【Java系列】详解多线程(二)——Thread类及常见方法(下篇)
个人主页:兜里有颗棉花糖
欢迎 点赞👍 收藏? 留言? 加关注💓本文由 兜里有颗棉花糖 原创
收录于专栏【Java系列专栏】【JaveEE学习专栏】
本专栏旨在分享学习Java的一点学习心得,欢迎大家在评论区交流讨论💌
一、启动一个线程-start()方法
在操作系统中创建线程时,通常会同时创建相应的PCB并将其加入到线程管理的数据结构中,比如线程链表或线程队列(此步骤是由操作系统内核来完成的)。
调用 start 方法, 才真的在操作系统的底层创建出一个线程。
解释:start 方法会通过调用系统API向操作系统请求创建一个新的线程,并分配相应的资源。这个请求将由操作系统内核处理,内核将为线程分配所需的资源。至于线程什么时候创建完成是由操作系统内核说了算的。
一旦操作系统内核完成资源的分配和初始化,线程就被创建出来了。此时,操作系统会将线程状态设置为就绪状态,表示该线程已经准备好被调度执行。线程调度器将在适当的时机选择一个就绪的线程,并将其分配给可用的CPU核心来执行。调用start方法是在操作系统底层创建一个线程的触发点。
另外,start方法的执行是在一瞬间就被执行完成的。因为start方法这是负责向操作系统中请求创建出一个线程,start方法执行完成之后,代码就会立即执行start方法后续的代码逻辑。
二、终止一个线程(重点)
我们知道,run方法执行完毕之后线程就结束了。这里我们说的终止线程就是想办法让run方法快速执行完毕(正常情况下run方法没有执行完的话线程是不会突然就结束了的,除非是特别极端的特殊情况,比如拔电源)。
(
方式一)手动设置标志位:
我们可以通过手动设定标志位的方式来让run方法快速执行完毕。
举例代码如下:
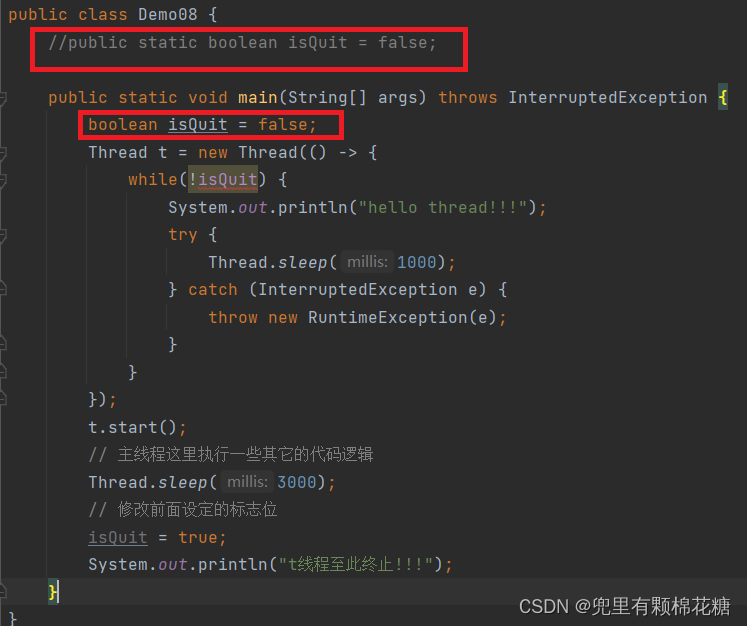
public class Demo08 {
public static boolean isQuit = false;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while(!isQuit) {
System.out.println("hello thread!!!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t.start();
// 主线程这里执行一些其它的代码逻辑
Thread.sleep(3000);
// 修改前面设定的标志位
isQuit = true;
System.out.println("t线程至此终止!!!");
}
}
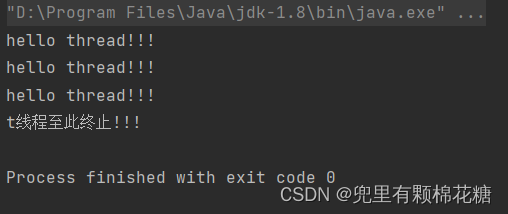
运行结果如下:
上述代码的执行结果其实是不稳定的,有时候可能会打印出来4个hello thread!!!因为sleep操作是存在误差的,比如如果真实的sleep时间比3000毫秒多的话,这里可能打印出来的就是4个hello thread!!!;如果这里真实的sleep时间比3000毫秒少的话,可能这里打印出来的就可能是两个hello thread!!!。
lambda变量捕获
现在将上述的代码进行细微的更改,请看:
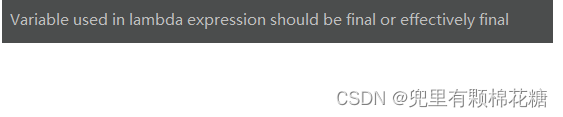
为什么这里的isQuit变量如果写作成员变量就不会报错,如果写作局部局部变量就会报错呢?
