MySQL窗口函数(MySQL Window Functions)
1、窗口函数基本概念
官网地址:https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
窗口可以理解为 记录集合,窗口函数就是在满足某种条件的记录集合上执行的特殊函数。
即:每条记录都要在此窗口内执行函数。
-
静态窗口:每条记录都要在此窗口内执行函数,窗口大小都是固定的。
-
动态窗口:不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数也称为 OLAP(Online Anallytical Processing)函数,意思是对数据库数据进行实时分析处理。窗口函数就是为了实现 OLAP 而添加的标准 SQL 功能。
窗口函数对一组查询行执行类似聚合的操作。然而,聚合操作将查询行分组为单个结果行,而窗口函数为每个查询行生成一个结果:
-
发生函数计算的行称为当前行。
-
与对其进行函数计算的当前行相关的查询行构成当前行的窗口。
2、语法格式
函数名(字段名) over(子句);
over 括号内若不写,则意味着窗口函数基于满足 where 条件的所有行进行计算;
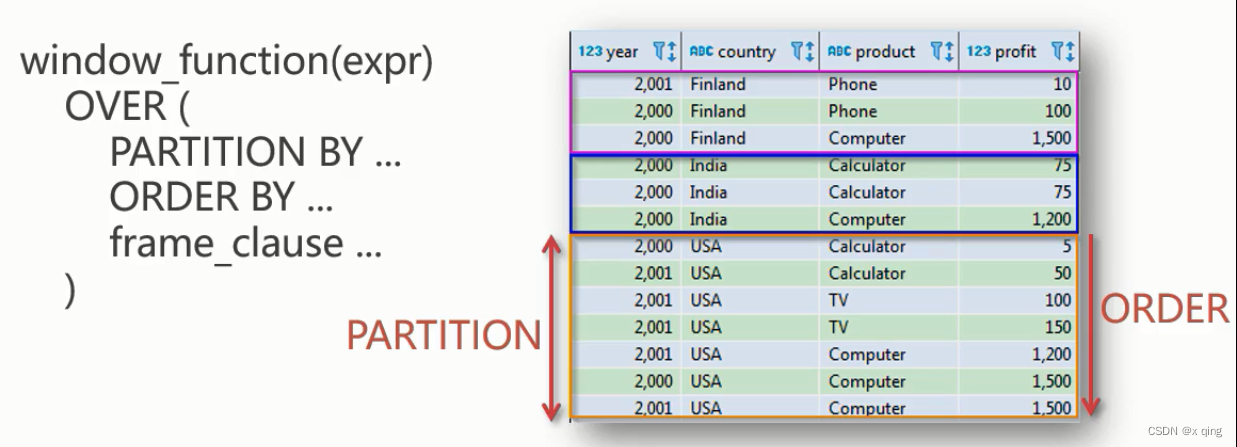
若括号内不为空,则支持以下语法来设置窗口:
函数名(字段名) over(partition by <要分列的组> order by <要排序的列> rows或者range between <数据范围>)
- partition by子句:按照指定字段进行分区,两个分区由边界分隔,窗口函数在不同的分区内分别执行,在跨越分区边界时重新初始化。
- order by子句:按照指定字段进行排序,窗口函数将按照排序后的记录顺序进行编号。可以和partition by子句配合使用,也可以单独使用。
- frame子句:当前分区的一个子集,用来定义子集的规则,通常用来作为滑动窗口使用。
数据范围:
数据范围由units(单位)和 extent(范围) 两部分组成
单位可以有2种选择:
- rows:通过起始行和结束行来划定范围,边界是明确的一行。
- range:通过具有相同值的行来划定范围,边界是一个范围,具有相同值的行作为一个整体看待。
范围也要两种定义方式:
- 只定义起始点(
start),终止点(end)默认就是当前行。 - 通过
between start and end子句,同时定义起始点(start)和终止点 (end)。
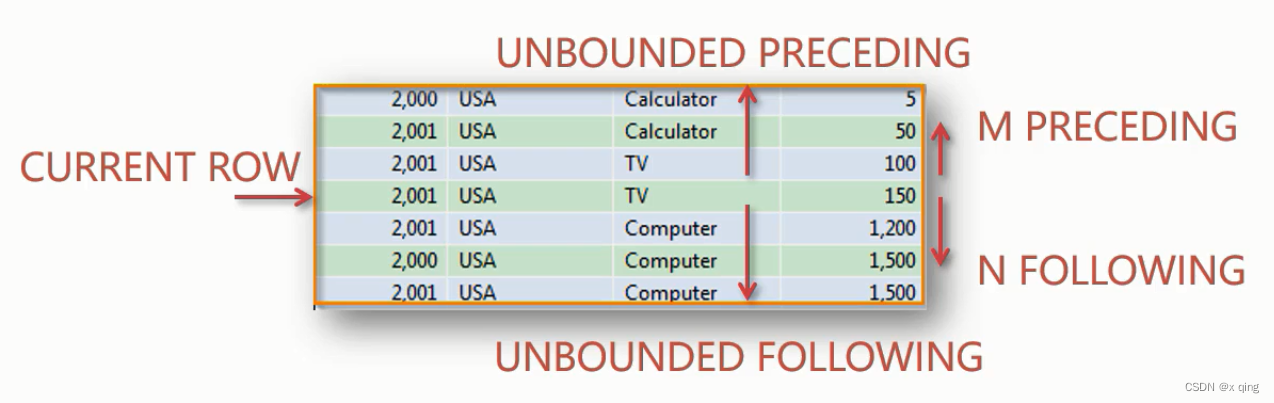
合法的start和end可以有如下5种选择:
- current row:当单位是
rows时,即当前行。当单位是range时,包含当前行和当前行相同的行(一个范围)。 - unbound preceding:窗口内第1行。
- unbound following:窗口内最后1行。
- expr preceding:当单位是
rows时, 边界时当前行的前expr行。当单位是range时,边界是值和"当前行的值-expr"相等的行,如果当前行的值是null,那边界就是和当前行相等的行。 - expr following:当单位是
rows时, 边界时当前行的后expr行。当单位是range时,边界时和"当前行的值+expr"相等的行,如果当前行的值是null,那边界就是和当前行相等的行。
举例:
# 取本行和前面两行
rows between 2 preceding and current row
# 取本行和之前所有的行
rows between unbounded preceding and current row
