2022-ECCV-Adaptive Face Forgery Detection in Cross Domain
发布时间:2024年01月20日
一、研究背景
1.伪造视频是逐帧生成的,因此会造成时间维度上的伪影。而鲁棒的检测模型需要对同一身份的不同帧有一致的检测结果。
1.利用频率线索进行deepfake检测效果良好,但也会导致帧间不一致问题,即不同帧检测结果不同。
2.以往方法中固定的分类超平面不能准确地分割所有帧的类别。
二、研究目标
1.提高预测结果的稳定性和一致性,以进一步提高检测算法的性能。
2.根据单个实例自适应地调整鉴别中心并进行预测。
三、技术路线
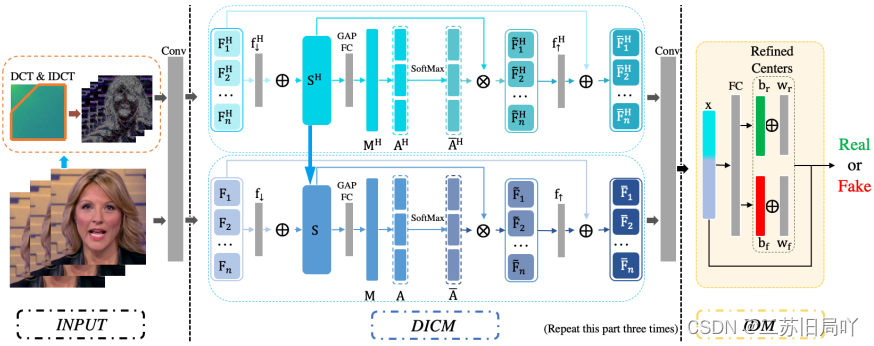
1.Dual-domain Intra-Consistency Module:通过挖掘帧间相关表征以及域间互补线索来获取潜在一致性。
- 频域变换:经DCT、IDCT得到频域特征 { F 1 H , … , F n H } \{F^{H}_1,\dots,F^{H}_n\} {F1H?,…,FnH?}
- 序列求和:经元素级求和得到序列级共有特征
S
H
S^H
SH,以增强帧间共有特征,减轻噪声特征

- 注意力:利用channel-wise SoftAttention为每个实例提取注意力特征嵌入
A
ˉ
i
H
\bar{A}^H_i
AˉiH?
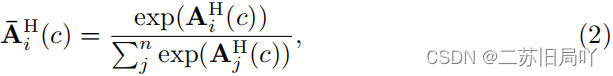
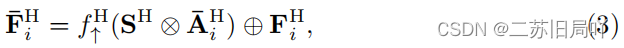
- RGB支路:融合频域特征后进行相似操作
- 特征拼接:拼接频域序列 { F 1 H , … , F n H } \{F^H_1,\dots,F^H_n\} {F1H?,…,FnH?}和RGB序列 { F 1 , … , F n } \{F_1,\dots,F_n\} {F1?,…,Fn?}
2.Instance-Discrimination Module:根据输入实例动态调整超平面的位置,令特征分布更广,正负区分度更大。
- 利用SoftMax+FC进行可能性预测:
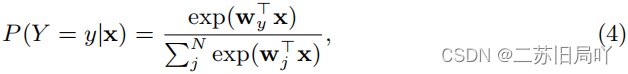
- 利用normalized SoftMax中的
w
o
w_o
wo?、
w
1
w_1
w1?表征鉴别中心
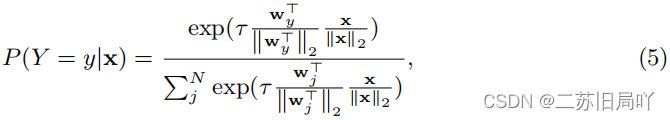
- 利用FC、BN、ReLU为 w o w_o wo?、 w 1 w_1 w1?提取偏置 b r b_r br?、 b f b_f bf?
