geopandas 笔记:plot 的scheme
发布时间:2024年01月15日
transbigdata 笔记:官方文档案例1(出租车GPS数据处理)-CSDN博客? 3.3.1 节的内容的拓展,这里主要是比较各个scheme的效果
主代码为:修改的就是第二行scheme的内容
plt.figure(1,(16, 6), dpi=300)
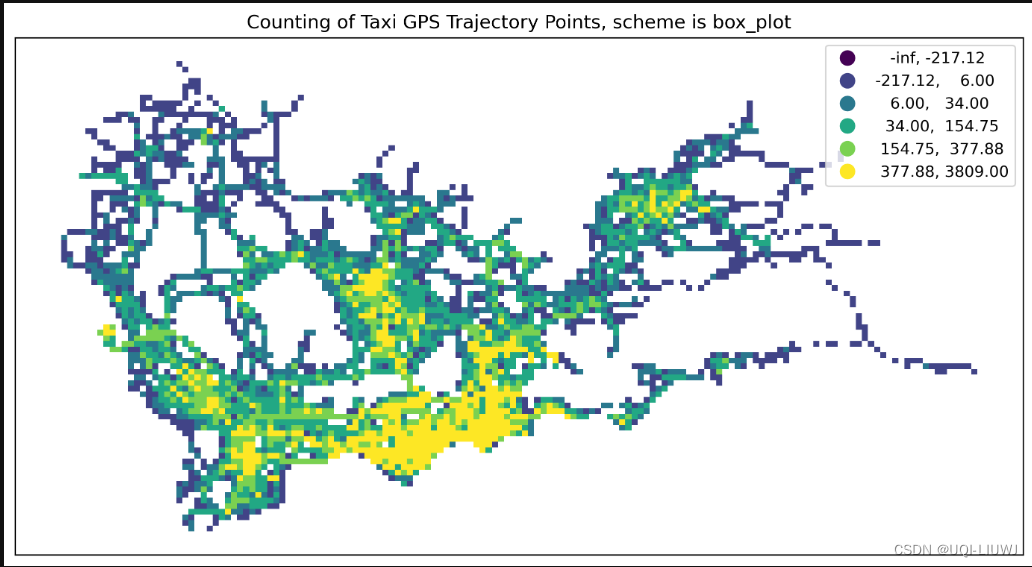
scheme='box_plot'
#图的大小和size
ax1 = plt.subplot(111)
#在图形中创建了一个子图。111 表示图形布局是1行1列,且这是第1个子图。
datatest.plot(ax=ax1,column='VehicleNum',legend=True, scheme=scheme)
'''
在子图ax1上绘制数据。
