Pandas模块部分内容详解
简要概述
Pandas是一个开源的,BSD许可的库,为Python (opens new window)编程语言提供高性能,易于使用的数据结构和数据分析工具。
Pandas 就像一把万能瑞士军刀,下面仅列出了它的部分优势 :
-
处理浮点与非浮点数据里的缺失数据,表示为
NaN; -
大小可变:插入或删除 DataFrame 等多维对象的列;
-
自动、显式数据对齐:显式地将对象与一组标签对齐,也可以忽略标签,在 Series、DataFrame 计算时自动与数据对齐;
-
强大、灵活的分组(group by)功能:拆分-应用-组合数据集,聚合、转换数据;
-
把 Python 和 NumPy 数据结构里不规则、不同索引的数据轻松地转换为 DataFrame 对象;
-
基于智能标签,对大型数据集进行切片、花式索引、子集分解等操作;
-
直观地合并(merge)、连接(join)数据集;
-
灵活地重塑(reshape)、透视(pivot)数据集;
-
轴支持结构化标签:一个刻度支持多个标签;
-
成熟的 IO 工具:读取文本文件(CSV 等支持分隔符的文件)、Excel 文件、数据库等来源的数据,利用超快的 HDF5 格式保存 / 加载数据;
-
时间序列:支持日期范围生成、频率转换、移动窗口统计、移动窗口线性回归、日期位移等时间序列功能。
Pandas内置数据结构
一、pandas数据结构之 Series
pandas在 ndarray 数组(NumPy 中的数组)的基础上构建出了两种不同的数据结构,分别是 Series(一维数据结构)DataFrame(二维数据结构)
Series 是带标签的一维数组,这里的标签可以理解为索引,但这个索引并不局限于整数,它也可以是字符类型,比如 a、b、c 等;
Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。

1.创建Series数据对象
Pandas 使用 Series() 函数来创建 Series 对象,通过这个对象可以调用相应的方法和属性,从而达到处理数据的目的.
import pandas as pd s=pd.Series( data, index, dtype, copy)
1.1创建一个空的Series对象
import pandas as pd
#输出数据为空
s = pd.Series([], dtype='float64')
print(s)1.2 使用矩阵ndarray创建Series对象
ndarray 是 NumPy 中的数组类型,当 data 是 ndarry 时,传递的索引必须具有与数组相同的长度。假如没有给 index 参数传参,在默认情况下,索引值将使用是 range(n) 生成,其中 n 代表数组长度。
没有传递任何索引,所以索引默认从 0 开始分配 ,其索引范围为 0 到len(data)-1,即 0 到 3。这种设置方式被称为“隐式索引”
import pandas as pd
import numpy as np
data = np.array(['a', 'b', 'c', 'd'])
s = pd.Series(data)
print(s)
?结果:? ? 0 ? ?a
? ? ? ? ? ? ? ? 1 ? ?b
? ? ? ? ? ? ? ? 2 ? ?c
? ? ? ? ? ? ? ? 3 ? ?d
? ? ? ? ? ? ? ? dtype: object
显示索引:自定义索引标签
import pandas as pd
import numpy as np
data = np.array(['a', 'b', 'c', 'd'])
s = pd.Series(data, index=[1001, 1002, 1003, 1004])
print(s)结果:?
1001 ? ?a
1002 ? ?b
1003 ? ?c
1004 ? ?d
dtype: object
1.3 python字典dict创建Series对象
case1:没有传递索引时
import pandas as pd
import numpy as np
dict1 = {'1号': '鸡哥', '二号': '小凡', '三号': '小王', '四号': '小裤'}
s = pd.Series(dict1)
print(s)结果:
1号 ? ?鸡哥
二号 ? ?小凡
三号 ? ?小王
四号 ? ?小裤
dtype: object
case2:用index参数传递索引时
import pandas as pd
import numpy as np
# 取索引
dict1 = {'1号': '鸡哥', '二号': '小凡', '三号': '小王', '四号': '小裤'}
# 如果一开始有索引,index的作用是取对应的索引,如果索引没有的话,值对应NaN
s = pd.Series(dict1, index=['二号', '四号', '五号'])
print(s,type(s))结果:
二号 ? ? 小凡
四号 ? ? 小裤
五号 ? ?NaN
dtype: object <class 'pandas.core.series.Series'>
小总结:
-
如果一开始没有索引,index的作用是加索引,如果超出值的个数,报错
-
如果一开始有索引,index的作用是取对应的索引,如果索引没有的话,值对应NaN
1.4 标量固定值创建
? ? ? 注意:如果是标量,如果没给索引值,就只有一个
import pandas as pd
import numpy as np
s = pd.Series(20, index=[1001,1002,1003,1004])
print(s,type(s))
结果:
1001 ? ?20
1002 ? ?20
1003 ? ?20
1004 ? ?20
dtype: int64 <class 'pandas.core.series.Series'>
2、Series数据的使用
2.1 位置索引访问
import pandas as pd
s = pd.Series([1, 2, 3, 4], index=['1001', '1002', '1003', '1004'])
print(s[2])结果:3
2.1.1通过切片的方式访问 Series 序列中的数据
import pandas as pd
s = pd.Series([1, 2, 3, 4], index=['1001', '1002', '1003', '1004'])
print(s[1:3])结果:
1002 ? ?2
1003 ? ?3
dtype: int64
2.1.2获取最后三个元素
import pandas as pd
s = pd.Series([1, 2, 3, 4], index=['1001', '1002', '1003', '1004'])
print(s[-3:])结果:
1002 ? ?2
1003 ? ?3
1004 ? ?4
dtype: int64
2.2 索引标签访问(常用)
