Python初识——小小爬虫
发布时间:2024年01月20日
一、找到网页端url
- 打开浏览器,打开百度官方网页点击图片,打开百度图片

- 鼠标齿轮向下滑,点击宠物图片
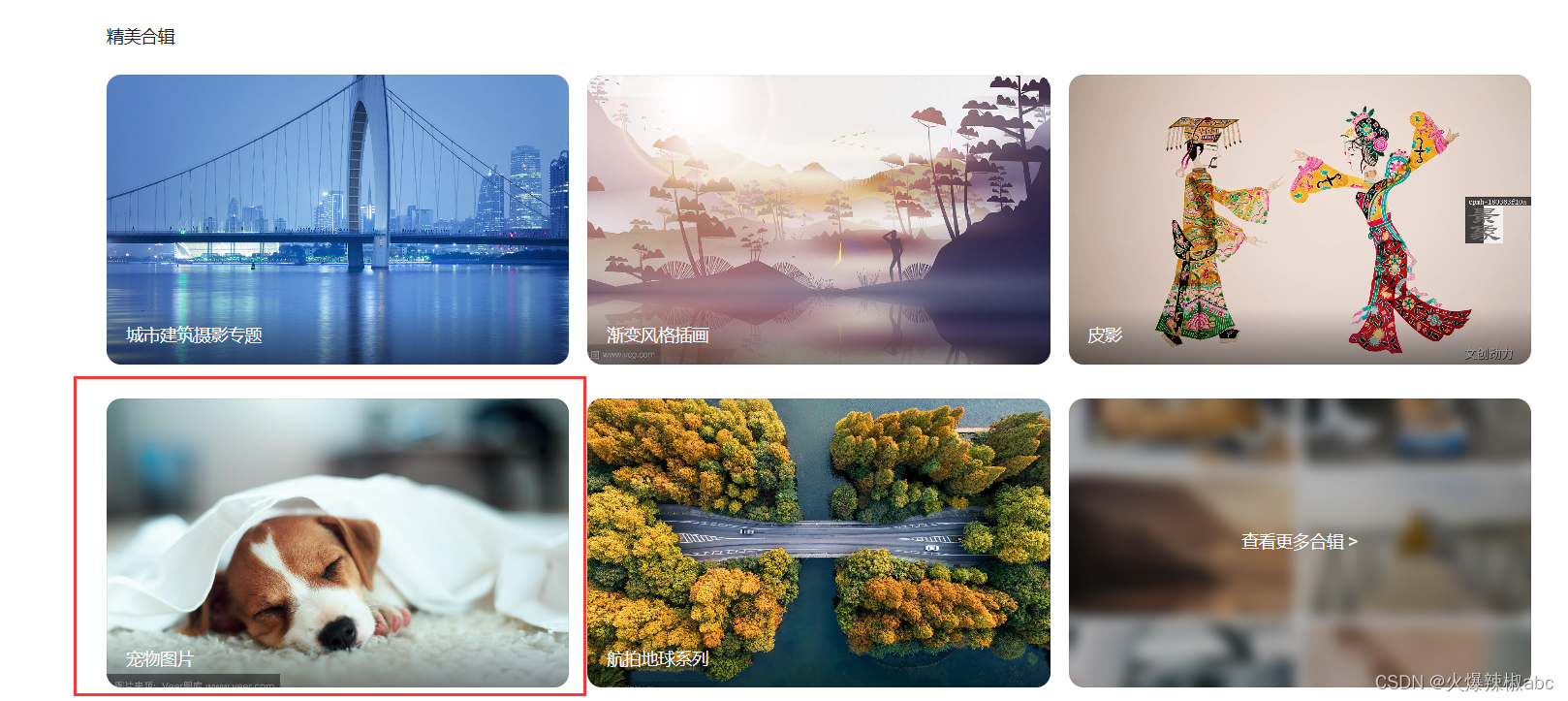
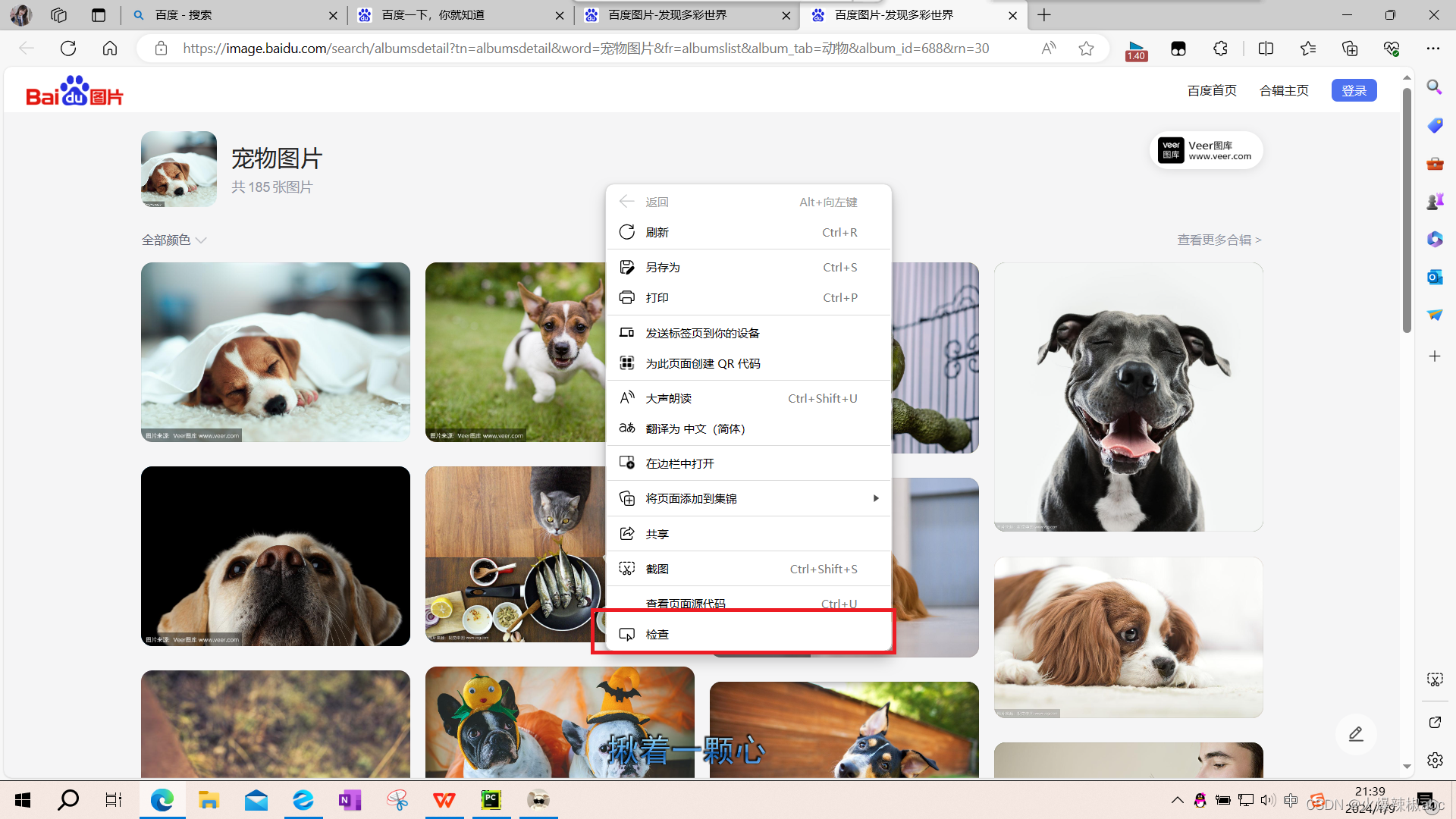
- 进入宠物图片网页,在网页空白处点击鼠标右键,弹出的框中最下方显示“检查”选项,点击(我是用的是edge浏览器)
- 点击刷新之后,将鼠标放于网页端,将齿轮向下滑可以看到更新的网络日志
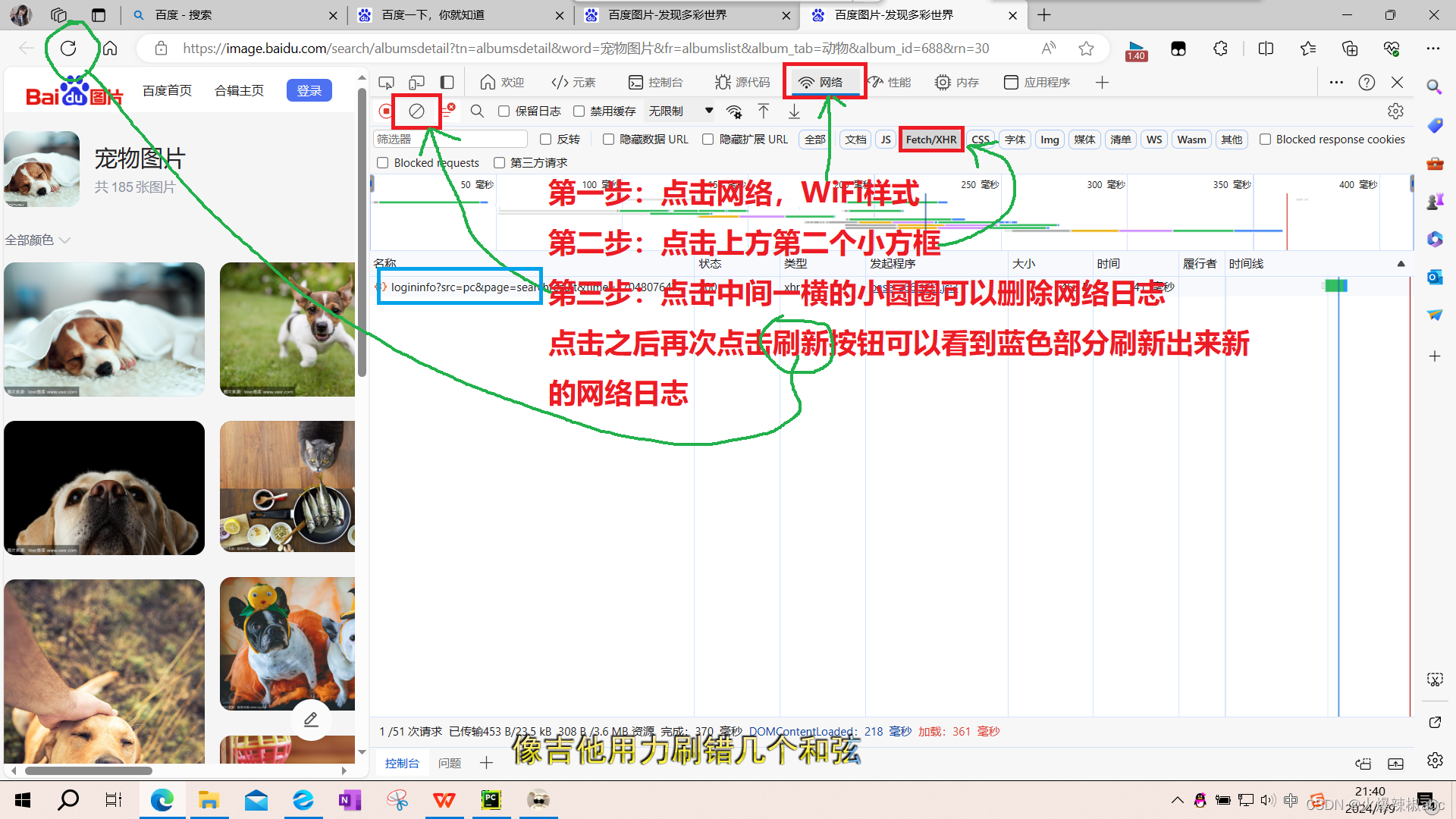
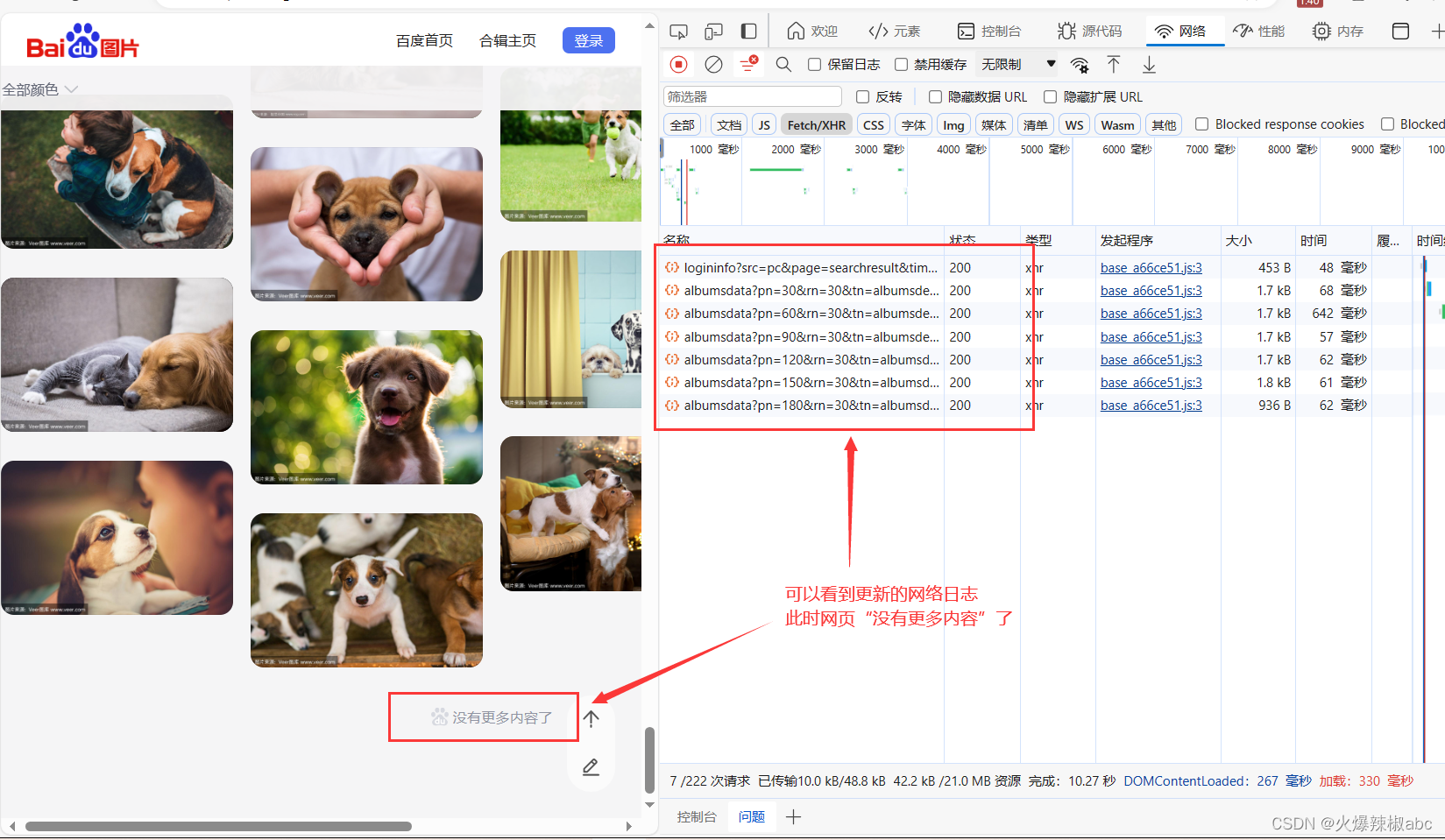
