MYSQL高级SQL语句
目录
一、环境准备
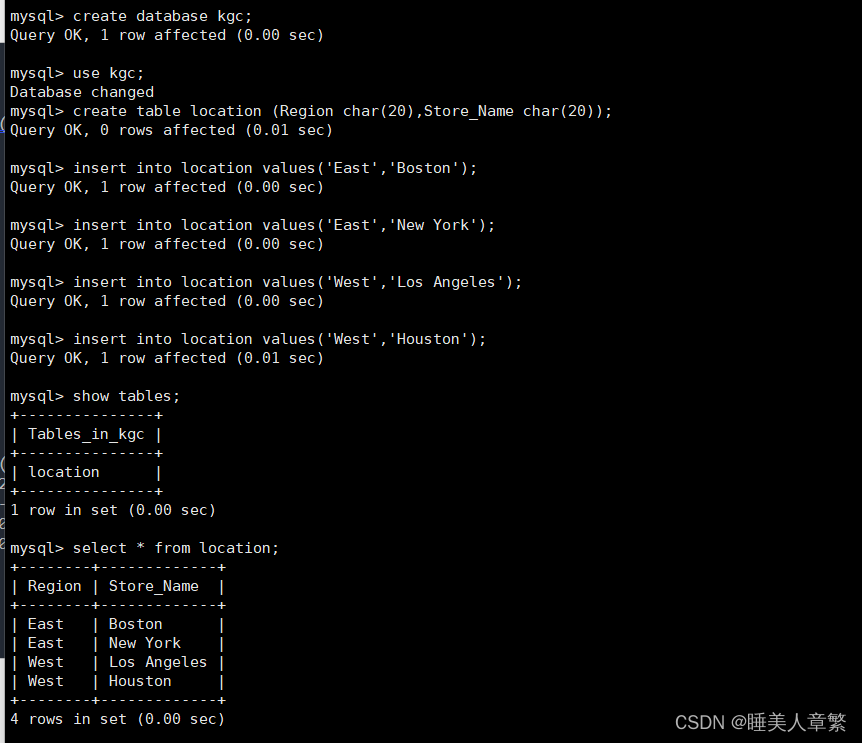
create database kgc;
use kgc;
create table location (Region char(20),Store_Name char(20));
insert into location values('East','Boston');
insert into location values('East','New York');
insert into location values('West','Los Angeles');
insert into location values('West','Houston');
location 表格
+----------+--------------+
| Region | Store_Name |
|----------+--------------|
| East | Boston |
| East | New York |
| West | Los Angeles |
| West | Houston |
+----------+--------------+
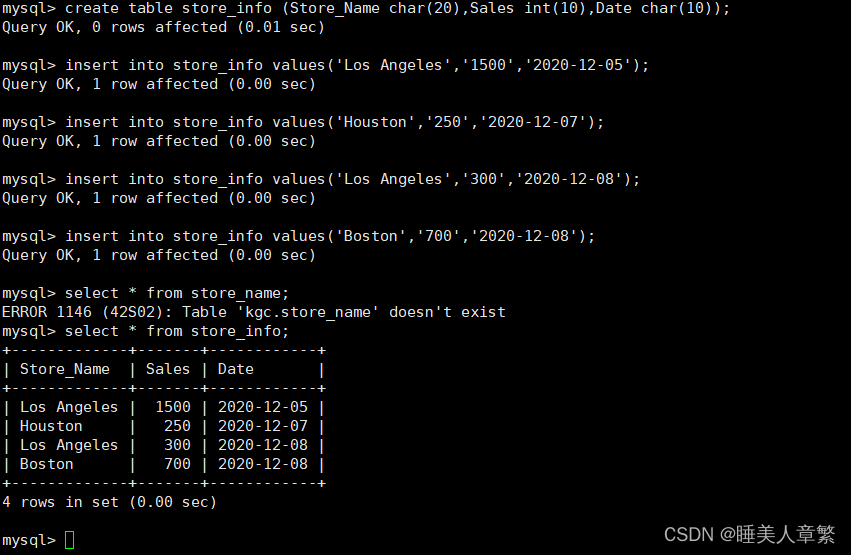
create table store_info (Store_Name char(20),Sales int(10),Date char(10));
insert into store_info values('Los Angeles','1500','2020-12-05');
insert into store_info values('Houston','250','2020-12-07');
insert into store_info values('Los Angeles','300','2020-12-08');
insert into store_info values('Boston','700','2020-12-08');
Store_Info 表格
+--------------+---------+------------+
| Store_Name | Sales | Date |
|--------------+---------+------------|
| Los Angeles | 1500 | 2020-12-05 |
| Houston | 250 | 2020-12-07 |
| Los Angeles | 300 | 2020-12-08 |
| Boston | 700 | 2020-12-08 |
+--------------+---------+------------+
二、高级SQL语句