column='VehicleNum' 指定了要绘制的数据列。
legend=True 表示在图表中包含图例。
scheme指定数据分类方案
'''
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
#设置x轴和y轴的刻度(为空)
plt.title('Counting of Taxi GPS Trajectory Points, scheme is '+scheme, fontsize=12);
#设置标题- ?
scheme参数在地理数据可视化中用来指定数据分类方案。这在绘制地图时特别有用,因为它可以帮助更好地展示数据的分布和模式。 - 在
geopandas的plot方法中使用scheme参数时,它决定了如何将数据分成不同的类别,以便于通过颜色或其他方式区分。
box_plot | 基于箱形图的分类方法,使用四分位数和异常值来定义类别
|
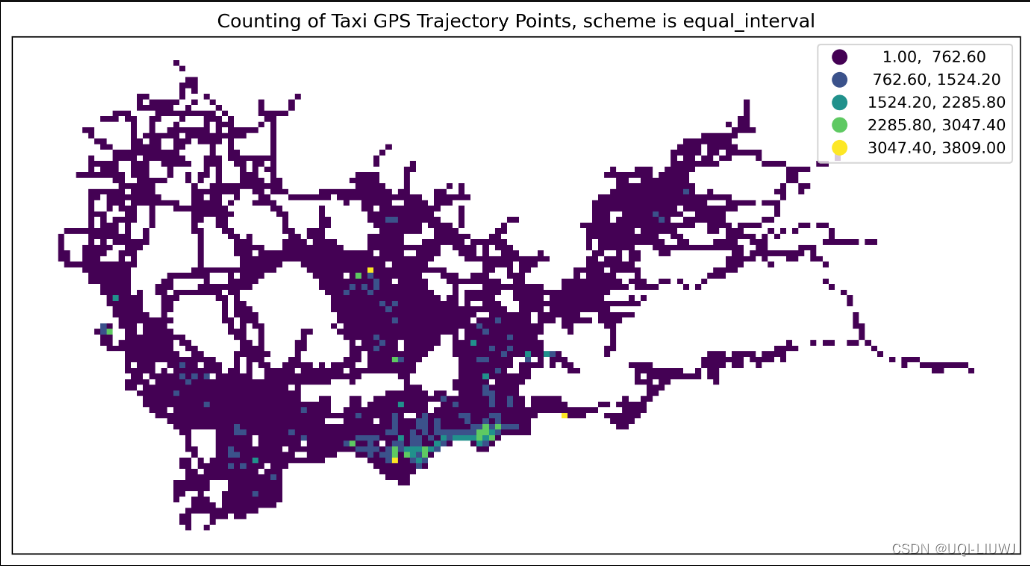
equal_interval | 将数据范围平均分成指定数量的间隔
|
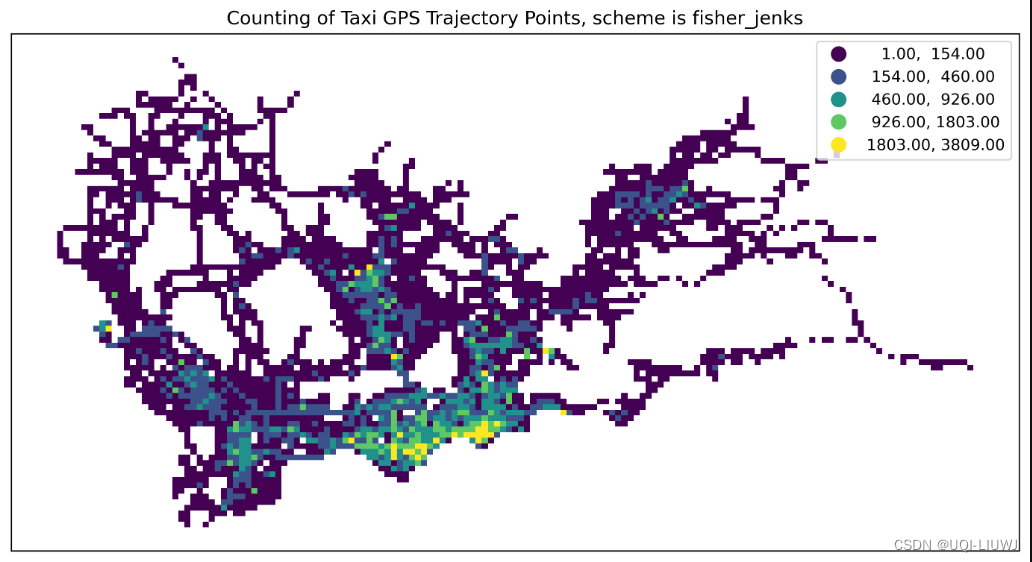
fisher_jenks | 一种优化算法,旨在减小类内方差并最大化类间方差
|
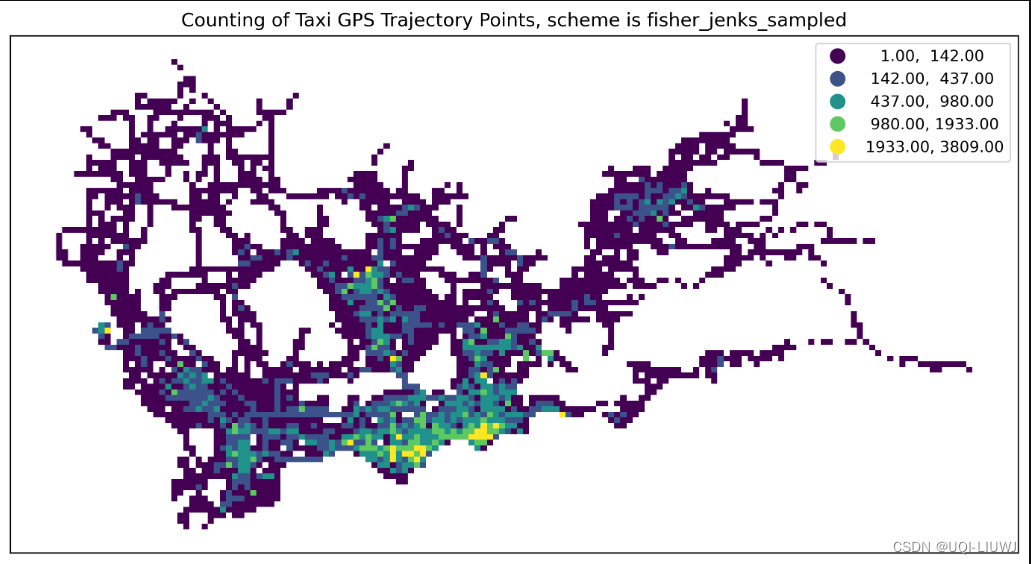
fisher_jenks_sampled | Fisher Jenks 算法的采样版本,适用于大数据集
|
headtail_breaks | 一种用于具有重尾分布的数据的分类方法,反复将数据分成头部(高频)和尾部(低频)两部分
|
jenks_caspall | 一种基于自然间断的分类方法
|
