HuggingFists-低代码玩转LLM RAG-准备篇
????????之前写了几篇关于如何使用HuggingFists系统搭建LLM RAG应用的文章。对于使用者来说,HuggingFists现在能带来两大点帮助。一是能够以低代码的方式快速处理客户的各类存量文档,如Word、Visio、PDF等。这些文档内容多样,其中不乏需要用到OCR等相关技术才能识别和抽取的内容;二是可以帮助使用者快速搭建出LLM RAG的研究环境,可以对比研究各LLM的差异,RAG的应答效果评估以及积累Prompt的相关知识。下面我们就介绍一下如何搭建使用HuggingFists完成RAG相关流程的预备环境。
(注:访问下面的链接玩转数据之低代码LLM RAG准备篇_哔哩哔哩_bilibili?可观看与本文匹配的操作视频。)
环境安装
环境要求
Linux系统3.10.0-957.21.3.el7.x86_64
至少4核8G,系统使用Containerd容器
安装Milvus
1.下载配置文件
wget https://github.com/milvus-io/milvus/releases/download/v2.3.3/milvus-standalone-docker-compose.yml -O docker-compose.yml
2.启动milvus
sudo docker compose up -d
3.查看milvus运行状态
sudo docker compose ps
安装HuggingFists
1.从git上拉取工程文件 git clone https://github.com/Datayoo/HuggingFists.git, 或者直接使用download zip下载。需要注意的是,当使用Windows操作系统克隆项目时,Linux脚本文件中的'\n'会被替换为'\r\n'。当拷贝项目到Linux系统下时,由于'\n'的不同,脚本会无法执行。使用IDEA的开发者可以参考配置 Git 处理行结束符解决问题。
2.进入sengee.community.linux,执行安装脚本 bash install.sh。脚本执行结束后,可通过curl http://localhost:38172 测试系统是否正确安装。安装结束后,可通过访问url地址:“http://服务器IP:38172” 打开工具使用界面。 如果外部无法访问到页面,可以将服务器重启一次再试,算子平台会开机自启。启动成功后会看到如下界面:
??? 
HuggingFists配置
添加Milvus数据源
- 进入HuggingFists数据源管理,选择数据库菜单。

- 点击添加数据源按钮,选择创建Milvus数据源类型
?
- 在数据源地址中添加Milvus所在数据库的IP地址及端口号,点击“提交”按钮,创建Milvus数据源成功。在数据源列表中可以看到刚创建的好的Milvus数据源。
创建Milvus表(集合)
- 点击查看Milvus数据源,可以看到数据源中的数据表及浏览数据表中的数据。(注:刚安装完的Milvus数据源是空的)

