分布式锁4 :数据库DB实现分布式锁的悲观锁和乐观锁,unique实现方式
一? ?方案1 使用悲观锁解决冲突
1.1 使用悲观锁原理
1.1.1 使用悲观锁的原理
1.悲观锁:在select的时候就会加锁,采用先加锁后处理的模式,虽然保证了数据处理的安全性,但也会阻塞其他线程的写操作。在读取数据时锁住那几行,其他对这几行的更新需要等到悲观锁结束时才能继续 。select ... for update
悲观锁适用于写多读少的场景,因为拿不到锁的线程,会将线程挂起,交出CPU资源,可以把CPU给其他线程使用,提高了CPU的利用率。
1.1.2?使用悲观锁的优缺点
?优点: 1.简单容易理解;2.可以严格保证数据访问的安全;
?缺点:
1.即每次请求都会额外产生加锁的开销且未获取到锁的请求将会阻塞等待锁的获取,在高并发环境下,容易造成大量请求阻塞,影响系统可用性。另外,悲观锁使用不当还可能产生死锁的情况。
2.性能一般。
5.1.3?使用悲观锁的使用行锁&表锁
1.使用悲观锁时,查询条件必须添加索引,成为索引字段,才走行锁。
2.使用悲观锁是,查询条件不加索引,走表锁。
5.1.4?演示案例
1会话A未提交状态
在会话A中:??执行命令:? begin;select *??from db_stock where product_code='1001' for update
会话A:select ... for update???给具体的行数据加上排他锁(product_code加上索引),也即行锁。
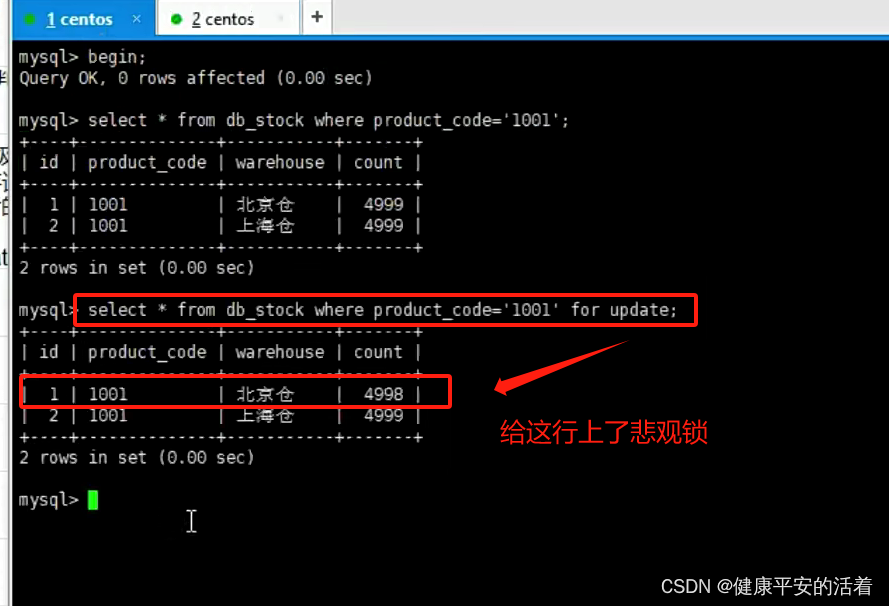
会话B :无法对1001进行更新,因为上了行级锁,无法进行更新

2会话A提交状态

会话B:进行了修改

? 1.2 操作案例
使用sql语句:?select ... for update???给具体的行数据加上排他锁(product_code加上索引),也即行锁。
1.mapper:编写悲观锁语句