- 点击一条网络日志可以看到url

可以看出,只有部分数字不同,其他相同
二、开始爬取
(1)导入请求模块
# 1.导入请求模块
from urllib import request
import json(2)发起请求,将请求结果赋予response
# 2. 发起请求 将请求结果赋予response
page = 1
while True:
res = request.urlopen(
f"https://image.baidu.com/search/albumsdata?pn={30 * page}&rn=30&tn=albumsdetail&word=%E5%AE%A0%E7%89%A9%E5%9B%BE%E7%89%87&album_tab=%E5%8A%A8%E7%89%A9&album_id=688&ic=0&curPageNum={page}")
page += 1(3)获取请求返回值,此时需要解码,将类型转换为字典
# 3.获取请求返回值,解码,将类型转换为字典
res = res.read().decode()
res = json.loads(res)

(4)解析数据
# 4.解析数据
datas = res['albumdata']['linkData']
for data in datas:
image_url = data['thumbnailUrl']
(5)请求图片
# 5.请求图片
res_image = request.urlopen(image_url)
res_image = res_image.read()(6)保存图片
count += 1
file = open(f"{count}.jpg", "wb")
file.write(res_image)
file.close()
if len(datas) != 30:
break
print(f"总共{count}张图片")最后,爬取到的图片就成功的保存到了本地文件夹里。
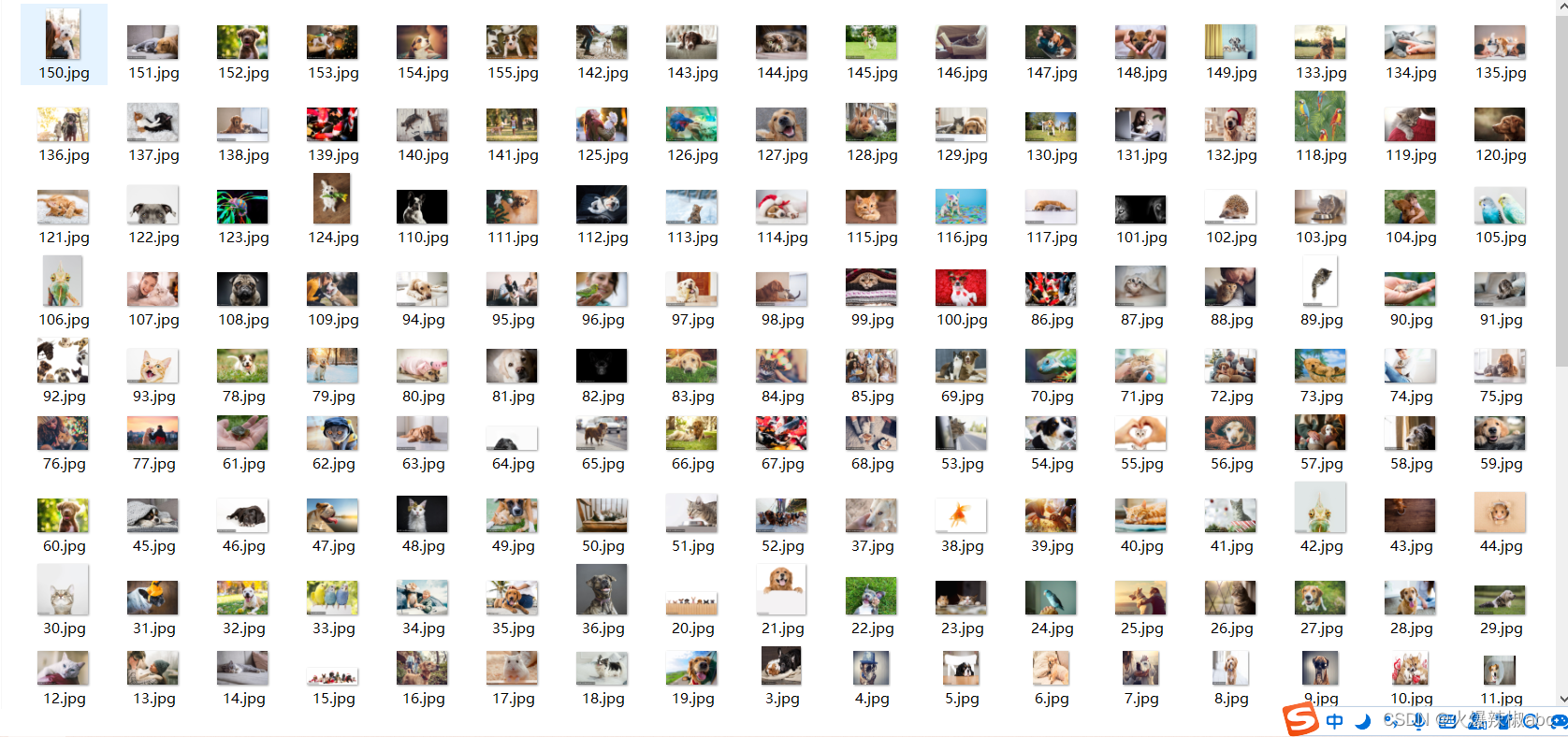
第一次清晰地直观地感受爬虫,好有趣,期待以后系统的学习!!

文章来源:https://blog.csdn.net/m0_63865649/article/details/135490448
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 浅谈安科瑞智能照明系统在马来西亚国家石油公司项目的应用
- 如何在Docker中搭建MinIO容器并实现无公网ip远程访问本地服务
- MySQL单表查询、多表查询、分组查询、等级查询综合练习
- 阿里云GPU服务器命名规则gn、vgn、gi、f、ebm和scc详解
- weixin001-ssm基于小程序的购物系统设计与实现
- Qt之QNetworkAccessManager 从本地和内存中上传数据到Http服务器
- 如何使用ActiveMQ:一篇技术指南
- 初识opeanCV(2)
- 对齐大型语言模型与人类偏好:通过表示工程实现
- 庆祝安科瑞企业微电网智慧能源管理系统生态交流会圆满举办——安科瑞 顾烊宇