[VGG团队论文阅读]Free3D: Consistent Novel View Synthesis without 3D Representation
Vedaldi, C. Z. A. (n.d.). Free3D: Consistent Novel View Synthesis without 3D Representation. Chuanxiaz.com. https://chuanxiaz.com/free3d/static/videos/Free3D.pdf
Free3D: 无需3D表示的一致新视角合成
Visual Geometry Group, University of Oxford
摘要
我们介绍了Free3D,这是一种简单的方法,专为从单个图像进行开放式新视角合成(NVS)而设计。与Zero-1-to-3类似,我们从预训练的2D图像生成器开始,以实现泛化,并对其进行微调以适应NVS。与最近和同时进行的工作相比,我们在不依赖显式3D表示(既慢又占用内存)或训练额外的3D网络的情况下获得了显著的改进。我们通过通过新的逐像素射线条件归一化(RCN)层更好地对目标相机姿态进行编码来实现这一点。后者通过告诉每个像素其特定的观察方向,将姿态信息注入底层2D图像生成器。我们还通过轻量级的多视图注意力层和多视图噪声共享改善了多视图一致性。我们在Objaverse数据集上训练Free3D,并展示了在多个新数据集中对各种新类别的出色泛化效果,包括OminiObject3D和GSO。我们希望我们的简单而有效的方法将作为一个坚实的基线,并在更准确的姿态下帮助未来NVS研究。项目页面可在 https://chuanxiaz.com/free3d/ 查看。

图1. Free3D在开放集环境中进行的新视角合成。在给定单个输入视图的情况下,我们的方法能够准确地合成一致的360度视频,而无需显式的3D表示。仅在Objaverse上进行训练,它在新数据集和类别上表现出很好的泛化能力。
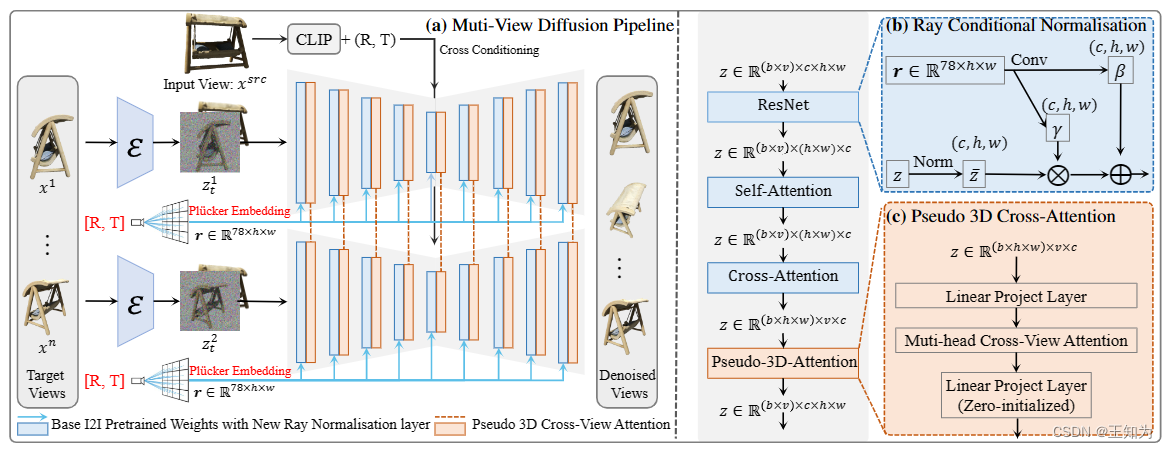
图2. 我们的Free3D的整体流程。(a) 给定单个源输入图像,提出的架构联合预测多个目标视图,而不是独立处理它们。为了实现一致的新视角合成而无需3D表示,(b) 我们首先提出了一种新颖的射线条件归一化(RCN)层,它使用每个像素的定向相机射线来调节潜在特征,从而使模型能够捕捉更精确的视点。? 引入了一个内存友好的伪3D交叉注意力模块,以有效地在多个生成的视图之间传递信息。请注意,这里相似度分数仅在时间上而非空间上计算,从而带来最小的计算和内存成本。

图3. 感知路径长度一致性(PPLC)。为了部分补偿视角变化,第二张图在比较之前相对于第一张进行了校正。为了说明使用校正的重要性,图中显示了一个大的方位角 φ: 57.6? 下的两个物体。顶行左侧显示了一个理想渲染的图像对,然而由于视角变化而导致了较大的LPIPS损失。右侧通过校正减小了这个分数。底行显示了相反的情况,其中一对不正确渲染的视图通过校正使其LPIPS损失增加。

图4. Objaverse上的定性比较。给定目标姿势,与现有的最先进方法相比,我们的Free3D显著提高了生成的姿势的准确性。请注意,Zero123-XL [17]是在规模更大的Objaverse-XL数据集[17]上训练的,该数据集包含1000万个3D对象。在附录图C.1和C.2中提供了更多的比较。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大语言模型漏洞缓解指南
- 【网络技术】【Kali Linux】Wireshark嗅探(七)超文本传送协议(HTTP)
- Http与Tcp协议的原理以及应用
- 基于YOLOv7算法的高精度实时车载摄像头下车辆检测系统(PyTorch+Pyside6+YOLOv7)
- JAVA进化史: JDK9特性及说明
- 近期封神的情绪文案
- 简中繁中互相转换gbk big5
- Orchestrator源码分析1-实例/拓扑发现
- 【AI视野·今日Sound 声学论文速览 第四十四期】Tue, 9 Jan 2024
- 老师家访的目的是什么