懒得玩游戏--帮我做数独
发布时间:2024年01月14日
简介
最近玩上了一款类似于数独的微信小程序游戏,名字叫数独趣味闯关,过了数独的关卡之后会给拼图,玩了几关之后摸清套路了就有点累了,但是还想集齐拼图,所以就编了个程序自动解数独。
自动解数独思路
核心思路
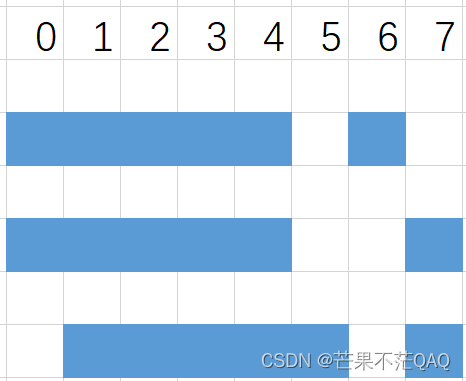
核心思路就是尝试所有排列组合,记录哪些位置能够确定是【□】或者【x】。例如下图所示,假设共有8个格,该行前数字为【5,1】。则有三种组合方式,以此能推断出位置【1,2,3,4】肯定为【□】,其他为待定,逐行逐列循环以得到所有位置的填充方式。
输入
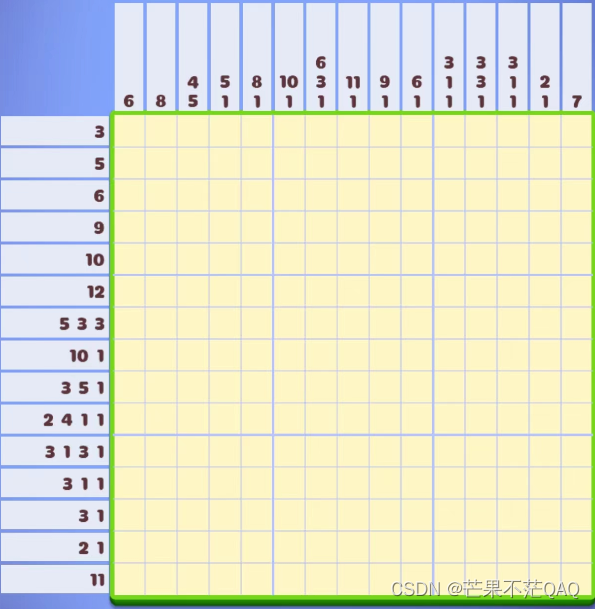
目前输入只能将每行/列前数字手动输入,为了输入方便,单个数字以整形直接输入,多个数字以字符串形式输入,用空格分割。如下图所示为输入样例
row = [3, 5, 6, 9, 10, 12, '5 3 3', '10 1', '3 5 1', '2 4 1 1', '3 1 3 1', '3 1 1', '3 1', '2 1', 11]
col = [6, 8, '4 5', '5 1', '8 1', '10 1', '6 3 1', '11 1', '9 1', '6 1', '3 1 1', '3 3 1', '3 1 1', '2 1', 7]
row = [[int(i) for i in s.split()] if type(s) is str else [s] for s in row]
col = [[int(i) for i in s.split()] if type(s) is str else [s] for s in col]
解析
- 对于一个新棋盘,逐行逐列扫描,以得到每个确定的位置。对于不同个数的数字,用不同层数的循环来解析。
- 具体来说,对于某一行/列,循环得出每个可能的填充方式,用一个长度为行数的列表,列表中每个元素为一个元组来记录每个位置可能的填充,如果该位置只有一种【□】或者【x】,就将其填入到棋盘中。若该位置有两种,则视为不确定,不进行填充。
- 由于扫描一次之后棋盘上某些位置已经确定填充,若循环得到的填充方式与现有棋盘相悖,则跳过当前循环,以此方式得到最终所有位置的填充。
打印
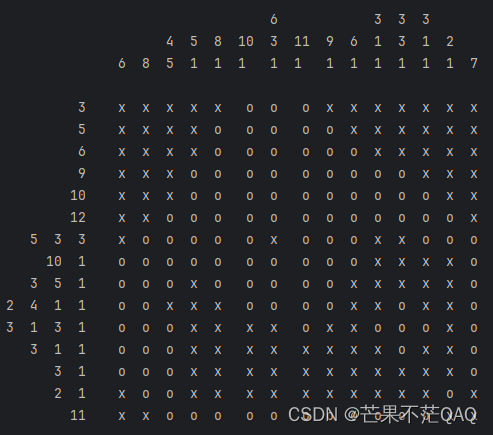
- 为了更直观的观看以便自己在手机上通关,所以做的更整齐一些。如下图所示。
完整代码
import numpy as np
row = [3, 5, 6, 9, 10, 12, '5 3 3', '10 1', '3 5 1', '2 4 1 1', '3 1 3 1', '3 1 1', '3 1', '2 1', 11]
col = [6, 8, '4 5', '5 1', '8 1', '10 1', '6 3 1', '11 1', '9 1', '6 1', '3 1 1', '3 3 1', '3 1 1', '2 1', 7]
row = [[int(i) for i in s.split()] if type(s) is str else [s] for s in row]
col = [[int(i) for i in s.split()] if type(s) is str else [s] for s in col]
map_size = len(row)
row_maxlen = max([len(i) for i in row])
col_maxlen = max([len(i) for i in col])
map_default_str = '-'
map = np.full([map_size, map_size], map_default_str)
num = [0]
def map_print():
candi_list = [1] * map_size # col中是否有超过10的数字,需要额外多一个空格
for i in range(map_size):
for j in col[i]:
if j >= 10:
candi_list[i] = 2
f = ''
for i in range(1, col_maxlen + 1):
cur_num_str = ''
for j in range(map_size):
if len(col[j]) >= i:
cur_num_str += str(col[j][-i]) + ' ' + ' ' * candi_list[j]
if col[j][-i] >= 10:
cur_num_str = cur_num_str[:-1]
