详解VIT(Vision Transformer)模型原理, 代码级讲解
发布时间:2024年01月16日
一、学习资料链接准备
1. 首先提供原始论文,VIT(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)模型提出论文下载:VIT论文??;
2.推荐的代码仓库,可以star我这个GitHub开源项目,对每行代码有详尽的注释:VIT模型详解
本篇博客和GitHub仓库,后面会持续更新,欢迎star;
二、模型亮点及整体架构介绍
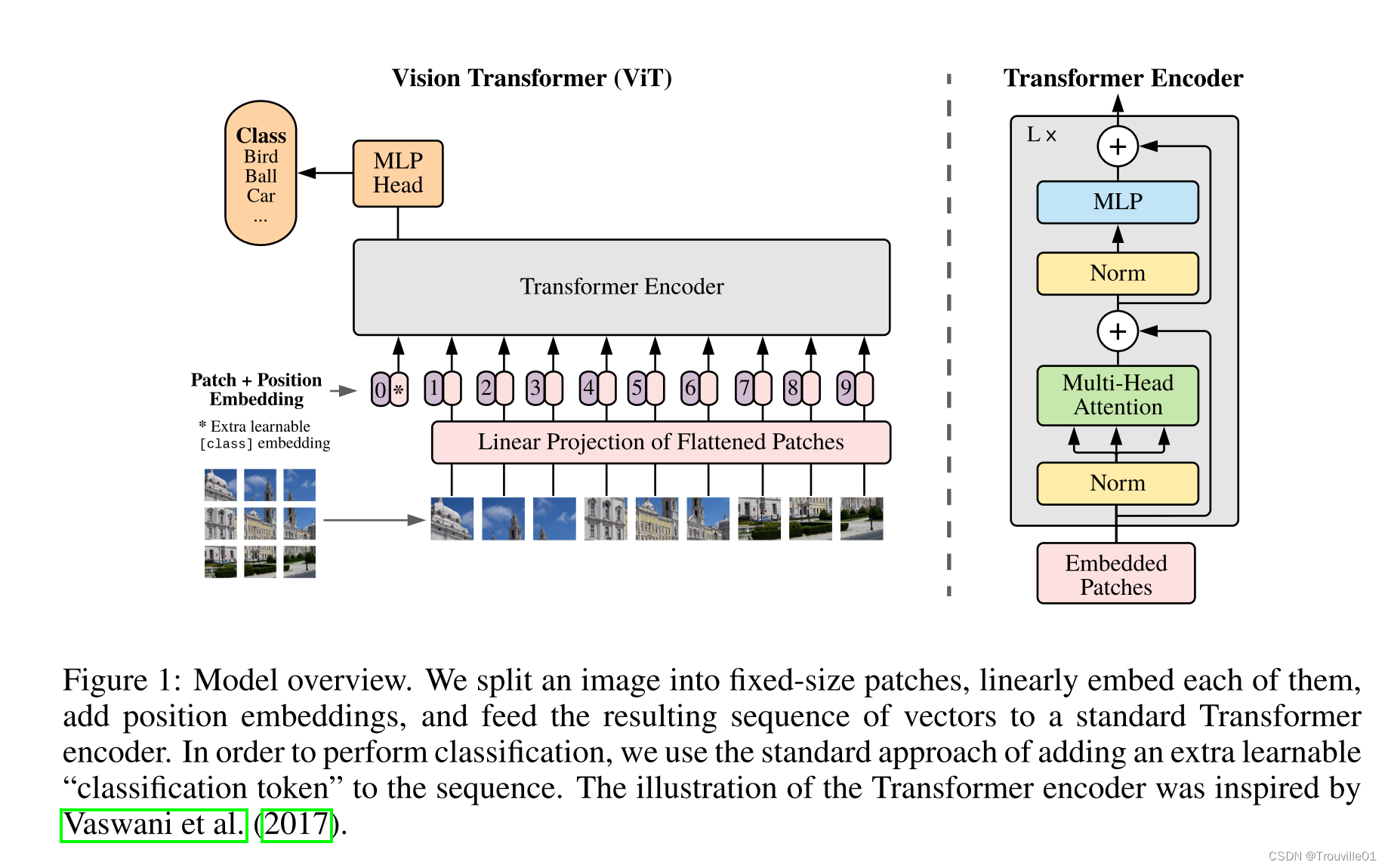
????????本篇文章首次发表在2021年ICLR上,首次将transformer模型运用到CV领域并且取得了相当高的分类效果,模型原理图如图1所示。模型提出将一幅图像切分成固定大小的patch(一般为16*16),然后进行线性排列后嵌入,为每个patch添加类别编码和位置编码之后输入到transformer编码器中,最后通过MLP进行分类预测。整篇文章最难理解的就是Transformer编码器结构中的多头注意力机制,下面我们来理解模型原理。
三、自注意力机制原理理解
1.
文章来源:https://blog.csdn.net/qq_43449643/article/details/135623953
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- BLHeli_S 代码分析---BLHeli.asm入口函数pgm_start分析
- xadmin-plus
- 记一次Android中获取时间戳在Java转字符串不正确的问题
- LoadRunner从零开始之软件性能测试
- 版本化数据库管理工具Flyway介绍和Spring Boot集成使用
- ip2domain - 批量查询ip对应域名、备案信息、百度权重
- python pandas操作
- MyBatis-Plus Page 分页不生效的问题处理
- 抖店怎么上架商品?流程如下,附现阶段打单发货教程
- EasyExcel 简单导入