Dataset和DataFrame的区别
发布时间:2024年01月18日
-
Dataset 和 DataFrame 的区别
-
DataFrame 就是 Dataset
根据前面的内容, 可以得到如下信息
- Dataset 中可以使用列来访问数据, DataFrame 也可以
- Dataset 的执行是优化的, DataFrame 也是
- Dataset 具有命令式 API, 同时也可以使用 SQL 来访问, DataFrame 也可以使用这两种不同的方式访问
所以这件事就比较蹊跷了, 两个这么相近的东西为什么会同时出现在 SparkSQL 中呢?
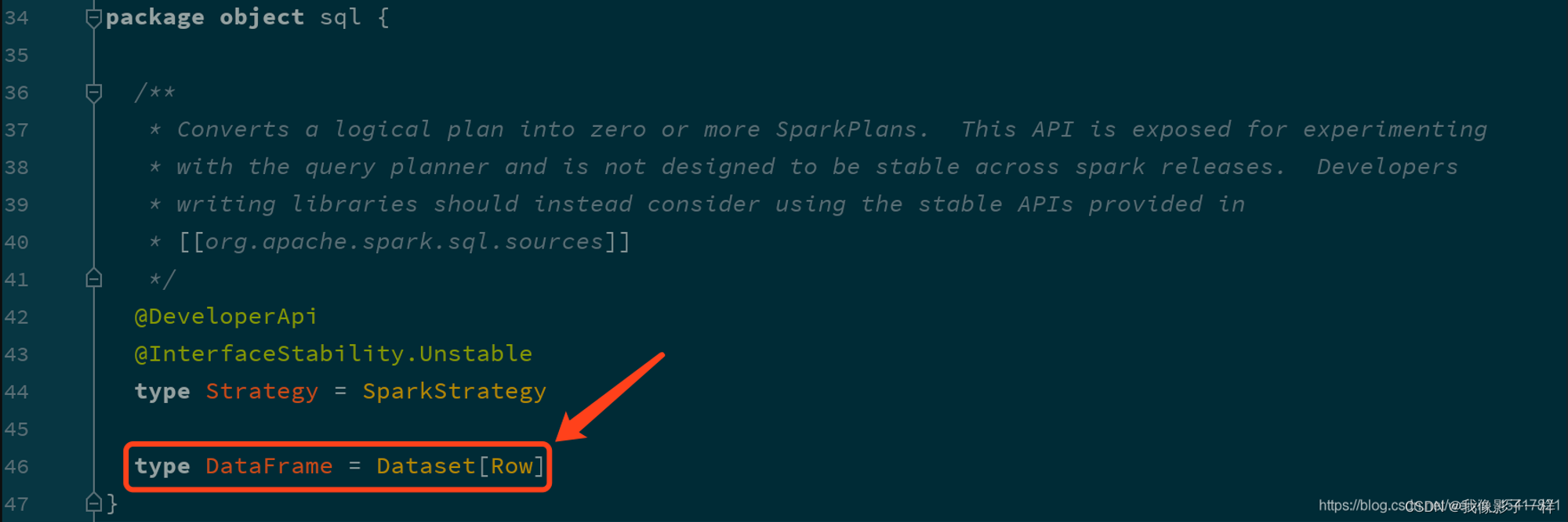
确实, 这两个组件是同一个东西, DataFrame 是 Dataset 的一种特殊情况, 也就是说 DataFrame 是 Dataset[Row] 的别名
-
DataFrame 和 Dataset 所表达的语义不同
- 第一点: DataFrame 表达的含义是一个支持函数式操作的 表, 而 Dataset 表达是是一个类似 RDD 的东西, Dataset 可以处理任何对象
- 第二点: DataFrame 中所存放的是 Row 对象, 而 Dataset 中可以存放任何类型的对象
@Test def dataframe3():Unit = { val spark = SparkSession.builder() .master("local[6]") .appName("dataframe3") .getOrCreate() import spark.implicits._ val personList = Seq(Person("zhangsan", 15), Person("lisi", 20)) // DataFrame 是弱类型的 val df:DataFrame = personList.toDF() // Dataset 是强类型 val ds:Dataset[Person] = personList.toDS() } case class Person(name: String, age: Int)- DataFrame 就是 Dataset[Row]
- Dataset 的范型可以是任意类型
-
第三点: DataFrame 的操作方式和 Dataset 是一样的, 但是对于强类型操作而言, 它们处理的类型不同
DataFrame在进行强类型操作时候,例如map算子,其所处理的据类型永远是Rowdf.map((row: Row) => Row(row.get(0), row.getAs[Int](1) * 2))(RowEncoder.apply(df.schema))show()但是对于
Dataset来讲,其中是什么类型,它就处理什么类型ds.map((person: Person) => Person(person.name, person.age * 2)).show()全代码
@Test def dataframe4(): Unit = { val spark = SparkSession.builder() .master("local[6]") .appName("dataframe4") .getOrCreate() import spark.implicits._ val personList = Seq(Person("zhangsan", 15), Person("lisi", 20)) // DataFrame 是弱类型的 val df: DataFrame = personList.toDF() // DataFrame 永远操作Row对象 df.map((row: Row) => Row(row.get(0), row.getAs[Int](1) * 2))(RowEncoder.apply(df.schema)) .show() // Dataset 是强类型 val ds: Dataset[Person] = personList.toDS() // Dataset 里面存放的是什么对象就操作什么对象,这里是 Person ds.map((person: Person) => Person(person.name, person.age * 2)) .show() } -
