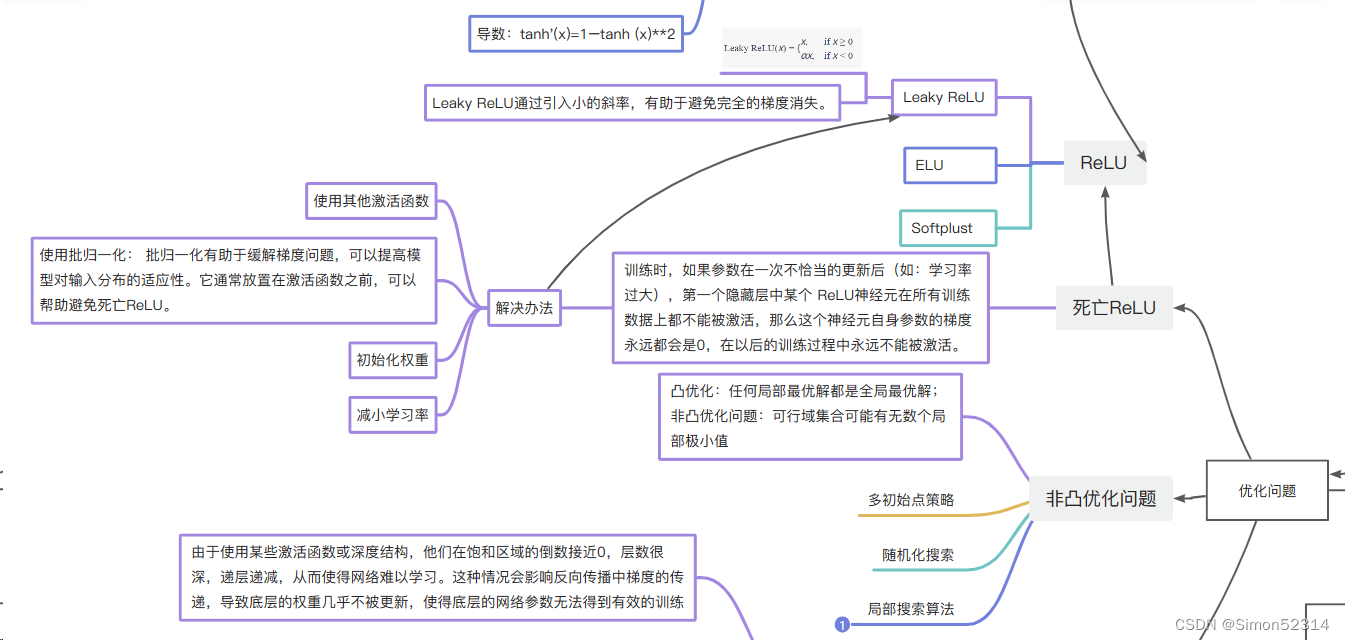
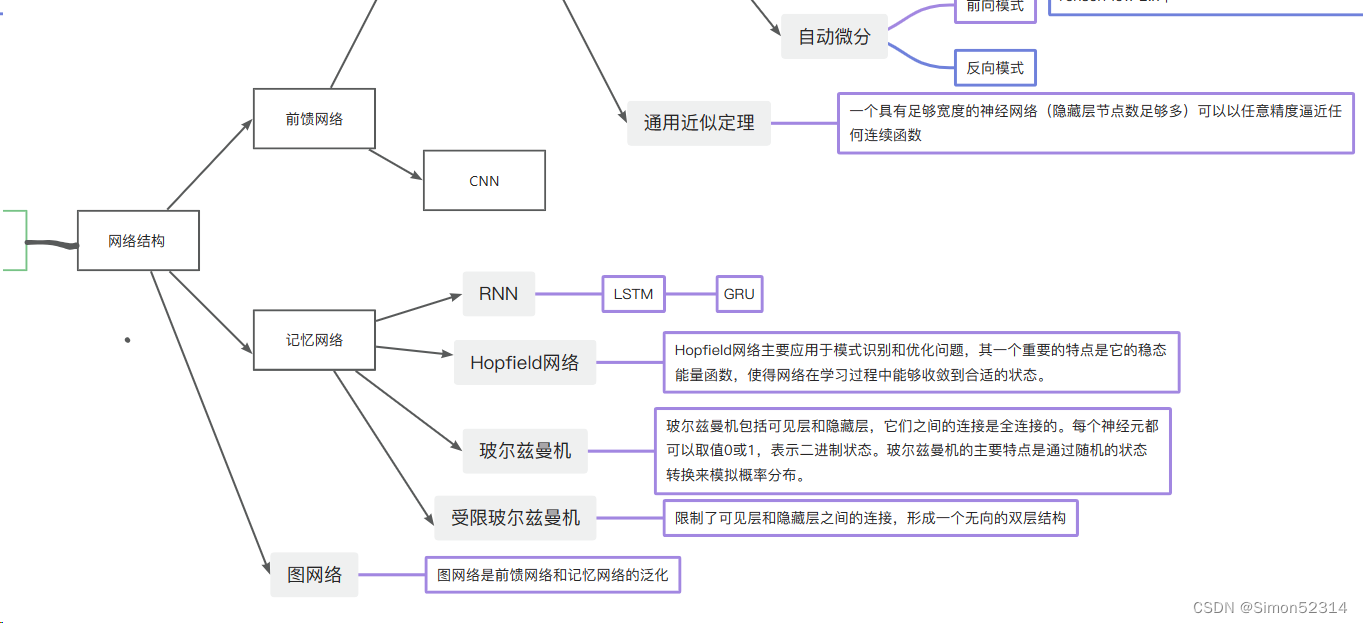
前馈神经网络复习
发布时间:2023年12月31日
 ?
