VITS(Conditional Variational Autoencoder with Adversarial Learning)论文解读及实现(一)
- 此篇为VITS论文解读第一部份
论文地址Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech - 模型使用了VAE,GAN,FLOW以及transorflomer(文本处理有用到),即除了未diffusion模型,将生成式模型都融入进来了,是一篇集大成的文章。涉及的知识点和公式也比较多(好在都是常用的公式)
- 模型结构及术语
①后验编码器posterior encoder p ( z ∣ x ) p(z|x) p(z∣x)
a.解释:在给定语音波形时,生成隐变量z的模型,
b. 输入是语音,
c. 输出是隐变量
②先验编码器prior encoder p ( z ∣ c t e x t , a ) p(z|c_{text},a) p(z∣ctext?,a)
a. 解释:给定文本和文本语音对齐矩阵A时,生成隐变量z的模型
b. 输入是文本和对齐矩阵A,
c. 输出是隐变量z
③解码器decoder p ( x ∣ z ) p(x|z) p(x∣z),
a. 解释:解码器是给定隐变量z时,生成音频波形x的模型,
b. 输入是隐变量
c. 输出是音频波形
④判别器discriminator D
a. 解释:判断一个音频波形数据是解码器生成的还是真时存在的
b. 输入音频波形,判断是真实音频还是模型生成的音频
c. 输出0~1的值
⑤随机时长预测 stochastic duration predictor
预测一个文本对应的波形时长(同一个人在一句话中同一个字的时长也是不同的,因此使用随机时长预测模型)
(备注,上面的音频波形都转换为mel线性谱使用,书写只是方便理解)
0 Abstract
In this work, we present a parallel endto-end TTS method that generates more natural sounding audio than current two-stage models. Our method adopts variational inference augmented with normalizing flows and an adversarial training process, which improves the expressive power of generative modeling. We also propose a stochastic duration predictor to synthesize speech with diverse rhythms from input text. With the uncertainty modeling over latent variables and the stochastic duration predictor, our method expresses the natural one-to-many relationship in which a text input can be spoken in multiple ways with different pitches and rhythms.
在这项工作中,我们提出了一种并行的端到端TTS方法,该方法比当前的两阶段模型产生更自然的声音。该方法采用normalizing flows(glow)增强的变分推理和对抗训练过程,提高了生成建模的表达能力。我们还提出了一个随机持续时间预测器,用于从输入文本合成具有不同节奏的语音。通过对潜在变量的不确定性建模和随机持续时间预测,我们的方法表达了一种自然的一对多关系,在这种关系中,文本输入可以以多个形式出现
1. Introduction
-
Text-to-speech (TTS)通常被简化为两阶段模型,
第一阶段是从文本生成语音的中间表征,如mel谱或者语音特征
第二阶段是根据中间表征生成波形图 -
我们提出了一种并行的端到端TTS方法
①Using a variational autoencoder (VAE) (Kingma & Welling, 2014), we connect two modules of TTS systems through latent variables to enable efficient end-to-end learning
使用VAE,我们通过隐变量连接TTS系统的两个模块,实现高效的端到端学习
②we apply normalizing flows to our conditional prior distribution and adversarial training on the waveform domain
我们将normalizing flow应用于我们的条件先验分布和波形域上的对抗训练。
③ we also propose a stochastic duration predictor to synthesize speech with diverse rhythms from input text.
