C++的构造析构函数
前言
本篇文章介绍C++的构造函数和虚构函数
写在前面
因为介绍构造函数基本都会设计虚函数和虚基类的使用,可以参考之前的文章:
C++中的虚函数
C++的虚基类
构造函数
每个类都分别定义了它的对象被初始化的方式,类通过一个或几个特殊的成员函数控制其对象的初始化过程,这些函数叫做构造函数。
所以说,构造函数的唯一作用就是初始化类的实例,注意初始化的意思两个:
- 在内存中给一个类的实例分配空间
- 给这个类的成员变量赋值
这也是初始化和赋值的区别:
初始化和赋值的区别就看操作的是不是一个新对象,如果一个新对象被定义,那就是初始化,如果没有新对象定义,那就是赋值。
构造函数的分类
从参数数量上,构造函数分为无参构造函数和有参构造函数,无参构造函数也叫做默认构造函数。
构造函数的生成
我们经常从资料上看到这么一句话:
如果一个类没有任何构造函数,编译器会创建一个默认构造函数
我们看下面的例子:
#include <iostream>
class A
{
public:
int a;
};
int main(int argc, const char* argv[])
{
A* a = new A();
a->a = 1;
}
上面的类A有默认构造函数吗?
答案是并没有
那a是怎么初始化的呢?
我们看一下代码执行a的初始化的时候的代码:
A* a = new A();
00007FF70EA624D3 mov ecx,1Ch
00007FF70EA624D8 call operator new (07FF70EA6104Bh)
00007FF70EA624DD mov qword ptr [rbp+0E8h],rax
00007FF70EA624E4 cmp qword ptr [rbp+0E8h],0
00007FF70EA624EC je main+5Eh (07FF70EA6250Eh)
00007FF70EA624EE mov rdi,qword ptr [rbp+0E8h]
00007FF70EA624F5 xor eax,eax
00007FF70EA624F7 mov ecx,1Ch
00007FF70EA624FC rep stos byte ptr [rdi]
主要操作有两步:
-
调用new函数在堆上分配了内存
-
重点是这句话
rep stos byte ptr [rdi]这句话的意思是给一段连续的内存赋值:
- 赋值开始地址保存在rdi寄存器,当前就是new分配的内存起始地址
- 赋值的长度保存在ecx寄存器,当前是1C,就是new分配时传入的参数
- 赋什么值保存在eax寄存器,
xor eax,eax,就是灵eax寄存器为0.
所以上面这行汇编的意思就是将这个类实例的内存全部初始化为0.
所以说一个类可以没有构造函数,这个时候,当初始化一个类的时候,直接根据类占用内存大小在栈或者堆中分配内存空间,然后初始化为0,仅此而已
那是不是说资料上的说法是错误的呢?其实,我们可以从两个角度来看是否存在默认构造函数:
- 从用户角度,上面的A虽然在代码中并没有生成默认构造函数,但是我们可以用调用默认构造函数一样的方法来创建一个类的实例,我们依然可以用下面的方法来创建A的实例,
对于用户来说,类一定有构造函数,编译器帮我们处理了没有任何构造函数的情况,并且还会将成员变量的值全部置成0.// 依然可以这么调用。仿佛类是有默认构造函数的。 A* a = new A(); a->a = 1; - 但是从编译器角度来看或者从代码角度看,一个类可以没有构造函数,但是类的实例依然可以被创建,只是分配空间和分配值而已。
如果有默认参数
一个类,作者可以定义构造函数,可以定义多个,有参无参都可以。如果一个含参的构造函数的所有参数都有默认值,也相当于类包含一个默认构造函数。
默认构造函数产生的条件
如果一个类没有构造函数,我们从上面知道,类实例化的时候的操作很简单,我们不讨论这部分,我们讨论存在默认构造函数的情况。
那么如果我们代码没有定义构造函数,编译器什么时候帮我们合成一个默认构造函数呢?