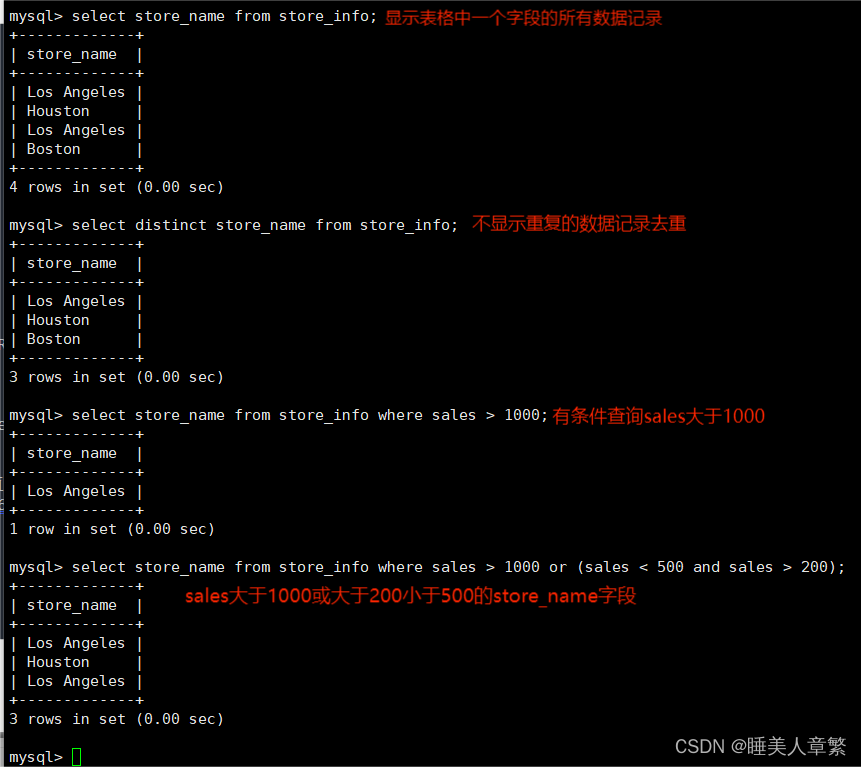
---- SELECT ----显示表格中一个或数个字段的所有数据记录
语法:SELECT "字段" FROM "表名";
SELECT Store_Name FROM Store_Info;
---- DISTINCT ----不显示重复的数据记录
语法:SELECT DISTINCT "字段" FROM "表名";
SELECT DISTINCT Store_Name FROM Store_Info;
---- WHERE ----有条件查询
语法:SELECT "字段" FROM "表名" WHERE "条件";
SELECT Store_Name FROM Store_Info WHERE Sales > 1000;
---- AND OR ----且 或
语法:SELECT "字段" FROM "表名" WHERE "条件1" {[AND|OR] "条件2"}+ ;
SELECT Store_Name FROM Store_Info WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);
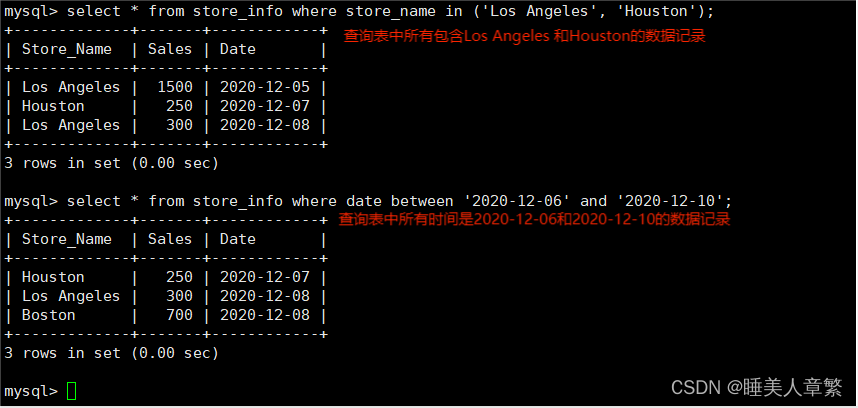
---- IN ----显示已知的值的数据记录
语法:SELECT "字段" FROM "表名" WHERE "字段" IN ('值1', '值2', ...);
SELECT * FROM Store_Info WHERE Store_Name IN ('Los Angeles', 'Houston');
---- BETWEEN ----显示两个值范围内的数据记录
语法:SELECT "字段" FROM "表名" WHERE "字段" BETWEEN '值1' AND '值2';
SELECT * FROM Store_Info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';
三、通配符(通常通配符都是跟 LIKE 一起使用的)
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符
'A_Z':所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串。例如,'ABZ' 和 'A2Z' 都符合这一个模式,而 'AKKZ' 并不符合 (因为在 A 和 Z 之间有两个字符,而不是一个字符)。
'ABC%': 所有以 'ABC' 起头的字符串。例如,'ABCD' 和 'ABCABC' 都符合这个模式。
'%XYZ': 所有以 'XYZ' 结尾的字符串。例如,'WXYZ' 和 'ZZXYZ' 都符合这个模式。
