AI对联生成案例(二)
模型训练
有了处理好的数据,我们就可以进行训练了。你可以选择本地训练或在OpenPAI上训练。
OpenPAI上训练
OpenPAI 作为开源平台,提供了完整的 AI 模型训练和资源管理能力,能轻松扩展,并支持各种规模的私有部署、云和混合环境。因此,我们推荐在OpenPAI上训练。
完整训练过程请查阅:?在OpenPAI上训练
本地训练
如果你的本地机器性能较好,也可以在本地训练。
模型训练的代码请参考?train.sh。
训练过程依然调用t2t模型训练命令:。具体命令如下:t2t_trainer
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>TRAIN_DIR=./output
LOG_DIR=${TRAIN_DIR}
DATA_DIR=./data_dir
USR_DIR=./usr_dir
PROBLEM=translate_up2down
MODEL=transformer
HPARAMS_SET=transformer_small
t2t-trainer \
--t2t_usr_dir=${USR_DIR} \
--data_dir=${DATA_DIR} \
--problem=${PROBLEM} \
--model=${MODEL} \
--hparams_set=${HPARAMS_SET} \
--output_dir=${TRAIN_DIR} \
--keep_checkpoint_max=1000 \
--worker_gpu=1 \
--train_steps=200000 \
--save_checkpoints_secs=1800 \
--schedule=train \
--worker_gpu_memory_fraction=0.95 \
--hparams="batch_size=1024" 2>&1 | tee -a ${LOG_DIR}/train_default.log
</code></span></span></span></span>各项参数的作用和取值分别如下:
-
t2t_usr_dir:如前一小节所述,指定了处理对联问题的模块所在的目录。 -
data_dir:训练数据目录 -
problem:问题名称,即translate_up2down -
model:训练所使用的 NLP 算法模型,本案例中使用 transformer 模型 -
hparams_set:transformer 模型下,具体使用的模型。transformer 的各种模型定义在 tensor2tensor/models/transformer.py 文件夹内。本案例使用 transformer_small 模型。 -
output_dir:保存训练结果 -
keep_checkpoint_max:保存 checkpoint 文件的最大数目 -
worker_gpu:是否使用 GPU,以及使用多少 GPU 资源 -
train_steps:总训练次数 -
save_checkpoints_secs:保存 checkpoint 的时间间隔 -
schedule:将要执行的 方法,比如:train, train_and_evaluate, continuous_train_and_eval,train_eval_and_decode, run_std_servertf.contrib.learn.Expeiment -
worker_gpu_memory_fraction:分配的 GPU 显存空间 -
hparams:定义 batch_size 参数。
好啦,我们输入完命令,点击回车,训练终于跑起来啦!如果你在拥有一块 K80 显卡的机器上运行,只需5个小时就可以完成训练。如果你只有 CPU ,那么你只能多等几天啦。 我们将训练过程运行在 Microsoft OpenPAI 分布式资源调度平台上,使用一块 K80 进行训练。
如果你想利用OpenPAI平台训练,可以查看在OpenPAI上训练。
4小时24分钟后,训练完成,得到如下模型文件:
- 检查站
- 型号.ckpt-200000.data-00000-of-00003
- 型号.ckpt-200000.data-00001-of-00003
- 型号.ckpt-200000.data-00002-of-00003
- 型号.ckpt-200000.index
- 型号.ckpt-200000.meta
我们将使用该模型文件进行模型推理。
模型推理
在这一阶段,我们将使用上述训练得到的模型文件进行模型推理,利用上联生成下联。
新建推理脚本文件inference.sh
点击查看?inference.sh?的代码。
在推理之前,需要注意如下几个目录:
TRAIN_DIR:上述的训练模型文件存放的目录。DATA_DIR:训练字典文件存放目录,即之前提到的。merge.txt.vocab.cleanUSR_DIR:自定义问题的存放目录,即之前提到的文件。merge_vocab.py
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>TRAIN_DIR=./output
DATA_DIR=./data_dir
USR_DIR=./usr_dir
DECODE_FILE=./decode_this.txt
PROBLEM=translate_up2down
MODEL=transformer
HPARAMS=transformer_small
BEAM_SIZE=4
ALPHA=0.6
poet=$1
new_chars=""
for ((i=0;i < ${#poet} ;++i))
do
new_chars="$new_chars ${poet:i:1}"
done
echo $new_chars > decode_this.txt
echo "生成中..."