Series 类似于固定大小的 dict,把 index 中的索引标签当做 key,而把 Series 序列中的元素值当做 value,然后通过 index 索引标签来访问或者修改元素值。
2.2.1使用索引标签访问单个元素值,如果不存在会报错
import pandas as pd
s = pd.Series([1, 2, 3, 4], index=['1001', '1002', '1003', '1004'])
print(s['1001'])结果:1
2.2.2使用索引标签访问多个元素值
注意访问多个值时索引要放在“列表“”中,否则会报错
import pandas as pd
s = pd.Series([1, 2, 3, 4], index=['1001', '1002', '1003', '1004'])
print(s[['1001', '1003', '1002']])结果:
1001 ? ?1
1003 ? ?3
1002 ? ?2
dtype: int64
3、Series常用属性
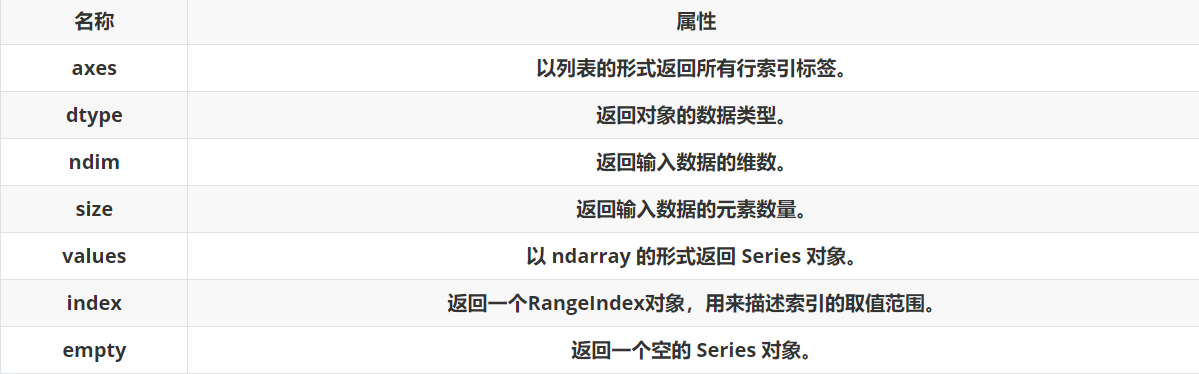
?3.1随机创建一个Series数据
import pandas as pd
import numpy as np
array1 = np.array([11, 22, 33, 44, 55])
pd1 = pd.Series(array1, index=[1001, 1002, 1003, 1004,1005])
print(pd1, type(pd1))
结果:
1001 ? ?11
1002 ? ?22
1003 ? ?33
1004 ? ?44
1005 ? ?55
dtype: int32 <class 'pandas.core.series.Series'>
3.2? axes
import pandas as pd
import numpy as np
array1 = np.array([11,22,33,44,55])
s = pd.Series(array1,index=[1001,1002,1003,1004,1005])
print(f'所有行索引的标签为{s.axes}')结果:所有行索引的标签为[Int64Index([1001, 1002, 1003, 1004, 1005], dtype='int64')]
3.2? dtype
import pandas as pd
import numpy as np
array1 = np.array([11,22,33,44,55])
s = pd.Series(array1,index=[1001,1002,1003,1004,1005])
print(f'数据类型为{s.dtype}')
结果:数据类型为int32
3.3? empty
返回一个布尔值,用于判断数据对象是否为空
import pandas as pd
import numpy as np
array1 = np.array([1])
s = pd.Series(array1)
print(s.empty)结果:False
3.4? ndim
查看序列的维数。因为Series 是一维数据结构,因此它始终返回 1。
import pandas as pd
import numpy as np
array1 = np.array([11, 22, 33, 44, 55])
s = pd.Series(array1, index=[1001, 1002, 1003, 1004, 1005])
print(s.ndim)结果:1
3.5? size
import pandas as pd
import numpy as np
array1 = np.array([11, 22, 33, 44, 55])
s = pd.Series(array1, index=[1001, 1002, 1003, 1004, 1005])
print(s.size)结果:5
3.6??values
import pandas as pd
import numpy as np
array2 = np.array([11, 22, 33, 44, 55])
s = pd.Series(array2, index=[1001, 1002, 1003, 1004, 1005])
print(s.values)结果:[11 22 33 44 55]
3.7? ?index
import pandas as pd
# 显式索引
s1 = pd.Series([11, 22, 33, 44, 55], index=[1001, 1002, 1003, 1004, 1005])
print(s1.index)
# 隐式索引
s2 = pd.Series([11, 22, 33, 44, 55])
print(s2.index)
结果:Int64Index([1001, 1002, 1003, 1004, 1005], dtype='int64')
? ? ? ? ? ?RangeIndex(start=0, stop=5, step=1)
4、Series常用函数
4.1head()? ? ? ?
如果不给值默认显示前五条数据
import pandas as pd
s1 = pd.Series([11, 22, 33, 44, 55], index=[1001, 1002, 1003, 1004, 1005])
print(s1.head(3))结果:
1001 ? ?11
1002 ? ?22
1003 ? ?33
dtype: int64
4.2tail()? ? ? ?
如果不给值默认显示后五条数据
import pandas as pd
s1 = pd.Series([11, 22, 33, 44, 55, 66], index=[1001, 1002, 1003, 1004, 1005, 1006])
print(s1.tail(2))结果:
1005 ? ?55
1006 ? ?66
dtype: int64
4.3isnull() 和notnull()
-
isnull():如果为值不存在或者缺失,则返回 True。
-
notnull():如果值不存在或者缺失,则返回 False。
import pandas as pd
s1 = pd.Series([11, None, None, 44])
print(pd.isnull(s1))结果:
0 ? ?False
1 ? ? True
2 ? ? True
3 ? ?False
dtype: bool
二、pandas数据结构之DataFrame
DataFrame 一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。
1.列表创建DataFame对象
1.1使用单一列表列表来创建一个 DataFrame
import pandas as pd
data = [1,2,3]
df = pd.DataFrame(data)
print(df)结果:?