'%AN%': 所有含有 'AN'这个模式的字符串。例如,'LOS ANGELES' 和 'SAN FRANCISCO' 都符合这个模式。
'_AN%':所有第二个字母为 'A' 和第三个字母为 'N' 的字符串。例如,'SAN FRANCISCO' 符合这个模式,而 'LOS ANGELES' 则不符合这个模式。
LIKE(匹配一个模式来找出我们要的数据记录)
语法:SELECT "字段" FROM "表名" WHERE "字段" LIKE {模式};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';
---- ORDER BY ----按关键字排序
语法:SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。
SELECT Store_Name,Sales,Date FROM Store_Info ORDER BY Sales DESC;

四、函数
数学函数:
abs(x)?? ??? ??? ??? ?返回 x 的绝对值
rand()?? ??? ??? ??? ?返回 0 到 1 的随机数
mod(x,y)?? ??? ??? ?返回 x 除以 y 以后的余数
power(x,y)?? ??? ??? ?返回 x 的 y 次方
round(x)?? ??? ??? ?返回离 x 最近的整数
round(x,y)?? ??? ??? ?保留 x 的 y 位小数四舍五入后的值
sqrt(x)?? ??? ??? ??? ?返回 x 的平方根
truncate(x,y)?? ??? ?返回数字 x 截断为 y 位小数的值
ceil(x)?? ??? ??? ??? ?返回大于或等于 x 的最小整数
floor(x)?? ??? ??? ?返回小于或等于 x 的最大整数
greatest(x1,x2...)?? ?返回集合中最大的值,也可以返回多个字段的最大的值
least(x1,x2...)?? ??? ?返回集合中最小的值,也可以返回多个字段的最小的值
SELECT abs(-1), rand(), mod(5,3), power(2,3), round(1.89);
SELECT round(1.8937,3), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.89,3,6.1,2.1);
聚合函数:
avg()?? ??? ??? ??? ?返回指定列的平均值
count()?? ??? ??? ??? ?返回指定列中非 NULL 值的个数
min()?? ??? ??? ??? ?返回指定列的最小值
max()?? ??? ??? ??? ?返回指定列的最大值
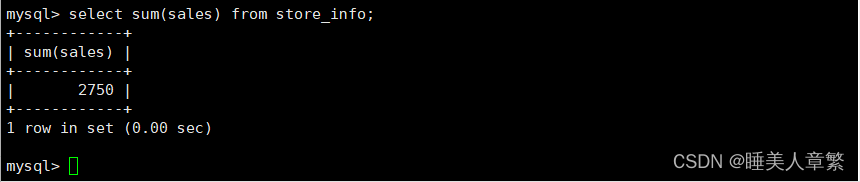
sum(x)?? ??? ??? ??? ?返回指定列的所有值之和
?