上述的错误原因是由于lambda变量捕获的原因,下面我们来进行解释:Lambda 表达式可以在其定义所在的方法的上下文中访问和使用外部变量,即Lambda表达式可以捕获外部变量。被Lambda表达式捕获的外部变量必须是final或是事实上final的。
上述代码中写的lambda表达式相当于一个回调函数,它的执行时机是在一个线程被创建好了之后,在另外一个线程内部被调用执行的。所以,lambda表达式的执行时机会稍后一些。所以这就导致后续我们执行lambda表达式的时候,局部变量isQuit已经被销毁了(isQuit局部变量是跟随main方法的),换句话来说main线程已经结束了,但是lambda表达式依然是在继续执行的。
上述这种情况是客观存在的,但是如果让lambda表达式去访问一个已经销毁了的变量这显然是不合适的。所以lambda表达式引入了变量捕获这样的机制。
lambda表达式的变量捕获机制:lambda表达式其实并不是直接访问的外部的变量,而是将外部的变量进行复制,即复制到lambda表达式内部(这样就解决了变量生命周期的问题)。
lambda表达式的变量捕获是有条件限制的:Lambda表达式内部访问的外部变量必须是final或者事实上是final(effectively final)。事实上是final的(即effectively final)意思就是变量可以不被final修饰,但是在代码中我们不能修改此变量,此时我们也可以称该变量是final effectively。如果对某变量进行修改的话,此时lambda表达式就不能对改变量进行变量捕获(之所以java中这样设定变量捕获是因为java是通过复制的方式来实现变量捕获机制的,如果外边的变量更改了但是lambda表达式内部的变量没有修改的话此时就很容易对代码产生歧义)。
相比之下,JS语言实现变量捕获的机制跟java中是有所区别的,JS并不是通过复制的方式来实现变量捕获的,而是通过直接改变外部变量的生命周期来保证lambda表达式可以访问到外部的变量,因此JS中的变量捕获的变量没有final或者effectively final的限制
以上是手动设置标志位的方式,其实在Thread类中已经为我们提供好了标志位:
Thread标志位,下面来看代码演示:
public class Demo09 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
// 这里的Thread.currentThread()其实就是t引用
// lambda表达式是在t构造之间就被定义好的。所以编译器构造的lambda表达式看到t之后就会认为t引用是一个还没有初始化的对象。
while(!Thread.currentThread().isInterrupted()) {
System.out.println("hello world!!!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
