gcc扩展选项__attribute__((interrupt))——指定中断处理函数属性
发布时间:2024年01月20日
1、调用者保存寄存器与被调用者保存寄存器
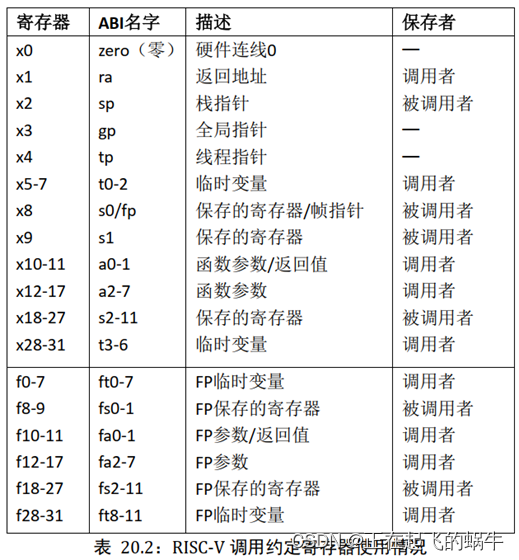
- 假设:函数A调用了函数B,寄存器x在函数B中被修改了,对于A函数而言,逻辑上x内容在调用函数B的前后应该保持一致。现在需要解决前后不一致的问题,有两种思路:
- 第一种:调用者保存的寄存器
- 在函数A在调用函数B之前提前把寄存器x的值存入栈中,执行完函数B之后再恢复x的内容。
- 在函数跳转前保存的寄存器,叫调用者保存寄存器
- 第二种:被调用者保存的寄存器
- 函数B在使用寄存器x前,先保存寄存器x的值到栈中,在函数B返回之前,要恢复寄存器x原来存储
的内容 - 在函数中,使用前必须保存、返回前必须恢复的寄存器
- 函数B在使用寄存器x前,先保存寄存器x的值到栈中,在函数B返回之前,要恢复寄存器x原来存储
- 第一种:调用者保存的寄存器
- 至于怎么划分寄存器是调用者保存,还是被调用者保存,这是芯片架构的函数调用规范决定的,写C语言的程序员不用感知。想了解RISC-V架构的函数调用规范,可参考文章:《RISC-V架构的函数调用规范和栈布局》;
2、异常向量表的访问方式:direct mode、vector mode
- 参考文章:《RISC-V架构——中断处理和中断控制器介绍》;
3、attribute((interrupt))的作用
__attribute__((interrupt)) void my_interrupt_function(void)
{
...... //中断处理
return;
}
- 在使用中断的vector模式时,需要将中断处理函数写到对应的异常向量表处,当产生中断时,硬件将自动跳转
- 中断处理就涉及到中断现场的保存和恢复,vector模式的中断处理函数一般C语言写的,那是否需要在中断处理函数里去写保存/恢复中断现场的代码?答案是不需要,只需要再中断处理函数前使用“attribute((interrupt))”修饰
- 作用:编译器将C语言写的中断处理函数翻译成汇编代码时,会自动插入保存/恢复现场的汇编代码。也就是把中断处理函数中会用到的寄存器都先存入栈中,在中断返回前,再从栈里面读出来恢复到寄存器中
4、汇编代码分析

- 同样的C语言函数,对比使用/不使用__attribute__((interrupt))修饰得到的反汇编文件
- 可以看到,使用__attribute__((interrupt))修饰后,汇编代码会多申请栈空间用于保存/恢复现场
5、总结
- 不使用__attribute__((interrupt))修饰,函数内只需要保存
被调用者保存的寄存器 - 使用__attribute__((interrupt))修饰后,只要在函数内使用到的寄存器都必须保存再恢复,会占用更多的栈空间,翻译得到的汇编代码也会增多
- 还可以指定中断处理函数的优化等级:
__attribute__((interrupt, optimize("O0"))) - 总结:只有中断处理函数才用__attribute__((interrupt))修饰,其余常规函数不要使用
文章来源:https://blog.csdn.net/weixin_42031299/article/details/135715599
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 常用排序算法:插入排序、希尔排序、选择排序、冒泡排序、快速排序、归并排序
- conda create SafetyError
- ES 通过查询更新某个字段,Error 500 (Internal Server Error)
- 微信小程序map组件如何使用?
- win10安装linux子系统失败问题、成功后迁移子系统、卸载子系统、修改子系统默认登录用户
- VG7050ECN 可编程压控晶体振荡器 (VCXO) 输出:LV-PECL
- C语言学习第二十七天(单链表)
- springboot/java/php/node/python葫芦卖菜管理系统【计算机毕设】
- 大学毕业生论文查重怎么样才能降低重复率呢?
- 关于 LockWindowUpdate 的最终总结