【数据仓库与联机分析处理】多维数据模型
目录
数据仓库和OLAP工具是基于多维数据模型的,该模型以数据立方体(Cube)的形式来观察和分析数据。
一、数据立方体
????????区别于关系数据模型中的二维表,数据立方体是一个多维的数据模型,类似于一个超立方体。它允许从多个维度来对数据建模,并提供多维的视角以观察数据。
????????数据立方体由维和事实定义。一般来说,维是透视图或是一个组织想要记录的实体。在通常情况下,多维数据模型会围绕某个主题来构建,该中心主题被称为事实,事实是用数值来度量的。
一个分店的销售数据表,如表所示,分店的销售按照时间维(按季度组织)和商品维(按所售商品的类型组织)表示:
| XX武汉分店 | ||
|---|---|---|
| 时间(季度) | 商品(类型)(单位:台) | |
| 笔记本 | 台式机 | |
| Q1 | 408 | 887 |
| Q2 | 496 | 945 |
| Q3 | 522 | 768 |
| Q4 | 6000? | 1023 |
下面从三维角度观察销售数据,如表所示,添加一个分店地址维,从时间、商品类型和分店地址来观察数据。
| 时间(季度) | XX武汉分店 | XX宜昌分店 | XX北京分店 | XX郑州分店 | ||||
| 商品(类型)(单位:台) | ||||||||
| 笔记本 | 台式机 | 笔记本 | 台式机 | 笔记本 | 台式机 | 笔记本 | 台式机 | |
| Q1 | 408 | 887 | 609 | 1089 | 812 | 1280 | 321 | 654 |
| Q2 | 496 | 945 | 688 | 1671 | 1092 | 843 | 431 | 892 |
| Q3 | 522 | 768 | 789 | 1230 | 533 | 657 | 450 | 900 |
| Q4 | 600 | 1023 | 806 | 1800 | 1288 | 438 | 560 | 732 |
????????概念上讲,这些数据也能够以三维数据立方体的形式来表示。如果需要四维的数据,可以在上表的基础上再多添加一个供应商维度。虽然不能直观地去想象,但是可以把四维的数据看作是三维数据的序列。例如,供应商1对应一个三维数据立方体,供应商2对应个三维数据立方体……以此类推,就可以把任意n维数据立方体看作是n-1维数据立方体的序列。
????????需要注意的是,数据立方体只是对多维数据存储的一种抽象,数据的实际物理存储方式并不等同于它的逻辑表示。
二、数据模型
????????在数据库设计中,通常使用的是实体—联系数据模型,数据的组织由实体的集合和他们之间的联系组成,这种数据模型适用于联机事务处理。然而,对于数据仓库的联机数据分析,则需要使用简明、面向主题的数据模型。目前最流行的数据仓库数据模型是多维数据模型。这种模型常用的模式有三种,分别是星形模式、雪花模式、事实星座模式。
? ? ? ? 对于这三种模式的定义,将用到一种基于SQL的数据挖掘查询语言(Data Mining Query Language , DMQL)。DMQL包括定义数据仓库的语言原语。数据仓库可以使用两种原语进行定义,一种是立方体定义,一种是维定义。
立方体定义语句具有如下语法形式:?
define cube <cube_name>[<dimension list>]:<meature_list>
维定义语句具有如下语法形式:?