t2t-decoder \
--t2t_usr_dir=$USR_DIR \
--data_dir=$DATA_DIR \
--problem=$PROBLEM \
--model=$MODEL \
--hparams_set=$HPARAMS \
--output_dir=$TRAIN_DIR \
--decode_from_file=$DECODE_FILE \
--decode_to_file=result.txt >> /dev/null 2>&1
echo $new_chars
cat result.txt
</code></span></span></span></span>开始推理
给增加可执行权限inference.sh
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>chmod +x ./inference.sh
</code></span></span></span></span>使用如下命令推理
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>./inference.sh [上联]
</code></span></span></span></span>例如,
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>./inference.sh 西子湖边逢暮雨
</code></span></span></span></span>等待推理完成后,你可能会得到下面的输出。当然,下联的生成和你的训练集、迭代次数等都有关系,因此大概率不会有一样的结果。
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>生成中...
西 子 湖 边 逢 暮 雨
故 里 乾 坤 日 盖 章
</code></span></span></span></span>推理结果也保存到了文件中。result.txt
搭建后端服务
训练好了模型,我们显然不能每次都通过命令行来调用,既不用户友好,又需要多次加载模型。因此,我们可以通过搭建一个后端服务,将模型封装成一个api,以便构建应用。
我们后端服务架构如下: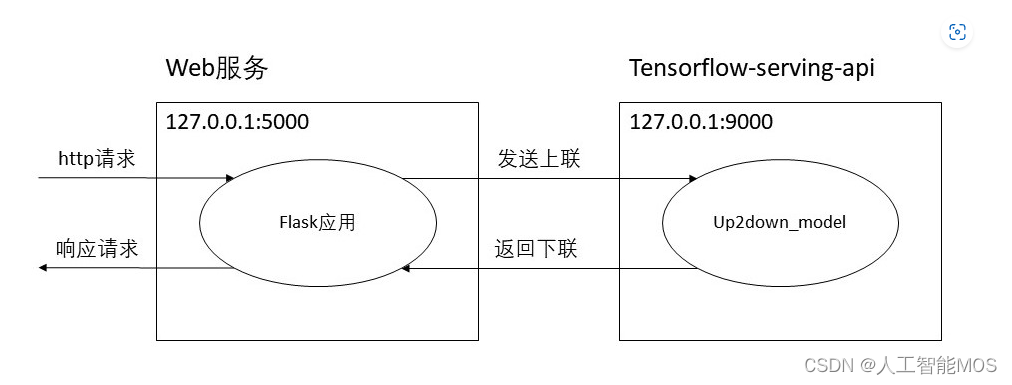
首先,利用为我们的模型开启服务,再通过Flask构建一个Web应用接收和响应http请求,并与我们的模型服务通信获取推理结果。tensorflow-serving-api
开启模型服务
开启模型服务有以下几个步骤:
-
安装
tensorflow-serving-api<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>pip3 install tensorflow-serving-api==1.14.0 echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | sudo apt-key add - sudo apt-get update && sudo apt-get install tensorflow-model-server </code></span></span></span>注意:
- 安装会自动安装的cpu版本,会覆盖版本。
tensorflow-serving-apitensorflowtensorflow-gpu - 如果有依赖缺失,请查阅:https://medium.com/@noone7791/how-to-install-tensorflow-serving-load-a-saved-tf-model-and-connect-it-to-a-rest-api-in-ubuntu-48e2a27b8c2a。
- 安装会自动安装的cpu版本,会覆盖版本。
-
导出我们训练好的模型
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>t2t-exporter --model=transformer \ --hparams_set=transformer_small \ --problem=translate_up2down \ --t2t_usr_dir=./usr_dir \ --data_dir=./data_dir \ --output_dir=./output </code></span></span></span> -
启动服务
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>tensorflow_model_server --port=9000 --model_name=up2down --model_base_path=$HOME/output/export </code></span></span></span>此处需要注意,
--port:服务开启的端口--model_name:模型名称,可自定义,会在后续使用到--model_base_path:导出的模型的目录
至此,模型服务已成功启动。
在Python中调用
启动模型服务后,完成以下步骤即可在Python中调用模型完成推理。
首先,新建目录,并将文件按如下目录结构放置。service
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>service \
config.json
up2down_model \
up2down_model.py
data \
__init__.py
merge.txt.vocab.clean
merge_vocab.py
</code></span></span></span></span>其中,字典文件和需拷贝到目录。merge.txt.vocab.cleanmerge_vocab.pyservice\up2down_model\data