else:
cur_num_str += ' ' * 2 + ' ' * candi_list[j]
f = ' ' + ' ' * (row_maxlen - 1) + cur_num_str + '\n' + f
print(f)
f = ''
for i in range(map_size):
cur_num_str = ''
for j in range(row_maxlen):
if len(row[i]) >= row_maxlen - j:
if row[i][j + len(row[i]) - row_maxlen] >= 10:
cur_num_str = cur_num_str[:-1]
cur_num_str += str(row[i][j + len(row[i]) - row_maxlen]) + ' ' * 2
else:
cur_num_str += ' ' * 2 + ' ' * candi_list[j]
cur_num_str += ' '
for j in range(map_size):
# cur_num_str += str(int(map[i][j])) + ' '
cur_num_str += ' ' * candi_list[j] + map[i][j] + ' '
f += cur_num_str + '\n'
print(f)
def simple_scan(idx, is_row=True):
map_list_tmp = np.full(map_size, 'x') # 当前行或列的值,用'x'初始化后,循环用'o'替换
cur_list = [set() for _ in range(map_size)] # 扫描多次保存可能填充的值
if is_row:
row_col_tmp = row.copy()
map_row_col = map[idx]
else:
row_col_tmp = col.copy()
map_row_col = map[:, idx]
if len(row_col_tmp[idx]) == 1:
for i in range(map_size - sum(row_col_tmp[idx]) + 1):
map_list_tmp[i: i + row_col_tmp[idx][0]] = 'o'
if is_require(map_list_tmp, map_row_col):
cur_list = merge_list(cur_list, map_list_tmp)
map_list_tmp = np.full(map_size, 'x')
elif len(row_col_tmp[idx]) == 2:
for i in range(map_size - sum(row_col_tmp[idx]) + 1 - len(row_col_tmp[idx]) + 1):
for j in range(i + row_col_tmp[idx][0] + 1, map_size - row_col_tmp[idx][1] + 1):
map_list_tmp[i: i + row_col_tmp[idx][0]] = 'o'
map_list_tmp[j: j + row_col_tmp[idx][1]] = 'o'
if is_require(map_list_tmp, map_row_col):
cur_list = merge_list(cur_list, map_list_tmp)
map_list_tmp = np.full(map_size, 'x')
elif len(row_col_tmp[idx]) == 3:
for i in range(map_size - sum(row_col_tmp[idx]) + 1 - len(row_col_tmp[idx]) + 1): # 8-2+1-2+1
for j in range(i + row_col_tmp[idx][0] + 1, map_size - sum(row_col_tmp[idx][1:]) + 1 - len(row_col_tmp[idx][1:]) + 1):
for k in range(j + row_col_tmp[idx][1] + 1, map_size - sum(row_col_tmp[idx][2:]) + 1 - len(row_col_tmp[idx][2:]) + 1):
map_list_tmp[i: i + row_col_tmp[idx][0]] = 'o'
map_list_tmp[j: j + row_col_tmp[idx][1]] = 'o'