? ? 0
0 ?1
1 ?2
2 ?3
1.2使用嵌套列表创建 DataFrame
import pandas as pd
data = [[1, 2, 3, 4], [5, 6, 7, 8]]
df = pd.DataFrame(data)
print(df)
print(type(df))结果:? ? 0 ?1 ?2 ?3
0 ?1 ?2 ?3 ?4
1 ?5 ?6 ?7 ?8
<class 'pandas.core.frame.DataFrame'>
1.3指定数值元素的数据类型为 float
import pandas as pd
data = [['鸡哥', 17, '篮球'], ['小凡', 18, '踩缝纫机']]
df = pd.DataFrame(data, columns=['Name', 'age', 'Habby'], dtype=float)
print(df)结果:
? Name ? age Habby
0 ? 鸡哥 ?17.0 ? ?篮球
1 ? 小凡 ?18.0 ?踩缝纫机
1.4字典嵌套列表创建,并加自定义的行标签
data 字典中,键对应的值的元素长度必须相同(也就是列表长度相同)。如果传递了索引,那么索引的长度应该等于数组的长度;如果没有传递索引,那么默认情况下,索引将是 range(n),其中 n 代表数组长度.
import pandas as pd
dict1 = {'name': ['鸡哥', '孙晓川', '山上'], 'habby': ['篮球', '土', '男枪']}
df = pd.DataFrame(dict1,index=[1001,1002,1003])
print(df)
结果:
? ? ? ? ? ?name habby
1001 ? 鸡哥 ? ?篮球
1002 ?孙晓川 ? ? 土
1003 ? 山上 ? ?男枪
1.5列表嵌套字典创建DataFrame对象
列表嵌套字典可以作为输入数据传递给 DataFrame 构造函数。默认情况下,字典的键被用作列名.
注意: 如果其中某个元素值缺失,也就是字典的 key 无法找到对应的 value,将使用 NaN 代替。
import pandas as pd
data = [{'a':2,'b':3},{'a':5,'b':7,'c':9}]
df = pd.DataFrame(data)
print(df)
结果:
? ??a ?b ? ?c
0 ?2 ?3 ?NaN
1 ?5 ?7 ?9.0
1.6使用字典嵌套列表以及行、列索引表创建一个 DataFrame 对象
import pandas as pd
data = [{'a': 2, 'b': 3}, {'a': 5, 'b': 7, 'c': 9}]
df1 = pd.DataFrame(data, index=[1001, 1002], columns=['a', 'b'])
df2 = pd.DataFrame(data, index=[1001, 1002], columns=['a1', 'b']) # b1 在字典键中不存在,所以对应值为 NaN
print(df1)
print(df2)
结果:?
? ? ? ? ? a ?b
1001 ?2 ?3
1002 ?5 ?7
? ? ? ? ? ? a1 ?b
1001 NaN ?3
1002 NaN ?7
1.7Series创建DataFrame对象
import pandas as pd
data = {'one': pd.Series([1, 2, 3], index=[1001, 1002, 1003]),
'two': pd.Series([1, 2, 3, 4], index=[1001, 1002, 1003, 1004])}