此外,我们将与模型服务通信获取下联的函数封装在了up2down_model.py中,下载该文件后拷贝到目录。service\up2down_model
另外,我们需要修改config.json文件为对应的内容:
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>{
"t2t_usr_dir":"./up2down_model/data",
"problem":"translate_up2down",
"model_name":"up2down",
"server_address":"127.0.0.1:9000"
}
</code></span></span></span></span>t2t_usr_dir:对联问题模块的定义文件及字典的存放目录model_name:开启时定义的模型名称tensorflow-serving-apiproblem:定义的问题名称server_address: 服务开启的地址及端口
最后,在目录下新建Python文件,通过以下两行代码即可完成模型的推理并生成下联。service
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>from up2down_model.up2down_model import up2down
up2down.get_down_couplet([upper_couplet])
</code></span></span></span></span>由于服务开启后无需再次加载模型和其余相关文件,因此模型推理速度非常快,适合作为应用的接口调用。
搭建Flask Web应用
利用Flask,我们可以快速地用Python搭建一个Web应用,实现对联生成。
主要分为以下几个步骤:
-
安装flask
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>pip3 install flask </code></span></span></span> -
搭建服务
我们在目录下新建一个文件,内容如下:
serviceapp.py<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>from flask import Flask from flask import request from up2down_model.up2down_model import up2down app = Flask(__name__) @app.route('/',methods=['GET']) def get_couplet_down(): couplet_up = request.args.get('upper','') couplet_down = up2down.get_down_couplet([couplet_up]) return couplet_up + "," + couplet_down[0] </code></span></span></span>由于我们把推理下联的功能封装在中,因此通过几行代码我们就实现了一个web服务。
up2down_model.py -
启动服务
在测试环境中,我们使用flask自带的web服务即可(注:生产环境应使用uwsgi+nginx部署,有兴趣的同学可以自行查阅资料)。
使用以下两条命令:
In Ubuntu,
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>export FLASK_APP=app.py python -m flask run </code></span></span></span>In Windows,
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>set FLASK_APP=app.py python -m flask run </code></span></span></span>此时,服务就启动啦。
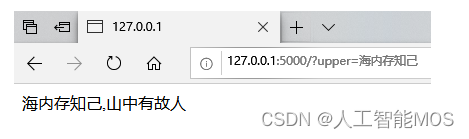
我们仅需向后端?http://127.0.0.1:5000/?发起get请求,并带上上联参数,即可返回生成的对联到前端。
upper示例,
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>http://127.0.0.1:5000/?upper=海内存知己 </code></span></span></span>返回结果如图:
-
后端服务的完整代码请参考:.\src\service
案例拓展
至此,我们已经学会了小程序的核心部分:训练模型、推理模型及搭建后端服务使用模型。由于小程序的其余实现部分涉及比较多的开发知识,超出了NLP的范畴,因此我们不再详细介绍,而是在该部分简单讲解其实现思路,对上层应用开发感兴趣的同学可以参考并实现。
实体提取
当用户通过小程序上传图片时,程序需要从图片中提取出能够描述图片的信息。 本案例利用了微软的Cognitive Service完成从上传的图片中提取实体的工作。上传图片后,程序会调用微软的Cognitive Service并将结果返回。
下面是返回结果的示例:
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>{
'tags':
[
{'name': 'person', 'confidence': 0.99773770570755},
{'name': 'birthday cake', 'confidence': 0.992998480796814},
{'name': 'food', 'confidence': 0.9029457569122314},
...
],
'description':
[
'person', 'woman', 'holding', 'smiling', ...
