Large Language Models Paper 分享
发布时间:2024年01月03日
论文1:?ChatGPT's One-year Anniversary: Are Open-Source Large Language Models Catching up?
简介
2022年11月,OpenAI发布了ChatGPT,这一事件在AI社区甚至全世界引起了轰动。首次,一个基于应用的AI聊天机器人能够提供有帮助、安全和有用的答案,遵循人类指令,甚至承认并纠正之前的错误。作为第一个这样的应用,ChatGPT在其推出仅两个月内,用户数量就达到了1亿,远远快于其他流行应用如TikTok或YouTube。因此,它也吸引了巨额的商业投资,因为它有望降低劳动成本,自动化工作流程,甚至为客户带来新的体验。
但ChatGPT的闭源特性可能引发诸多问题。首先,由于不了解内部细节,比如预训练和微调过程,很难正确评估其潜在风险,尤其是考虑到大模型可能生成有害、不道德和虚假的内容。其次,有报道称ChatGPT的性能随时间变化,妨碍了可重复的结果。第三,ChatGPT经历了多次故障,仅在2023年11月就发生了两次重大故障,期间无法访问ChatGPT网站及其API。最后,采用ChatGPT的企业可能会关注API调用的高成本、服务中断、数据所有权和隐私问题,以及其他不可预测的事件,比如最近有关CEO Sam Altman被解雇并最终回归的董事会闹剧。
此时,开源大模型应运而生,社区一直在积极推动将高性能的大模型保持开源。然而,截至2023年末,大家还普遍认为类似Llama-2或Falcon这样的开源大模型在性能上落后于它们的闭源模型,如OpenAI的GPT3.5(ChatGPT)和GPT-4,Anthropic的Claude2或Google的Bard3,其中GPT-4通常被认为是最出色的。然而,令人鼓舞的是差距正在变得越来越小,开源大模型正在迅速赶上。
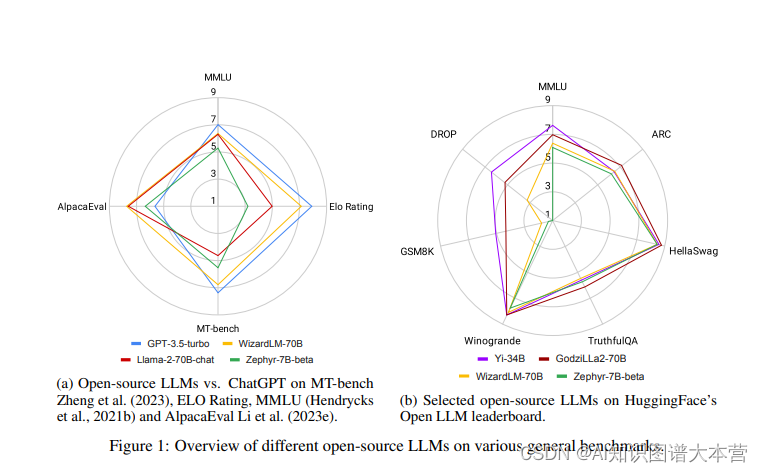
文章来源:https://blog.csdn.net/weixin_43564920/article/details/135371266
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 内部风险解密:企业反间谍策略,如何全面封堵内部泄密漏洞?
- opencv006图像处理之仿射变换(旋转,缩放,平移)
- Hazelcast系列(十一):Map(三)备份、过期驱逐与内存格式
- cocos2d-x之lua核心编程电子版-(无偿赠送,只供学习,禁止以此出售)
- 程序员会被人工智能取代吗?努力学习代码还有意义吗?
- 每日一题——LeetCode977
- 【ArcGIS Pro微课1000例】0056:度分秒与十进制度互相转换(度分秒→度、度→度分秒)
- Vue2 - v-model 简介
- Nginx的location和rewrite的使用
- Android WorkManager入门(一)