?

 ?
?
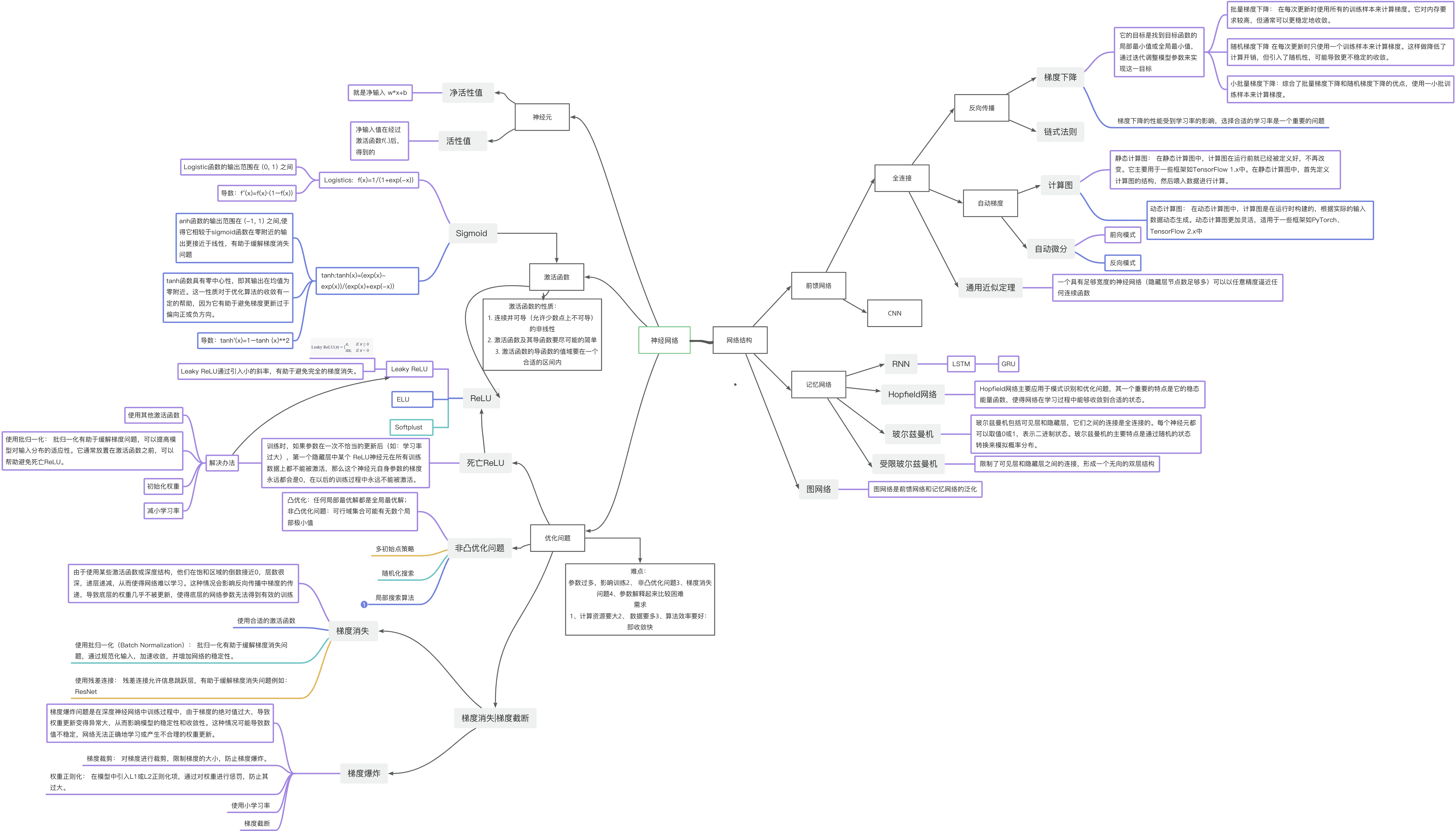
 ?习题4-1? 对于一个神经元(wx + b),并使用梯度下降优化参数w时如果输入x 恒大于0,其收敛速度会比零均值化的输入更慢
?习题4-1? 对于一个神经元(wx + b),并使用梯度下降优化参数w时如果输入x 恒大于0,其收敛速度会比零均值化的输入更慢
在全连接网络模型中,将输入的x值进行零均值化是一种预处理方法,旨在将训练集中的每个输入值x减去其均值,以0为中心,满足均值为0。这样做的优点是在反向传播时加快网络中每层权重参数的收敛,避免Z型更新的情况,从而加快神经网络的收敛速度。
零均值化,数据分布会距离零比较近,而激活函数在0附近的梯度比较大,这样收敛的快,此外,输入恒大于0,可能会引起抖动,反而不利于收敛
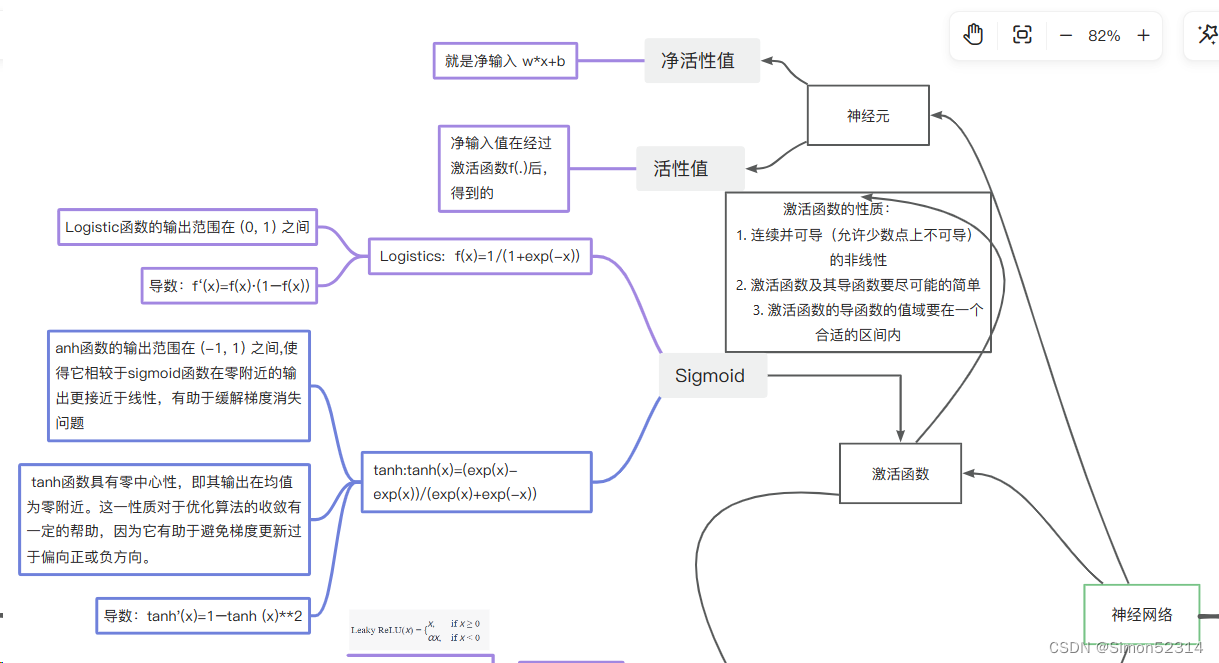
习题4-7 为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化??

习题4-8 为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令 w =0,b =0??
在使用反向传播算法进行参数学习时,采用随机参数初始化而不是直接将权重 w 和偏置 b 初始化为零的主要原因有两个:
对称性破坏: 如果将所有权重 w 初始化为相同的值,例如零,那么在模型进行反向传播的过程中,所有权重将保持相同的值,并且在更新梯度时会一直保持对称性。这导致了一个问题,即无论多少个神经元,它们都会以相同的方式响应相同的输入,这样就失去了神经网络学习特征的能力。
避免梯度消失: 如果所有权重和偏置都初始化为零,那么在反向传播的过程中,所有神经元的梯度将是相同的。这样,在进行梯度下降更新时,每个参数都会按相同的步长更新,导致网络在训练过程中很难学到有用的特征,同时也可能遇到梯度消失的问题。

 ?
?
?参考链接:
文章来源:https://blog.csdn.net/m0_62581697/article/details/135314926
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- nuxt3 路由相关
- 机器学习-PCA降维【手撕】
- 低成本高回报:如何利用免版素材库提升设计品质?
- 并网逆变器学习笔记7---下垂控制MATLAB仿真
- Vue中keep-alive缓存的详解(深度理解)
- C++多态(万字详!!!)
- MX6ULL学习笔记(十三)Linux 自带按键驱动程序
- 【C++】初步认识基于C的优化
- 解决ImportError: Failed to import test module: sys.__init__
- 【数据结构】C语言实现链式二叉树(附完整运行代码)