第四点: DataFrame 只能做到运行时类型检查, Dataset 能做到编译和运行时都有类型检查
- DataFrame 中存放的数据以 Row 表示, 一个 Row 代表一行数据, 这和关系型数据库类似
- DataFrame 在进行 map 等操作的时候, DataFrame 不能直接使用 Person 这样的 Scala 对象, 所以无法做到编译时检查
- Dataset 表示的具体的某一类对象, 例如 Person, 所以再进行 map 等操作的时候, 传入的是具体的某个 Scala 对象, 如果调用错了方法, 编译时就会被检查出来
// DataFrame所代表的弱类型操作是编译时不安全,运行时类型安全 df.groupBy("name, school") // Dataset所代表的操作是类型安全的,编译时安全的 ds.filter(person => person.school) //这行代码明显报错, 无法通过编译
-
Row 对象的操作
Row 是什么?
Row 对象表示的是一个 行
Row 的操作类似于 Scala 中的 Map 数据类型
@Test def row(): Unit = { // 1. Row 如何创建,它是什么 // row 对象必须配合 Schema 对象才会有列名 val p = Person("zhangsan", 15) val row =Row("zhangsan", 15) // 2. 如何从 Row 中获取数据 row.getString(0) row.getInt(1) // 3. Row 也是样例类 row match { caseRow(name, age) =>println(name, age) } } case class Person(name: String, age: Int)
-
DataFrame 和 Dataset 之间可以非常简单的相互转换
case class Person(name:String,age:Int) val spark = SparkSession.builder() .appName("df_ds") .master("local[6]") .getOrCreate() import spark.implicits._ val df: DataFrame = Seq(Person("zhangsan", 15), Person("lisi", 15)).toDF() val ds_fdf: Dataset[Person] = df.as[Person] val ds: Dataset[Person] = Seq(Person("zhangsan", 15), Person("lisi", 15)).toDS() val df_fds: DataFrame = ds.toDF()
总结
- DataFrame 就是 Dataset, 他们的方式是一样的, 也都支持 API 和 SQL 两种操作方式
- DataFrame 只能通过表达式的形式, 或者列的形式来访问数据, 只有 Dataset 支持针对于整个对象的操作
- DataFrame 中的数据表示为 Row, 是一个行的概念
-
文章来源:https://blog.csdn.net/m0_56181660/article/details/135637332
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux操作系统基础 – 管理目录
- C++八股学习心得.7
- LeetCode 21 合并两个有序链表
- [足式机器人]Part2 Dr. CAN学习笔记-Advanced控制理论 Ch04-5稳定性stability-李雅普诺夫Lyapunov
- 羊大师讲解喝羊奶的好处多,降低脂肪风险还有不少!
- JQuery的$(this)在if之后会变化
- 今日开幕!飞凌嵌入式受邀参加2023年瑞萨技术交流日全国巡回展
- 手把手带你死磕ORBSLAM3源代码(一)目录详解
- HDFS概述
- Mybatis 传参的方式