Thread.sleep(3000);
// 这里是把标志位设置为true
t.interrupt();
}
}
解释:
while(Thread.currentThread().isInterrupted())
Thread.currentThread()可以获取到当前线程的对象,currentThread方法是Thread类提供的一个静态方法,在哪个线程中调用这个方法我们就可以获得哪个线程对象的引用。
isInterrupted()是Thread类提供的一个标志位,如果为true的话代表线程应该要结束;如果为false的话代表线程可以不必结束。isInterrupted()用于检查当前线程是否被中断,并返回一个布尔值。如果线程没有被中断,该方法将返回false;如果线程被中断,该方法将返回true。。
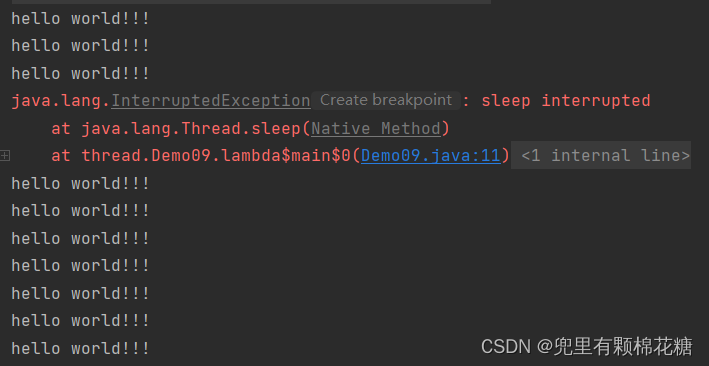
代码运行结果如下:
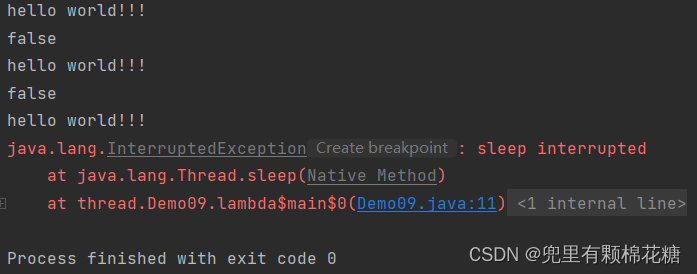
代码抛出异常后会继续打印hello world!!!,然后循环下去。
代码解释:代码中的t线程陷入睡眠之后又被interrupt唤醒了;如果我们手动设置标志位的话,是没有办法唤醒t线程的。
当一个线程正在睡眠(通过调用Thread.sleep()方法)时,如果其他线程调用了该线程的interrupt()方法,会导致正在睡眠的线程被强制中断,抛出InterruptedException异常。
注意:上述代码中,interrupt()方法是由主线程调用的。(当一个线程A需要中断另一个线程B时,它可以调用线程B的 interrupt() 方法。这个调用会将线程B的中断状态标志位设置为 true,即表示线程B被请求中断。)
在上述代码中,当t线程被interrupt()方法唤醒时(举个栗子,比如我们设定的sleep(1000),但是此时才过去10毫秒,但是线程依然会被唤醒),它的中断标志位会被设置为true。而sleep()方法会抛出InterruptedException异常,同时会清除中断标志位。因此,在上述代码中,当sleep()方法被interrupt()方法唤醒时,它会抛出InterruptedException异常,并清除中断标志位。因此,前面设置的标志位会被清除。此时,中断标志位会被重新设置为false。
当中断标志位被重新设置为false之后,while循环会继续进行打印操作。
重点:上述的代码大家一定要好好进行理解,尤其是中断标志位那个地方,有很多的小点需要大家注意。
上述代码中,sleep被唤醒的同时,中断标志位被重新设定为了
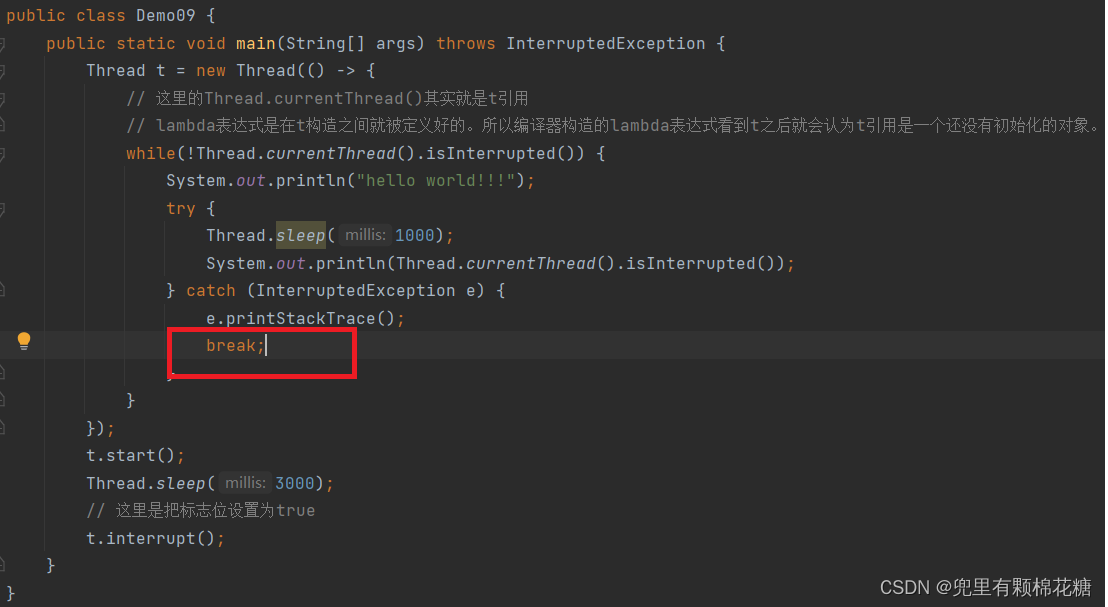
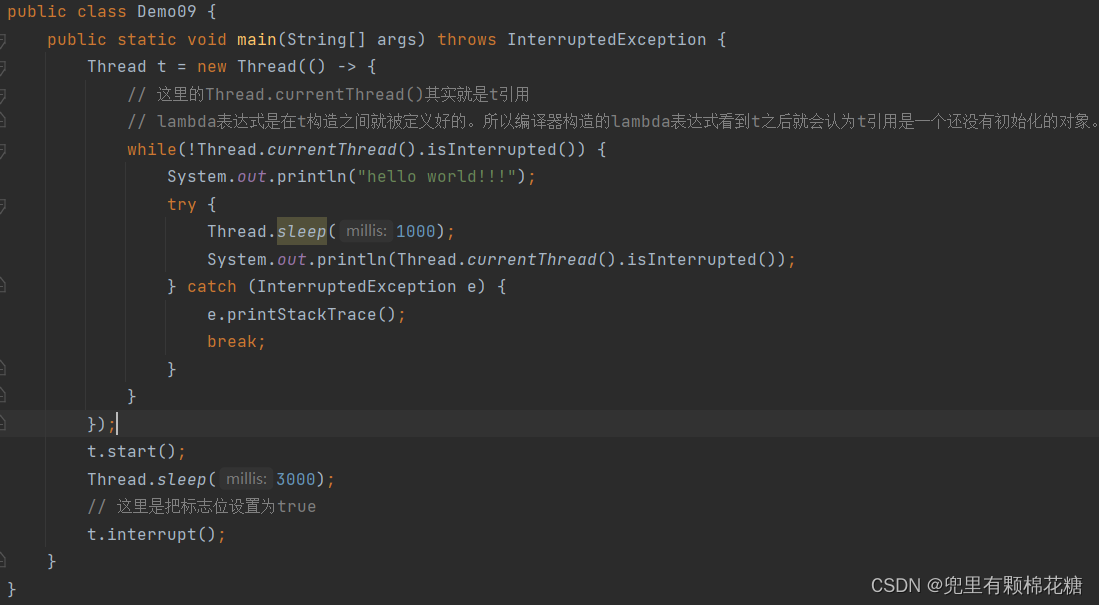
false;之后,线程会继续执行下去,但是如果我们想要让线程结束的话,此时我们只需要在catch之后加上break就可以了。演示代码如下:
运行结果如下:
异常信息打印出来之后,代码中的while循环就会被break,即使我们不清除标志位的话,代码依然就会结束(当然加上break之后,标志位依然会被清除然后标志位会被重新设置为false)。
还有一点就是如果我们不想看到程序运行结果中的异常信息的话,我们可以直接注释掉catch中的e.printStackTrace();(用于打印异常的堆栈跟踪信息)就好了
关于sleep唤醒之后可以执行哪些操作:
我们这里依然是以刚刚上述的代码进行举例,如果你忘记了的话,请看下图:
sleep被唤醒之后,开发人员一般可以有以下几种操作方式(给开发者留下了一定的操作空间,具体要干什么还是要根据具体的时机需求来决定):
- 立即结束线程(如上图就是加上break之后就会立即结束线程)
- 执行其它的一些代码逻辑,执行完这些代码逻辑之后再结束线程(即再
catch中执行执行其它的代码逻辑,等到这些代码逻辑执行结束之后再break就可以了) - 或者忽略终止请求继续循环下去(即
catch中不写break就好了)
判断中断标志位的两种方式:
- Thread.interrupted():这是一个静态方法,
此方法在判定标志位的同时会对标志位进行清除 - Thread.currentThread().isInterrupted():这是一个成员方式(
推荐使用这种方式)判断标志位的时候不会进行清除
三、等待一个线程-join()
我们知道多个线程是并发执行的,具体的执行过程都是由操作系统进行调度的,而操作系统调度线程的过程是完全随机的,随机意味着我们不知道这些线程的执行的先后顺序是怎样的。而这里的等待线程就是用来规划线程结束顺序的手段
举个栗子:现在又A、B两个线程,我们希望B线程先结束而A线程后结束,所以可以让A线程中调用B.jion()的方法,此时B线程没有执行完的话,那么A线程就会进入阻塞状态(
阻塞状态的意思就是代码不继续往后执行了,即该线程暂时不去cpu上参与调度)。相当于给B线程留下了执行时间,当B线程执行完毕(即run方法执行完毕)之后,A线程就会从阻塞状态中恢复回来继续往后执行。
请看代码演示:
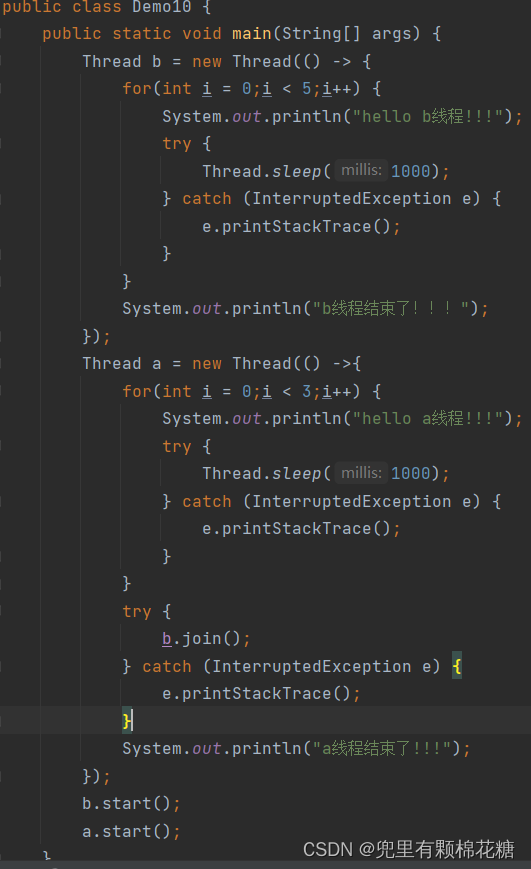
public class Demo10 {
public static void main(String[] args) {
Thread b = new Thread(() -> {
for(int i = 0;i < 5;i++) {
System.out.println("hello b线程!!!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("b线程结束了!!!");
});
Thread a = new Thread(() ->{
for(int i = 0;i < 3;i++) {
System.out.println("hello a线程!!!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("a线程结束了!!!");