define dimension <dimension_name> as? (<attribute_or_subdimension_list>)
(一)星形模型
????????星形模式是最常见的模型范例,其包括:
(1)一个大的、包含大批数据、不含冗余的中心表(事实表);
(2)一组小的附属维表。
????????这种模式图很像是星星,如图所示,维表围绕中心表显示在中心表的射线上。在这个图中,一个销售事实表Sales共有四个维,分别为 time维、branch维、item维和 location维。该模式包含一个中心事实表Sales,它包含四个维的关键字和三个度量 units_sold、dollars_sold 和 avg_sales。
????????在星形模式中,每个维只用一个维表来表示,每个表各包含一组属性。例如,item 维表包含属性集 {item_key,item_name,brand,type,supplier_type},这一限制可能会造成某些冗余。例如,某些商品属于同一个商标,或者来自于同一个供应商。
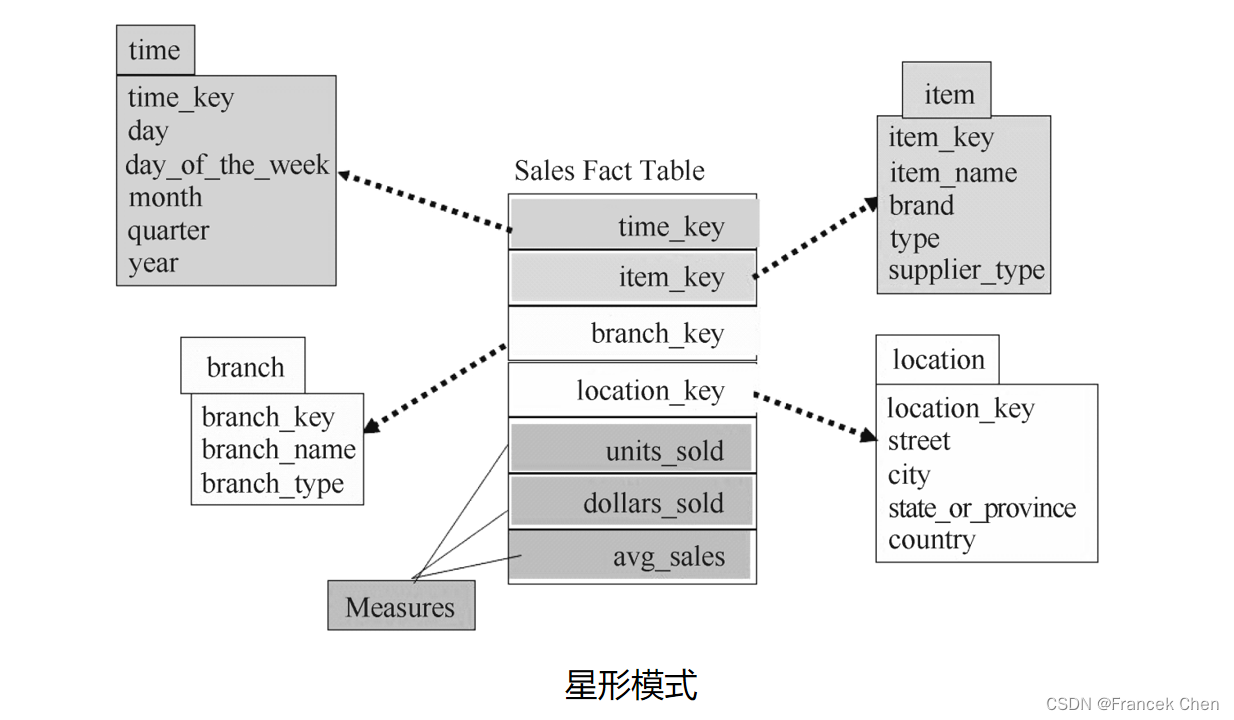
图中的星形模式使用DMQL定义如下:
define cube sales_star [time,item,branch,location]:?
dollars_sold = sum(sales_in_dollars), units_sold = count(*), avg_sales = avg(sales_in_dollars)
define dimension time as (time_key, day, day_of_the_week, month, quarter, year)
define dimension item as (item_key, item_name, brand, type, supplier_type)
define dimension branch as (branch_key, branch_name, branch_type)?
define dimension location as (location_key, street, city, state_or_province, country)?
????????define cube定义了一个数据立方体——sales _star,它对应于图中的中心表 Sales 事实表。该命令说明维表的关键字和三个度量:units_sold、dollars_sold 和 avg_sales。数据立方体有四个维,分别为 time、item、branch 和 location,其中每一个 define dimension 语句分别定义一个维。
(二)雪花模式
????????雪花模式是对星形模式的扩展,如图所示。在雪花模式中,某些维表被规范化,进一步分解到附加表(维表)中。从而使得模式图形变成类似于雪花的形状。从图中可以看到,location 表被进一步细分出 city 维,item 表被进一步细分出 supplier 维。

图中的雪花模式可以使用DMQL定义如下:?
define cube sales_snowflake [time,item,branch,location]:?
dollars_sold = sum(sales_in_dollars), units_sold = count (*), avg_sales = avg (sales_in_dollars)
define dimension time as (time_key, day, day _of _the week, month, quarter, year)?
define dimension item as (item_key, item_name, brand, type, supplier(supplier_key, supplier_type))?
define dimension branch as (branch_key, branch _name, branch_type)?
define dimension location as(lacation _key, street, city(city_key, state_or_province, country))?