df = pd.DataFrame(data)
print(df)
结果:
? ? ? ? ? one ?two
1001 ?1.0 ? ?1
1002 ?2.0 ? ?2
1003 ?3.0 ? ?3
1004 ?NaN ? ?4
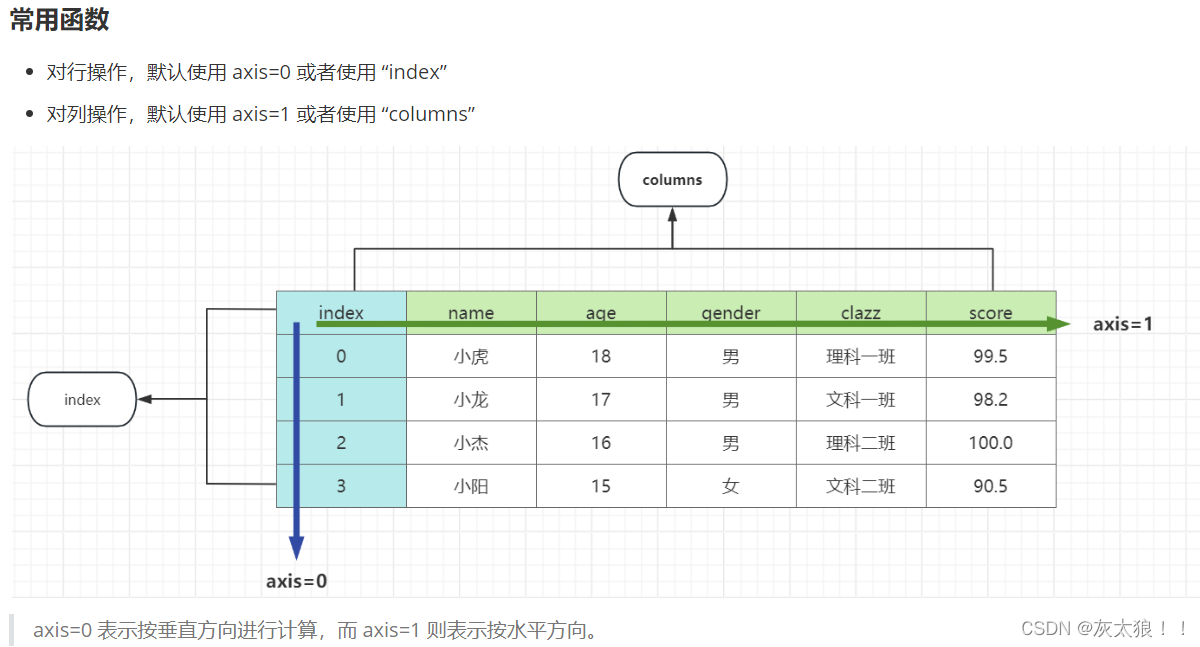
2.DataFrame使用与操作
DataFrame 可以使用列索(columns index)引来完成数据的选取、添加和删除操作
2.1列索引选取,添加数据列
import pandas as pd
data = {'name': pd.Series(['鸡哥', '小王', '小裤'], index=[1001, 1002, 1003]),
'one': pd.Series([1, 2, 3, 4], index=[1001, 1002, 1003, 1004])}
df = pd.DataFrame(data)
print(df['name']) # 列索引选取数据列
df['two'] = pd.Series([5, 6, 7, 8], index=[1001, 1002, 1003, 1004]) # 列索添加数据列
print(df)
# 将已经存在的数据列做相加运算
df['three'] = df['one'] + df['two'] # 若存在NAN值,NaN与任意一个值相加,结果依旧是NaN
print(df)结果:
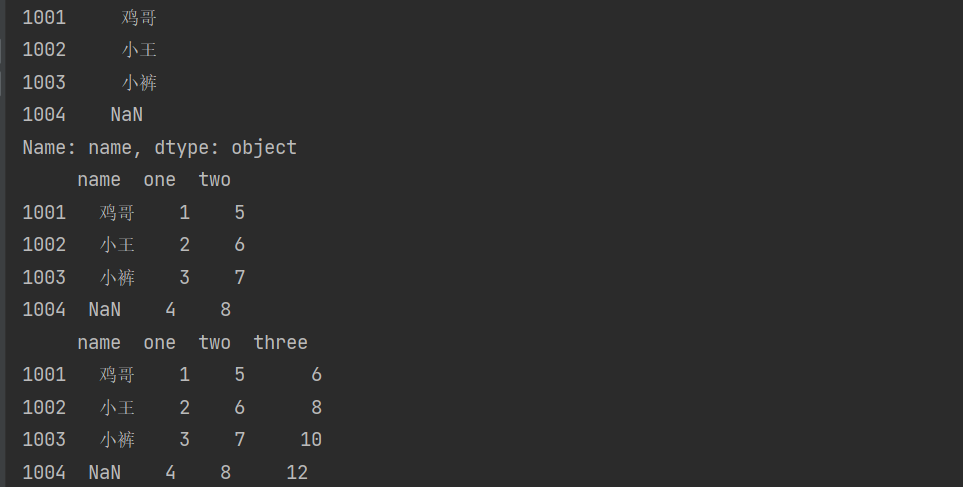
2.2使用 insert() 方法插入新的列
import pandas as pd
data = [['鸡哥', '18'], ['小裤', '17'], ['小王', '19']]
df = pd.DataFrame(data, columns=['name', 'age'])
df.insert(1, column='habby', value=['篮球', '唱', '跳']) #数值1代表插入到columns列表的索引位置
print(df)?结果:
? name habby age
0 ? 鸡哥 ? ?篮球 ?18
1 ? 小裤 ? ? 唱 ?17
2 ? 小王 ? ? 跳 ?19
2.3列索引删除数据列
del 和 pop() 都能够删除 DataFrame 中的数剧,在此使用上述2.1的结果测试
import pandas as pd
data = {'name': pd.Series(['鸡哥', '小王', '小裤'], index=[1001, 1002, 1003]),
'one': pd.Series([1, 2, 3, 4], index=[1001, 1002, 1003, 1004])}
df = pd.DataFrame(data)
df['two'] = pd.Series([5, 6, 7, 8], index=[1001, 1002, 1003, 1004])
df['three'] = df['one'] + df['two']
del df['one']
print(df)
print('*' * 40)
ret = df.pop('two') # 将删除的列封装成Series对象进行返回
print(ret)
print('*' * 40)
print(df)结果:? 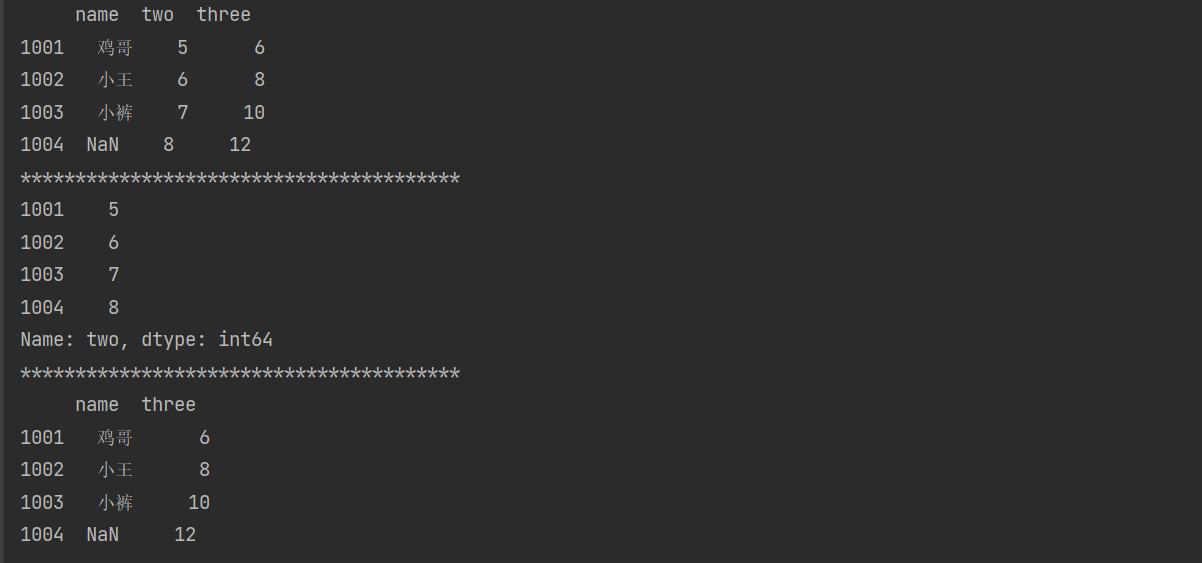 ? ? ? ? ? ? ??
? ? ? ? ? ? ??
行索引操作DataFrame
2.4标签索引选取,可以将行标签传递给 loc 函数?,返回的类型为.Series
?