SELECT avg(Sales) FROM Store_Info;
SELECT count(Store_Name) FROM Store_Info;
SELECT count(DISTINCT Store_Name) FROM Store_Info;
SELECT max(Sales) FROM Store_Info;
SELECT min(Sales) FROM Store_Info;
SELECT sum(Sales) FROM Store_Info;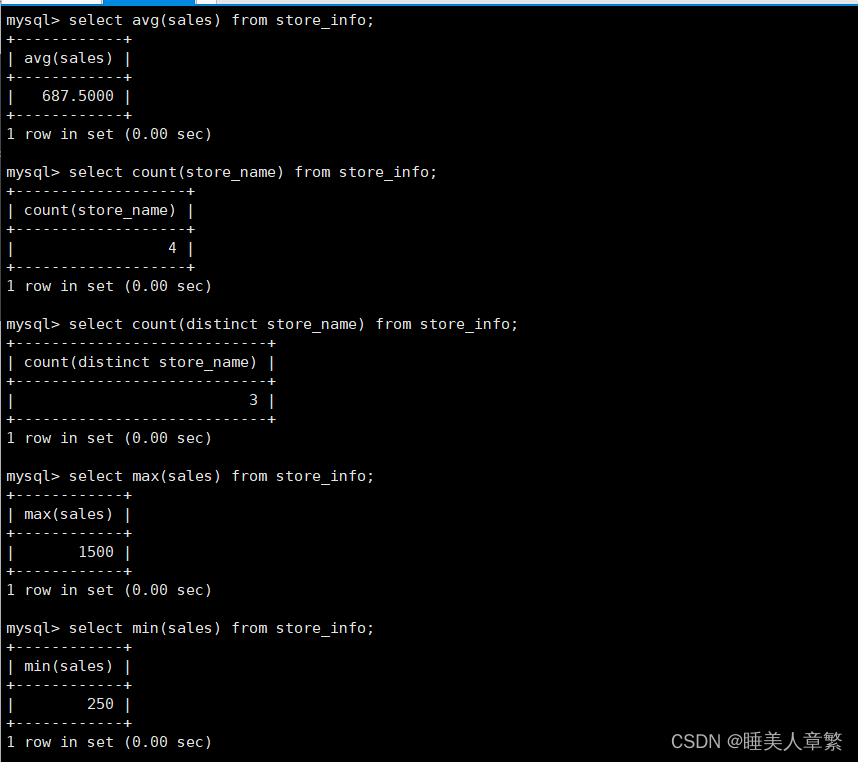
字符串函数:
trim()?? ??? ??? ??? ?返回去除指定格式的值
concat(x,y)?? ??? ??? ?将提供的参数 x 和 y 拼接成一个字符串
substr(x,y)?? ??? ??? ?获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同
substr(x,y,z)?? ??? ?获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串
length(x)?? ??? ??? ?返回字符串 x 的长度
replace(x,y,z)?? ??? ?将字符串 z 替代字符串 x 中的字符串 y
upper(x)?? ??? ??? ?将字符串 x 的所有字母变成大写字母
lower(x)?? ??? ??? ?将字符串 x 的所有字母变成小写字母
left(x,y)?? ??? ??? ?返回字符串 x 的前 y 个字符
right(x,y)?? ??? ??? ?返回字符串 x 的后 y 个字符
repeat(x,y)?? ??? ??? ?将字符串 x 重复 y 次
space(x)?? ??? ??? ?返回 x 个空格
strcmp(x,y)?? ??? ??? ?比较 x 和 y,返回的值可以为-1,0,1
reverse(x)?? ??? ??? ?将字符串 x 反转
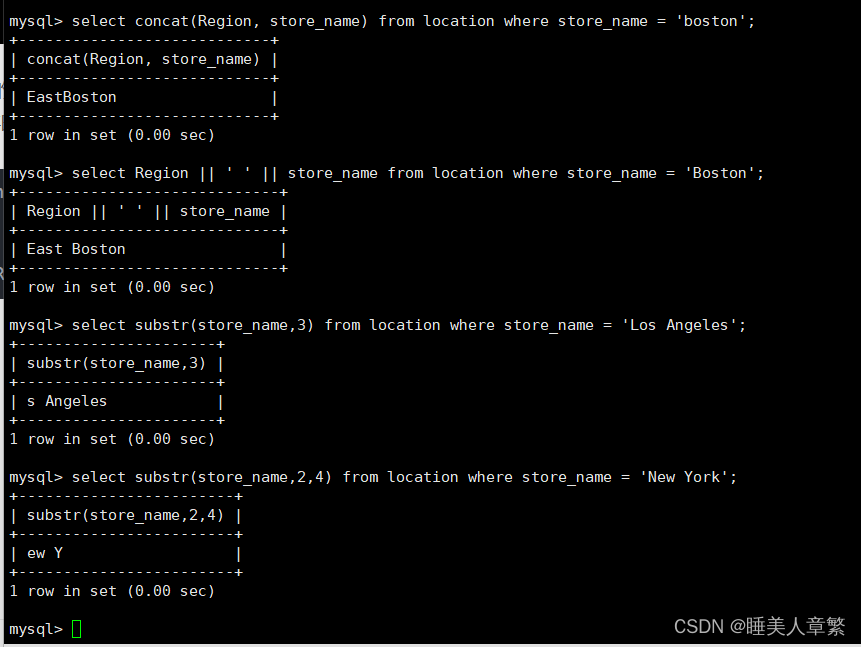
SELECT concat(Region, Store_Name) FROM location WHERE Store_Name = 'Boston';
#拼接字符串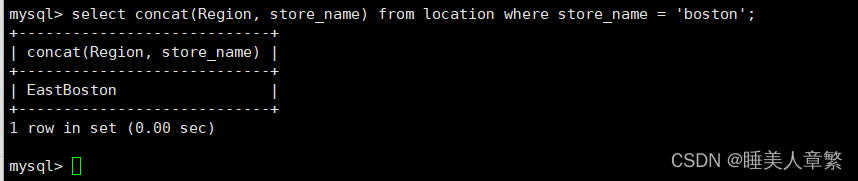
#如sql_mode开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';
SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。?