????????该定义类似于星形模式中的定义,不同的是雪花模式对维表 item 和 location 的定义更加规范。在 sales_snowflake 数据立方体中,sales_star 数据立方体的 item 维被规范化成两个维表: item 和 supplier。注意 supplier 维的定义在 item 的定义中被说明,用这种方式定义 supplier,隐式的在 item 的定义中创建了一个 supplier_key。类似的,在 sales_snowflake 数据立方体中,sales_star 数据立方体的 location 维被规范化成两个维表 location 和 city,city 的维定义在 location 的定义中被说明,city_key 在 location 的定义中隐式地创建。
(三)事实星座模式
????????在复杂的应用场景下,一个数据仓库可能会由多个主题构成,因此会包含多个事实表,而同一个维表可以被多个事实表所共享,这种模式可以看作是星形模式的汇集,因而被称为事实星座模式。
????????如图所示,图中包含两张事实表,分别是 Sales 表和 Shipping 表,Sales 表的定义与星形模式中的相同。Shipping 表有五个维或关键字:time_key,item_key,shipper_key,from_location,to_ location。两个度量:dollars_cost 和 units_shipped。在事实星座模式中,事实表是能够共享维表的,例如,Sales 表和 Shiping 表共享 time、 item 和 location 三个维表。

图中的事实星座模式可以使用DMQL定义如下:
define cube sales [time,item, branch,location]:?
dollars_sold = sum(sales in dollars), units_sold = count (*), avg_sales = avg(sales_in_dollars)?
define dimension time as (time_key, day, day_of _the_Week, month, quarter, year)?
define dimension item as (item_key, item_name, brand, type, supplier_type)?
define dimension branch as (branch_key, branch_name, branch_type)?
define dimension location as (location_key, street, city, state_or_province, country)?
define cube shipping [time, item, shipper, from_location, to_location]:?