import pandas as pd
d = {'one': pd.Series([11, 21, 31], index=['1001', '1002', '1003']),
'two': pd.Series([11, 21, 31, 41], index=['1001', '1002', '1003', '1004'])}
df = pd.DataFrame(d)
print(df.loc['1002'])
??结果:
one ? ?21.0
two ? ?21.0
Name: 1002, dtype: float64 <class 'pandas.core.series.Series'>
2.5整数索引选取,通过将数据行所在的索引位置传递给 iloc 函数,也可以实现数据行选取
import pandas as pd
d = {'one': pd.Series([11, 21, 31], index=['1001', '1002', '1003']),
'two': pd.Series([11, 21, 31, 41], index=['1001', '1002', '1003', '1004'])}
df = pd.DataFrame(d)
print(df.iloc[1])结果:
one ? ?21.0
two ? ?21.0
Name: 1002, dtype: float64
2.6切片操作多行选取
import pandas as pd
d = {'one': pd.Series([11, 21, 31], index=['1001', '1002', '1003']),
'two': pd.Series([11, 21, 31, 41], index=['1001', '1002', '1003', '1004'])}
df = pd.DataFrame(d)
print(df[1:3])结果:
? ? ? one ?two
1002 ?21.0 ? 21
1003 ?31.0 ? 31
2.7添加数据行
import pandas as pd
df1 = pd.DataFrame([[11, 22], [33, 44]], columns=['A', 'B'])
df2 = pd.DataFrame([[55, 66], [77, 88]], columns=['A', 'B'])
df = df1.append(df2)
print(df)结果:
? ? A ? B
0 ?11 ?22
1 ?33 ?44
0 ?55 ?66
1 ?77 ?88
2.8删除数据行,如果索引标签存在重复,那么它们将被一起删除
import pandas as pd
df1 = pd.DataFrame([[11, 22], [33, 44]], columns=['A', 'B'])
df2 = pd.DataFrame([[55, 66], [77, 88]], columns=['A', 'B'])
df = df1.append(df2)
df1 = df.drop(0) # 根据索引值删除
print(df1)结果:
? ? A ? B
1 ?33 ?44
1 ?77 ?88
3.常用属性和方法汇总
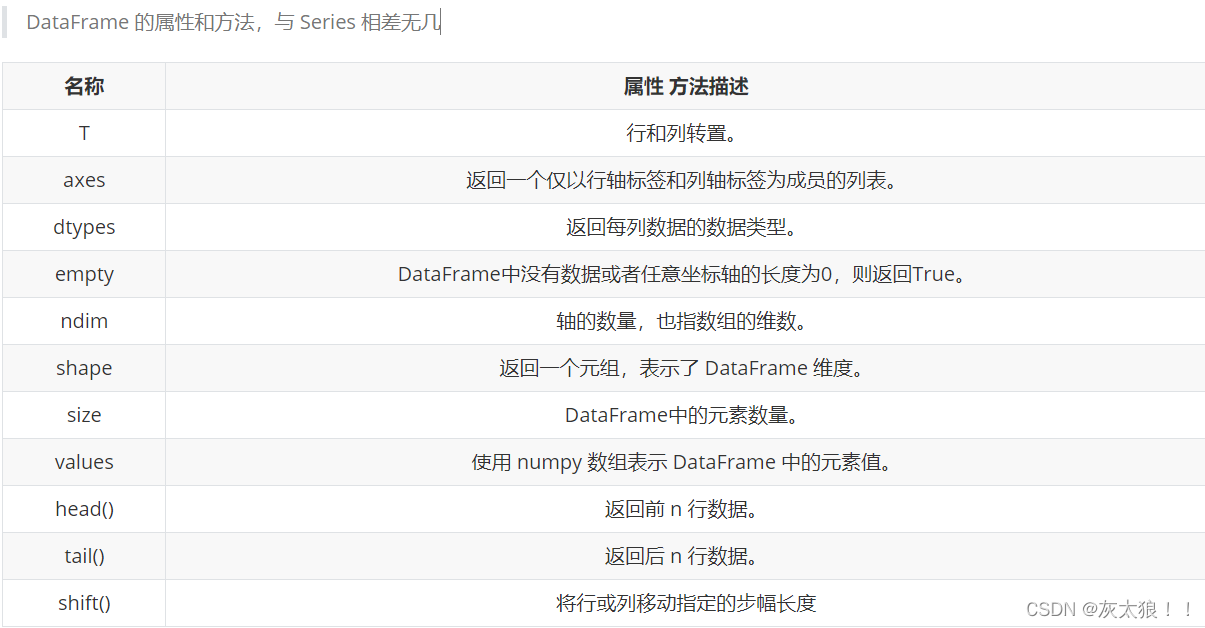
由于在一维结构中已经展示大多数方法,在此不在赘述,下面展示一维中没有的两个方法:
3.1? T
import pandas as pd
import numpy as np
d = {'Name':pd.Series(['python编程大全','hadoop基础',"hive进阶",'spark基础','flink进阶','mysql从入门到成神','java之路']),
'years':pd.Series([5,6,15,28,3,19,23]),
'Rating': pd.Series([4.23, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8])}
#构建DataFrame
df = pd.DataFrame(d)
#输出series
print(df.T)结果:

?3.2?shift()移动行或列
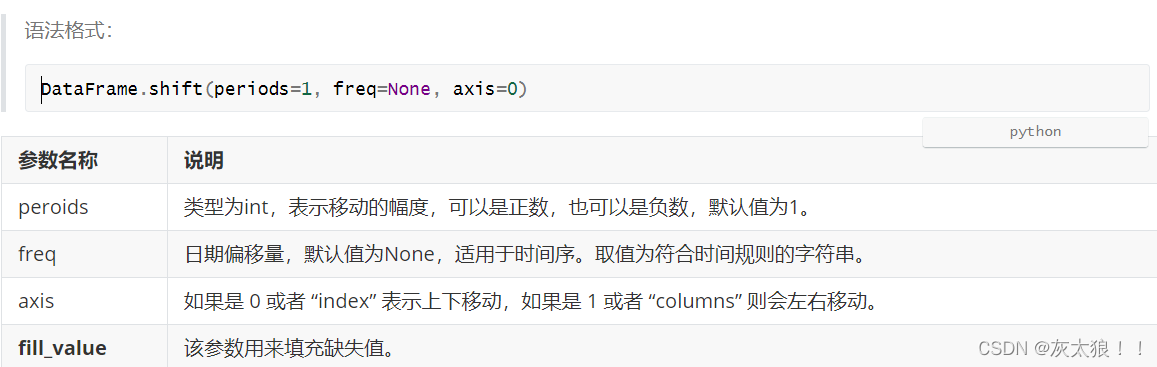
3.2.1? peroids和axis
import pandas as pd
import numpy as np
data = {'Name': pd.Series(
['python编程大全', 'hadoop基础', "hive进阶", 'spark基础', 'flink进阶', 'mysql从入门到成神', 'java之路']),
