R语言:资金评估
发布时间:2024年01月20日
代码示例?
# 1. 导入数据
fund_data <- read.csv("D:/R语言/基金.csv", sep = ',', header = TRUE, na.strings = "--")
fund_data <- fund_data[-1]
fund_data[is.na(fund_data)] <- 0
# 2. Z-score标准化函数
standardize <- function(x) {
return((x - mean(x)) / sd(x))
}
# 3. 对需要标准化的列应用标准化函数
fund_data$最新净值 <- standardize(fund_data$最新净值)
fund_data$累计净值 <- standardize(fund_data$累计净值)
fund_data$日增长率 <- standardize(fund_data$日增长率)
# 4. 计算评级分数
fund_data$评级分数 <- rowMeans(fund_data[, c("最新净值", "累计净值", "日增长率")])
# 5. 根据评级分数进行评级
fund_data$评级 <- cut(fund_data$评级分数, breaks = c(-Inf, -1, -0.5, 0.5, 1, Inf), labels = c("E", "D", "C", "B", "A"))
# 打印基金数据框中的评级列
print(fund_data$评级)
# 6. 可视化基金评级分布
# 创建基金评级的条形图,关闭默认的横轴标签(xaxt="n"),并指定标签位置
barplot(table(fund_data$评级), main = "基金评级分布", ylab = "数量", xaxt = "n",
names.arg = c("A", "B", "C", "D", "E"))
# 添加标签
text(
x = 1:5, # x轴位置
y = table(fund_data$评级)+0.2, # y轴位置
labels = table(fund_data$评级), # 标签
pos = 3, # 文本位置,3表示在上方
cex = 0.8 # 文本大小
)
# 自定义x轴标签
axis(1, at = 1:5, labels = c("A", "B", "C", "D", "E"))
# 统计各评级的数量并输出
rating_counts <- table(fund_data$评级)
print("各评级的数量统计:")
print(rating_counts)评级可视化?
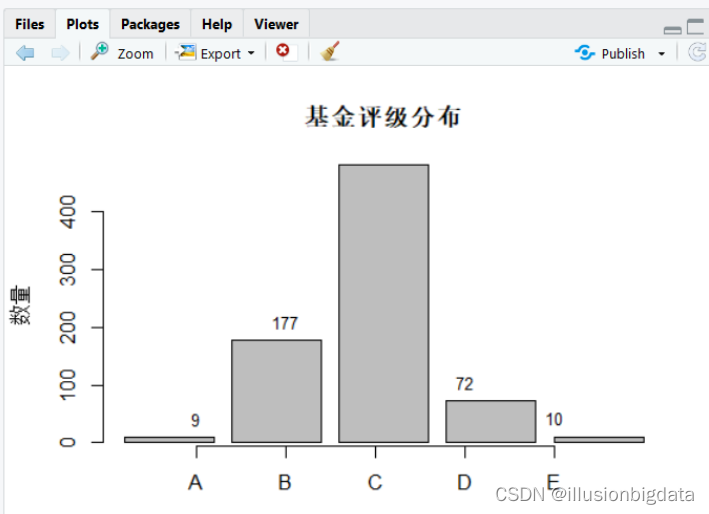 ?评级统计
?评级统计
 ?
?
文章来源:https://blog.csdn.net/mynameispy/article/details/135711502
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章