2.service:添加事务注解??@Transactional

3.数据表

4.jmeter压力测试
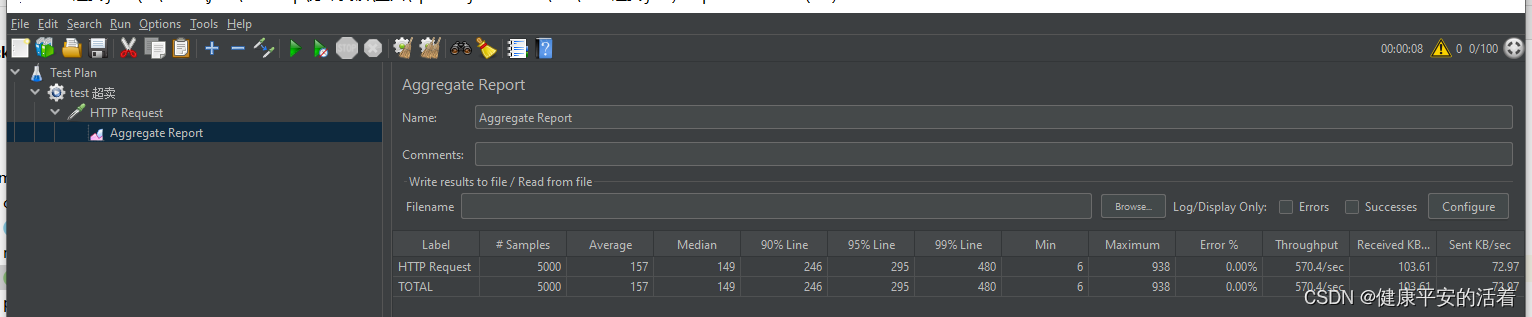
?5.查看效果:成功实现所减数据为0,均正确消费。
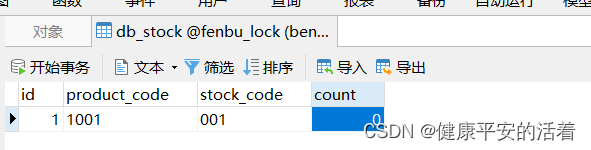
1.3 死锁场景模拟
1.表数据
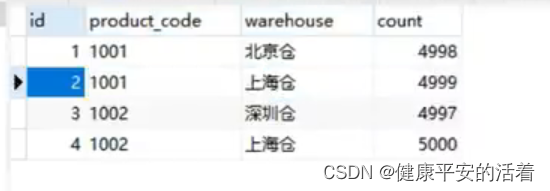
2.A会话
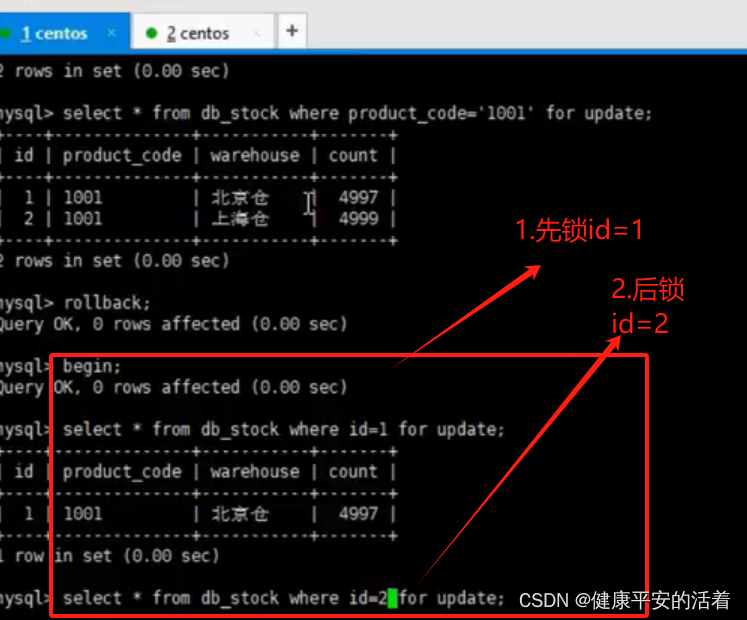
3.B会话
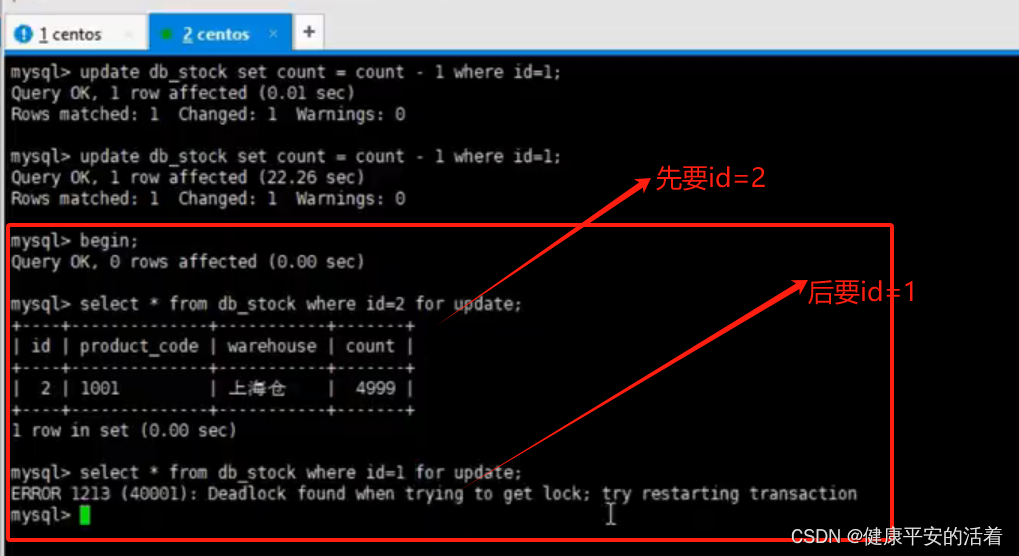
说明:A会话中,先锁住id=1,再锁住id=2;B会话中,先锁住id=2,再锁住id=1;彼此等待获取锁。则会造成死锁
1.4?此方案的优缺点
1.性能问题;2.死锁问题:对多条数据加锁时,加锁顺序要一致;
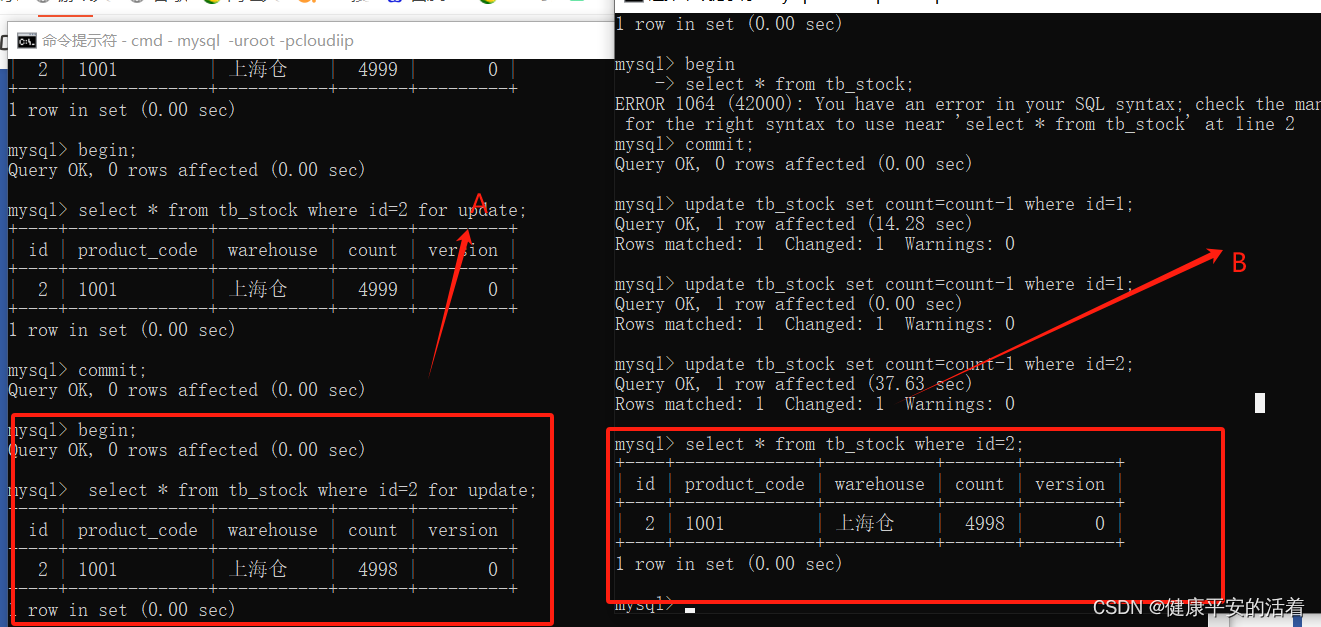
3.库存操作要统一,一个会话用 select??x for update??一个会话执行select可以进行查询 ,可能存在数据不一致情况。
会话A:进行查询上行锁,处于未commit状态时,会话B进行??select??查询,会话B可以查询出内容。
二? 方案2:使用乐观锁解决冲突
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据名称:大众点评POI数据数据年份:2022最新版数据量:4000w数据范围:全国范围数据变量:id、店铺id、店铺名称、店铺位置、店铺区县、店铺商圈、小类、大类、城市id、城市名、是否外卖、均价、
- MySQL命令速查——视图操作
- 3、Git分支操作与团队协作
- 支付行业迎穿透式监管,龙湖秘密收购上海电银合规存疑
- JavaScript-运算符-笔记
- SpringMVC(全局异常处理.动态接收Ajax请求)
- 微信分享返回APP后页面无法点击修复
- Mybatis-Generator-1.4.2
- ZLMediaKit 切换用于源的RingBuffer
- firewalld防火墙命令行工具