'years': pd.Series([5, 6, 15, 28, 3, 19, 23]),
'Rating': pd.Series([4.23, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8])}
# 构建DataFrame
df = pd.DataFrame(data)
df = df.shift(periods=2, axis=0)
print(df)结果:

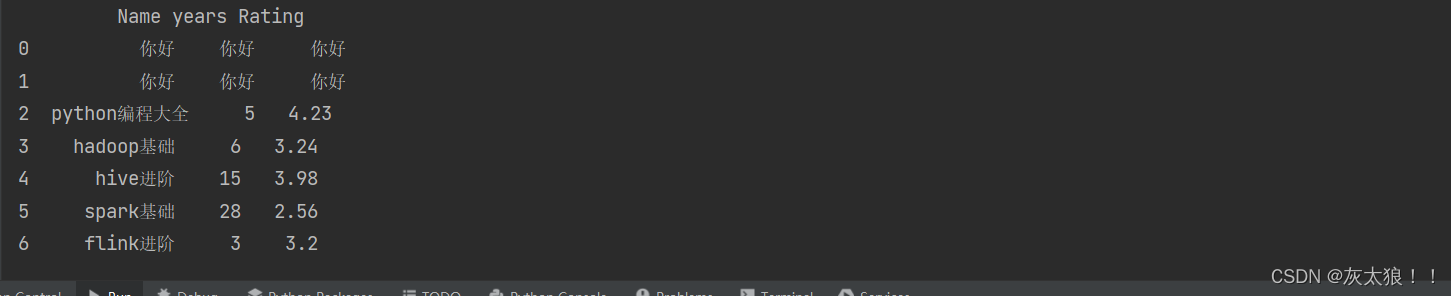
3.2.2???fill_value 参数填充 DataFrame 中的缺失值
data = {'Name': pd.Series(
['python编程大全', 'hadoop基础', "hive进阶", 'spark基础', 'flink进阶', 'mysql从入门到成神', 'java之路']),
'years': pd.Series([5, 6, 15, 28, 3, 19, 23]),
'Rating': pd.Series([4.23, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8])}
# 构建DataFrame
df = pd.DataFrame(data)
df = df.shift(periods=2, axis=0, fill_value='你好')
print(df)结果:
三、Pandas数学分析(描述性统计)

?3.1sum()求和
? ?在默认情况下,返回 axis=0 的所有值的和
import pandas as pd
import numpy as np
data = {'name': pd.Series(['鸡哥', '小王', '小凡', '小裤']),
'math': pd.Series([61, 62, 63, 64]),
'english': pd.Series([71, 72, 73, 74])
}
df = pd.DataFrame(data)
print(df.sum(axis=1))?结果:

3.2mean()求均值
在默认情况下,返回 axis=0 的平均值
import pandas as pd
import numpy as np
data = {'name': pd.Series(['鸡哥', '小王', '小凡', '小裤']),
'math': pd.Series([61, 62, 63, 64]),
'english': pd.Series([71, 72, 73, 74])
}
df = pd.DataFrame(data)
print(df.mean(axis=1))结果:

?3.3std()求标准差
import pandas as pd
import numpy as np
data = {'name': pd.Series(['鸡哥', '小王', '小凡', '小裤']),
'math': pd.Series([61, 62, 63, 64]),
'english': pd.Series([71, 72, 73, 74])
}
df = pd.DataFrame(data)
print(df.std(axis=1))
?结果:

3.4describe() 函数显示与 DataFrame 数据列相关的统计信息摘要
import pandas as pd
import numpy as np
data = {'name': pd.Series(['鸡哥', '小王', '小凡', '小裤']),
'math': pd.Series([61, 62, 63, 64]),
'english': pd.Series([71, 72, 73, 74])
}
df = pd.DataFrame(data)
print(df.describe())
?结果:

四、Pandas csv读写文件
1read_csv()读文件
1.1分隔符

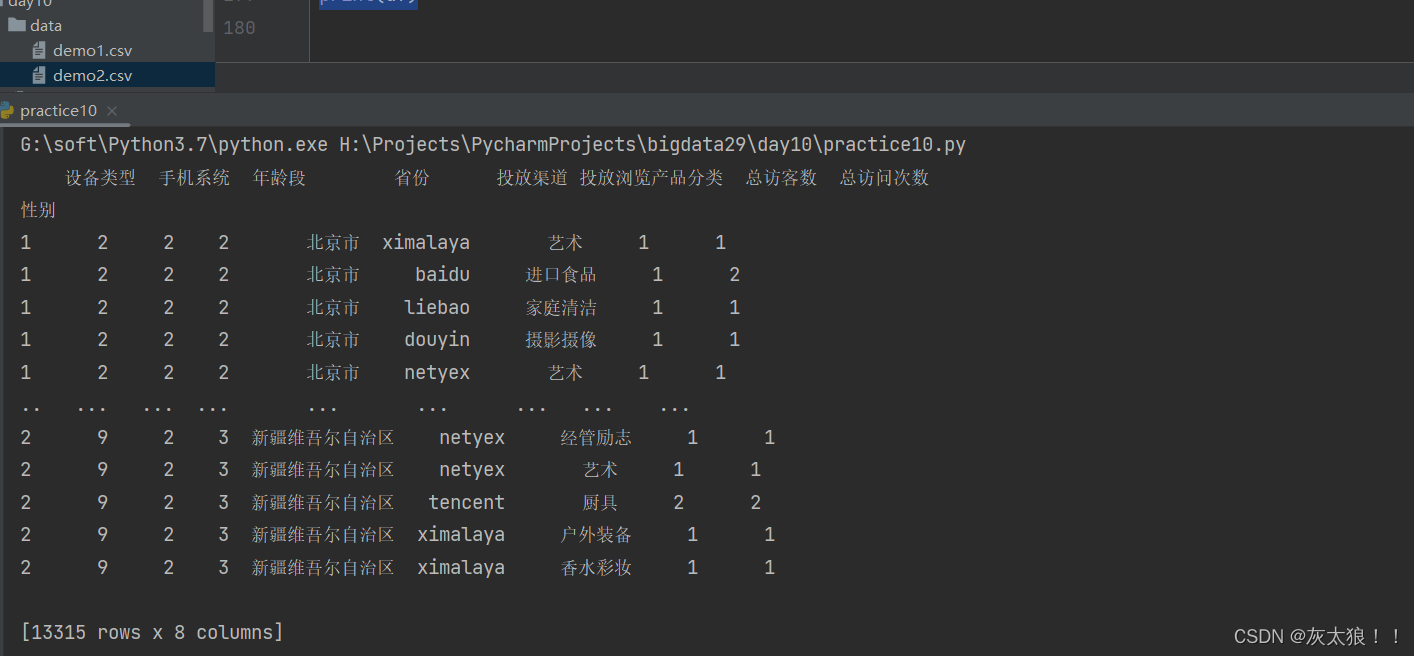
1.2index_col,这个参数是用来决定读进来的数据哪一列做索引的
import pandas as pd
df = pd.read_csv('H:\Projects\PycharmProjects\\bigdata29\day10\data\demo1.csv', encoding='gbk', index_col=2)
print(df)结果:
? ?