});
b.start();
a.start();
}
}
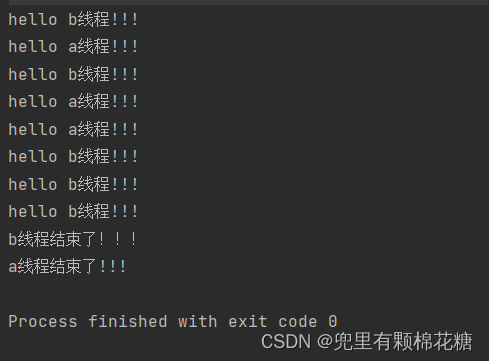
代码演示结果如下:
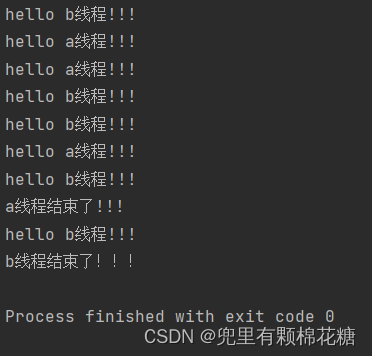
上述代码中是a线程先结束b线程后结束。
现在我们让b线程先结束a线程后结束的话,代码如下图:
运行结果如下:
如上图b线程先结束,a线程后结束。
关于阻塞阻塞状态的解释:阻塞状态就是线程代码不在继续往后执行了,即该线程不再参与cpu调度了。
sleep方法可以让线程进入阻塞状态,但是sleep方法的阻塞是有时间限制的。
而join方法的阻塞可以说是没有时间限制,如果有两个线程A、B,倘若是B.join()的话,如果B线程没有执行结束的话,那么A线程就会死等下去即A线程将永远不被执行知道B线程执行结束。
显然,jion方法的死等这样的方式是有些不大合适的,jion方法还有另外一种形式,即public void join(long millis)(等待线程结束,最多等millis毫秒),这里的参数相当于一个最大等待时间。
另外还有一点:join方法是可以被interrupt方法唤醒的,其实
sleep、join、wait方法产生阻塞之后都是可以被interrupt唤醒的(这几个方法在被唤醒之后会自动清除标志位,这一点和sleep类似)。
四、获取当前对象的引用
获取当前对象引用可以使用该方法:public static Thread currentThread();(可以返回当前线程对象的引用),在哪个线程中调用该方法就可以获取到哪个线程的引用。
五、休眠当前线程
休眠当前线程方法如下:
public static void sleep(long millis) throws InterruptedException:休眠当前线程millis毫秒public static void sleep(long millis, int nanos) throws InterruptedException:可以更高精度的休眠
好了,本文到这里就结束了,希望友友们可以支持一下一键三连哈。嗯,就到这里吧,再见啦!!!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机毕业设计 | 基于SpringBoot的健身房管理系统(附源码)
- 使用java解析xmind文件
- 【Gradio】1、Gradio 是什么
- python AI五子棋对战
- c++ 在类中调用另一个类
- Pycharm终端中conda无法切换到虚拟环境的解决方法(两种方案)
- RESTFul api相应状态码
- 损失函数中正则化中的平方项的作用!!
- 在C++中,如果你想要对其他类的对象数据进行增删改查(CRUD:Create, Read, Update, Delete),有几种常见的方式可以实现。
- GO EASY 游戏框架 之 GRPC 扩展篇 04