dollars _cost = sum(cost_in _dollars), units _shipped = count(*)?
define dimension time as time in cube sales?
define dimension item as item in cube sales?
define dimension shipper as(shipper_key, shipper_name, location as location in cube sales,?shipper_type)?
define dimension from_location as location in cube sales?
define dimension to_location as location in cube sales?
????????define cube 语句用于定义数据立方体 sales 和 shipping,分别对应图中的两个事实表。注意数据立方体 sales 的 time, item 和 location 维分别可以被数据立方体 shipping 共享,由于这三个维表已经在 sales 中被定义,在定义 shipping 时可以直接通过 “as” 关键字进行引用。
三、多维数据模型中的OLAP操作
????????在学习多维数据模型中的OLAP操作之前,首先需要认识一下概念分层。
????????概念分层提出的背景是因为由数据归纳出的概念是有层次的。例如,假定在一个location维表中,location是“华中科技大学”,可以通过常识归纳出 “武汉市” “湖北省” “中国” “亚洲” 等不同层次的更高级概念,这些不同层次的概念是对原始数据在不同粒度上的概念抽象。所谓概念分层,实际上就是将低层概念集映射到高层概念集的方法。
????????许多概念分层隐藏在数据库模式中。例如,假定 location 维由属性 number、street、city、province、country 定义。这些属性按一个全序相关,形成一个层次,如 “city<province<country”。维的属性也可以构成一个偏序,例如,time 维基于属性 day、week,month、quarter、year 就是一个偏序 “day<month<quarter;week}<year”(通常人们认为周是跨月的,不把它看作是月的底层抽象;而一年大约包含52个周,常常把周看作是年的底层抽象)。这种通过定义数据库模式中属性的全序或偏序的概念分层称作模式分层。
????????概念分层也可以通过对维或属性值的离散化或分组来定义,产生集合分组分层。例如,可以将商品的价格从高到低区间排列,这样的概念分层就是集合分组分层。对于商品价格这一维,根据不同的用户视图,可能有多个概念分层,用户可能会更加简单地把商品看作便宜、价格适中、昂贵这样的分组来组织概念分层。
????????概念分层允许用户在各种抽象级别处理多维数据模型,有一些OLAP数据立方体操作允许用户将抽象层物化成为不同的视图,并能够交互查询和分析数据。由此可见,OLAP为数据分析提供了友好的交互环境。