- 利用Instance-Discrimination SoftMax进行可能性预测:
IDM会根据每个单独的实例来调整鉴别中心
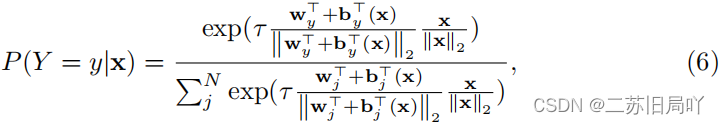
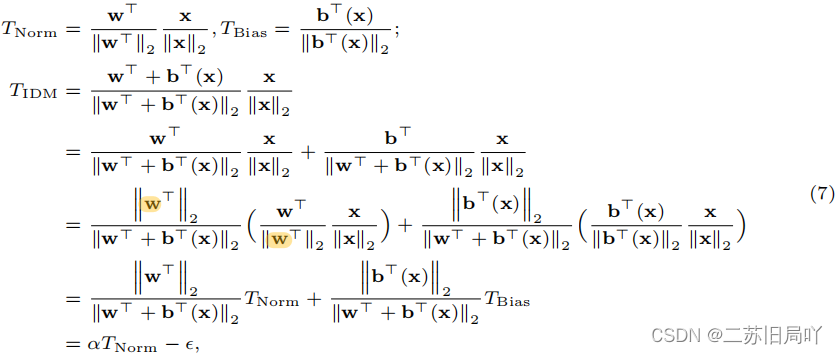
- 数学推导
? \epsilon ?可看作自适应边界,与以往固定的positive margin不同, ? \epsilon ?可正可负
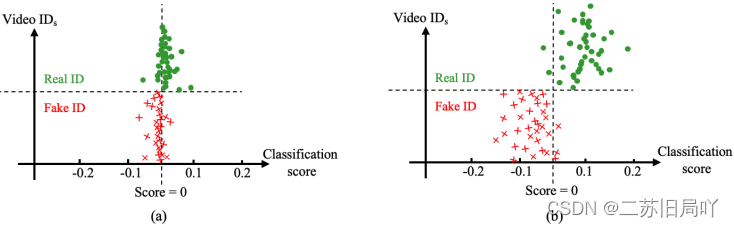
四、实验结果
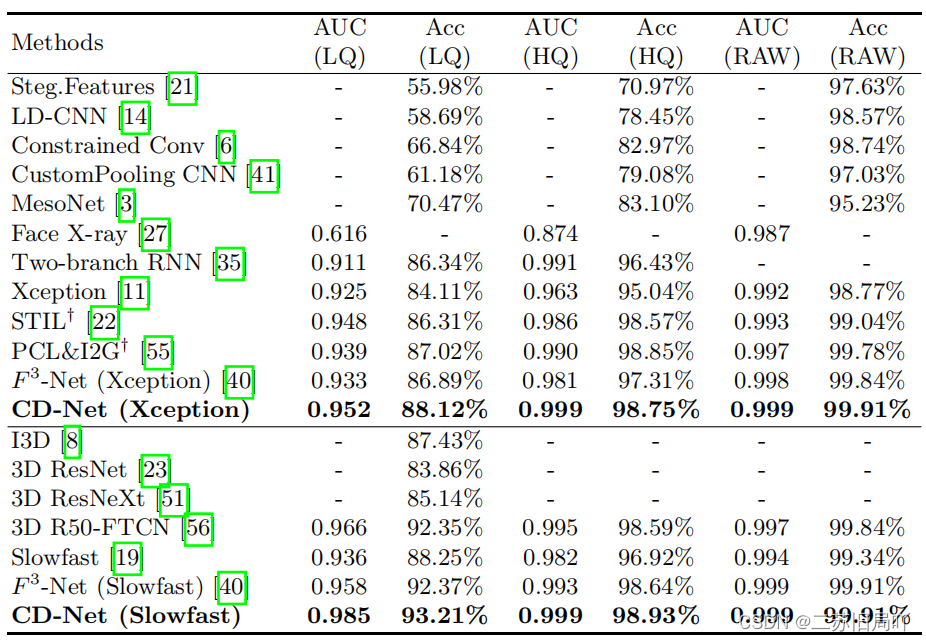
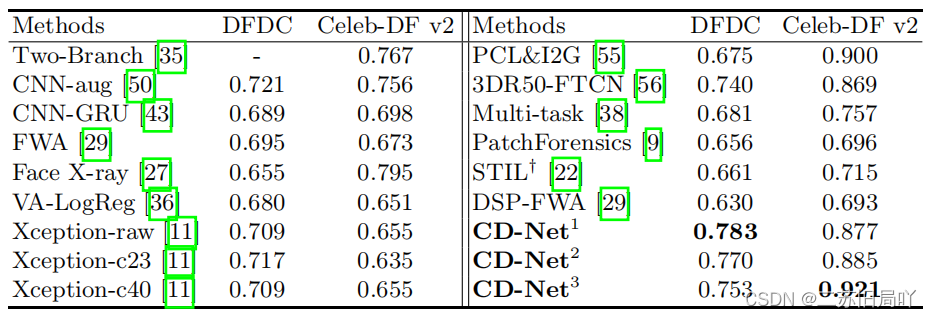
文章来源:https://blog.csdn.net/qq_37246721/article/details/135684462
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- windows配置防火墙
- Github Copilot 的使用方法和快捷键
- [FreeRTOS] 初识FreeRTOS
- 力扣题目学习笔记(OC + Swift)16. 最接近的三数之和
- python数字图像处理基础(二)——图像基本操作、滑动条、鼠标操作
- 【算法题】矩阵顺时针旋转90° (js)
- 【MySQL】数据类型
- 01.08
- 【Axure高保真原型】3D商品销售可视化模板
- 天津大数据分析培训班 常见的大数据培训课程