我们还提出了一个随机持续时间预测器,用于从输入文本合成具有不同节奏的语音。
2 Method
- The proposed method is mostly described in the first three subsections:
①conditional VAE formulation;
②alignment estimation derived from variational inference; adversarial ③training for improving synthesis quality - 所提出的方法主要在前三个小节中进行描述:
①条件VAE公式;
②基于变分推理的对齐估计;
③提高合成质量的对抗性训练

2.1 Variational Inference
2.1.1 OVERVIEW
- VITS can be expressed as a conditional VAE with the objective of maximizing the variational lower bound, also called the evidence lower bound (ELBO), of the intractable marginal log-likelihood of data
l
o
g
p
θ
(
x
∣
c
)
log p_\theta (x|c)
logpθ?(x∣c)
VITS可以表示为一个条件VAE,其目标是最大化 l o g p θ ( x ∣ c ) log p_\theta (x|c) logpθ?(x∣c)的变分下界,也称为证据下界(ELBO)
变分公式:
l o g p θ ( x ∣ c ) > = ∑ q ? ( z ∣ x ) [ l o g p θ ( x ∣ z ) ? l o g q ? ( z ∣ x ) p θ ( z ∣ c ) ] logp_\theta (x|c)>= \sum q_\phi (z|x)[logp_\theta (x|z)-log\frac{q_\phi(z|x)}{p_\theta (z|c)}] logpθ?(x∣c)>=∑q??(z∣x)[logpθ?(x∣z)?logpθ?(z∣c)q??(z∣x)?]
等式后面可以展开为两项:
l o g p θ ( x ∣ c ) > = ∑ q ? ( z ∣ x ) l o g p θ ( x ∣ z ) ? ∑ q ? ( z ∣ x ) l o g q ? ( z ∣ x ) p θ ( z ∣ c ) logp_\theta (x|c)>= \sum q_\phi (z|x)logp_\theta (x|z)- \sum q_\phi (z|x)log\frac{q_\phi(z|x)}{p_\theta (z|c)} logpθ?(x∣c)>=∑q??(z∣x)logpθ?(x∣z)?∑q??(z∣x)logpθ?(z∣c)q??(z∣x)?
上式中第一项即为ELBO,第二项为KL散度
pθ(z|c) 是给定条件c 情况下,因变量z的先验分布
pθ(x|z) 是数据x的似然函数, (及解码器)
qφ(z|x) 是后验分布
训练损失是-ELBO, 及重构损失 ? log pθ(x|z)
2.1.2. RECONSTRUCTION LOSS
- 重构loss,使用梅尔谱图,而不是原始波形
- 我们通过解码器将隐变量z上采样到波形y,并将y变换到频谱域x_mel。然后将预测与目标mel谱图之间的L1 loss作为重建loss:
L r e c o n = ∣ ∣ ∣ x m e l ? x ^ m e l ∣ ∣ 1 L_{recon}=|||x_{mel} - \hat x_{mel}||_1 Lrecon?=∣∣∣xmel??x^mel?∣∣1? - 使用mel图谱作为损失的原因
1 能改善感知质量,因为mel图谱更能代表人的听觉系统
2 mel图片来自音频,因此不需要训练,只需要STFT和一个线性变换
3 只在训练阶段使用,对推理没有影响
2.1.3. KL-DIVERGENCE
- 条件c (由两部分组成ctext和A)
1 文本条件ctext
2 文本波形对齐矩阵A - 为了提高后验编码器能力,使用线性mel谱代替之前的mel谱
- 则KL 散度如下

- normalizing flow引入
发现增加后验分布的表现能力对真实样本对生成非常重要,引入flow ,使简单的分布变成更复杂的分布,