?1.3usecols,这个参数可以指定你从文件中读取哪几列
import pandas as pd
df = pd.read_csv('H:\Projects\PycharmProjects\\bigdata29\day10\data\demo1.csv', encoding='gbk', usecols=[2,4])
print(df)
结果:

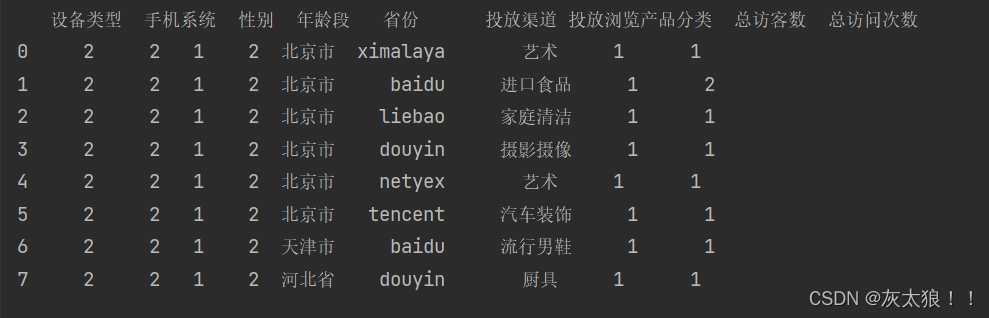
1.4nrows,指定读取记录多少行
import pandas as pd
df = pd.read_csv('H:\Projects\PycharmProjects\\bigdata29\day10\data\demo1.csv', encoding='gbk', nrows=8)
print(df)
结果:
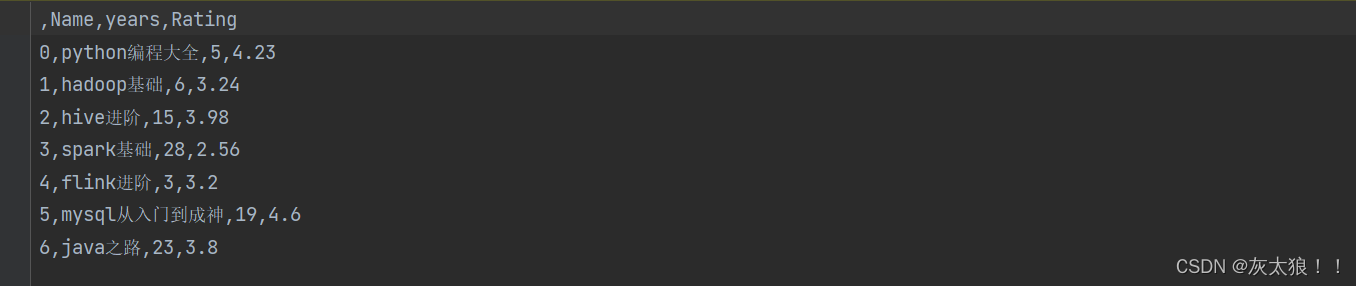
2.to_csv()写文件
现在我们将上述3.常用属性和方法汇总下3.1转置后的数据写入到一个叫demo3的文本中
import pandas as pd
import numpy as np
d = {'Name':pd.Series(['python编程大全','hadoop基础',"hive进阶",'spark基础','flink进阶','mysql从入门到成神','java之路']),
'years':pd.Series([5,6,15,28,3,19,23]),
'Rating': pd.Series([4.23, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8])}
df = pd.DataFrame(d)
df.to_csv('data/demo3.csv')
结果:
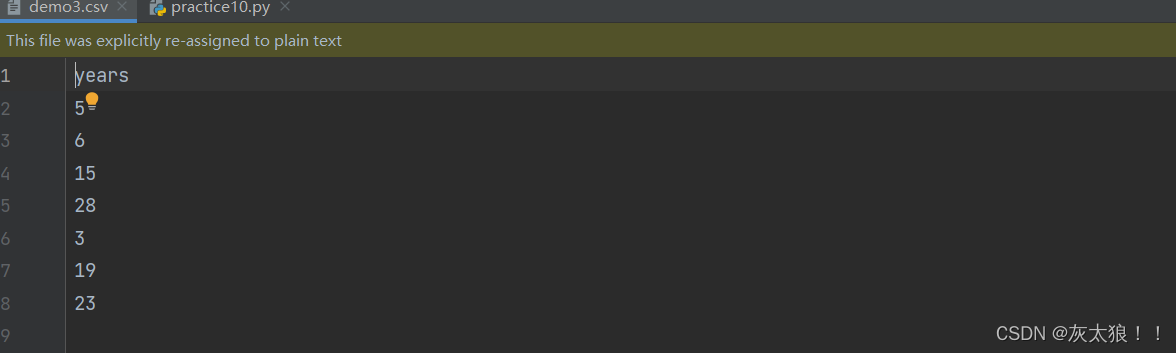
3参数说明
index:缺省index=True,如果你不加这个参数,写文件时会连带索引号一起写入
columns:按指定的列写入文件
encoding:
encoding:主要是为了兼容Python2的一些中文操作。大家知道由于计算机的发展历史,中文以及中文语系(包括日文、韩文等)并没有西方字母排列的那么规范。导致我们在不同的系统环境、不同的编程语言下都有可能会生成编码不一样的中文文件来。
import pandas as pd
import numpy as np
d = {'Name': pd.Series(
['python编程大全', 'hadoop基础', "hive进阶", 'spark基础', 'flink进阶', 'mysql从入门到成神', 'java之路']),
'years': pd.Series([5, 6, 15, 28, 3, 19, 23]),
'Rating': pd.Series([4.23, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8])}
df = pd.DataFrame(d)
df.to_csv('data/demo3.csv', index=False, columns=['years'], encoding='GBK')
结果:?