????????典型的OLAP的多维分析操作包括:下钻(Drill-down)上卷(Roll-up)切片(Slice)切块(Dice)以及转轴(Pivot)等。下面将以表“四个分店的销售数据表”的数据为例分别对这些操作进行详细介绍。
(一)下钻
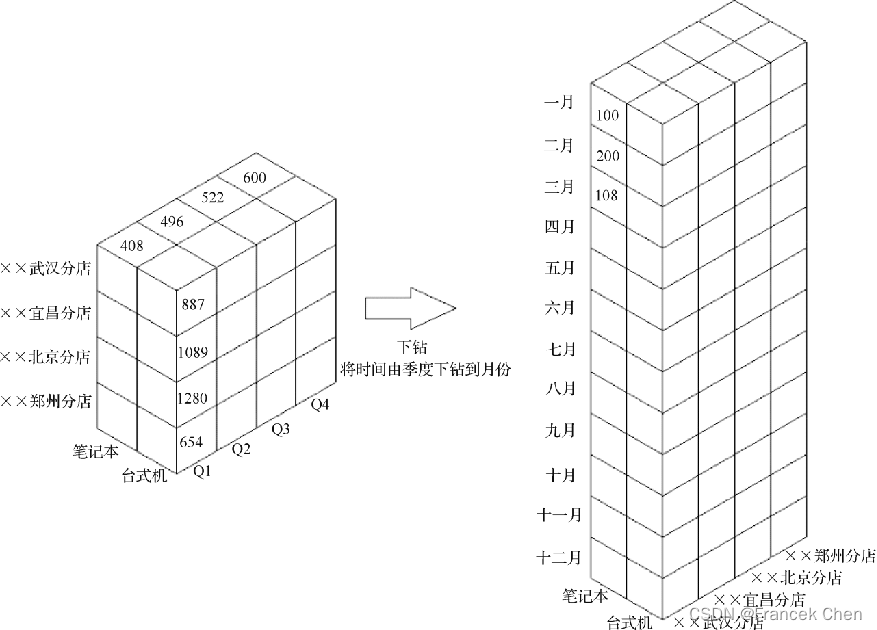
????????下钻(Drill-down)是指在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分成更加细节的数据。如图所示,下钻操作从时间这一维度对数据立方体进行更深一步的细分,从季度下钻到月份,从而能够针对每个月份的数据进行进一步更加细化的分析。
(二)上卷
????????上卷(Roll-up)实际上就是下钻的逆操作,即从细粒度数据向高层的聚合。如图所示,上卷操作也是从时间这一维度对数据立方体进行操作的,将第一季度和第二李度的数据合开为上半年的数据,将第三季度和第四季度的数据合并为下半年的数据,从而将数据聚合,使得在史高层次上讲行数据分析成为可能。?

(三)切片
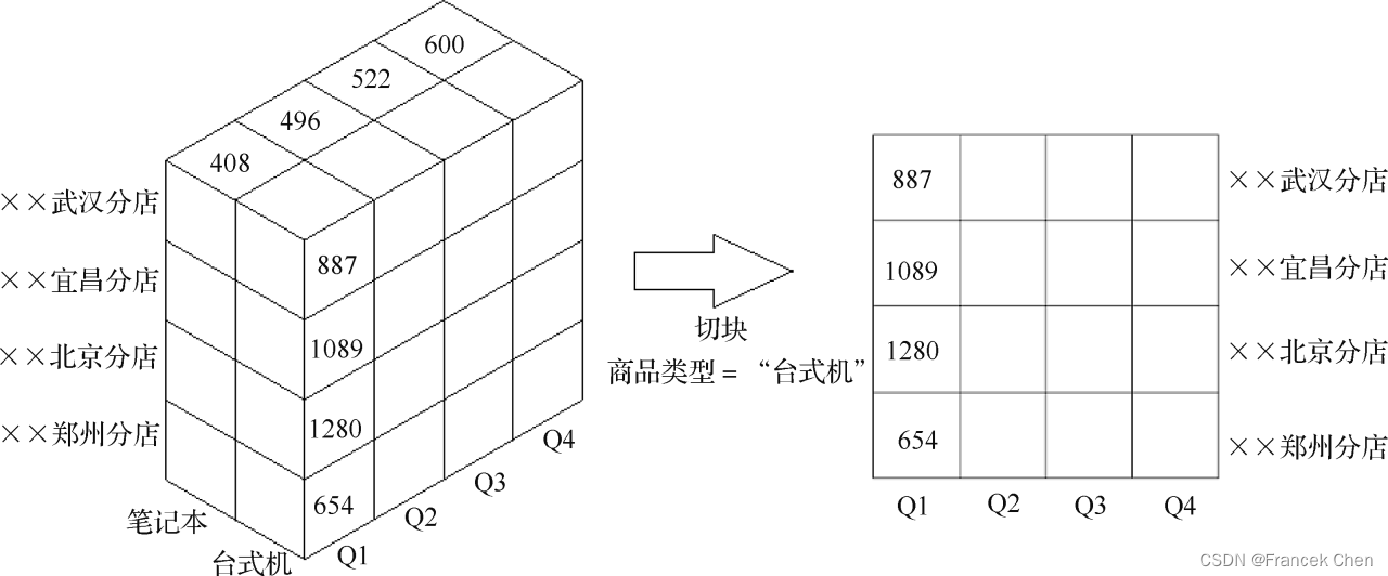
????????切片(Slice)是指选择维中特定区间的数据或者某批特定值进行分析。如图所示,对于商品类型这一维度添加限制条件,只针对台式机这个商品类型进行切片操作,就可以单独分析关于台式机的所有四个分店在各个季度的所有数据。
(四)切块
????????切块(Dice)操作通过在两个或多个维上进行选择,定义子数据立方体。如图所示,展示了一个切块操作,它涉及三个维,并通过指定商品类型、时间和分店这三个限制各件对据立方体进行切块。

(五)转轴
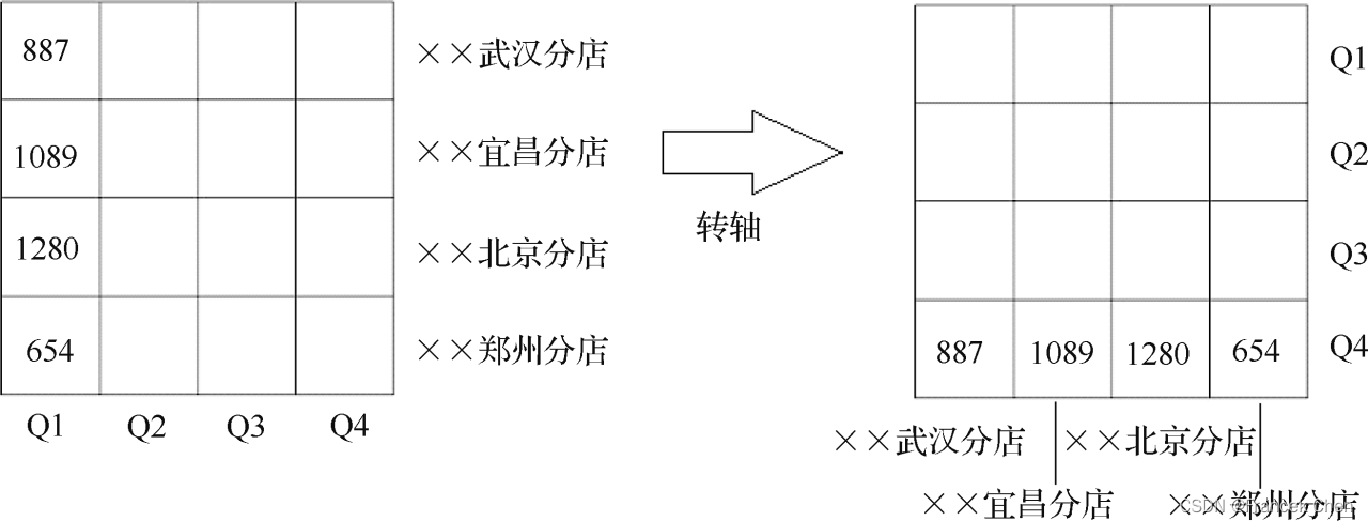
????????转轴(Pivot)即维的位置的互换,就像是二维表的行列转换。转轴操作只是转动数据的视角,提供数据的替代表示。如图所示,展示了一个转轴操作,转轴实际上只是将时间和分店这两个维在二维平面上进行转动。转轴的其他例子包括转动三维数据方体,或将一个三维立方体变换成二维的平面序列等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 液体装载机
- 使用Python实现简单的区块链
- 【UE5.1】给森林添加天气效果
- 20240116两点之间距离计算
- 基于Springboot的宠物领养系统(有报告)。Javaee项目,springboot项目。
- STM32标准库开发——串口发送/单字节接收
- 消耗服务器带宽的因素有哪些
- k8s的网络类型
- 极智一周 | 自动驾驶芯片、Mobileye EyeQ、高通骁龙、特斯拉FSD、地平线征程、华为昇腾 And so on
- 动手学深度学习3 数据操作+数据预处理