即对正太分布采样的z,先过一个normalizing flow,生成 f θ ( z ) f_\theta (z) fθ?(z),再正太分布生成 p θ ( z ∣ c ) p_\theta (z|c) pθ?(z∣c)
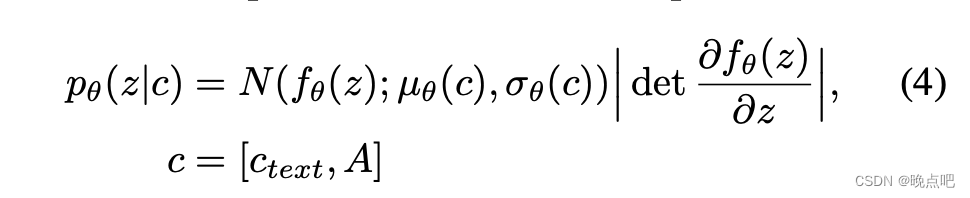
2.2. Alignment Estimation
2.2.1. MONOTONIC ALIGNMENT SEARCH
使用Monotonic Alignment Search方法,估计文本和目标语音的对齐矩阵A,
一个方法通过normalizing flow 最大化数据似然,算法感兴趣可以参考Monotonic Alignment Search论文

因为是优化ELBO,而不是直接优化p(x),因此对上述等式(5)进行变换,只提出和A有关的一项,得到下式(6)

2.2.2. DURATION PREDICTION FROM TEXT
文本持续时间预测
-
通过文本语音对齐矩阵,将语音求和 ∑ j A i j \sum_j A_{ij} ∑j?Aij?可以得到文本的持续时间,然后训练一个持续时间预测模型
缺点:不能表现一个人同一时刻的不同语速,(即统一因素时长都是同一个值) -
我们设计了一个随机时长预测模型,该模型基于flow ,目标是最大化似然,
-
因为每个因素的输入都是1,有以下2个问题
①是一个离散的整数,需要被量化后才能输入连续的 normalizing flows,
②是一个标量,阻止了高维变换, -
我们使用了variational dequantization和 variational data augmentation两种方法,
①我们引入两个随机变量u和ν,它们与持续时间序列d具有相同的时间分辨率和维度,分别用于variational dequatization 和 variational data augmentation,
②限制u的取值范围为 [0, 1),那么d-u就为正数,
③我们将ν和d通道连接起来,以获得更高维度的潜在表示。
④然后从后验分布 q ? ( u , v ∣ d , c t e x t ) q_\phi (u,v|d,ctext) q??(u,v∣d,ctext)中采样u,v,,目标是音素持续时间的对数似然的变分下界:
⑤loss为负变分下界
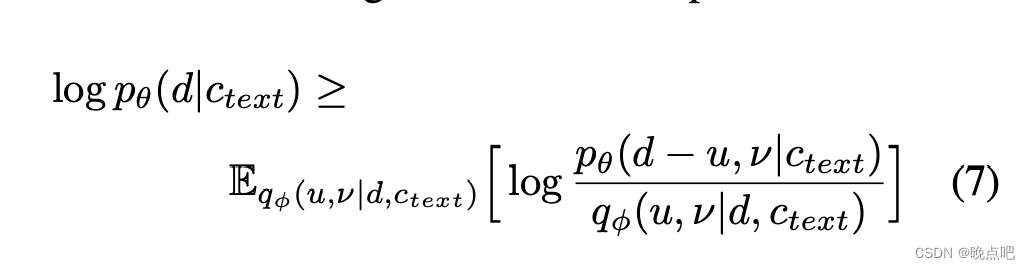
2.3. Adversarial Training
我们添加了一个判别器D来识别解码器G产生的输出和真实波形y
对抗损失和其他gan区别不大

2.4. Final Loss
结合VAE和GAN的训练,整体的VAE损失可以表示如下
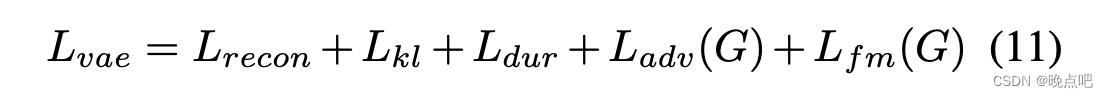
2.5. Model Architecture
- 该模型的整体架构由下面5部份组成。其中后验编码器
p
(
z
∣
x
)
p(z|x)
p(z∣x)和判别器D只用于训练,不用于推理。
①posterior encoder p ( z ∣ x ) p(z|x) p(z∣x)
②prior encoder p ( z ∣ c t e x t , a ) p(z|c_{text},a) p(z∣ctext?,a)
③decoder p ( x ∣ z ) p(x|z) p(x∣z),
④discriminator D
⑤ stochastic duration predictor
2.5.1. POSTERIOR ENCODER
- For the posterior encoder, we use the non-causal WaveNet residual blocks used in WaveGlow
对于后验编码器,我们使用WaveGlow中使用的非因果WaveNet残差块 - A WaveNet residual block consists of layers of dilated convolutions with a gated activation unit and skip connection. The linear projection layer above the blocks produces the mean and variance of the normal posterior distribution. For the multi-speaker case, we use global conditioning in residual blocks to add speaker embedding.
