python学习曲线绘制
发布时间:2024年01月05日
1. 学习曲线的绘制 learning_curve的使用案例
learning_curve 函数是 Scikit-learn 库中用于生成学习曲线的工具。以下是该函数的主要参数及其解释:
estimator:
- 模型估计器(estimator),即要评估性能的机器学习模型。这是必需的参数。
X:
- 特征数据,输入模型的训练数据。
y:
- 目标数据,与特征数据相对应的标签。
train_sizes:
- 用于指定用于生成学习曲线的训练样本的相对或绝对数字。可以是浮点数(表示相对大小)或整数(表示绝对大小)的数组。
cv:
- 交叉验证生成器或可迭代的次数,用于将数据集拆分为训练集和验证集。默认为 None,表示使用 3 折交叉验证。
scoring: 可选参考,以_socre结尾的越高越好,以_error或_loss结尾的越低越好。
- 评估指标的字符串,用于衡量模型性能。默认为 None,表示使用模型的默认评估指标。
n_jobs:
- 并行运行的作业数。-1 表示使用所有可用的CPU核心。
train_sizes_abs:
- 返回用于生成学习曲线的训练样本的绝对数字。
shuffle:
- 是否在每次迭代中对数据进行洗牌。默认为 True。
random_state:
- 伪随机数生成器的种子,用于洗牌和交叉验证的拆分。
函数的返回值包括三个数组:
train_sizes_abs:
- 用于生成学习曲线的训练样本的绝对数量。
train_scores:
- 每个训练大小对应的训练集上的性能得分。
test_scores:
- 每个训练大小对应的验证集上的性能得分。

学习曲线是通过这些得分的平均值和标准差绘制而成的,使你能够了解模型在不同训练集大小下的性能表现,并帮助你判断模型是否过拟合或欠拟合。
from sklearn.model_selection import learning_curve
def draw_learn_curve(model, X, y,cv=5):
# 使用random forest模型拟合数据,学习曲线图展示训练集和交叉验证集的得分情况
train_size, train_score, test_score = learning_curve(model, X, y, cv=cv, train_sizes=np.linspace(0.1,1.0,5))
# 计算训练集得分的均值
train_scores_mean = np.mean(train_score, axis=1)
# 计算训练集得分的标准差
train_scores_std = np.std(train_score, axis=1)
# 计算交叉验证集得分的均值
test_scores_mean = np.mean(test_score, axis=1)
# 计算交叉验证集得分的标准差
test_scores_std = np.std(test_score, axis=1)
# 绘制训练集得分的误差线
plt.fill_between(train_size, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
# 绘制交叉验证集得分的误差线
plt.fill_between(train_size, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
# 绘制训练集得分曲线
plt.plot(train_size, train_scores_mean, 'o--', color="r",
label="训练集得分")
# 绘制交叉验证集得分曲线
plt.plot(train_size, test_scores_mean, 'o-', color="g",
label="交叉验证集得分")
# 显示网格线
plt.grid()
# 设置标题
plt.title(f'{model}模型的学习曲线')
# 显示图例
plt.legend(loc="best")
rf = RandomForestClassifier(n_estimators=100, max_depth=5,random_state=42,n_jobs=-1) draw_learn_curve(rf,X,y,cv=5)
结果如下
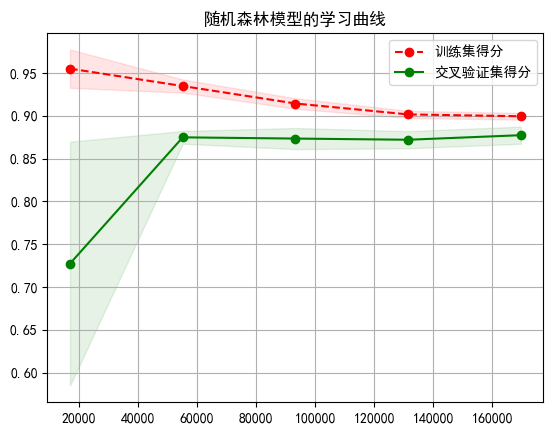
文章来源:https://blog.csdn.net/qq_45939398/article/details/135414100
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 含中间直流的三相电力电子变压器PET仿真模型
- 【笔记】Helm-3 主题-12 Helm插件指南
- 引领行业赛道!聚铭网络入选安全419年度策划“2023年教育行业优秀解决方案”
- 746. 使用最小花费爬楼梯 --力扣 --JAVA
- VSCode远程连接centos
- nm命令使用详解,让你加快学习速度
- GitLab存在任意用户密码重置漏洞(CVE-2023-7028)
- 深入探索COM技术:实现跨语言组件集成
- R语言将list转变为dataframe(常用)
- 设计模式-委托模式