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
?
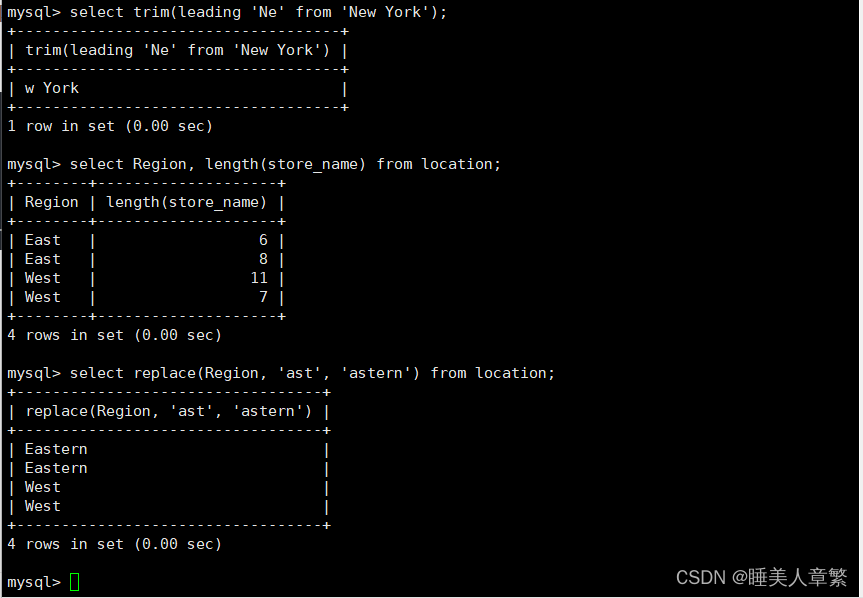
SELECT TRIM(LEADING 'Ne' FROM 'New York');
SELECT Region,length(Store_Name) FROM location;
SELECT REPLACE(Region,'ast','astern')FROM location;
GROUP BY(对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的)
GROUP BY 有一个原则,凡是在 GROUP BY 后面出现的字段,必须在 SELECT 后面出现;
凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面
语法:SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1";
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;
HAVING(用来过滤由 GROUP BY 语句返回的记录集,通常与 GROUP BY 语句联合使用)
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
语法:SELECT "字段1", SUM("字段2") FROM "表格名" GROUP BY "字段1" HAVING (函数条件);
?