编译器生成默认构造函数的情况如下:
- 如果一个类没有任何构造函数,但是包含一个类类型的成员变量,并且该成员变量还有一个
默认构造函数。这时候编译器会为当前类生成一个默认构造函数,来调用成员变量的默认构造函数。 - 如果一个类没有任何构造函数,但是父类有默认构造函数,这时候编译器会为当前类生成一个默认构造函数,来调用父类的默认构造函数。
- 如果一个类没有任何构造函数,但是该类含有虚函数,这时候编译器会为当前类生成一个默认构造函数,来为类对象的虚函数表指针赋值。
- 如果一个类没有任何构造函数,但是该类带有虚基类,编译器会为当前子类和父类都生成一个默认构造函数
- 如果一个类没有任何构造函数,但是该类在定义成员变量的时候赋初值,这时候编译器会为当前类生成一个默认构造函数
接下来我们分析一下为什么这些情况需要默认构造函数,先看下面两个前提,所有的分析都是基于下面的两个前提:
- 首先,
编译器生成默认构造函数的前提是类一定没有定义任何构造函数。如果有构造函数,那所有的初始化工作应该是程序员负责,编译器可能进行协助。 - 第二,如果需要生成默认默认构造函数,说明肯定有事情需要做
- 包含一个类类型的成员变量,并且该成员变量还有一个默认构造函数时,不能直接把内存都设置为0,因为成员变量需要初始化,为啥需要初始化呢?因为成员变量也是一个类,并且有默认构造函数,即然有默认构造函数,成员变量初始化时肯定需要做些事情,可能给一个变量赋值,可能设置虚函数指针,反正内存不能都设置为0。即然成员变量内存不能都设置为0,当前类肯定也不能,因为当前类包含成员变量的内存。所以这个时候需要一个默认构造函数,默认构造函数会执行成员变量的默认构造函数
- 上面的说明对基类同样适用,因为类同样包含基类的内存部分
- 虚函数和虚基类就简单了,因为多了一个虚函数指针或者虚基类指针,需要在默认构造函数中给赋值。
- 最后如果给成员变量赋了初值。同样的意思就是类实例的内存必须要修改,不能都是0。
即使赋的初值是0也会生成默认构造函数。
列表初始化
构造函数的列表初始化是指在构造函数函数体执行之前执行的初始化操作,有些操作是我们自己添加的,有些是编译器帮我们添加的,总的来说,列表初始化的操作范围如下:
- 普通成员变量初始化
- 虚函数指针赋值
- 虚基类指针赋值
- 基类构造函数调用
- 类成员构造函数调用
这些基本都和上面我们介绍生成默认构造函数的条件是匹配的,我们现在来看一下这些初始化的顺序是怎样的。
看下面的代码:
class B1
{
public:
int b1 = 3;
};
class B2
{
public:
int b2 = 3;
};
class A:virtual public B1
{
public:
B2 b3;
int a1;
int a=0;
B2 b2;
A(int pA) :
a(pA) {}
virtual void A1() {}
};
我们看一下A的构造函数执行:
00007FF6A6122351 mov rax,qword ptr [this]
00007FF6A6122358 lea rcx,[A::`vbtable' (07FF6A612BC88h)]
00007FF6A612235F mov qword ptr [rax+8],rcx
00007FF6A6122363 mov rax,qword ptr [this]
00007FF6A612236A add rax,20h
00007FF6A612236E mov rcx,rax
00007FF6A6122371 call B1::B1 (07FF6A612154Bh)
00007FF6A6122376 mov rax,qword ptr [this]
00007FF6A612237D lea rcx,[A::`vftable' (07FF6A612BC80h)]
00007FF6A6122384 mov qword ptr [rax],rcx
00007FF6A6122387 mov rax,qword ptr [this]
00007FF6A612238E add rax,10h
00007FF6A6122392 mov rcx,rax
00007FF6A6122395 call B2::B2 (07FF6A6121541h)
00007FF6A612239A mov rax,qword ptr [this]
00007FF6A61223A1 mov ecx,dword ptr [pA]
00007FF6A61223A7 mov dword ptr [rax+18h],ecx
00007FF6A61223AA mov rax,qword ptr [this]
00007FF6A61223B1 add rax,1Ch
00007FF6A61223B5 mov rcx,rax
00007FF6A61223B8 call B2::B2 (07FF6A6121541h)
00007FF6A61223BD mov rax,qword ptr [this]
00007FF6A61223C4 lea rsp,[rbp+0C8h]
00007FF6A61223CB pop rdi
00007FF6A61223CC pop rbp
00007FF6A61223CD ret
通过上述汇编代码,我们能够得出下面的结论,注意,这些结论是针对于vs的编译器来说的,我个人觉得,有些初始化顺序是无所谓的,别的编译器并不一定和当前一致:
- 如果当前类是虚继承,先初始化虚基类指针。
基类的初始化发生在虚函数指针初始化之前。这个好理解,因为基类也有可能存在虚函数指针,我们必须保证最终的指针指向的是当前类的虚函数表。所以虚函数指针的初始化应该在基类的初始化后面才能覆盖之前的赋值。- 基类的初始化发生在成员变量初始化之前。
- 成员的初始化顺序与它们在类定义中的出现顺序一致。跟构造函数中初始值列表的顺序没有关系。
- 如果一个成员变量没有显示初始化,并且没有在定义的时候提供默认值,构造函数不进行处理
- 如果类有构造函数的话,不会将内存初始化为0
通过打印A的a1值发现,a1并不等于0,并且汇编代码中并没有将内存初始化为0的指令
如果类的成员是const、引用或者属于某种未提供默认构造函数的类类型,我们必须通过构造函数初始值列表为这些成员提供初值。
如果在构造函数中调用虚函数,并不通过虚函数表来调用,而是从起始构造函数向后查找,先找到虚函数就调用哪个?