WaveNet残差块由带有门控激活单元和跳跃连接的膨胀卷积层组成。block层上方的线性投影层产生正态后验分布的均值和方差。对于多说话人的情况,我们在残差块中使用全局调节来添加说话人嵌入
2.5.2. PRIOR ENCODER
- encode 组成:
The prior encoder consists of a text encoder that processes the input phonemes ctext and a normalizing flow fθ that improves the flexibility of the prior distribution
先验编码器由处理输入音素文本的文本编码器和提高先验分布灵活性的规范化流fθ组成 - 文本编码器:
The text encoder is a transformer encoder that uses relative positional representation
文本编码器是使用相对位置表示的转换器编码器 - 模型输出
We can obtain the hidden representation htext from ctext through the text encoder and a linear projection layer above the text encoder that produces the mean and variance used for constructing the prior distribution.
我们可以通过文本编码器和文本编码器上面的线性投影层从文本中获得隐藏表示htext,该层产生用于构造先验分布的均值和方差。 - normalizing flow结构
The normalizing flow is a stack of affine coupling layers consisting of a stack of WaveNet residual blocks. For simplicity, we design
the normalizing flow to be a volume-preserving transformation with the Jacobian determinant of one.
归一化流是由一堆WaveNet残差块组成的一堆仿射耦合层。为了简单,我们设计归一化流是一个雅可比行列式为1,体积不变变换。 - 多说话人
For the multispeaker setting, we add speaker embedding to the residual blocks in the normalizing flow through global conditioning.
对于多说话人设置,我们通过全局调节将说话人嵌入到归一化流中的剩余块中。
2.5.3. DECODER
- decoder结构
The decoder is essentially the HiFi-GAN V1 generator
解码器本质上是HiFi-GAN V1发生器 - 结构组成:
It is composed of a stack of transposed convolutions, each of which is followed by a multireceptive field fusion module (MRF). The output of the MRF is the sum of the output of residual blocks that have different receptive field sizes
它由一堆转置卷积组成,每个转置卷积之后都有一个多接受场融合模块(MRF)。MRF的输出是具有不同接受野大小的剩余块的输出之和 - 多说话人设置
For the multi-speaker setting, we add a linear layer that transforms speaker embedding and add it to the input latent variables z.
对于多说话人设置,我们添加了一个线性层来转换说话人嵌入并将其添加到输入潜在变量z中。
2.5.4. DISCRIMINATOR
We follow the discriminator architecture of the multi-period discriminator proposed in HiFi-GAN The multi-period discriminator is a mixture of Markovian window-based sub-discriminators , each of which operates on different periodic patterns of input waveforms.
我们借鉴HiFi-GAN中提出的多周期鉴别器的鉴别器结构,多周期鉴别器是基于马尔可夫窗的子鉴别器的混合物,每个子鉴别器对输入波形的不同周期模式起作用。
2.5.5. STOCHASTIC DURATION PREDICTOR
The stochastic duration predictor estimates the distribution of phoneme duration from a conditional input htext.
随机持续时间预测器从条件输入文本中估计音素持续时间的分布。
For the efficient parameterization of the stochastic duration predictor, we stack residual blocks with dilated and depth-separable convolutional layers. We also apply neural spline flows, which take the form of invertible nonlinear transformations by using monotonic rational-quadratic splines, to coupling layers.
为了有效地参数化随机持续时间预测器,我们用膨胀的和深度可分的卷积层叠加残差块。我们还应用neural spline flows用于耦合层,它采用单调有理-二次样条曲线的可逆非线性变换形式。
For the multi-speaker setting, we add a linear layer that transforms speaker embedding and add it to the input htext.
对于多speaker设置,我们添加了一个线性层来转换speaker嵌入并将其添加到输入文本中。
3. Experiments
文章涉及知识点和公式证明较多,自行查看相关资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!