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM(Sales) > 1500;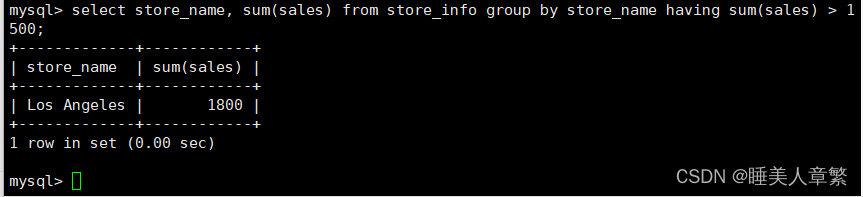
别名(字段別名 表格別名)
语法:SELECT "表格別名"."字段1" [AS] "字段別名" FROM "表格名" [AS] "表格別名";
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;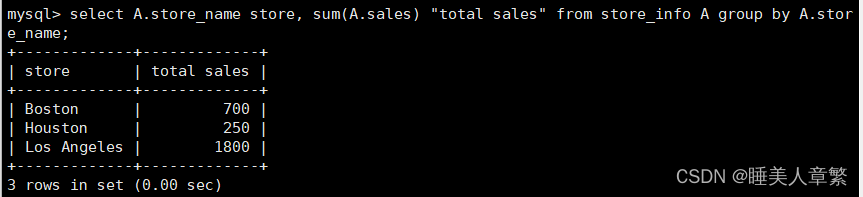
子查询(连接表格,在WHERE 子句或 HAVING 子句中插入另一个 SQL 语句)
语法:SELECT "字段1" FROM "表格1" WHERE "字段2" [比较运算符] ?? ??? ??? ??? ?#外查询
(SELECT "字段1" FROM "表格2" WHERE "条件");?? ??? ??? ??? ??? ??? ??? ??? ??? ?#内查询
#可以是符号的运算符,例如 =、>、<、>=、<= ;也可以是文字的运算符,例如 LIKE、IN、BETWEEN
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM location WHERE Region = 'West');
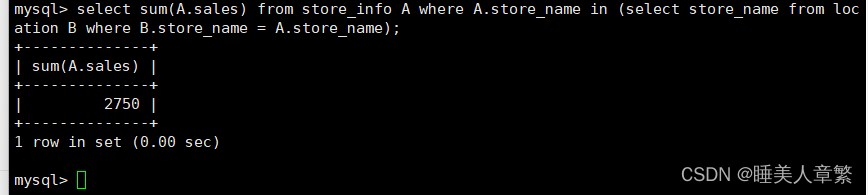
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);

EXISTS(用来测试内查询有没有产生任何结果,类似布尔值是否为真)
#如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果。
语法:SELECT "字段1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
?
SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');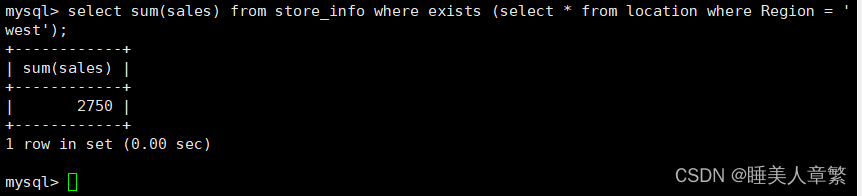
连接查询
location 表格
+----------+--------------+
| Region | Store_Name |
|----------+--------------|
| East | Boston |
| East | New York |
| West | Los Angeles |
| West | Houston |
+----------+--------------+
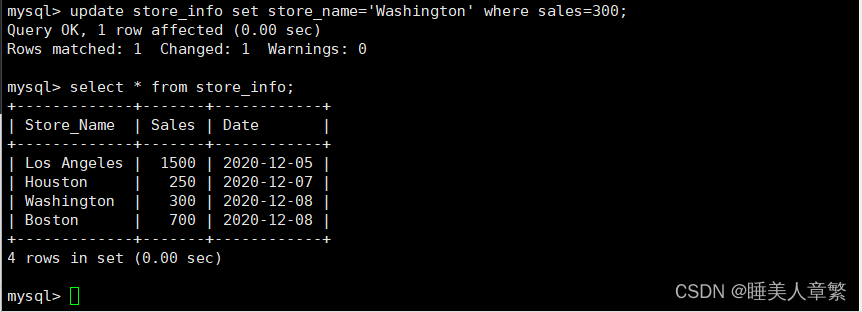
UPDATE Store_Info SET store_name='Washington' WHERE sales=300;
Store_Info 表格
+--------------+---------+------------+
| Store_Name | Sales | Date |
|--------------+---------+------------|
| Los Angeles | 1500 | 2020-12-05 |
| Houston | 250 | 2020-12-07 |
| Washington | 300 | 2020-12-08 |
| Boston | 700 | 2020-12-08 |
+--------------+---------+------------+
inner join(内连接):只返回两个表中联结字段相等的行
left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录?