不要在类的构造函数中和析构函数中调用虚函数
委托构造函数
委托构造函数使用它所属类的其他构造函数来执行它自己的初始化过程。
委托构造函数的使用注意事项:
委托构造函数的初始值列表只有一个,就是类名本身,相当于使用另外一个构造函数或者委托构造函数来进行初始化- 一般来说,委托构造函数的参数应该比初始化列表中的构造函数参数更少。
委托构造函数的执行顺序:
当一个构造函数委托给另一个构造函数时,受委托的构造函数的初始值列表和函数体先依次执行,然后执行构造函数的函数体
看下面的例子:
#include <iostream>
class A
{
public:
int a;
int b;
int c;
public:
A():A(0){std::cout<<"A()"<<std::endl;};
A(int pa):A(pa,0){std::cout<<"A(int)"<<std::endl;};
A(int pa,int pb):A(pa,pb,0){std::cout<<"A(int,int)"<<std::endl;};
A(int pa,int pb,int pc):a(pa),b(pb),c(pc){std::cout<<"A(int,int,int)"<<std::endl;};
};
int main(int argc, const char * argv[])
{
A a;
return 0;
}
输出结果如下:
A(int,int,int)
A(int,int)
A(int)
A()
什么时候执行默认构造函数
总得来说,当一个类执行默认初始化时会调用默认构造函数
默认初始化
- 当在块作用域内不使用任何初始值定义一个类的非静态变量或者数组时,该类执行默认初始化,如果类没有默认构造函数,编译器将报错
- 当一个类包含一个类成员时,在该类调用合成的默认构造函数时,该类成员执行默认初始化
- 当一个类包含一个类成员时,但是该类在执行构造函数时没有显式初始化该类成员,该类成员执行默认初始化
在实际中,即使定义了其他构造函数,最好也提供一个默认构造函数。
转换构造函数
如果一个构造函数只有一个实参,并且没有添加explicit修饰符,则该构造函数称为转换构造函数,转换构造函数定义了从实参类型到类类型的隐式转换机制。
看下面的例子:
class A
{
public:
int a=0;
A(int pA) :
a(pA) {}
};
我们可以使用下面的方法创建类A的实例:
int main(int argc, const char* argv[])
{
// 可以直接使用1来创建A的实例
A a = 1;
std::cout << "A::a=" << a.a << std::endl;
}
通过在函数定义前添加explicit修饰符,能够禁止隐式转换。
聚合类
满足下面这些条件的类称为聚合类:
- 所有的成员都是public的
- 类没有构造函数并且不会生成默认构造函数
- 类没有基类
聚合类可以使用初始化列表直接初始化类对象,使用形式跟数组是一致的。
静态变量
如果在类的外部定义静态函数,static关键字只能在函数声明的时候使用。
全局对象的分配
可执行文件中会保存全局对象在运行时的内存地址,在main函数体执行之前,会有编译器插入的代码:
- 给全局对象分配内存空间
- 将内存清0
- 调用全局对象的构造函数
- 然后才会执行main函数
- 在main函数执行完成后,会调用全局对象的析构函数
局部静态对象
局部静态对象是在第一次使用的时候才会被分配内存,并且进行初始化,并且编译器在局部静态变量所在内存位置添加了一个四字节标志,用来表示是否初始化成功。如果初始化成功,局部静态对象再次被使用的时候就不进行初始化了,并且向全局添加程序执行完成后的析构代码。
析构函数
析构函数的写法
- 析构函数由一个波浪号加类型名组成
- 析构函数没有返回值
- 析构函数没有参数
对于类A的析构函数写法如下:
~A();//声明
A::~A() {}//定义
析构函数是否存在
从编译器角度来说,析构函数和构造函数一样,不一定存在。并且析构函数和构造函数的区别在于析构完成后我们就不会在使用对象了,鉴于此,析构函数不需要考虑类似构造函数中的赋值操作。因为只要把内存释放了就行了,反正值也不会再用。所以析构函数存在的必要比构造函数低,析构函数存在的情况:
- 我们自己写了析构函数,这通常发生在对象中有手动分配的内存,或者当前类为基类,一般
基类中都要声明析构函数为虚函数 - 如果一个类的基类有析构函数,则编译器会为当前类合成一个析构函数,析构函数为了能调用基类的析构函数
- 如果当前类有一个类类型成员并且该成员有析构函数,则编译器会为当前类合成一个析构函数,析构函数为了能调用成员的析构函数
析构函数的特点
- 析构函数不能重载
- 析构函数不会销毁用户使用操作符在堆中创建的对象。需要用户在析构函数体中使用delete或者delete[]自己释放内存
析构函数的执行顺序
- 如果存在析构函数,先执行函数体