# 取本行和之后所有的行
rows between current row and unbounded following
# 从前面三行和下面一行,总共五行
rows between 3 preceding and 1 following
# 当 order by 后面没有 rows between 时,窗口规范默认是取本行和之前所有的行
# 当 order by 和 rows between 都没有时,窗口规范默认是分组下所有行 (rows between unbounded preceding and unbounded following)
# 当前行和当前行值减1范围 等价于 range between 1 preceding and current row。代表值的范围落在区间 [当前行值-1,当前行值] 内所有行。
# 这里的1 preceding不再是前1行的意思,而是"当前行的值-1"。
range 1 preceding
单位rows和range的区别
建表语句
create table wf_example(
id smallint unsigned not null auto_increment primary key,
wind varchar(32),
val smallint);
insert into wf_example values
(null,'Window_A',1),
(null,'Window_A',2),
(null,'Window_A',2),
(null,'Window_A',3),
(null,'Window_A',3),
(null,'Window_A',3),
(null,'Window_B',100),
(null,'Window_B',200),
(null,'Window_B',300),
(null,'Window_B',400),
(null,'Window_B',500);
示例为滚动求和,计算当前行和前一行的和:
select wind,val,
sum(val) over (partition by wind order by val rows 1 preceding) 当前行和前1行的和,
sum(val) over (partition by wind order by val rows between 1 preceding and current row) 第二种定义方式
from wf_example;
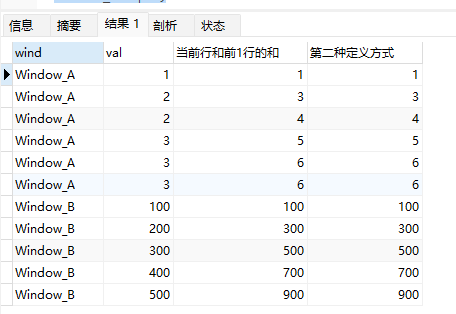
上面示例中:
- 第一个定义是
rows 1 preceding,单位是rows(行), - 第一个范围是
1 preceding(当单位为rows时,1 preceding代表当前行的前1行). - 第一个采用了仅定义起始点的方式,终止点默认就是当前行。
- 第二个采用了
between 1 preceding and current row的方式,显式指定了起始和结束范围,效果是相同的。
我们将一个滚动求和SQL中的单位定义由rows改为range,再看一下效果:
select wind,val,
sum(val) over (partition by wind order by val range 1 preceding) range单位下当前行和当前行值减1范围的和
from wf_example;
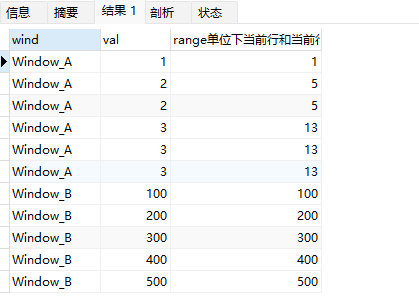
面示例中,当单位变为range时:
- 定义为 range 1 preceding,等价于 range between 1 preceding and current row。
