit这些tuple。
- 在本项目中,plan中索引对象的类型始终是 BPlusTreeIndexForTwoIntegerColumn。可以安全地将其转换并存储在执行器对象中:tree_ = dynamic_cast<BPlusTreeIndexForTwoIntegerColumn *>(index_info_->index_.get())。
- 然后,可以从索引对象构建一个索引迭代器,扫描所有键和tuple ID,从表堆中查找元组,并按顺序emit所有元组。BusTub 仅支持具有单个唯一整数列的索引。
Task #2 - Aggregation & Join Executors
添加一个aggregation executor、几个join executors,并使优化器在规划查询时能够在nested loop join和hash join之间进行选择。
Impl:
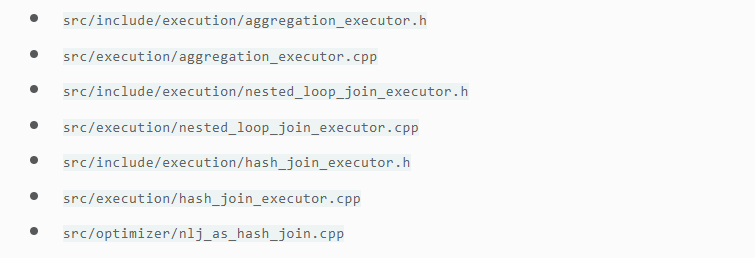
- Aggregation
- 为每组输入计算一个聚合函数(count*、count、min、max、sum)。它只有一个子执行器。输出模式由 group-by columns和aggregation columns组成。
- 实现聚合的常见策略是使用哈希表,并将group-by columns作为key。在这个项目中,可以假设聚合哈希表适合放在内存中。这意味着不需要实施基于分区的多级策略,哈希表也不需要由缓冲池页面支持。
- 提供了一个 SimpleAggregationHashTable 数据结构,它提供了一个内存中的哈希表(std::unordered_map),但其接口是为计算聚合而设计的。该类还提供了一个 SimpleAggregationHashTable::Iterator 类型,可用于遍历哈希表。需要为该类完成 CombineAggregateValues 函数。
- note:在init时就完成aggregation hash table初始化。
- NestedLoopJoin
- 默认情况下,DBMS 将对所有连接操作使用 NestedLoopJoinPlanNode。
- 使用类中的nested loop join算法为 NestedLoopJoinExecutor 实现INNER JOIN和LEFT OUTER JOIN(左边的表不受限制)。此算子的输出模式是左表中的所有列,然后是右表中的所有列。对于外层表中的每个元组,都要考虑内层表中的每个元组,如果满足连接谓词,则输出一个元组。
- 应在 NestedLoopJoinPlanNode 中使用谓词。请参阅 AbstractExpression::EvaluateJoin,它会处理左元组和右元组及其各自的模式。请注意,这将返回一个值,可能是 false、true 或 NULL。有关如何在元组上应用谓词,请参阅 FilterExecutor。
- note:对于每个left_tuple,先evaluate join,将匹配的emit,然后处理未匹配的,即右列的值为NULL。
- HashJoin
- 如果查询包含两个列之间等条件连接的连接(等条件之间用 AND 分隔),则 DBMS 可以使用 HashJoinPlanNode。
- 使用类中的hash join算法为 HashJoinExecutor 实现INNER JOIN和LEFT OUTER JOIN。此算子的输出模式是左表中的所有列,然后是右表中的所有列。与聚合一样,可以假定连接所使用的哈希表完全适合内存。
- note:init时即完成hash join,通过模板类自定义unordered_map的哈希函数。
- Optimizing NestedLoopJoin to HashJoin
- hash join通常比NestedLoopJoin产生更好的性能。当可以使用散列连接时,应修改优化器,将NestedLoopJoinPlanNode转换为HashJoinPlanNode。具体来说,当连接谓词是两列之间等条件的连接时,可以使用hash join算法。
- 在本项目中,处理单个等式条件以及通过 AND 连接的两个等式条件将获得满分。

- note:自下而上构建优化;需要检查等式条件每一边的列属于哪个表。外层表中的列有可能位于等价条件的右侧;最后返回HashJoinPlanNodeRef。
Task #3 - Sort + Limit Executors and Top-N Optimization
Impl:
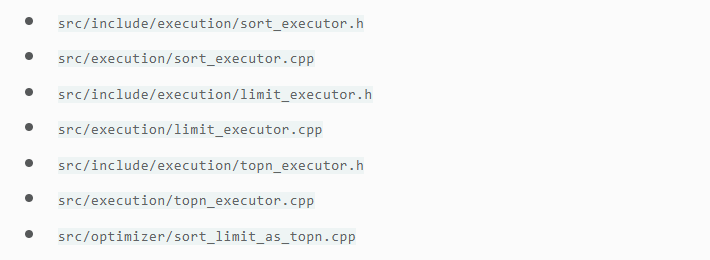
如果表上有索引,Query Processing层将自动选择它进行排序。在其他情况下,需要一个特殊的排序执行器来完成这项工作。
对于所有order by语句,假设每个排序键只会出现一次。
- Sort
- 如果查询的 ORDER BY 属性与索引的键不匹配,BusTub 将为查询生成一个 SortPlanNode;
- 该计划节点的输出scheme与其输入相同。可以从 order_bys 中提取排序键,然后使用带有自定义比较器的 std::sort 对子节点的元组进行排序。您可以假定表中的所有条目都完全适合内存。
- 如果查询不包含排序方向(即 ASC、DESC),则排序模式为默认模式(即 ASC)。
- Limit
- LimitPlanNode 指定查询将生成的tuple数。
- LimitExecutor 限制其子执行器输出的tuple数量。如果其子执行器产生的tuple数量少于plan node中指定的限制,则该执行器不会产生任何影响,并产生其接收到的所有tuple。
- 该计划节点的输出scheme与其输入相同。无需支持偏移。
- Top-N Optimization Rule
- 支持 top-N 查询。
- 默认情况下,BusTub 会将此查询规划为 SortPlanNode 和 LimitPlanNode。这样做效率很低,因为使用堆来跟踪最小的 10 个元素远比对整个表进行排序更有效。注意堆的输出顺序是相反的。std::priority_queue<Tuple, std::vector, decltype(cmp)> pq(cmp);
- 实现 TopNExecutor 并修改优化器,使其用于包含 ORDER BY 和 LIMIT 子句的查询。
更多优化,TODO。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机的性能指标
- rabbitMq 入门及面试大全
- 灌区信息化方案(什么是现代化灌区,如何一步到位)
- vu3+ts:mousedown mousemove mouseup 与 click事件冲突的解决办法
- mysql常用增删改查命令详解
- USACO备考冲刺必刷题 | P2722 Score Inflation
- 谁能分享下pmp备考指南?第七版PMBOK该怎么学?
- 云渲染服务器是什么东西?视频云渲染需不需要购买服务器吗?
- ConcurrentHashMap深度分析
- 海思 tcpdump 移植开发详解