- 然后销毁成员,成员按照初始化顺序的逆序销毁
如果成员是基本类型,不用处理- 如果成员是类类型成员并且该成员有析构函数,调用类类型成员的析构函数的代码
- 如果一个类的基类有析构函数,调用基类析构函数的代码
下面看一段代码例子:
#include <iostream>
class A
{
public:
int a=3;
~A() {};
virtual void vA() {}
};
class A1
{
public:
int a1=2;
~A1() {};
};
class B :public A
{
public:
int b=10;
A1 a;
A1* a3;
int b1 = 20;
A1 a2;
B() { a3 = new A1(); }
~B() { delete a3; }
};
void test()
{
B b;
std::cout << "b::" << &b << std::endl;
std::cout << "b::size::" << sizeof(B) << std::endl;
}
执行test方法,我们得到b的内存大小为40个字节,分配顺序如下:
- 虚函数指针,占8字节
- 基类A的成员a=3,占4字节
- 边界对齐,占4字节
- 成员b=10,占4字节
- 成员a1,占4字节
- 成员A1指针,占8字节
- 成员b1=20,占4字节
- 成员a2,占4字节
下面是内存布局的截图:
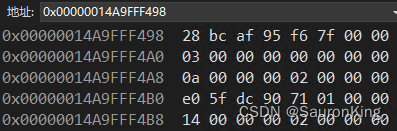
我们分析一下当test执行完成后析构的执行顺序,指令代码如下,关键位置我添加了注释。
00007FF695AF1E41 mov rcx,qword ptr [rbp+0C8h]
// 执行析构函数体 delete a3
00007FF695AF1E48 call A1::`scalar deleting destructor' (07FF695AF151Eh)
00007FF695AF1E4D mov qword ptr [rbp+0D8h],rax
00007FF695AF1E54 jmp B::~B+71h (07FF695AF1E61h)
00007FF695AF1E56 mov qword ptr [rbp+0D8h],0
00007FF695AF1E61 mov rax,qword ptr [this]
// 定位到成员变量a2处,a2是A1类的实例
00007FF695AF1E68 add rax,24h
00007FF695AF1E6C mov rcx,rax
// 调用a2的析构函数
00007FF695AF1E6F call A1::~A1 (07FF695AF1523h)
00007FF695AF1E74 mov rax,qword ptr [this]
// 定位到成员变量a1处,a1是A1类的实例
00007FF695AF1E7B add rax,14h
00007FF695AF1E7F mov rcx,rax
// 调用a1的析构函数
00007FF695AF1E82 call A1::~A1 (07FF695AF1523h)
// 定位到当前类实例的起始位置
00007FF695AF1E87 mov rcx,qword ptr [this]
// 调用基类的析构函数
00007FF695AF1E8E call A::~A (07FF695AF150Ah)
00007FF695AF1E93 lea rsp,[rbp+0E8h]
00007FF695AF1E9A pop rdi
00007FF695AF1E9B pop rbp
00007FF695AF1E9C ret
什么时候调用析构函数
- 栈中分配的对象在离开作用域的时候被销毁
- 当一个对象被销毁时,其成员被销毁
- 容器或数组被销毁时,其成员被销毁
- 动态分配的对象使用delete时被销毁
- 对于临时对象,当创建他的完整表达式结束时销毁
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- APT(高级持久性威胁)组织
- POLL机制
- 面试干货,左神532页刷题宝典助你大厂面试一臂之力
- Socks5代理IP在跨境电商与游戏中的应用
- pnpm : 无法加载文件 C:\Program Files\nodejs\pnpm.ps1,因为在此系统上禁止运行脚本。
- 人工智能_机器学习075_SVM支持向量机_算法整体回顾_总结_支持向量机_拉格朗日乘子法_KKT条件_对偶问题转换_SMO算法求解---人工智能工作笔记0115
- 数据库学习日常案例20231221-oracle libray cache lock分析
- 深入探索MySQL的innodb_thread_concurrency配置
- java练习题之接口interface练习
- 超详细YOLOv8目标检测全程概述:环境、训练、验证与预测详解