- 当单位为range时,这里的1 preceding不再是前1行的意思,而是"当前行的值-1"。
- 而range between 1 preceding and current row 代表值的范围落在区间 [当前行值-1,当前行值] 内所有行。
- 在Window_A中,第二行val值为2,因此包含值在 [2-1, 2] 范围内的所有行,即1,2,3行,sum求和结果为5,第三行同理。
- 在Window_A中,第四行val值为3,因此包含值在 [3-1, 3] 范围内的所有行,即2,3,4,5,6行,sum求和结果为13,第五、六行同理。
- 在Window_B中,第2行val值为200,因此包含值在[200-1, 200]范围内的所有所有行,只有第二行,sum求和结果就是自己,后面的行同理。
上面的SQL通过加入first_value和last_value函数我们可以更直观的看出边界(first_value返回内第1个值,last_value返回内最后一个值):
select wind,val,
sum(val) over (partition by wind order by val range 1 preceding) range单位下当前行和当前行值减1范围的和,
first_value(val) over (partition by wind order by val range 1 preceding) first_val,
last_value(val) over (partition by wind order by val range 1 preceding) last_val
from wf_example;
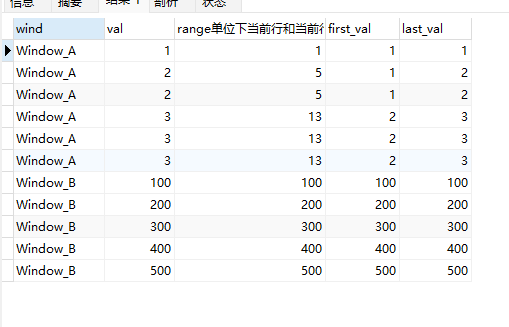
- 在Window_A中,val的值差距为1,因此 range 1 preceding可以触及前面的行。
- 在Window_B中,val的值差距为100,因此range 1 preceding无法触及前面的行(first_value和last_value都是自己),每一行的都只包含当前行自己。
但如果我们把range 1 preceding改成 range 100 preceding,则Window_B中可以触及前面的行:
select wind,val,
sum(val) over (partition by wind order by val range 100 preceding) range单位下当前行和当前行值减1范围的和,
first_value(val) over (partition by wind order by val range 100 preceding) first_val,
last_value(val) over (partition by wind order by val range 100 preceding) last_val
from wf_example;
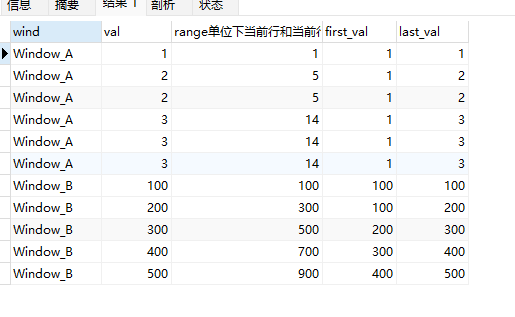
可以看到Window_B中求和列变成了当前行和前1行的val的和,同时first_val变成了前1行的值(代表当前行的包含前1行)。
单位rows和range的区别总结就是:
rows是通过行来划分边界,边界是明确的某一行。
range是通过值来划定边界,边界是具有某个值的所有行。
缺少order by子句
根据窗口定义是否有order by子句:
- 有 order by 子句时,默认的定义是:range between unbound preceding and