maximum_breaks | 选择最大化类间差异的间断点
|
quantiles | 数据被平均分配到指定数量的类别中,每个类别包含相等数量的观测值
|
percentiles | 类似于分位数,但允许更具体的百分位数设定
|
std_mean | 基于平均值和标准差的分类方法
|
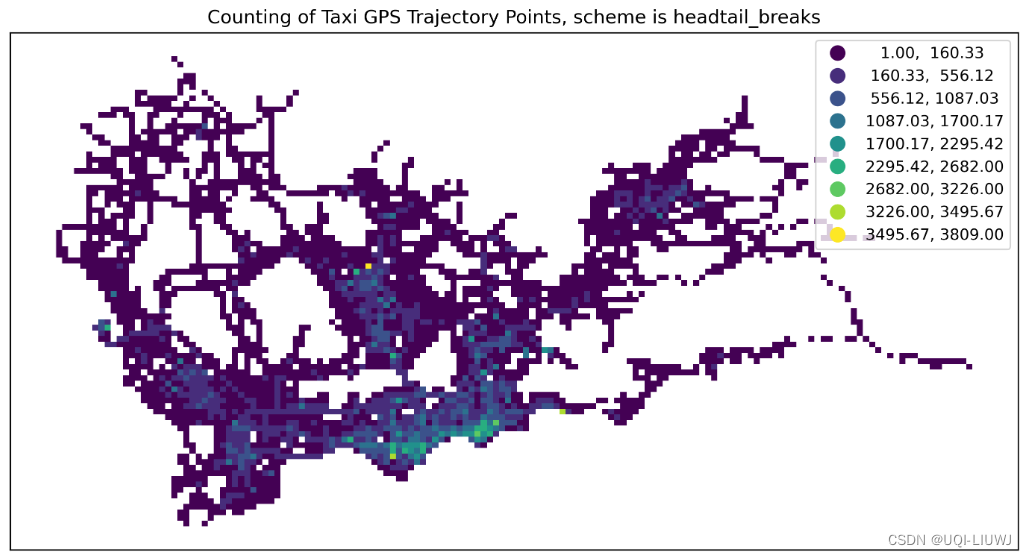
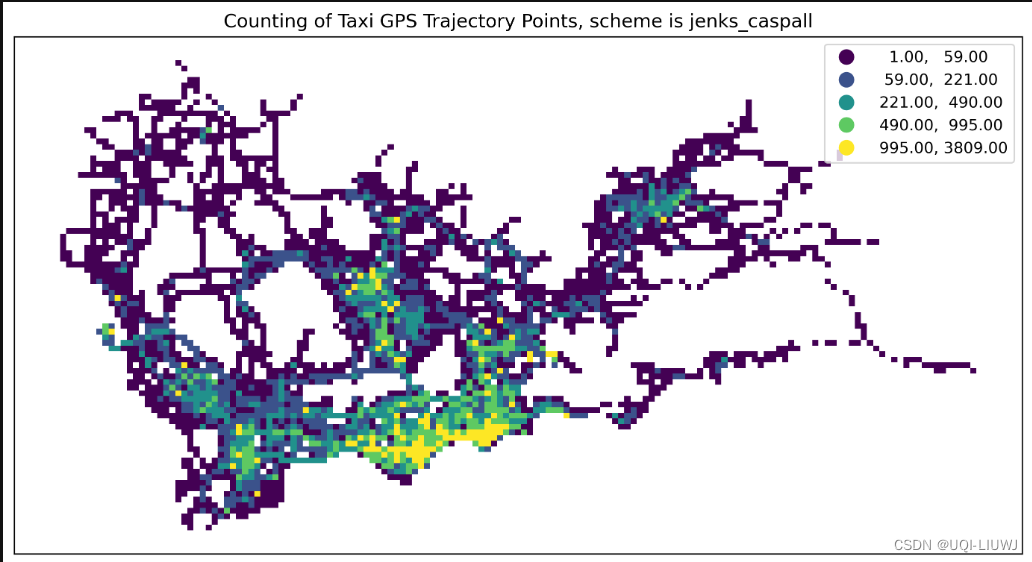
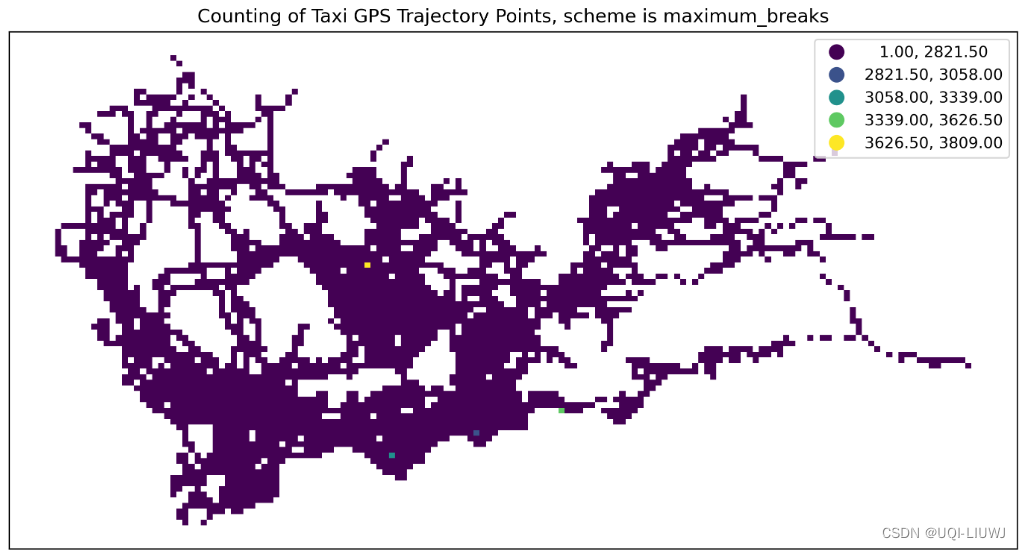
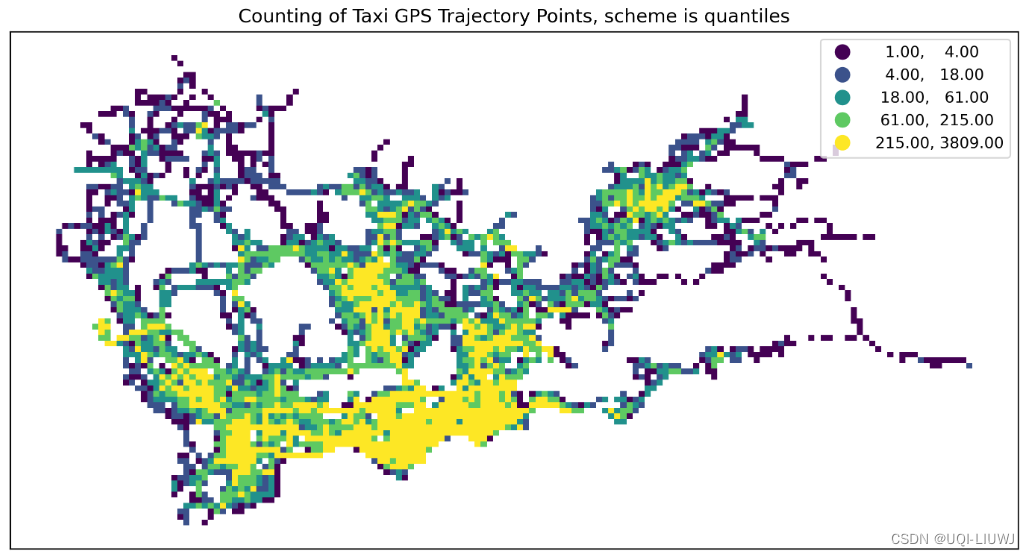
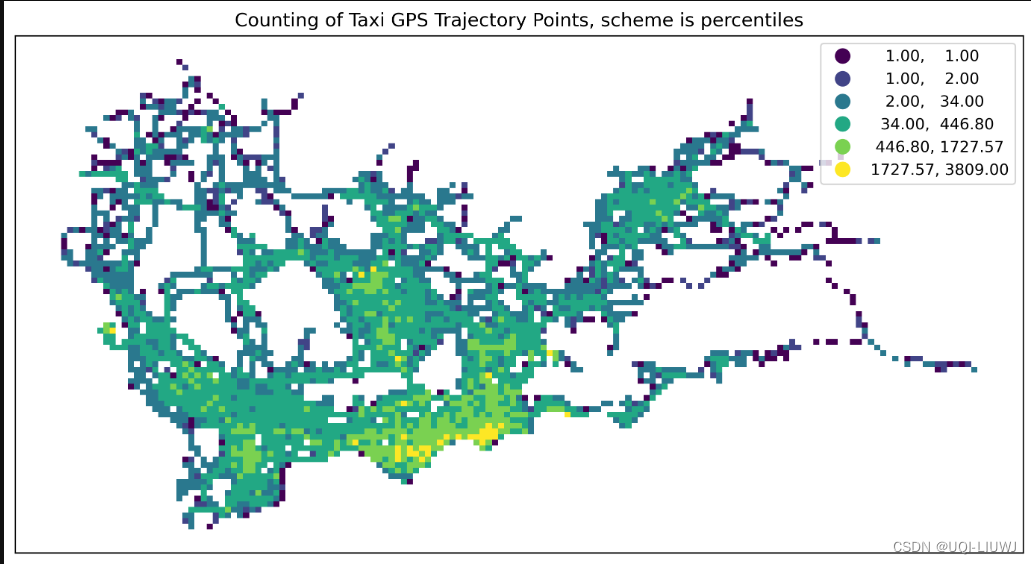
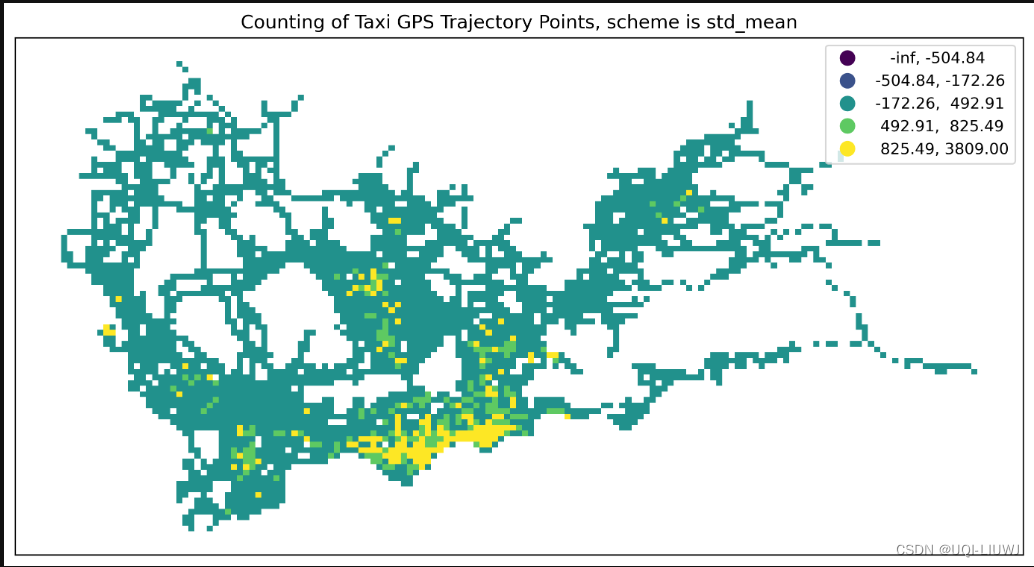
文章来源:https://blog.csdn.net/qq_40206371/article/details/135603497
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【从浅到深的算法技巧】实例方法,对象
- 图论:最短路(dijkstra算法、bellman算法、spfa算法、floyd算法)详细版
- 中国电子学会2022年12月份青少年软件编程Scratch图形化等级考试试卷一级真题(含答案)
- pytorch中nn.Sequential详解
- 【MySQL】数据库之Redis的持久化
- 产品经理学习-产品运营《用户运营策略》
- zblog主题模板:zblog主题自适应wordpress设计工作室公司模板
- M-G370PDF1(IMU)
- MySQL的安装和部署
- 文件内容搜索利器 - grep