深度学习(七):bert理解之输入形式
传统的预训练方法存在一些问题,如单向语言模型的局限性和无法处理双向上下文的限制。为了解决这些问题,一种新的预训练方法随即被提出,即BERT(Bidirectional Encoder Representations from Transformers)。通过在大规模无标签数据上进行预训练,BERT可以学习到丰富的语言表示,从而在各种下游任务上取得优秀的性能。
BERT与之前的语言表示模型不同,BERT的设计目标是通过在所有层中联合考虑左右上下文,从无标签文本中预训练深度双向表示。因此,预训练的BERT模型只需添加一个额外的输出层,就可以用于各种任务,如问答和语言推理,而无需进行大量的任务特定架构修改。BERT在概念上简单而实证强大,它在包括自然语言处理任务在内的十一个任务上取得了新的最先进结果。
一.输入形式
为了使得BERT模型适应下游的任务(比如说分类任务,以及句子关系QA的任务),输入将被改造成[CLS]+句子A(+[SEP]+句子B+[SEP]) 其中
1.[CLS]: 代表的是分类任务的特殊token,它的输出就是模型的pooler output。
2.[SEP]:分隔符。
3.句子A以及句子B是模型的输入文本,其中句子B可以为空,则输入变为[CLS]+句子A。
在BERT中,输入的向量是由三种不同的embedding求和而成,在以下所举的例子中,每个单词都表示为一个768维的向量。具体形式如下图:

分别是Token嵌入层,Segment嵌入层和Position嵌入层,以下是对其介绍:
-
token嵌入层的作用是将单词转换为固定维的向量表示形式。在将输入文本传递到token嵌入层之前,首先对其进行token化。tokens化是使用一种叫做WordPiecetoken化的方法来完成的。这是一种数据驱动的token化方法,旨在实现词汇量和非词汇量之间的平衡。token嵌入层将每个wordpiece token转换为指定的高维向量表示形式。
-
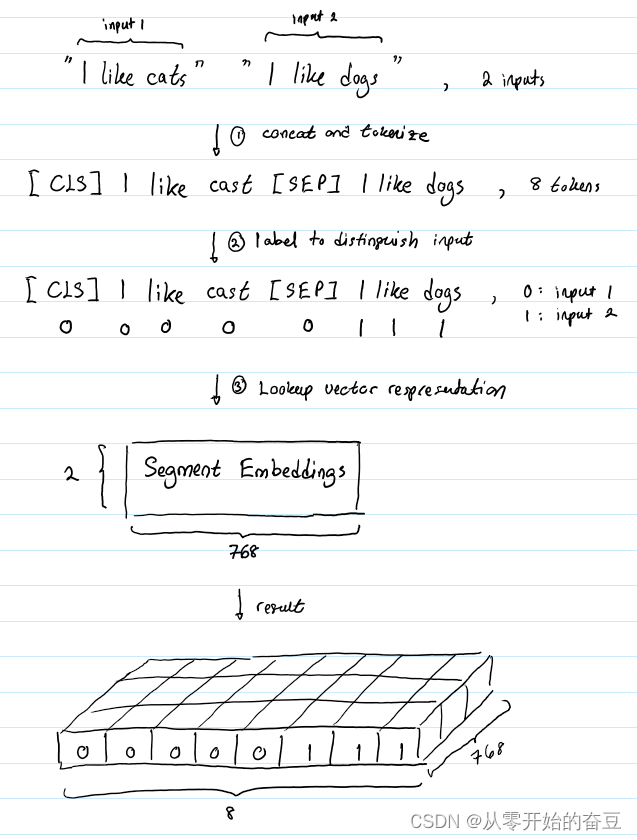
Segment嵌入层的作用是标记相同句子的每个词以区分不同的句子,假设我们的输入文本对是(“I like cats”, “I like dogs”),则Segment的标记过程如下图:
- Position嵌入层的作用为允许BERT理解给定的输入文本。例如语句“I think, therefore I am”,第一个I和第二个I不应该用同一向量表示。假设BERT被设计用来处理长度为512的输入序列。作者通过让BERT学习每个位置的向量表示来包含输入序列的顺序特征。这意味着Position嵌入层是一个大小为(512,768)的查找表,其中第一行是第一个位置上的任意单词的向量表示,第二行是第二个位置上的任意单词的向量表示,等等。因此,如果我们输入“Hello world”和“Hi there”,“Hello”和“Hi”将具有相同的Position嵌入,因为它们是输入序列中的第一个单词。同样,“world”和“there”的Position嵌入是相同的。
故综上可得出长度为n的token化输入序列将有三种不同的表示,即:
1.token嵌入,形状(1,n, 768),这只是词的向量表示
2.Segment嵌入,形状(1,n, 768),这是向量表示,以帮助BERT区分成对的输入序列。
3.Position嵌入,形状(1,n, 768),让BERT知道其输入具有时间属性。
对这些表示进行元素求和,生成一个形状为(1,n, 768)的单一表示。这是传递给BERT的编码器层的输入表示。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 男人女人都需要的技术活 拿去不谢:远程调试,发布网站到公网演示,远程访问内网服务
- Javascript 开发html网页读写IC卡源码
- python的configparser模块读入文件时出现UnicodeDecodeError: ‘gbk‘ codec can‘t decode
- 【教程】代码混淆详解
- MySQL进阶SQL语句
- 消防数据监测可视化大屏:守护城市安全的智慧之眼
- 可定制化的企业电子招标采购系统源码
- 爆款短视频拍摄的人员架构方案
- 氟里昂并联机组的制冷系统设计
- 【Databend】merge 的用法