current row - 没有 order by 子句时,默认的定义是:range between unbound preceding and
unbound following
即:当有order by 子句时,是从组内第一行到当前行(注意单位是range,也包含当前行相同值的行)。当没有order by 子句时,就是从组内第1行到最后一行(组内所有行),所有的行都是相等的。
我们通过最初的sum函数来观察这种的区别:
select wind,val,
sum(val) over (partition by wind order by val) 带orderby子句,
sum(val) over (partition by wind) 不带orderby子句
from wf_example
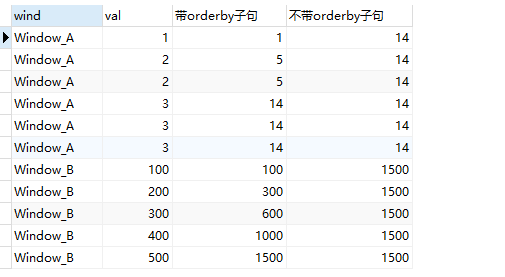
上面示例中:
- 带order by子句时,sum函数求和范围是第1行到当前行(包含和当前行相等的行)的和,sum的结果是递增的。
- 不带order by 子句时,每一行sum,求出来都是组内全部行的和,没有order by子句,众生平等。
3、窗口函数和普通聚合函数的区别
①聚合函数是将多条记录聚合为一条; 窗口函数是每条记录都会执行,有几条记录执行完还是几条。
②聚合函数也可以用于窗口函数。
4、命名窗口
当一个窗口被多次引用的时候,在每个over后面都写一遍定义就显得有些繁琐了,此场景可以通过命名窗口优化:一次定义,多次引用。
命名窗口的定义是通过 window wind_name as () 来进行定义的,括号内的部分就是原over子句后的窗口定义,在用over关键字调用窗口时,直接引用窗口名wind_name即可:
select wind,
sum(val) over w group_sum -- 通过名称 w 引用窗口
from wf_example
window w as (partition by wind); -- 命名窗口定义
通常情况下使用时只需要直接引用窗口名称即可,有时需要对窗口进一步加工,例如排序等,可以用括号将窗口名扩起来,后面跟上order by 子句:
select wind,
first_value(val) over (w order by val desc) first_val_desc, -- 通过窗口名引用,并降序排列
first_value(val) over (w order by val asc) first_val_asc -- 通过窗口名引用,并升序排列
from wf_example
window w as (partition by wind); -- 命名窗口定义
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java中Semaphore的深入解析与实战应用
- JTAG 扫描不到EBAZ4205 ZYNQ PS原因分析
- java ssm 二手图书销售系统 闲置图书交易平台 校园图书交易 jsp
- 偷偷读个中国社科院与新加坡新跃社科联合培养博士惊艳你们
- async、await、Promise 的底层实现
- Redis-Day2实战篇-短信登录(基于Session实现登录, 集群的session共享问题, 基于Redis实现共享session登录)
- FFmpeg转码流程和常见概念
- Pandas.DataFrame.drop() 删除行或列 详解 含代码 含测试数据集 随Pandas版本持续更新
- 推荐几个靠谱的视频素材网站,让你的作品更吸引人~
- 机器学习---协同过滤