map_list_tmp[k: k + row_col_tmp[idx][2]] = 'o'
if is_require(map_list_tmp, map_row_col):
cur_list = merge_list(cur_list, map_list_tmp)
map_list_tmp = np.full(map_size, 'x')
elif len(row_col_tmp[idx]) == 4:
for i in range(map_size - sum(row_col_tmp[idx]) + 1 - len(row_col_tmp[idx]) + 1): # 8-2+1-2+1
for j in range(i + row_col_tmp[idx][0] + 1, map_size - sum(row_col_tmp[idx][1:]) + 1 - len(row_col_tmp[idx][1:]) + 1):
for k in range(j + row_col_tmp[idx][1] + 1, map_size - sum(row_col_tmp[idx][2:]) + 1 - len(row_col_tmp[idx][2:]) + 1):
for l in range(j + row_col_tmp[idx][2] + 1, map_size - sum(row_col_tmp[idx][3:]) + 1 - len(row_col_tmp[idx][3:]) + 1):
map_list_tmp[i: i + row_col_tmp[idx][0]] = 'o'
map_list_tmp[j: j + row_col_tmp[idx][1]] = 'o'
map_list_tmp[k: k + row_col_tmp[idx][2]] = 'o'
map_list_tmp[l: l + row_col_tmp[idx][3]] = 'o'
if is_require(map_list_tmp, map_row_col):
cur_list = merge_list(cur_list, map_list_tmp)
map_list_tmp = np.full(map_size, 'x')
for i in range(map_size):
if is_row:
if len(cur_list[i]) == 1 and map[idx][i] == map_default_str:
map[idx][i] = list(cur_list[i])[0]
num[0] += 1
else:
if len(cur_list[i]) == 1 and map[i][idx] == map_default_str:
map[i][idx] = list(cur_list[i])[0]
num[0] += 1
def merge_list(l, n):
for i in range(len(l)):
l[i] = l[i].union(set(n[i]))
return l
def is_require(l1, l2):
for i in range(map_size):
if l2[i] != map_default_str and l1[i] != l2[i]:
return False
return True
if __name__ == '__main__':
while True:
for i in range(map_size):
simple_scan(i, is_row=True)
for j in range(map_size):
simple_scan(j, is_row=False)
map_print()
if num[0] == map_size * map_size:
break
文章来源:https://blog.csdn.net/qq_41496421/article/details/135584534
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于Web的流浪狗收容领养管理平台的设计与实现论文
- 12.13每日一题(备战蓝桥杯快速排序)
- 北斗卫星技术在建筑监测领域的革新实践
- redis源码之:多线程
- 品牌出海新篇章:DTC营销与红人矩阵的完美结合
- SCI一区级 |【GWO-Attention-CNN-GRU】基于灰狼算法优化注意力机制卷积神经网络结合门控循环单元实现数据多维输入单输出预测附matlab代码
- 一天一个设计模式---单例模式
- C++的命名空间域
- 软件测试用例经典方法 | 单元测试法案例
- NGINX 配置本地HTTPS(免费证书)