right join(右连接):返回包括右表中的所有记录和左表中联结字段相等的记录
SELECT * FROM location A RIGHT JOIN Store_Info B on A.Store_Name = B.Store_Name ;
SELECT * FROM location A LEFT JOIN Store_Info B on A.Store_Name = B.Store_Name ;
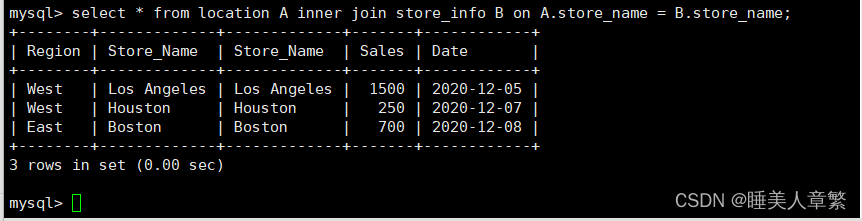
内连接一:
SELECT * FROM location A INNER JOIN Store_Info B on A.Store_Name = B.Store_Name ;
内连接二:
SELECT * FROM location A, Store_Info B WHERE A.Store_Name = B.Store_Name;
SELECT A.Region REGION, SUM(B.Sales) SALES FROM location A, Store_Info B
WHERE A.Store_Name = B.Store_Name GROUP BY REGION;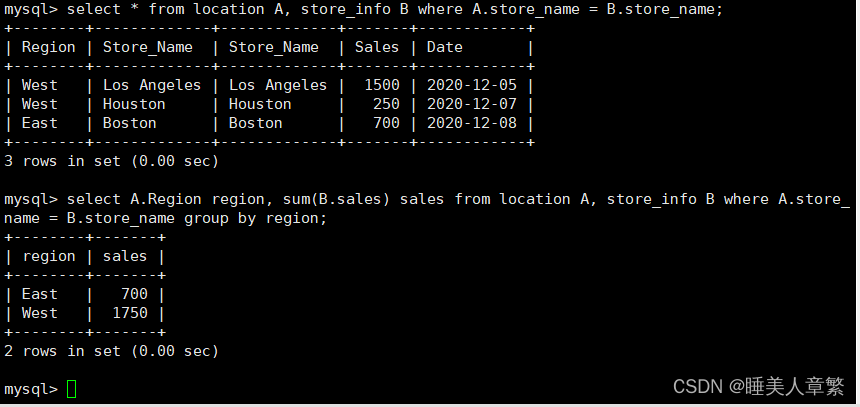
UNION(联集,将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类)
UNION :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
UNION ALL :将生成结果的数据记录值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM Store_Info;
SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM Store_Info;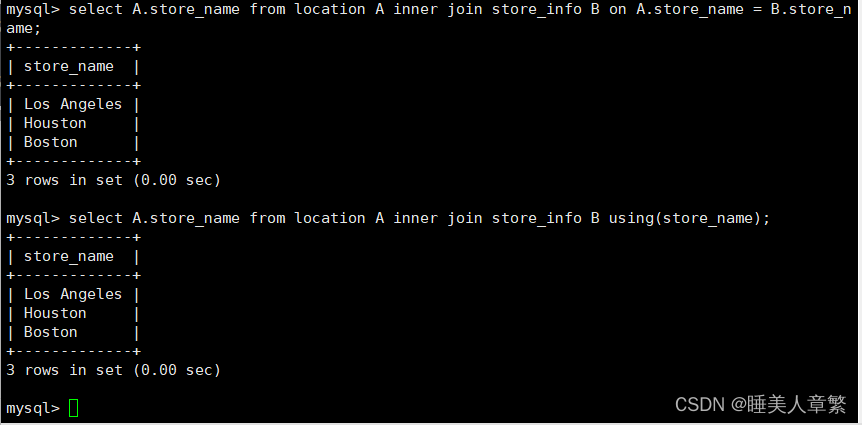
交集值(取两个SQL语句结果的交集)
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name;
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);#取两个SQL语句结果的交集,且没有重复
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