- 点击“新建表”按钮;添加字段,必须为表指定一个主键字段。需要为表创建一个floatvector类型的向量字段。向量字段的长度必须要与使用的Embedding算法输出的向量长度一致,否则在插入向量时会报错。
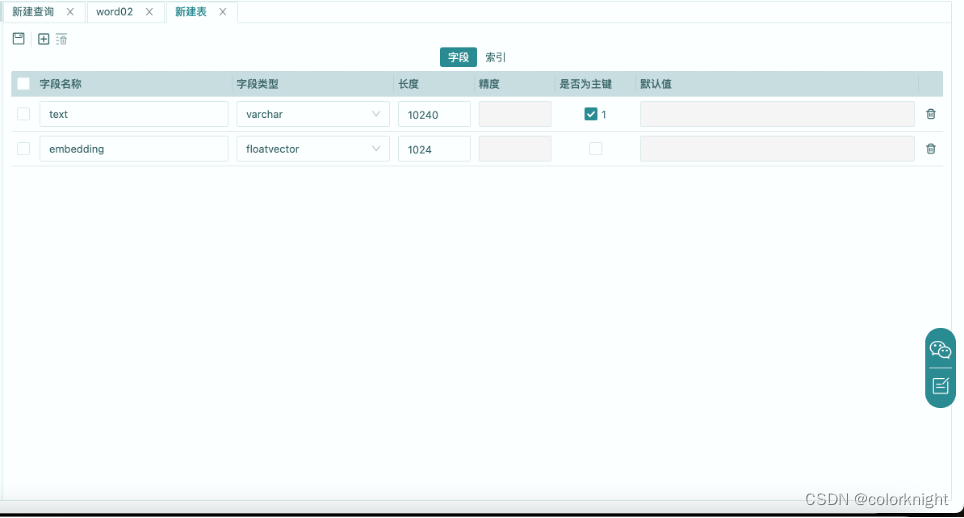
- 为向量表创建一个向量索引,如果不创建的话,对向量表的读取与写出都会引发错误。创建向量索引时,为向量字段指定索引类型,创建索引。
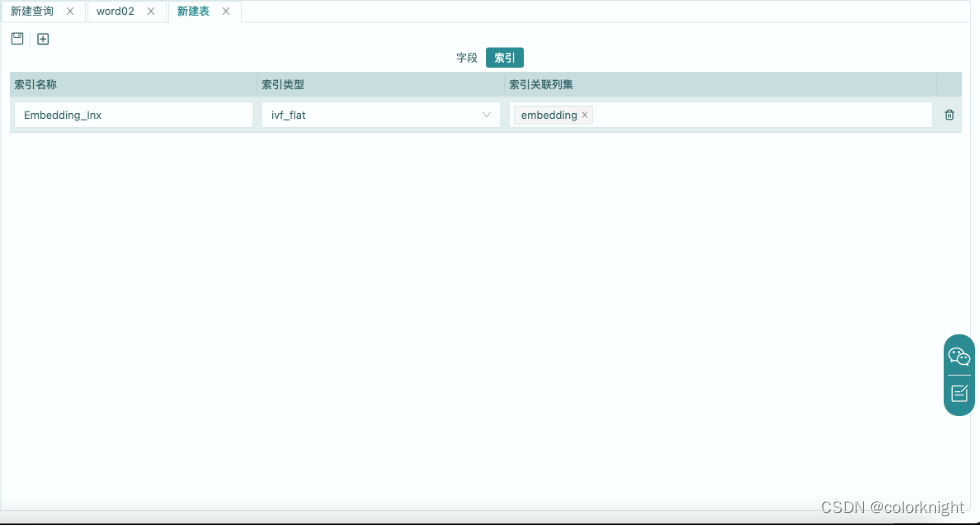
- 数据表创建成功,可以准备对milvus的读取或写出了。
添加阿里千问大模型访问账号
- 点击界面右上角的“user_name”,点击“个人设置”进入“资源账号”界面。
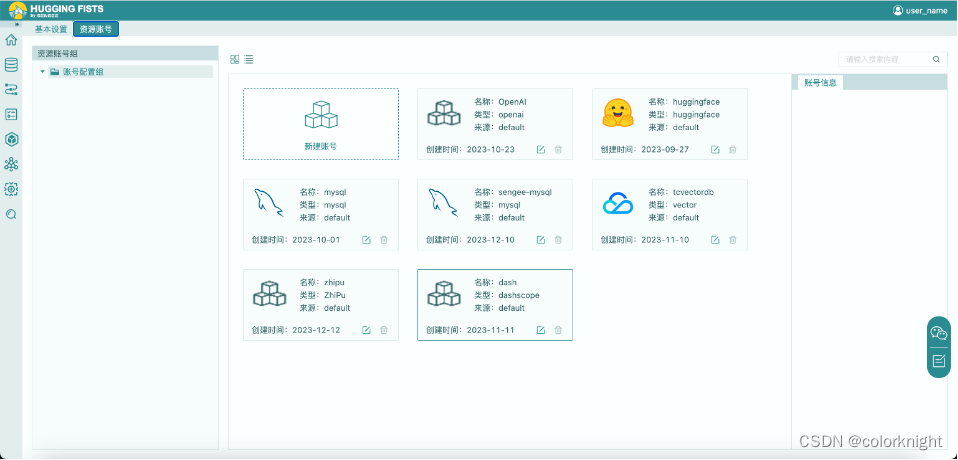
- 点击“新建账号”按钮,选择“Dash Scope”账号类型,填写“访问token”,创建账号。阿里“通义千问”账号的申请可参见链接“https://help.aliyun.com/zh/dashscope/developer-reference/quick-start”