五、Pandas绘图 matplotlib.pyplot出图
1.?柱状图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号
print(np.random.rand(10, 4), type(np.random.rand(10, 4)))
list1 = [
[99, 98, 97, 95, 89],
[89, 98, 76, 90, 88],
[76, 90, 98, 89, 89],
[99, 98, 97, 95, 89],
[96, 88, 93, 92, 99],
[94, 92, 98, 93, 81],
[92, 91, 91, 98, 81]
]
array1 = np.array(list1)
df = pd.DataFrame(array1,
index=['第1次测试', '第2次测试', '第3次测试', '第4次测试', '第5次测试', '第6次测试', '第7次测试'],
columns=['第一组', '第二组', '第三组', '第四组', '第五组'])
# 或使用df.plot(kind="bar")
df.plot.bar()
# plt.bar(['第1次测试','第2次测试','第3次测试','第4次测试','第5次测试','第6次测试','第7次测试'], [11,22,33,44,55,66,77])
plt.xticks(rotation=360)
plt.show()
结果:
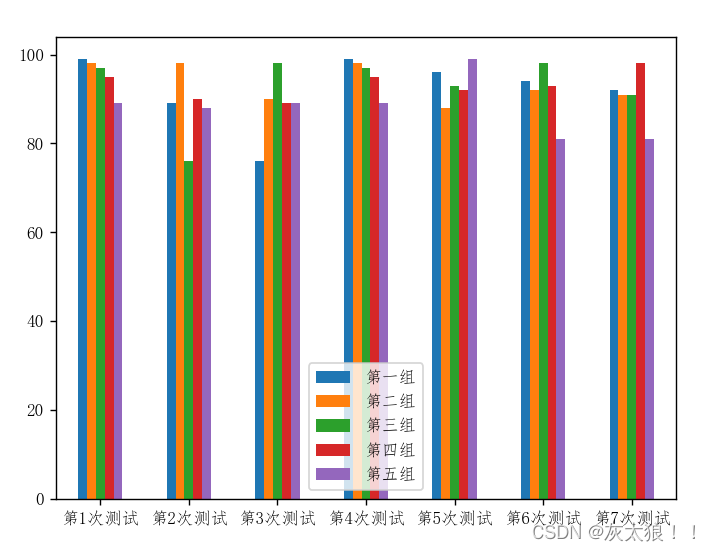
横向的柱状图:将参数df.plot.bar() 改为df.plot.barh(stacked=True)
2 散点图(机器学习的聚类)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
# 创建一个DataFrame
data = {'x': [1, 2, 3, 4, 5], 'y': [2, 4, 6, 8, 10]}
df = pd.DataFrame(data)
# 绘制散点图
df.plot(kind='scatter', x='x', y='y')
# 显示图形
plt.show()结果:
3 饼状图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号
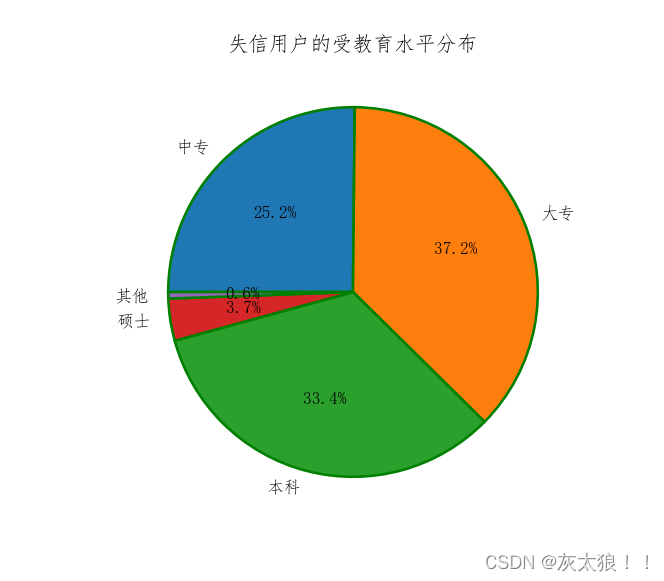
data1 = pd.Series({'中专': 0.2515, '大专': 0.3724, '本科': 0.3336, '硕士': 0.0368, '其他': 0.0057})
# 将序列的名称设置为空字符,否则绘制的饼图左边会出现None这样的字眼
data1.name = ''
# 控制饼图为正圆
plt.axes(aspect='equal')
# plot方法对序列进行绘图
data1.plot(kind='pie', # 选择图形类型
autopct='%.1f%%', # 饼图中添加数值标签
radius=1, # 设置饼图的半径
startangle=180, # 设置饼图的初始角度
counterclock=False, # 将饼图的顺序设置为顺时针方向
title='失信用户的受教育水平分布', # 为饼图添加标题
wedgeprops={'linewidth': 1.5, 'edgecolor': 'green'}, # 设置饼图内外边界的属性值
textprops={'fontsize': 10, 'color': 'black'} # 设置文本标签的属性值
)
# 显示图形
plt.show()结果:
本文只供作者回顾知识点所用,由于水平有限,若有错误欢迎诸位大佬指正!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RabbitMQ入门指南(八):MQ可靠性
- 纳米材料市场分析:预计2029年将达到1367亿元
- docker 安装mysql 数据库(亲测有效)
- PostgreSQL中误删除数据怎么办(一)
- redis 从0到1完整学习 (十三):RedisObject 之 Set 类型
- SvgShellExtensions 在资源管理器直接预览SVG格式图片
- Kubernetes 的用法和解析 -- 6
- YOLOv8加入顶会ICLR2022MobileViT模块
- zblog主题_zblog主题模板多功能门户百科资讯网站自适应模板
- RT-Thread 中断管理