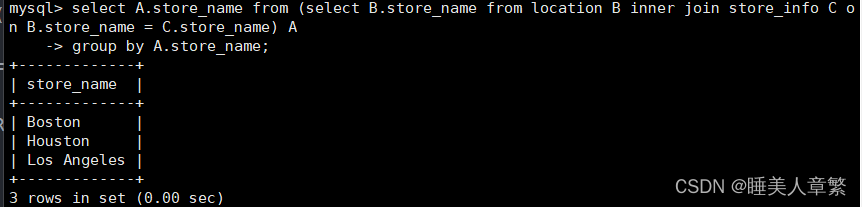
SELECT A.Store_Name FROM (SELECT B.Store_Name FROM location B INNER JOIN Store_Info C ON B.Store_Name = C.Store_Name) A
GROUP BY A.Store_Name;
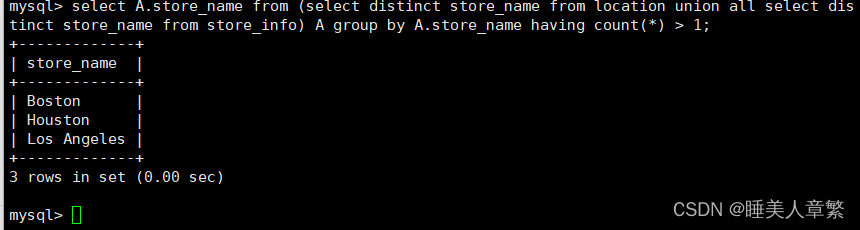
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM Store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;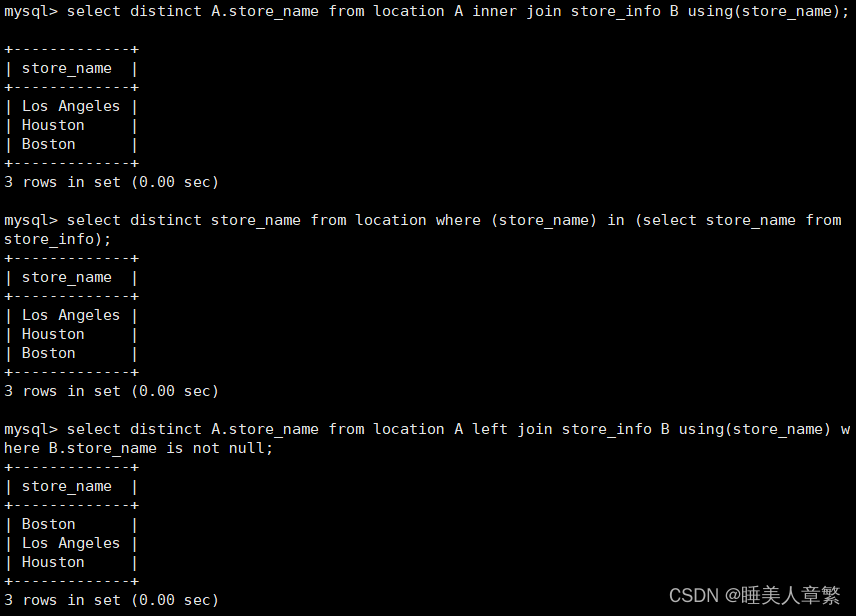
无交集值(显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复)
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NULL;
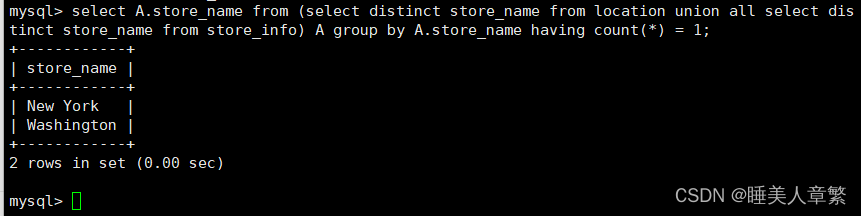
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM Store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) = 1;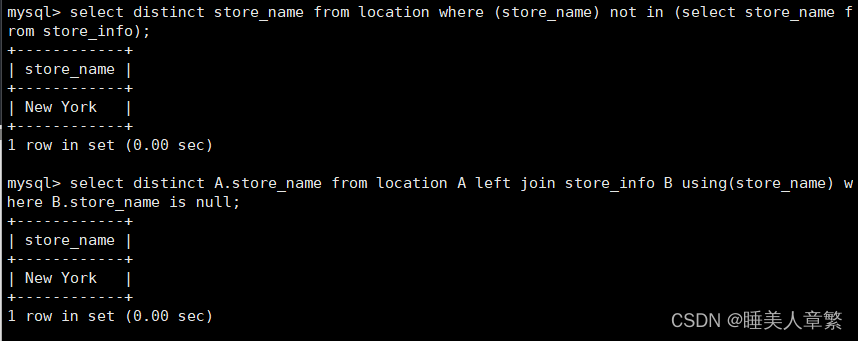
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 12.29_黑马数据结构与算法笔记Java
- NVIDIA jetson编译opencv 源码 python版本
- Modbus,DNP3的理解
- Ps2022版DR5插件扩展窗口不展示及未正确签署等问题修复
- go-carbon v2.3.5 发布,轻量级、语义化、对开发者友好的 golang 时间处理库
- 使用npm时一直idealTree:npm: sill idealTree buildDeps
- VC++项目的32位、64位的配置和链接问题
- 免费的数据恢复软件哪个好?这10个数据恢复软件可以试试
- Endnote中文献数据库的整体导出迁移,以及导入到新计算机具体步骤-以Endnote X8为例
- java开发安全之:Portability Flaw: File Separator