添加Prompt模板
- 点击“资源库”,点击进入“Prompt”库
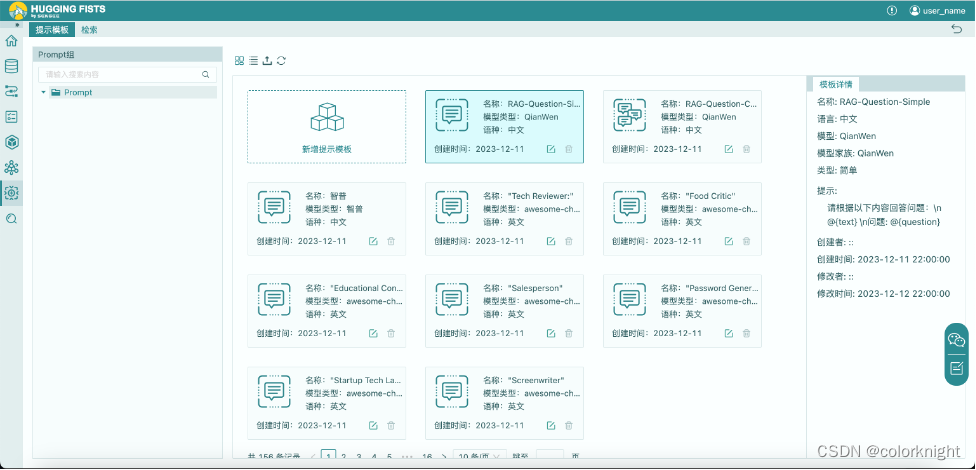
- 点击“新建提示模板”,创建Prompt模板。

- 创建“简单”提示模板,用于单轮提示RAG检索流程的编写。

提示:“请根据以下内容回答问题:\n @{text} \n问题: @{question}”
- 创建“复杂”提示模板,用于多轮提示RAG检索流程的编写。

前置提示:“我将输入多段信息,在我没有让你回答问题之前,你只需确认收到内容即可。”
提示:“@{text}\n请确认收到了信息,然后我将继续输入”
后置提示:“@{text}\n输入结束。请根据我之前输入的上下文回答问题,若上下文不足以回答问题,你则根据自己的知识回答以下问题: @{question}”
结束
??? 使用HuggingFists以低代码方式搭建LLM增强检索生成(RAG)的准备工作完成了,大家可以试试看了。另外,HuggingFists能做的事情还有很多,能接入的数据源很多,对结构化、半结构化数据的处理支持也很好,可以完成传统ETL工具的很多工作。如果有什么扩展需求的支持,可以通过GitHub留言或者扫描系统的中的微信号寻求技术支持。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PyTorch ,TensorFlow和Caffe之间的区别
- 网络安全(黑客)技术——自学2024
- 基于Python、Keras和OpenCV的实时人脸活体检测
- 爬虫如何使用代理IP通过HTML和CSS采集数据
- 基于SSM的厂区宿舍管理系统+66634(免费领源码)可做计算机毕业设计JAVA、PHP、爬虫、APP、小程序、C#、C++、python、数据可视化、大数据、全套文案
- 【软件测试】APP 上架指南:iOS App Store 首次上架被拒原因分析与解决方案
- 计算机毕业设计----SSH勤工助学管理系统
- Linux分割合并文件
- 企业如何使用WhatsApp进行营销?
- Hadoop-HDFS读流程(从输入命令到回显)