]
}
</code></span></span></span></span>返回结果中包含了和字段,里面分别包含了该图片的意象。tagsdescription
筛选及翻译Tag
可以看到,调用cognitive service以后,会返回大量的tags,而我们需要从中挑选出符合要求的tag。在这个阶段,我们有两个目标:
- 找到能准确描述图片内容的tag
- 找到概括性强的tag,
首先,我们为了找出能准确描述图片内容的tag,我们取了返回结果中和中都存在的tag作为对图片描述的tag。这样就初步筛选出了更贴近图片内容的tag。tagsdescription
从直观上理解,概括能力越好的tag自然是出现频率越高的。因此,我们构建了一个高频词典,收集了出现频率前500的tag,并给出了对应的中文翻译。我们仅保留并翻译在词典内的tag,而不在词典内的tag会在这个阶段被进一步地过滤掉。
在高频词典的构建中,我们对中文翻译做了改进,使其与古文意象更接近,便于搜索出对应的上联。因此,高频词典不再是纯粹的中英互译的词典,而是英文tag到相关意象的映射。例如,我们将'building'映射为'楼','skiing'映射为'雪','day'映射为'昼'等。
利用这样的高频词典,就完成了翻译及过滤tag的过程。
思考:会不会出现过滤后的tag太少的情况?
为此,我们做实验统计了两个指标,若仅保留前500个高频tag,tag覆盖率约为100%,tag平均覆盖数约为10个/张。
( 注:tag覆盖率 = 至少有一个tag在高频词典内的图片数 / 总图片数 * 100% , tag平均覆盖数 = 每张图片中在高频词典内的tag数之和 / 总图片数 * 100% )
因此可以确保极大多数的图片是不会全部tag都被过滤掉的,并且剩余的tag数量适中。
上联匹配
提取完实体信息,我们的目标是找出与实体匹配程度较高的上联数据。于是,我们希望尽量找出包含两个tag的上联数据,这样能够保证匹配程度较高。
匹配分为如下几个步骤:
-
分别找出包含每个tag的上联的索引
例如,假设通过上一步的翻译及过滤最终得到了:'天', '草','沙滩'这几个tag,我们需要分别找出包含这几个tag的上联的索引,如:
- '天':{ 3, 74, 237, 345, 457, 847 }
- '草':{ 23, 74, 455, 674, 54, 87, 198 }
- '沙滩':{ 86, 87, 354, 457 }
-
找出包含两个tag的对每组索引分别取交集
例如,
- '天' + '草':{ 74 }
- '天' + '沙滩': { 457 }
- '草' + '沙滩':{ 87 }
-
合并取交集的结果
例如,得到结果{ 74, 457, 87 }。
-
若交集为空,则随机从各自tag中选取部分索引。
-
从上面的结果中随机选出上联数据。
通过以上几个步骤,我们可以在确保至少包含一个tag的同时,尽可能找出包含两个tag的上联。
下联生成
得到了上联以后,我们可以利用上面开启模型服务中提到的方法生成下联。
搭建后端
后端部分的实现也可以参考上述的搭建Flask Web应用或Flask中文文档。
在部署至生产环境时,可以使用uwsgi+nginx的方式。
总结
本案例利用深度学习方法构建了一个上联预测下联的对联生成模型。首先通过词嵌入对数据集编码,再利用已编码的数据训练一个Encoder-Decoder模型,从而实现对联生成的功能。另外,该案例还结合微软Cognitive Service中的目标检测,对用户上传图片进行分析,利用分析结果匹配上联,再通过训练好的模型生成下联。最后,搭建后端服务实现完整的应用功能。该案例很好地演示了从模型选择、训练、推理到搭建后端服务等完整的应用开发流程,将理论与实践结合。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- com.github.ltsopensource.remoting.exception.RemotingConnectException报错
- 【数学建模美赛M奖速成系列】报名流程与论文的基本格式
- 【Android】ANR
- OSPF中各类LSA的对比
- 力扣热题100道-普通数组篇
- antd中DatePicker禁选范围如何设置
- 识别pdf中论文标题并重命名PDF名称(2023.12.27)
- 使用 ffmpeg-python 合成视频(一)
- 如何搭建Z-blog网站并结合内网穿透实现无公网ip访问本地站点
- @NotNull 参数校验,以及结果返回